大原雄介の半導体業界こぼれ話
高性能メモリHBM、冷却用“煙突”が必要になる時代に突入
2026年6月22日 06:06

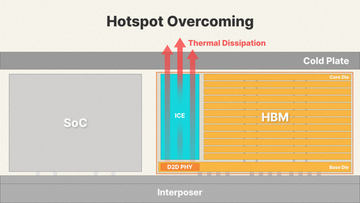
SK hynixが5月27日、「iHBM」を発表したことはニュースで取り上げている通り。D2D PHYをDRAMからオフセットして配し、このD2D PHYの上に専用の冷却経路(ICE: Integrated Cooling Elements)を置くことで、D2D PHYの発熱を直接冷却できるようにする、というものだ。
実はこの発想そのものはSK hynixが初めてというわけではない。Samsung Electronicsは今年(2026年)のCOMPUTEXで、HPB(Heat Path Block)を利用したHBM5の構造を公開したことがTrendForceなどで報じられている。

このHPBは、元々同社のプロセッサ「Exynos 2600」用に提供されたものであり、今年1月に同社のTech Blogのエントリで紹介されている。直接的な理由は、HBMのD2D PHYの発熱をどうにかしないといけないという話であるが、話はもう少し根が深い。
今年のISSCCにおけるフォーラム(Forum 3.7)でSamsung Semiconductorがちょうど「Packaging-Aware Design and Optimization of HBM Power Delivery in AI Platforms」という講演を行なっているので、まずはここからいくつかスライドをご紹介したい。
高速化と積層化で冷却がカギに
図1は転送速度の推移で、DDR/GDDR系に比べてHBMが急速に帯域を増やしているが、消費電力が着実に増え続ける。効率そのものは2pJ/bitを切ることも夢ではないとしているが、これはHBM3Eの世代からロジックプロセスが入ったことも関係している。その話は次でするとして、この効率は帯域を増やしているから効率が改善しているという話であって、絶対的な消費電力(とHBMのチップの底面積)は増え続ける傾向にある。


一方、HBMのロジックプロセスの話となるが、そのHBMの基本的な構造が図3。基本的にHBMは一番下にベースダイが置かれ、ここがプロセッサとのI/F(冒頭で出てきたD2D PHYなんかがこれに相当する)を担当する。ベースダイはこれ以外に信号補正とか、若干だがロジック回路(プロセッサから送られたコマンドを解釈して動作モードを変更するとか)も入るが、HBMといっても所詮はDRAMであるから、それほど難しいロジックが入るわけではない。

それもあって、これまではベースダイもDRAMダイと同じプロセスで製造されていた。元々DDR/LPDDRやGDDRでは、こうしたPHYとDRAMセルが一体で製造されていたから、これそのものは別に不思議ではない。ただPhoto01に出てきた数字をピンあたりの速度に換算すると
| 世代 | 帯域幅(GB/sec) | 幅(bit) | 速度(Gbps) |
|---|---|---|---|
| HBM2 | 307 | 1,024 | 2.4 |
| HBM2e | 461 | 1,024 | 3.6 |
| HBM3 | 819 | 1,024 | 6.4 |
| HBM3e | 1,178 | 1,024 | 9.2 |
| HBM4 | 2,048 | 2,048 | 8 |
| HBM4e | 3,072 | 2,048 | 12 |
となる。つまり、HBM3eあたりで信号速度が上がりすぎることになった。そこでベースダイだけDRAM用プロセスではなく、ロジック用プロセスを利用するという移行が発生することになった。悪い(?)ことに、この後も信号速度は落ちることがなかったから、よりベースダイは高速で動作する必要が出た。
HBM3でいえば、6.4Gbpsで信号の送受信が行なわれるが、当たり前だがDRAMセルはこんな高速でのデータの送受信はできない。ピーク性能は以前でも200Mbps程度、今でも400Mbpsには達しない程度だろう。そのためマージンを見込んで200Mbpsを前提にすると、32bit分のインターリーブが必要になる。
つまり、6.4Gbpsで来た信号を32個のDRAMセルに200Mbpsで同時に流し込む、あるいは逆に32個のDRAMセルから同時に200Mbpsでデータを読み取り、これを6.4Gbpsの信号に変換して送り出す必要がある。ということは、回路の一部は6.4GHzで動いてるわけで、いかに動作周波数が高くなったかがお分かりいただけよう。
HBM4ではバス幅を2,048bitに増やしたが、それでも信号速度はあまり下がらないどころか、HBM4eでは10GHzを超える速度になる。ベースダイがロジックプロセスでの製造に切り替わるのは、それに見合う理由があるわけだ。
加えて、DRAMセルそのものについてもそんなわけで限界まで高速駆動されているから、いくらDRAMといっても消費電力は上がる。
もっと問題なのは、HBMではDRAMダイが積層されるということだ。初代のHBMは4層とかだったのが、今では12層や16層になっている。つまりDRAMダイに対しての供給電力が4倍とかになっている(速度向上分も加味すると、もっとかもしれない)。結果として必要となる電力が急増しているのだが、TSVに大電流を流すと燃えるので(後で出てくる)、TSVにおける電力ピンの数を増やすことで対処する、という話になっている(図4)。

積層方法にも変化が生まれるか
これに絡んで話が出てくるのが、DRAMダイの積層を従来のマイクロバンプからハイブリッドボンディング(つまりファンデルワールス力を利用した、Cu VIA同士の直接接続)に切り替えようという動きである。
理由は複数あり、
- 12層ぐらいまではマイクロバンプを利用した積層でも高さが許容範囲内に収まるが、16層など、さらに今後多層化を狙おうとすると、高さが高くなりすぎる問題が出てくる。ハイブリッドボンディングだと接続部の高さが0(なにしろVIA同士が直接接続される)なので、厚みを抑えられる
- マイクロバンプ経由だと熱抵抗が大きくなるので、下の方のDRAMダイ(やベースダイ)の熱を上の方のDRAMダイに伝えにくくなる。つまりHBM全体の温度が上がりやすくなる。ハイブリッドボンディングでは熱抵抗がかなり下がる(なにしろCu同士だ)ので、温度上昇を抑えやすい
- マイクロバンプは電気抵抗もCuよりは大きいので、消費電力が増えるとそれだけマイクロバンプ部での発熱が発生する事になる。ハイブリッドボンディングの電気抵抗はマイクロバンプより小さいので、それだけ発熱も抑えやすい
といったあたりだ。
これだけ見れば「ならなぜハイブリッドボンディングにしないのか」と思われるだろうが、理由はコストだ。ハイブリッドボンディングの実装コストはマイクロバンプの数倍であり、しかもHBMは多層構造だからコストの差が非常に大きくなりやすい。高価格でも性能さえ出るなら許されるHBM4以降でなければ許容できないレベルの価格差になるだろう。
ちなみにこのあたりの状況を示したスライドがこちら(図5)。右のMicro bump countとはベースダイとDRAMダイ、あるいはDRAMダイ同士の接続に使われるマイクロバンプの数で、HBM4→HBM4eでこれだけ増えている。隣のC4 Countはベースダイとインターポーザーの間のC4バンプの数で、こちらも大幅に増えている。で、右の写真が発熱が多すぎて破壊されたダイ(ベースなのかDRAMなのかは判断付きにくいが、断面からするとベースダイっぽい)である。こうならないように工夫が必要というわけだ。

DRAMダイのように(相対的に)消費電力&発熱が少ないダイですらこうした問題がいろいろ出まくっているわけなので、ベースダイの方はさらに消費電力&発熱が問題になる。特に消費電力に関していえば、原理的に消費電力の大きなベースダイの近くにデカップリングキャパシターを置けない(から供給電力の変動が大きくなりやすい)という問題があるとしている(図6)。

HBM4/4eの世代ですらこうした問題が出ているわけなので、この後予定されているHBM5の世代ではさらに問題が深刻化する。要するに電力供給と発熱をどうするか?という問題だ。
まず最初に行なわれるのが、HBMへの直接給電である。従来はHBMへの給電はASIC側から行なわれていた(図7)が、これだとシリコンインターポーザー内に大電流が流れることになる。短距離ではあるものの、シリコンインターポーザーは配線幅が短いから大電流を流すのには不適当である。そこで、HBMの給電はASIC経由ではなく外部からシリコンインターポーザーを垂直に貫通するような形にすることで、配線抵抗によるロスを最小に抑える工夫を凝らしている。

次世代のGPUは、チップあたりの消費電力が1kWを超えるという化け物であり、これに対応するためにVPD(Vertical Power Delivery: GPUチップの真裏にVRMを配し、そこから基板を垂直に貫通するように電力供給を行なう方式)を採用するという話になっているが、HBMも同じような状況になっている。
ちょっと前に、次世代チップに向けてIntelのEMIB-Tの引き合いが急激に増えているという話があった。EMIBは図7のように、ASICとHBMをつなぐことしかできないが、EMIB-Tは図8のようにインターポーザーを貫通して直接基板と接続ができる。TSMCのCoWoSの供給が逼迫しており、なので代案としてEMIBを使おうにもHBMの垂直給電ができない。EMIB-Tならこれが解決するというわけだ。

SK hynixもSamsungも“煙突”構造採用目論む
さて次が放熱の話である。ここで冒頭の話に戻るが、要するにSK HynixのiHBMのこの図に集約されている。ベースダイを少し大きく取り、はみ出した部分に一番発熱の大きなD2D PHYを配したうえで、その真上に冷却用の柱(海外では煙突呼ばわりされていた。まぁ煙突という表現はなかなか適切だ)を置くことで、効率的に放熱しようという仕組み。SamsungのHPBの方も似たようなものだ。
図7は同社が今年1月に公開した動画からの流用だが、APダイの上に冷却用のブロックを設け、ここから放熱を行なうことでDRAM経由の不効率な放熱に頼らなくて済む。

現時点でiHBMとHPBの大きな違いは、冷却ブロック(要は煙突)とD2D PHYの接続方法である。HPBはある意味コンサバティブで、D2D PHYを含むベースダイ(これはモールドパッケージでカバーされる)の上に煙突を置くが、iHBMの方はそのモールドパッケージを挟まず、直接(といっても絶縁膜位は設けられるだろうが)ICEを載せることで効率を高めよう、という仕組みだ。機械的強度を考えるとちょっと不安になる実装だが、その分冷却効率は高いだろう。
HBM5世代はまだはっきりしないが、1スタックが最大20層、消費電力はスタックあたり100Wを突破するとかいう予測もある。これをカバーするためには煙突が必須というのがSK HynixとSamsungの見解である(Micronだけは独自路線で、省電力設計+TSVを利用したクーリングで行けるとしている)。
パッケージに煙突が露出するようなことはないと思うが(HPBの方はひょっとすると……の可能性はある)、内部に煙突が入っていることは間違いないという時代が来るらしい。ちなみに業界の予測によれば、その先はHBM Stackそのものも液冷が必須になるようだ。恐ろしい時代である。