西川和久の不定期コラム
LLMがローカルで動くパラメータ数どこまで?Metaの「Llama 2」を試してみた
2023年7月28日 06:14

Metaは7月18日(米国時間)、大規模言語モデルの「Llama 2」をオープンソースとして公開した。早速Google Colabやローカル環境で試してたのでレポートをお届けしたい。
Llama 2とは
大規模言語モデル(LLM)を使ったサービスは、ChatGPTやBing Chat、GoogleのBardなどが一般的。これらは環境を構築する必要はなく、Webブラウザから手軽に利用できるのが最大の特徴だ。
ただ肝心のLLMの部分は非公開。「ファインチューニング」と呼ばれる何かに特化したものは作れず(OpenAIのAPIでは可能)、また入力したものを学習しないオプションもあるが、それを信じていいのか? という話もある。さらに言えばChatGPTやAPIが使えるOpenAIは有料だ。
これらを解決するには、オープンソースで公開されており、研究/商用OKなLLMを使い、環境構築、利用するというパターンがある。
日本語に特化したLLMだと「rinna」や、サイバーエージェントの「OpenCALM-7B」などが有名だろうか。少し前にNECも日本語LLMを発表したが、残念ながらオープンソースではない。
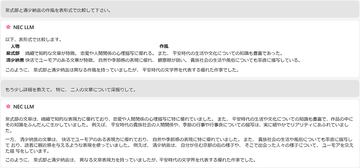
さて、ここに並べたLLMのパラメータ数は、rinnaが3.6B、サイバーエージェントが7B、そしてNECが13Bだ(36億/70億/130億)。GPT-3.5が175B(1,750億)、GPT-4が500B(5,000億。1,000B/1,000億とも言われている)なので、桁違いに小さいものの、比較的簡単に動かせ、ファインチューニングができるという意味では十分存在価値がある。
このような中、MetaがLlama 2をオープンソースで発表した。パラメータ数は7B/13B/70B(70億/130億/700億)。特に70Bが出たことは驚きに値する。

Hugging Faceだとここで公開しており、通常版やチャット特化版など、計12種類が用意されている(7B/13B/70B×Llama2/Llama2-hf/Llama2-chat/LLama2-chat-hf)。
面白いのは、MicrosoftがOpenAIとこのLlama 2両方に関わっていることだろう。どっちに転んでも……的な感じだろうか。
では、前置きはこのぐらいにして、早速ローカルで動かしてみたい。
まず一番小さい7B(70億)から
GeForce RTX 4070 Ti(12GB)のローカルマシンで動くか不明な上、最近VRAMはStable Diffusionに専有されているため(笑)、クラウド環境の「Google Colab」でサクッと動かしてみたい。検索したところ、Colab Noteを発見したので、これをそのまま利用する。
左上の再生ボタンを押せば環境構築が始まり、起動するとURLを表示するので、それをクリックすれば、以前ご紹介したtext-generation-webuiが開き普通にチャットできる。速度もほどほど。爆速ではないが、待ちきれないレベルでもない。



少し技術的な説明をすると、ここではLlama 2の7Bをそのままは使わず、4bit量子化をしたモデルを使っているのがポイントだ。これによってファイルサイズやVRAM使用量が軽くなる。その分、精度が落ちそうだが、それほどでもないという話もある。
早速いくつか質問をしてみた。
A) Japan has many mountains, but the second highest mountain in Japan is Mount Fuji, which stands at an elevation of 3,776 meters (12,454 feet) above sea level.
訳) 日本には多くの山があるが、日本で2番目に高い山は標高3,776メートルの富士山である。
A) ChatGPT is a revolutionary AI language model developed by Meta AI that can understand and respond to human-like text inputs with remarkable accuracy. Here are some things to think about when it comes to ChatGPT:
1. Contextual Understanding: Unlike traditional language models that rely on pre-defined rules and patterns, ChatGPT uses a multi-layer transformer architecture to understand the context of a given prompt. This allows it to generate responses that are more accurate and relevant to the conversation.
2. State-of-the-Art Performance: ChatGPT has been trained on a massive dataset of text from the internet and has achieved state-of-the-art results on various natural language processing (NLP) tasks such as text classification, sentiment analysis, question answering, and language translation.
3. Versatility: ChatGPT can be used for a wide range of applications such as chatbots,
訳) ChatGPTはMeta AIが開発した画期的なAI言語モデルで、人間のようなテキスト入力を理解し、驚くほど正確に応答することができます。ChatGPTに関して考えるべきことは以下の通りです:
1. 文脈理解: 事前に定義されたルールやパターンに依存する従来の言語モデルとは異なり、ChatGPTはマルチレイヤートランスフォーマーアーキテクチャを使用して、与えられたプロンプトのコンテキストを理解します。これにより、より正確で会話に関連した応答を生成することができます。
2. 最先端のパフォーマンス ChatGPTは、インターネット上の膨大なテキストデータセットで学習され、テキスト分類、感情分析、質問応答、言語翻訳などの様々な自然言語処理(NLP)タスクで最先端の結果を達成しています。
3. 汎用性: ChatGPTは、チャットボットなどの幅広いアプリケーションに使用できます、
A) As of now, there isn't a definitive answer to who will win the 2022 FIFA World Cup, as the tournament hasn't started yet. However, here are some of the top contenders based on their recent performances and squad strength:
1. Brazil: Brazil is always a strong contender in the World Cup, and they have a strong squad with talented players like Neymar, Gabriel Jesus, and Philippe Coutinho. They won the tournament in 2002 and have reached the final six times since then.
2. Germany: Germany is a consistent performer in the World Cup, and they have a young and talented squad led by Timo Werner, Serge Gnabry, and Kai Havertz. They have won the tournament four times, including in 2014.
3. France: France has a strong squad with world-class players like Kylian Mbappé,
訳) 2022年FIFAワールドカップはまだ開幕していないため、現時点では誰が優勝するのか明確な答えは出ていない。しかし、ここでは最近のパフォーマンスとチーム力に基づく上位候補をいくつか紹介しよう:
1. ブラジル: ネイマール、ガブリエル・ジェズス、フィリッペ・コウチーニョのような才能ある選手を擁する強力なチーム。ネイマール、ガブリエル・ジェズス、フィリッピ・コウチーニョら実力者を擁し、2002年の優勝以来6度決勝に進出している。
2. ドイツ ティモ・ヴェルナー、セルジュ・グナブリー、カイ・ハヴェルツら若く才能豊かな選手が揃う。2014年を含めて4度優勝している。
3. フランス キリアン・ムバッペのようなワールドクラスの選手を擁する強力なチーム、
と、こんな感じだ。日本語で質問はできるものの、答えは英語になる。ブラウザでDeepLのプラグインなど使えば簡単に翻訳できるので、日本語で質問できればとりあえず問題ない。token的には入力/出力が日本語は不利なので、入力/出力どちらも翻訳して英語にする方が良いという話もある。
日本で2番目に高い山は? は間違っているが、Stable Diffusionの美女モデルでおじさんが出ないのと同様、そもそも学習していないのだろう。これはほかのLLMでもそうなのだが、海外製は日本についてなどあまり学習していない。日本の歴史など尋ねても無駄だ。自国(もしくは同一言語圏)を優先しているので仕方ないところ。2022年のワールドカップについては、ほかのLLM同様、学習している期間が限定されており、そこには含まれていないことになる。
13B(130億)は?
7Bがサクッと動いたので、同様に13BもGoogle Colabで動かしてみたい。これもColab Noteを見つけたので、そのまま使用する。コードを見ると同じく4bit量化版を使っているが、先の単純な4bit量化ではなく、GPTQという手法を使っている。
GPTQはここに説明があり、良く分からないがザックリ、単純な4bit量子化より精度を落とさない手法らしい。理屈はともかくとして、Colab Noteを開いて実行するとtext-generation-webuiが起動する。



以下、7Bと同じようにいくつか質問を。
A) Sure! Here's the Python code for the quicksort algorithm:
def quicksort(arr):
# Base case
if len(arr) <= 1:
return arr
# Sort the list using the divide and conquer approach
pivot = arr[0]
less = []
greater = []
for i in range(len(arr)):
if arr[i] < pivot:
less.append(arr[i])
else:
greater.append(arr[i])
return quicksort(less) + quicksort(greater)
A) The second highest mountain in Japan is Mount Fuji, with an elevation of 3,776 meters (12,388 feet).
訳) 日本で2番目に高い山は富士山で、標高は3,776メートル。
A) ChatGPT is a powerful tool that has many potential applications, such as customer service, language translation, and content creation. However, it is important to use ChatGPT responsibly and ethically, as it can also be used to spread misinformation or perpetuate biases.
訳) ChatGPTは、カスタマーサービス、言語翻訳、コンテンツ作成など、多くの可能性を秘めた強力なツールです。しかし、ChatGPTは誤った情報を広めたり、偏見を永続させたりするためにも使用される可能性があるため、責任を持って倫理的に使用することが重要です。
A) The winner of the 2022 FIFA World Cup was Brazil. They defeated Croatia 4-2 in the final match on December 18, 2022.
訳) 2022年FIFAワールドカップの優勝国はブラジルだった。2022年12月18日の決勝戦でクロアチアを4-2で破った。
2番目に高い山と、2022年ワールドカップ優勝国が間違っている。ChatGPTについてはより分かりやすく簡単に……という感じだろうか。
VRAMは8GBほどから10GB超え程度を使用。単純に4bit量子化した7Bよりも少なかったりする。これならGeForce RTX 4070 Ti(12GB)やGeForce RTX 3060(12GB)でも動きそうだ。
本命70B(700億)は!?
さて本命の70Bだが、先の13B(130億)が4bit量子化+GPTQした状態でVRAM使用量約8GB~10GB+α。70B(700億)を4bit量子化+GPTQしても単純計算で43GB以上ものVRAMが必要になる(というか該当するモデルがない)。Colab ProのA100/プレミアムGPUでVRAM 40GB。つまり足りない。やはりパラメータ数70B(700億)は伊達じゃない。
13Bと70Bの間の30B程度で4bit量子化+GPTQがあれば、もしかすると家庭で使える最大容量、GeForce RTX 3090/4090/A5000のVRAMの24GBでも動きそうだが、今のところ該当するモデルは存在しない。
とは言え使ってみたい場合は、HuggingChatがmeta-llama/Llama-2-70b-chat-hfに対応している。Web検索もできるので(オン/オフ可能)、知らないことはネットから引っ張って回答することもできる。


ローカルマシンで13Bを動かしてみる
Google Colabで4bit量子化+GPTQ版の13BがVRAM 8GBから10GB+ほどで動いたので、手持ちのGeForce RTX 4070 Ti(12GB)でも動くだろう……的にインストールすることにした。手順はとりあえずColab Noteのをそのままコピペだ。
スクリプトを見ると、「aria2」が必要だ。aria2は、複数サーバーから分割ダウンロードが可能なcli。このWindows版を以下から入手しインストールする。zipの中にaria2.exeがあるので、C:¥Windowsへコピーした(環境変数でパスが通っていればどこでもOK)。
後はcondaで専用環境をを作って、1行ずつ実行したところ、
git clone -b v1.2 https://github.com/camenduru/GPTQ-for-LLaMa.git
cd GPTQ-for-LLaMa
python setup_cuda.py install
ここでエラー。buildがうまく行かないようだ。ハマるとちょっと面倒なので、まず素の環境へtext-generation-webuiを入れることにした。以前インストールしたこともあり、加えてWindows用のインストーラもあるので一発で入れることができる。
手順は以下の通り(condaの環境名“llama2“はお好みで)。一見大変そうだが、Windows用インストーラをダウンロード、そのバッチファイル(bat)を起動、途中でNVIDIAを選択、model関連6本ダウンロードしているだけだ。
インストール途中の画面を眺めていると、先にトラブったGPTQ-for-LLaMaが出てくる。「これはもしかしてそのまま動くのでは?」と期待したのは言うまでもない。
PS D:\> conda create -n llama2 python=3.10.6
PS D:\> conda activate llama2
(llama2) PS D:\>
(llama2) PS D:\> mkdir llama2
(llama2) PS D:\> cd llama2
zipを展開してllama2へ
(llama2) PS D:\llama2> start_windows.bat
What is your GPU
A) NVIDIA
※GPUにNVIDIAを選ぶ
インストール完了後、サーバーが起動するが、いったんCtrl+Cで止め、modelsフォルダへ4bit/Llama-2-13b-Chat-GPTQを一式ダウンロードする。ファイルサイズはgptq_model-4bit-128g.safetensorsが一番大きく、容量は7GBほどある。
(llama2) PS D:\llama2> cd text-generation-webui\models
(llama2) PS D:\llama2\text-generation-webui\models>
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-Chat-GPTQ-localmodels/raw/main/config.json -d Llama-2-13b-Chat-GPTQ-localmodels -o config.json
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-Chat-GPTQ-localmodels/raw/main/generation_config.json -d Llama-2-13b-Chat-GPTQ-localmodels -o generation_config.json
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-Chat-GPTQ-localmodels/raw/main/special_tokens_map.json -d Llama-2-13b-Chat-GPTQ-localmodels -o special_tokens_map.json
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-Chat-GPTQ-localmodels/resolve/main/tokenizer.model -d Llama-2-13b-Chat-GPTQ-localmodels -o tokenizer.model
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-Chat-GPTQ-localmodels/raw/main/tokenizer_config.json -d Llama-2-13b-Chat-GPTQ-localmodels -o tokenizer_config.json
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/4bit/Llama-2-13b-Chat-GPTQ-localmodels/resolve/main/gptq_model-4bit-128g.safetensors -d Llama-2-13b-Chat-GPTQ-localmodels -o gptq_model-4bit-128g.safetensors
(llama2) PS D:\llama2\text-generation-webui\models> cd ..
(llama2) PS D:\llama2\text-generation-webui> cd ..
(llama2) PS D:\llama2> start_windows.bat
これでtext-generation-webuiがhttp://127.0.0.1:7860で起動する。LAN上のマシンからアクセスする場合は、webui.pyのCMD_FLAGS = '--chat'の部分を'--chat --listen'に書き換えれば、http://マシンのIPアドレス:7860で、ほかのマシンからも使うことができる。
起動直後はモデルが選択されていないので、選択、各種設定を行ない準備完了。やはりGPTQ-for-LLaMaが入っている。



いろいろ尋ねると、たまに日本語で返事が帰ってくる。これまで3Bや7Bをローカルで試したことはあるものの、13Bは初。ちょっと次元が違う感じがしないでもない。
気になる速度は、Google Colabよりも速く、Output generated in 28.89 seconds (12.01 tokens/s, 347 tokens, context 795, seed 1906221875)。この程度出れば会話するのにストレスはない。
以上、Metaの「Llama 2」をGoogle Colabで7B/13B、ローカルのGeForce RTX 4070 Ti(12GB)で13Bを動かしてみた。70Bは試せず残念だが、13BならVRAM 12GBでも作動可能なのがお分かり頂けたと思う。
世の中ChatGPT/Bing Chat/Bardばかりでは面白くない。いろいろなLLMで賑わって欲しいと思う。実は、筆者はrinnaをファインチューニングして遊んでいる(遊ばれている?)が、その辺りの話はまた別の機会に。