福田昭のセミコン業界最前線
AIプロセッサ「MI350」や「Spyre」、37.6Gbit/平方mmの超高密度フラッシュなどがISSCC 2026で披露
2026年2月10日 06:25

半導体集積回路の研究開発成果に関する世界最大規模の国際学会「ISSCC(International Solid-State Circuits Conference)」が、今年もまもなく開催される。開催期間は2026年2月15日~19日、開催場所は米国カリフォルニア州サンフランシスコのMarriott Marquisホテルである。
ISSCC(ISSCC 2026)の開催概要は、本コラムですでにご報告した。今回は注目の発表をご紹介する。
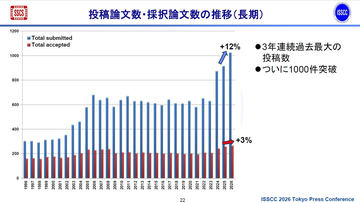
AMDの最新GPU「MI350」やIBMのAIアクセラレータ「Spyre」など
はじめはプロセッサの注目発表を説明しよう。5件の研究開発成果を採り上げた。いずれもAI用途のGPUやアクセラレータなどのチップ、あるいはパッケージ(モジュール)である。
AMDは、最新世代のAI向けGPU「Instinct MI350シリーズ」の技術概要を発表する(講演番号2.1)。CDNA4アーキテクチャを採用した。6nmノードの入出力ダイ(IOD)の上に、3nmノードの計算ダイ(XCD)を4つ水平に並べて搭載する。積層済みダイ群(チップレット)を主記憶のHBMモジュールとともに同じパッケージに収容した。理論的なピーク性能は前世代と比べて1.9倍に向上し、HBMの入出力帯域幅と記憶容量はいずれも1.5倍に拡大(同じ実装面積当たり)した。
Rebellions(韓国)は、AIの大規模推論に向けたチップレット構成のサブシステムを開発した(講演番号2.2)。チップレット間の接続(メッシュ接続)にはUCIeを採用した。メッシュ接続の転送速度は16Gbpsを超える。サブシステムは4nmノードのニューラルネットワークプロセッサ(NPU)、HBM3Eモジュール、シリコン集積化キャパシタなどで構成する。大規模言語モデルLlamaバージョン3.3(700億パラメータ)においてシングルバッチ2k/2k入出力シーケンスを実行したときの性能は56.8TPS(トークン/秒)。
IBMは推論向けに最適化された、スケーラブルで電力効率の高いAIアクセラレータ「Spyre」の研究成果を述べる(講演番号2.6)。シングルスロットのPCIeカードにサブシステムをまとめた。高度な電力管理機能、低精度浮動小数点データ形式のサポート、高スループットのメモリサブシステムなどを備える。5nm CMOS技術で製造したシリコン面積が330平方mmのアクセラレータ・ダイには260億個のトランジスタを搭載した。最新のGPUと比べ、32%高いスループットと2~3倍のエネルギー効率を達成したとする。

MediaTekは、拡散畳み込みニューラルネットワーク(ConvNet)の実行時に7.4TOPS/平方mm、17.4TOPS/Wの性能を有する生成拡散アクセラレータ「MADiC」を発表する(講演番号2.8)。3nmプロセスで製造するシリコンの面積は0.338平方mmとかなり小さい。エッジ端末の生成画像編集に向けて開発した。
NVIDIAは、顔検出の遅延時間が787μs、消費電力が4.6mW(60フレーム/秒)で常時オンのリアルタイム画像プロセッサ「ALPhA-Vision」を開発した(講演番号31.9)。16nmノードで製造したダイのシリコン面積は4.20平方mm。顔検出精度は99.3%で、まだ改善の余地がある。
37.6Gbit/平方mmの高密度NANDフラッシュとHBM4準拠の高速大容量メモリ
続いてはメモリの注目発表である。5件の研究開発成果を採り上げた。最初の1件が3D NANDフラッシュメモリ、残りの4件がDRAMの成果発表となる。
Sandiskとキオクシアは共同で、記憶密度が37.6Gbit/平方mmと高い3D NANDフラッシュメモリを開発した(講演番号15.1)。シリコンダイの記憶容量は2Tbitと大きい。ワード線の積層数は332層、多値記憶方式は4bit/セルである。メモリセルアレイを6個のプレーンに分割して読み書きの性能を高めた。書き込みスループットは85MB/sと高く、読み出しレイテンシは65μSと短い。

Samsung Electronicsは、記憶容量が36GB(288Gbit)、データ転送速度が3.3TB/sのHBM4規格準拠DRAMモジュールを発表する(講演番号15.6)。第6世代の10nmノードで製造した記憶容量24GbitのDRAMダイ(コアダイ)を12枚、TSV(シリコン貫通ビア)接続で積層した。入出力データ本数は2,048本と前世代HBM(HBM3E)の2倍に増えた。ベースダイ(ロジックダイ)は4nmノードのFinFET技術で製造した。入出力当たりのデータ転送速度は13.2Gbpsと高い。コアダイの適応型ボディバイアスとチャンネルごとの自動較正によって高い転送速度を達成している。
SK hynixは、入出力ピン当たりのデータ転送速度が14.4Gbpsと高い16GbitのLPDDR6 SDRAMを開発した(講演番号15.7)。製造技術は1c世代(1γ世代)の技術ノードである。LPDDR6独自の低消費電力モード、LDO(低降下電圧レギュレータ)ベースの書き込みクロックツリー、無終端とオンダイ終端を動的に切り換える書き込み動作、高速チップセレクト制御、システムメタモードなどの要素技術を組み込んだ。
Samsung Electronicsは、入出力ピン当たりのデータ転送速度が12.8Gbpsと高い16GbitのLPDDR6 SDRAMを発表する(講演番号15.8)。12DQサブチャンネルのワイドNRZデータ入出力、行(Row(ロウ))ごとのアクチベーションをカウントする機能(ロウハンマー不良対策)、メタデータスキームをサポートする。
SK hynixは、入出力ピン当たりのデータ転送速度が48Gbpsと高い24GbitのGDDR7 DRAMを開発した(講演番号15.9)。ミッドレンジのAI推論用途に向けた。対称型2チャンネルモードの動作機能、クロックパスの最適化機能、RAS機能などを搭載する。
26mWの低消費Ge-on-Siイメージセンサーと2億画素のCMOSイメージセンサー
次はイメージセンサーの注目発表である。4件の研究開発成果を採り上げた。自動車の先進運転システムを支えるLiDARのレシーバ、AR/VRヘッドセット向けの低消費センサーアレイ、8Kビデオ撮影向けの高解像度イメージセンサーなどが登場する。
STMicroelectronicsは、視野角(FoV)が54度✕42度、解像度が52✕42チャンネル、フレーム速度が60フレーム/秒(fps)のLiDARレシーバを発表する(講演番号7.1)。3次元積層技術と65/40nmCMOS技術によって220×198個の裏面照射SPADアレイ、ピクセル内時間デジタル変換(TDC)回路、距離測定(ToF)と強度測定のデュアルカウンタ、オンチップメモリを集積した。25V出力の昇圧回路をチップとパッケージに分けて搭載する。レシーバの消費電力は153mW(60fps)。距離測定誤差が1cm未満の測定可能距離は最長9.6m。
ソニーセミコンダクタソリューションズは、400×300画素で10μmピッチのゲルマニウムオンシリコン(Ge-on-Si)SPADセンサーアレイを開発した(講演番号7.5)。低消費電力のAR/VR向け。室温で動作する。フレーム速度が30フレーム/秒のときに消費電力は26mWと低い。受光波長1300nmのときに光子検出効率(PDE)は5.1%。測定距離10m(直接ToF方式)の距離測定誤差は3cm未満。プログラム可能なマクロピクセルとオンチップヒストグラム機能を備えており、最大で500個のマクロピクセルを選択的に活性化する。

Samsung Electronicsは、低雑音の1,200万画素等価グローバルシャッタ方式CMOSデジタルイメージセンサーを発表する(講演番号7.9)。4つの画素(2x2配列)が1個のアナログデジタル変換器(ADC)を共有する。画素ピッチは1.5μm。4つの画素を定時間隔でデジタル化する4相ジグザグ読み出し。動き補償を内蔵する。雑音レベルは平均固定パターン雑音(FPN)が0.65e-rms、ランダム雑音が1.09e-rms(アナログ利得16)と低い。
SmartSens Technologyは、画素ピッチが0.61μmで画素数が2億画素と多いCMOSイメージセンサーを開発した(講演番号7.10)。高品位ビデオ撮影用。40nm技術のダイと22nm技術のダイを積層する。裏面照射型。デュアルコンバージョンゲイン(DCG)読み出しアーキテクチャ、2x2画素を共有するアーキテクチャなどを採用した。変換利得は275μV/e-(0.7e-の読み出し雑音に相当)。モーションアーチファクトフリーの高ダイナミックレンジ(HDR)画像合成、60フレーム/秒の8Kビデオ撮影をサポートする。
AIチップの技術概要をNVIDIAやMicrosoftなどが招待講演で説明
最後はAI関連チップの招待講演である。「Highlighted Chip Releases for AI (注目のAI向けチップ)」と題する招待講演セッションで、開発企業がAIチップの技術概要を述べる。全部で4件の講演を予定する。
はじめに、NVIDIAがデスクトップAIスパコン「DGX」用プロセッサ「GB10」の概要を述べる(講演番号17.1)。20個のArmv9.2コアを内蔵するCPUダイとデスクトップ向けに調整したBlackwell iGPUダイを1つのパッケージに収容した。iGPUは第5世代Tensorコアと第4世代RT(レイトレーシング)コア、24MBの2次キャッシュを内蔵する。演算性能はFP32で31TFLOPS、FP4で1PFLOPS。製造技術はいずれのダイもTSMCの3nmプロセスである。
続いてSTMicroelectronicsが、Arm Cortex-M55 CPUと、自社製NPU(Neural-ART NPU)を内蔵するマイクロコントローラ「STM32N6ファミリ」の概要を説明する(講演番号17.2)。エッジAI応用を狙った。1GHz動作のNeural-ART NPUは、600GOPSと3TOPS/Wの性能を実現する。追加のコプロセッサは、グラフィックス/ビデオ/画像処理を高速化し、非長方形ディスプレイの処理を最適化した。製造技術は16nmのFinFET。

それからMobilint(韓国)が、AI推論アクセラレータ用NPUファミリに共通のNPUコアをハード/ソフト協調設計によって開発した成果を述べる(講演番号17.3)。オンプレミス向けアクセラレータ「ARIES」は、4コアのNPUクラスタを2つ内蔵する。製造技術はSamsungの14nmプロセス、シリコン面積は181平方mm。オンデバイス向けアクセラレータ「REGULUS」はシングルコア構成。製造技術はTSMCの12nmプロセス、シリコン面積は50平方mmと小さめ。
最後にMicrosoftがAIアクセラレータ「MAIA」(MAIA 100とみられる)のアーキテクチャと実装を解説する(講演番号17.4)。レチクルサイズ(約800平方mm)のパッケージ技術、750Wの消費電力を供給および放熱する機構、物理設計手法、検証手法などを述べる。
このほかにも興味深い講演が少なくない。あいにく予算の関係で筆者は現地取材を予定していない。オンデマンドによって講演を視聴し、レポートをお届けする予定なので、ご期待されたい。