西川和久の不定期コラム
340億パラメータのLLMは手元のPCで動く?Metaの「Code Llama 34B」を試してみた!
2023年9月29日 06:18

Metaは8月24日(現地時間)、コーディング向けの大規模言語モデル、「Code Llama」を発表。パラメータ数7B、13B、34Bとあるので、今回はその中から34BをローカルPCで動かしてみたい。
Code Llamaとは
同社Llama 2の記事に関しては7月に掲載した。13Bとは言え、これまで1桁Bばかりだったので、手元で動くとそれだけでも感慨深いものがある。
今回ご紹介するCode Llamaは、同じくMetaだが、汎用的なLlama2とは違い、Llama2をベースにプログラム生成に特化したモデルとなる。筆者は普段いろいろなLLMを使っているが、用途的にはプログラミングに関するものばかり。そうなるとこのCode Llamaの方が重宝しそうだ。
ベースモデルの「Code Llama」、Pythonに特化した「Code Llama-Python」、Instructに特化した「Code Llama - Instruct」の3種類あり、それぞれ7B、13B、34Bが用意されている。
先の記事を書いた時はGPUがGeForce RTX 4070 TiなのでVRAMが12GB。13BをローカルPCで動かすのが一杯一杯だった。
今回は手元にRTX 3090と、前回ご紹介したGIGABYTE「GV-N4090IXEB-24GD」もまだあるため、VRAM倍増の24GBで試すことが可能だ。そして34BがローカルPCで動くと一段ギアが上がる形となる。

以下、実際の手順などを説明するが、テスト環境が同じと言うこともあり一部、以前の記事と被るところもある。予めご了承いただきたい。
環境設定 / text-generation-webui
今回も簡単にインストールできて手間いらずのtext-generation-webuiを使用する。前回の環境が残っているので
PS D:\> conda activate llama2
(llama2) PS D:\> cd llama2
(llama2) PS D:\llama2> update_windows.bat

として最新にしたが、未インストールの時は
PS D:\> conda create -n llama2 python=3.10.6
PS D:\> conda activate llama2
(llama2) PS D:\>
(llama2) PS D:\> mkdir llama2
(llama2) PS D:\> cd llama2
※ 環境名はお好みで
と入力しよう。
そしてここからパッケージをダウンロードし、zipを展開してllama2へ
(llama2) PS D:\llama2> start_windows.bat
とすれば、http://127.0.0.1:7860で起動する。

LAN上のマシンからアクセスする場合は、webui.pyのCMD_FLAGS = '--chat'の部分を'--chat --listen'に書き換えれば、http://マシンのIPアドレス:7860でLAN上のマシンからも使うことができる。筆者の場合、加えてほかのアプリと被らないよう、ポート番号も替えており
CMD_FLAGS = '--chat --listen --listen-port 7862'
と、こんな感じで部屋中のPCから使用できるようにした。
モデルのダウンロードとロード
前回はaria2cコマンドを使い手動でモデルをダウンロードしたが、text-generation-webuiにはUI上で簡単にダウンロードできる仕掛けがあるので今回はそこから行なう。
モデルは、codellama-34b-instructを4bit/GGUF化したTheBloke / CodeLlama-34B-Instruct-GGUFのcodellama-34b-instruct.Q4_K_M.ggufを使用した。


ダウンロード方法は簡単で、Modelタブの右側、Download model or LoRAの上の行へTheBloke/CodeLlama-34B-Instruct-GGUFを入力、右下にある[Get file list]を押すと一覧が出るので、2bit~8bit量子化GGUF Modelから適当なのを下の行へ入力する(コピペする)。恐らくメモリ/VRAMの関係上、codellama-34b-instruct.Q4_K_M.ggufが無難だろう。
そして[Download]をクリック。19GBほどあるので、回線状況にもよるが結構時間がかかるため気長に待つ。
ダウンロードが終わったら、左上Model項目のリフレッシュボタンを押し、一覧にあるcodellama-34b-instruct.Q4_K_M.ggufを選択する。
次に左側にあるModel Loaderをllama.cpp、n-gpu-layersを45と設定。後者はVRAM容量が許す限り大きい値にする。50で試すとVRAM不足エラーとなったので、45とした。これで23GB前後を使用、不足部分はメインメモリに割り当てられる。そして左上にある[Load]を押せばロードされ、チャット可能になる。

このままでもチャットできるのだが、Parameters > Instruction templateをLlama-v2へ、Parameters > Generationのmax_new_tokensを4,096へ設定した。
前者はなしでも動くには動くが、入力したプロンプトをLlama2の作法に合わすテンプレートだ。文脈把握にも対応する。後者は、一度に入出力可能な最大トークン数。デフォルトだと200。これでは直に途切れてしまうので4,096とした。以前試した時、2,048超えるとおかしな作動をしていたのだが、今のところ問題なく動いている。


チャットとメモリ使用量や作動速度
普通にチャット形式で試してみたが、日本語での質問は大丈夫だが、返事は英語となる(たまに日本語)。これはWebブラウザの翻訳プラグインなどを使えば大した問題ではなく、日本語で聞けるだけで十分。どのみちプログラミング系の参考資料は英語が多いので慣れている。URLを使った要約も日本語は駄目だが英語ならOK(日本語は面倒がらず読めばいい)。


さて、AIが生成するコードについてだが、まずいきなり長くなるようなコードを作ろうとせず、機能(Function)ごとで細切れに作り問題ないかチェックする。加えて自分で検証できないようなものは生成しない。これが大原則かと思う。
筆者の場合、知らないフレームワークやモジュールなどを使うかも!? の時、簡単なサンプルコードを作ってもらい確認。後はリファレンス的なものを見ながら(もしくは尋ねながら)自分でコーディングするイメージだ。使用頻度の低いclassやfunctionを忘れているのでどうだったけ? と聞くこともある。
もう1つはやればできるが面倒的なもの、たとえばデータコンバータなどは作ってもらう(もちろん検証はする)。いずれにしても優秀なアシスタントがいる感じだろうか。たまにボケて妙なのを出してくるので、そこをツッコむのも面白い。
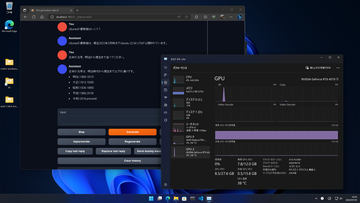
さて問題のメモリ、そしてVRAMの使用量だが、先のModelロード時に指定したn-gpu-layersが45だと、メモリ約30GB、VRAM約23GBの計53GB……と、凄まじい量となる。これを見ると、次PCを組む時はメモリ64GBにしたい! と思ってしまう(笑)。

気になる速度は、GeForce RTX 4070 TiでLlama2を使った時は(全てVRAM上)、Output generated in 28.89 seconds (12.01 tokens/s, 347 tokens, context 795, seed 1906221875)だったが、今回GeForce RTX 4090だとOutput generated in 58.27 seconds (10.49 tokens/s, 611 tokens, context 109, seed 968395139)。
12.01 tokens/s vs 10.49 tokens/s。メモリと併用している分、少し遅いものの、感覚的に10 tokens/s前後なら、通常用途として全く問題ない速度になった。
余談。自宅回線をU-NEXT光01(100Mbps)からフレッツ光(1Gbps)へ
ちなみに余談になるが、筆者は2001年から使っていた光回線(旧Broad Gate01/現U-NEXT光01)の固定IPアドレス付きサービス停止に伴い、フレッツ光(マンション共有1Gbps)+ASAHIネットに乗り換えた。
もともと光でも100Mbpsだったのだが、ネットマスク255.255.255.248/29と、複数の固定IPアドレス付き。Webサーバーや仕事関連でIPアドレス制限などを設定していたこともあって替えずにそのままにしていた経緯がある。これを変更となると結構大騒動だ。
まず足元のNAS / VirtualBoxで作動していた各Webサーバーは、Xserver VPSに引っ越し。3core/2GB/50GBで月額539円ど激安だが、Celeronで作動していたVirtualBoxより圧倒的に速い。Mastdonサーバーも動かしていたが、これは引っ越しが面倒なのと頻度も低いため廃止した。
次に仕事上固定IPアドレスは少なくとも1つは必要。ASAHIネットのオプション、固定IPアドレスを追加で申し込み、取得したIPアドレスを各社に連絡。

既に10日ほど経っているが、肝心の速度はマンション共有1Gbpsとは言え、筆者の住むマンションは小規模で、事務所×3、住居×3。おそらく全世帯が一斉に使ってもたかが知れている。実際測ると700~850Mbps。最近Model系のファイルは数GBなどが普通なので、ダウンロードが圧倒的に速くなり大満足だ。
今回19GBものModelファイルをダウンロードした割には短時間で終わったので、そう言えば……と余談として扱った。
以上、Metaの「Code Llama 34B」をメモリ32GB+VRAM 24GBの環境でギリギリ動かすことができた。これからも分かるように、さらに上の70Bは、現状、一般的なハイエンドローカルPCでの作動は不可能かと思われる。素直にGoogle Colab(Pro)を使うのが無難だろう。
いずれにしてもVRAM 12GBから24GBのGPUへ替えた理由の1つは、これだったりする。達成できて嬉しい限り。高価な爆速大容量GPUで、美女画像だけ出しているわけではない(笑)。