トピック
AI/HPCにはなぜ複数種のプロセッサーが必要なのか。カギとなる次世代Xeonスケーラブル・プロセッサーの新機能とは?
- 提供:
- インテル株式会社
2022年7月28日 06:30

今、さまざまな社会課題を解決するため、社会のデジタル化、いわゆるデジタルトランフォーメーション(DX)が叫ばれている。DXを実現する上で、必要なのがクラウドの処理能力だ。
しかし、データセンターに求められる性能の高さや、要求の種類が増えた結果、そこで使われるプロセッサーはワンサイズ・フィッツ・オールではなくなり、インテルでは、複数の種類のプロセッサー、たとえばCPU、GPUなどを異種混合で利用していくことが、データセンター全体の性能や電力効率を引き上げていく道だと指摘する。
ただこれまで、異種混合のプロセッサーを扱うのには、高いレベルの技術が必要だった。そういった中、インテルは、「oneAPI」という1つの開発環境で統合的に扱うことを可能とし、データセンターの能力をより引き上げている。
DXによりニーズが高まるデータセンター、既にワンサイズ・フィッツ・オールの時代ではない
COVID-19のパンデミックが始まって以降、急速なデジタル化が進んでいる。そのデジタル化を支えるのは、PCやスマートフォンのようなクライアントデバイスだ。PCやスマートフォンなどのクライアントデバイスは、クラウドにあるデータセンターと対になって利用されるのが一般的だ。
クラウドストレージ、AIサービス、クラウドゲーミングといったさまざまなサービスはデータセンターに置かれているサーバーの中で動いており、5Gなどの高速インターネット回線経由でユーザーに対して提供する仕組みになっている。多くの産業でDXが進展した結果、クラウドに置かれているサーバーの処理能力への需要も増え続けている。
そうした中でデータセンター向けのXPU(x Processor Unit、複数種類のプロセッサー)戦略を推し進めるインテルは、複数種類のプロセッサーを異種混合利用することで、Amazon Web ServicesやMicrosoft Azure、Google Cloudなどのクラウドサービスプロバイダー、あるいは大企業の自社データセンターなどで必要とされるニーズに応えようとしている。
インテルアクセラレーテッド・コンピューティング・システムズ&グラフィックス事業本部スーパーコンピュート事業部マーケティングマネージャーのブライアン・ゴーレンビワフスキー氏が「今やデータセンターのプロセッサーはワンサイズ・フィッツ・オールではない。AI向けと言っても伝統的なマシンラーニングもあれば、巨大なデータセットで学習を行なうディープラーニングもある。データ量も、必要とする処理能力もさまざまであり、それぞれに対応するプロセッサーが必要になる」と述べる通り、同社ではAIだけをとってみても複数の製品を提供している。

データセンターで走っているサービスは1種類ではない。伝統的なエンタープライズITも走っていれば、AI、そしてHPC(High Performance Computing)など多種多様なサービスがデータセンターのサーバー上で動作している。さらにそれらとクライアントデバイスを中継する5Gの基地局も、従来の固定機能を持つ通信機器から、OpenRANやvRANなど、SDN(Software Defined Network)と呼ばれる汎用プロセッサー+ソフトウェアの組み合わせに置きかえられている。また、通信事業者の基地局ないしはその近くには、特定のサービスなどを提供するエッジサーバーも置かれ始めており、そうしたニーズも増大しているのが現状だ。
そこで、インテルはさまざまなニーズに対応すべく複数種のプロセッサーを提供し、「oneAPI」というソフトウェア開発環境と組み合わせることで、1つのプログラムコードを用いながらも、複数のプロセッサーの中から最適なものを利用して処理できる環境を実現している。
ゴーレンビワフスキー氏は「異なるワークロードに対して開発者がどんなハードウェアを組み合わせてよいかを理解していなくても、一般的なプログラムの知識があれば複数のプロセッサーに対応したソフトウェアを作成できる」と、oneAPIのメリットを説明する。
oneAPIという大きな傘のもとに、CPU、GPU、FPGA、アクセラレーターなど複数のプロセッサーを提供し、かつ、競合他社のプロセッサーまでもカバーしながら、ソフトウェアとハードウェアを両輪で回していく。インテルでは、そうした壮大な戦略を掲げているのだ。
進化するCPUのXeonスケーラブル・プロセッサー、AMXによりAI性能を大きく引き上げた次世代製品Sapphire Rapidsが間もなく登場
このようなインテルのXPU戦略の中で、依然として重要なポジションを占めているのがCPUである。インテルは2021年に、第3世代インテルXeonスケーラブル・プロセッサーを発表、出荷しており、多くのデータセンターに既に導入されている。
そして間もなく、次世代製品となる開発コード名「Sapphire Rapids(サファイア・ラピッズ)」を第4世代インテルXeonスケーラブル・プロセッサー(以下、Sapphire Rapids)として発表する見通しで、既に特定の顧客やPCメーカーなどに対して出荷を開始している。

実はXeonスケーラブル・プロセッサーは、AI市場では推論、学習ともにもっとも利用されているCPUになる。推論に関してはCPUだけで、学習に関してはGPUと組み合わせて利用されることが多いが、いずれにせよ多くのAI向けのサービスがXeonスケーラブル・プロセッサー上で動いていることは業界の常識だ。
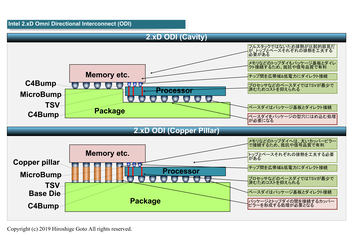
そしてインテルは、Sapphire Rapidsで新しい拡張を導入する。ハードウェア面ではEMIB(Embedded Multi-die Interconnect Bridge、イーミブ)という、2.5Dで4つのダイ(CPUなどが生産される単位のこと)をパッケージ内で統合する技術が利用されており、CPUコア数を需要などに応じて柔軟に設定することが可能になる。
また、HBM2e(High Bandwidth Memory 2)と呼ばれる広帯域幅のメモリを搭載したバージョンも提供される計画で、HPCのアプリケーションのようなメモリ帯域で性能が決まってくるアプリケーション、たとえば製造業、石油/ガスのシミュレーションなどで大きな効果がある。

インテルは、従来のx86命令を拡張する命令セットを数世代おきに導入しているのだが、Sapphire Rapidsのもう1つの特徴は、新しい命令セットになるAMX(Advanced Matrix eXtensions)だ。AMXでは、新たに導入されるTMUL(Tile Matrix mULtiply unit)と呼ばれる行列乗算アクセラレーターを利用することで、INT8、Bflot16を用いたAI演算時に性能が大幅に向上する。
具体的には、AMXによって、BF16を利用した場合でFP32に比較して約8倍、同時にINT8の精度で、AVX-512を利用して演算した場合と比較しても約8倍という性能を実現する。

なお、推論向けソリューションとしては、インテルは今後、専用アクセラレーターを投入する。インテルが2019年に買収を発表したHabana Labs由来の製品である「Greco」(グレコ)がそれだ。
Grecoでは、製造プロセスルールが前世代品の16nmから7nmに微細化されるとともに、キャッシュ容量やメモリ帯域などが増やされ、システムの熱設計消費電力も200Wから75Wに下げられるなど、省電力化されながら性能は向上している。より電力効率を重視したAI推論を必要とするユーザーであれば、こちらも要注目だ。Grecoは今年の後半に選択された顧客に対して出荷が開始される見通しだ。
最大で47個のダイを2D/3Dに実装したGPUのPonte Vecchio
インテルはAI学習向けのソリューションも充実させている。GPUに関してはPonte Vecchio(ポンテベッキオ)と呼ばれるGPU製品を開発しており、間もなく、顧客などに対して提供を開始する。


Ponte Vecchioは非常にユニークな製品となっている。ハードウェアの観点で言うと、インテルがタイル(Tile)と呼んでいる、複数のダイが1つのパッケージ上で統合されている製品となる。
Sapphire Rapidsでも利用されている、2.5Dに複数のチップを実装する技術であるEMIB、3Dに複数のチップを実装する技術のFoveros(フォベロス)という2つの実装技術を活用して、2D方向にも、3D方向にも複数チップがパッケージ上に実装されており、最大で47のチップが組み合わされて1つのGPUが構成されている。こうした仕組みを採用することで、従来のモノリシックな1つの巨大チップよりも、性能を引き上げることが可能になっている。

Ponte Vecchioは単精度(FP32)で45TFLOPSという性能を発揮する。電力効率に優れており、高い演算性能を必要とするようなワークロードに適した製品となる。
ゴーレンビワフスキー氏は「AIの学習はまさにそうしたワークロードで、学習にGPUが利用されているのはそうした電力効率がポイントになっていると考えることができる。Ponte Vecchioでは大容量のキャッシュ、新しいエンジンとして使えるXMXを搭載しており、それを活用することでさらに高効率にAI学習を行なうことが可能になる」と、必要に応じてCPUからPonte Vecchioに並列実行する処理をオフロードしていくことで、データセンター全体の電力効率を上げていくことができると説明する。
Ponte Vecchioでは、さらに、Xe-LinkというGPU専用のインターコネクトが用意されており、最大8個までスケールアップして利用できるようになっている。実際のデータセンターではそうしたスケールアップと同時に、インテルが提供するIPU(Infrastructure Processing Unit)を活用してスケールアウトしても利用される見込みで、両方をバランスよく構成できることもPonte Vecchioの特徴だ。
電力効率や費用対効果を重視しながらAI学習を行なうソリューションには「Gaudi2」を提供
電力効率やコストを追求しながらAI学習を行ないたいというニーズには、インテルが2019年に買収したHabana Labsが開発した、GaudiシリーズのAIアクセラレーターという選択肢も提供している。
GaudiシリーズのようなASICベースアクセラレーターの特徴は、用途に特化すれば大きな効果を得られることだ。それにより高い電力効率や必要対効果に優れた性能を得ることができるという。
インテルは既に初代GaudiをAWS(Amazon Web Services)のEC2 DL1インスタンスとして提供開始しており、特定のディープラーニングの学習処理(ResNet50およびBERT-Large)において、GPUに比べて低コストかつ低消費電力で処理を行なえると説明している。
インテルはそのGaudiの後継として、Gaudi2を5月に発表している。Gaudi2では製造プロセスルールが微細化され、コンピュートエンジンが増やされ、処理能力が3.2倍と大きく向上するのが特徴となる。
初代Gaudiに比べてプロセスルールの微細化(16nmから7nmへ)したほか、演算用のエンジンが8から24に大きく増やされていること、新しくFP8の演算精度に対応していること、さらには48MBのキャッシュと32GBのHBM2e(1TB/秒)メモリ、TDPが300Wから600Wに増やされるなどのスペックアップにより、最大で約3.2倍の学習性能を実現するという。それによって、Gaudiの特徴だった高い電力効率や費用対効果などがさらに改善されている。

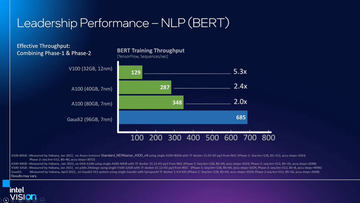
このGaudi2は、既にサーバー機器ベンダーのSUPERMICROが、8つのモジュールを搭載したサーバーを発表しており、インテルが5月にダラスで開催したIntel Vision 2022で展示を行なった。インテルによれば、既に顧客への提供が開始されている。

FPGAやクラウドゲーミングの実現などに対応したArctic Sound-Mなども提供
このほかにも、インテルは2015年に買収したAltera由来のFPGA(Field-Programmable Gate Array)や、クラウドゲーミングなどを実現するクラウドGPUソリューション向けのArctic Sound-Mなどが用意しており、CPU、GPU、FPGA、そしてアクセラレーターなどの複数のソリューションをそろえ、顧客が自社のニーズに応じて選択することを可能にしている。
まさにゴーレンビワフスキー氏の言う通り、ワンサイズ・フィッツ・オールではなく、ニーズに応じた製品を選択することで、より高いAIの学習性能を実現し、HPCの処理をより高速に行なえるようにしているわけだ。




このような、複数の種類の異なるハードウェアを効率よく利用するためのカギがoneAPIとなる。