特集
眠っているIntelのNPUをLLMで叩き起こしてみた
2026年3月26日 06:11

最新のPCのほとんどに標準で入っているのに、利用頻度がかなり少ないものの1つとして、NPUが挙げられる。
NPUはAI処理を効率よくこなせるプロセッサとして知られている。Microsoftが定めたCopilot+ PCをクリアする基準となる40TOPSに達しているものであれば、Windowsの標準機能が使ってくれる。その機能が実用的かどうか、使用頻度はどうかさておき、動かそうと思えば一応、いつでも使うことはできる。
しかしこの性能基準をクリアしていない、Arrow Lakeのコードネームで知られるCore Ultraシリーズ2のNPU「Intel AI Boost」は、ほとんど使い道がない。ノートPCであれば、「Windows スタジオ エフェクト」という背景ぼかし処理に活用できるのだが、この機能は特定のモデルでしか有効化できず、USBのWebカメラを接続するデスクトップPCでは使えない。
サードパーティのソフトとしては、画像編集ソフト「GIMP」のStable Diffusionプラグイン、動画編集の「CapCut」で背景切り抜き、音声録音ソフト「Audacity」のOpenVINOプラグインで文字起こしにNPUを活用できることが知られている。しかし、Stable Diffusionで生成できる画像はクオリティが低いし、動画編集も録音からの文字起こしもほとんどしないユーザーにとって無縁。ちょっとNPUの性能を試してみたいがために、動画や録音素材をわざわざ用意するのも面倒だろう。
身近なLLMでNPUを使う
NPUといえばAI、そしてより身近なAIといえばLLMだ。このLLMをNPUの上で動作させる方法はないのだろうか?
実は、Ryzen AIプロセッサ向けには、NPUを生かすことができるサードパーティのLLMフロントエンドソフトが登場している。それが「Lemonade Server」だ。Lemonade ServerではバックエンドにRyzen AI Softwareを利用し、LLMをNPU上で動作させられる。

しかし当然のことだが、Lemonade ServerはIntel AI Boost非対応である。
「なんとかIntel AI BoostでもLLMを動かしたい!」
そのヒントは、2025年1月に遡る。このとき、Microsoft製のエディタ「Visual Studio Code」の拡張機能「AI Toolkit」で、NPUによる推論をサポートしたことがニュースになった。ただし、このときの対応はSnapdragon Xを搭載したCopilot+ PCのみで、しかも使えるモデルはDeepSeek R1だけ。当時、実機で試された石田氏の窓の杜の記事での結果は、“悲惨”ともいえる状況だった。


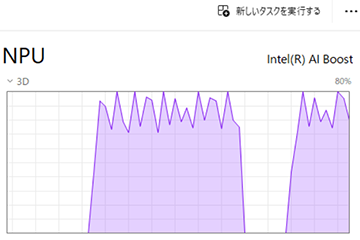
この後、IntelやAMDのNPUに対応したという云々の公式アナウンスも特になされず(なかったよね?)、筆者含めておそらく世の中の大半の方にとって、記憶の彼方に飛ばされたただの歴史となっていることだろう。
ところが先日、Lunar LakeのミニPC「GMKtec K13」をレビューする機会があって、その際に「そういえばIntel含めて対応するとかの話はどうなったんだっけ?」と、久々にVisual Studio Codeをセットアップして確認してみたところ、ちょっと古いがQwen2.5のモデルがIntel向けに用意されていることが分かった。そして、ちゃんとNPUで動作することも確認できた。

Qwen2.5はさすがに最新のQwen3.5と比べると見劣るし、Visual Studio Code上でセットできる最大コンテキストウィンドウが1,536に限定されてしまっているので、利用用途は限定されるのだが、日本語の受け答えについて、DeepSeek R1よりはるかに実用的であることも確認できた。

Arrow Lakeじゃあだめですか?
ここで筆者は2つの疑問が湧いた。
- Lunar Lakeで動作するのなら、Arrow Lakeでも動作するのではないか
- LLMのためにエディタを起動するのは変なので、LLM専用フロントエンドを使えないか
ただ、そもそも「Intel NPUでLLM」と漠然としたキーワードでネット上を調べても、「cmakeとNPUのライブラリをインストール、Pythonのスクリプトで記述」といった頭が痛い情報しか出てこなかった。
ここで、ジェンスン・フアン氏の言葉が脳裏をよぎった。
「AIの作り方や使い方が分からなければ、AIに尋ねればステップ・バイ・ステップで教えてくれる」。

さすがにステップ・バイ・ステップとまでは行かなかったが、AI(Google Gemini)から以下のようなヒントを得ることができた。なお、Visual Studio Codeに関する質問と、NPUでLLMに関する質問は別のチャットで行なっていた。
- Visual Studio CodeのAI Toolkit拡張におけるローカルでのLLM実行は、Foundry Local(旧称:Azure AI Foundry)を使っている。Foundry Localは単体でバックエンドとして動作する
- フロントエンドはAnythingLLMがONNXモデル(NPUでも使えるモデル)の対応が進んでいる


ただ、AnythingLLMのONNXの話はSnapdragon X対応のようであり、そもそもONNXランタイムの実行はFoundry Localが担うので、AnythingLLMを(バックエンド+フロントエンドのセットとして)使う義理も特にない……
まあ、ものは試しということで先にAnythingLLMを入れてみたところ、設定(メイン画面左下の歯車アイコン)でLLMプロバイダー(バックエンド)としてFoundry Localが選択できることが分かった。つまり、フロントエンドだけ、GUIで使いやすいAnythingLLMにすることができるというわけだ。

Foundry Localとモデルのセットアップ
ならば話は早い。Foundry Localをセットアップしてモデルを入れ、以降はAnythingLLMをフロントエンドとして使うだけのはずだ。早速Windowsのターミナルを立ち上げて、以下のように入力する。
> winget install Microsoft.FoundryLocal
そもそもMS-DOS時代ぐらいしかMicrosoftのOS環境でコマンドを打っていなかった老人にとって「wingetってなんぞや」というところから始まると思うが、Ubuntuでいうところの「apt」に相当するコマンドだと思ってほしい(話の飛躍)。
続いては、NPUで使えるモデルをチェックする。Foundry Localが使えるモデルは今のところそんなに多くないので、リストアップすると「-openvino-npu」がついているものはすぐに見つかるはずだ。そしてここで先の疑問がほぼ解消した。Foundry LocalでLLMを動かすのは、Copilot+ PCに限定されたなんらかの仕組みではなくOpenVINOを使っているということ。これなら、Arrow LakeのNPUでも動く可能性が高い。
> foundry model list

今回は例として、モデルの規模が比較的大きい「qwen2.5-coder-7b」を使ってみる。ほかのモデルを利用する場合は、名前を適宜変えてほしい。ちなみにモデルIDまで指定しないとCPU実行版が落ちてくるようなので注意したい。
> foundry model download qwen2.5-coder-7b-instruct-openvino-npu:2
ダウンロードが終わったら、AnythingLLMに戻り、「Open settings」のアイコンをクリック。AIプロバイダーの「LLM」の項目で、LLMプロバイダーとして「Microsoft Foundry Local」を選び、Chat Modelとして「qwen2.5-coder-7b-instruct-openvino-npu:2」を選択する。

ちなみに「Show advanced settings」でModel Context Windowの数値が入れられるが、試しに65,536を入れてみても問題なく動作した。ただしこの数値が大きければ大きいほどメモリ使用率も増えるので注意したい。
あとはチャット画面に戻り、チャットをするだけだが……筆者の目論見通り、Arrow LakeのIntel AI Boostでも使えることが確認できたのだった。最初はモデルのロードやイニシャライズ処理で2~3分待たされるが、以降は比較的早く応答してきた。
NPU×LLMの将来
Arrow LakeのNPUは性能が低いため、トークン出力速度は8tok/s前後。しかもqwen2.5とモデルが古く、なおかつNPUに最適化されているためか、長い出力ができず片言程度だ。

とはいえ、NPUには「低消費電力」というメリットがある。今回はCore Ultra 9 285HXを搭載したMINISFORUMの「MS-02 Ultra」でテストしたが、アイドル時13W前後で推移するCPUパッケージ電力は、わずか5W~7W程度増えただけだった。CPUやGPUのファンの回転数もほとんど変化せず、静かなままだ。
さすがに結果の出力を急ぐようなシーンにおいて、8tok/sという速度は耐え難いかもしれない。しかし雑談の相手、もしくはちょっとしたヒントや知識を得るための相手としてはどうだろうか?それならむしろちょっと遅くても、消費電力5Wのほうが実用的だと思えてくる気がした。

課題は、現時点では手軽に試せる仕組みがFoundry Localに限定されているため、そこに登録されていない最新モデルなどはすぐに試せないということ。一応、Foundry Localのモデルはこれからも拡充を続けるようだが、もう少しスピード感をもって更新していただきたい。
そういえば、“登場して、ちょっと話題になって、いつの間にかフェードアウトしていく”ソフトの1つに、「伺か」のようなデスクトップマスコットがあるが、比較的小型な言語モデルをファインチューニングして、キャラクター性を持ちつつ、ある程度知性をもって自然言語で受け答えができるマスコットなら、NPU上でひっそり動いてもいいのではないか?
……そう考えながら、今日もNPUと雑談を続けるのであった。

