大原雄介の半導体業界こぼれ話
リアルモードなどを廃止したIntel「X86-S」計画の断念、そしてQualcomm対Arm訴訟の現状
2024年12月24日 06:18

のっけからいきなりIntelのパット・ゲルシンガー氏解任でスタートした12月。今さら解説する必要もないだろうから細かく触れるつもりはないが、そもそもブライアン・クルザニッチ氏がCEOを解任された後、CFOのボブ・スワン氏が暫定CEOに就いたものの後任が決まらず、2年半あまりCEO職を務めたことを考えると、すぐに後任が決まるとは考えにくい。だとすると、またIntelは貴重な時間を失うのだろうか。
もしIntelがなくなるとしたら、それは競合に負けたとかではなく、自壊したということになるのだろうな、とつらつら感じたりする。
X86-Sイニシアチブ
Tom's Hardwareが12月20日に報じたところによれば、IntelはX86-Sイニシアチブを断念したそうだ。
X86-Sイニシアチブについては以前に触れているが、端的に言えば16bitモードの切り捨てである。あくまで捨てるのは16bitモードのみで、16bit命令が捨てられるわけではない。

当初Intelは、これを自社で進める予定であったが、今年(2024年)10月にx86 Ecosystem Advisory Groupが結成された以上、こうした大規模な仕様変更はIntel単独で行なうのではなく、x86 Ecosystem Advisory Groupに持ち込むのが筋である。まだX86-Sのページは残っているが、最終更新日付は2023年5月18日のままである。
ちなみにFRED及びAVX10に関しては、引き続きイニシアチブが進行中という話であったが、こちらも遠からずx86 Ecosystem Advisory Groupに持ち込まれることになるかと思われる。

現在のx86のマーケットシェアで、既にAMDは3割近い。またX86-SにしてもFRED/AVX10にしてもパートナーエコシステムを無視して進めるのは無理である。これらの利害関係者が一堂に集まるところに仕様を提示するのが一番賢明かつ効率的な方法だと思うからだ。
Arm vs Qualcomm、法廷闘争の現状

これを書くに至って過去記事を参照しようとしたら、意外にもPC Watchではあまり報じられていなかったようなので、まずは簡単に経緯をご紹介する。
2021年、Qualcommは米国のNuviaを買収し、同社の開発していたCPUコアを入手する。ところがArmはこの買収は同社のライセンス違反にあたるとして2022年8月、デラウェア州連邦地方裁判所にQualcommとNuviaを提訴する(case number 1:22-cv-01146)に至る。

長らくこの状態が続いたが、2024年4月にQualcommはやはりデラウェア州連邦地方裁判所に反訴(case number 1:24-cv-00490)。いろいろ泥沼化の様相を呈してきた。これに対し今年10月24日、ArmはQualcommに対してアーキテクチャライセンス契約の解除に定められている60日前の通告を実施したことがBloombergなどで報じられた。つまり12月24日に、Qualcommの保有するアーキテクチャライセンスが無効となるということになる。
さてそんな状況が続いた12月20日、デラウェア州連邦地方裁判所はQualcommがArmとのライセンスを遵守している、という判断を下したことをBloombergが報じた。もっともこの判断、Qualcomm自身はArmとのライセンス契約、および商標権を侵害してはいないとしたものの、ArmとNuviaの間のライセンス契約に関しては陪審員の意見が一致しなかったとしており、なのでまだ再審理あるいは交渉の余地が残るものになっている。
Qualcommはこの結果を受けて声明を発表している一方、Armは現時点では何も声明を発表していない。ただこの裁判所の判断は、ライセンス契約解除の根拠を失うものと考えられる。なので、もしArmがライセンス契約解除を強行した場合は、ライセンス契約解除が無効である訴えをQualcommが起こすことは間違いないだろう。ただその一方でまだArmが訴えを取り下げるとも思えない。上に書いたように、ArmとNuviaのライセンスに関しては今回評決不一致となっており、おそらくはこの部分に関してArmは改めて裁判を提起するか、もしくは再訴することになると思われる。
そんなわけでこの争いは来年(2025年)以降も持ち越しになるのはほぼ確定した形だ。最終的にどういう形で決着するのかを読むのは筆者には荷が重すぎるし、いつ決着がつくのかを予測するのも無理である。
ただ1つ言えることは、現状ArmがWindows PCのマーケットに参入するのはQualcommの助けなしには無理ということだ。
たとえばMediaTekも、ようやくChromebookのマーケットに“参入できている”に過ぎない。5月にMediaTekがNVIDIAと共同でAIPC向けチップセットを開発するのでは?という予測記事が台湾経済日報に掲載されたが、少なくとも今年のCOMPUTEXではそういう話は一切出てこなかったし、MicrosoftもMediaTekの基調講演には呼ばれていなかった。
そしてこの訴訟問題が解決するまで、ArmとQualcommがAIPCマーケットの参入に関して協力することはありえないだろう。そのArmはCOMPUTEXにおける基調講演の後の質疑応答で、2030年までにWindowsプラットフォームでArmが大多数になるという楽天的な予測を示したが、それを本気でやるつもりならこの問題の早期解決を図らないといけないようにも思える。さて、どう転がるのだろうか?

UALinkのアップデート
10月の記事で、UECが意外に早く立ち上がりそうという話をご紹介したが、もう1つUALinkも意外に迅速に立ち上がりそうだ。というのは12月11日、SynopsysがUALinkとUECのIP、及びVerification IPの提供を開始することをアナウンスしたからだ。

UALinkが何か?という話は以前の解説記事をご覧いただくのが早いが、要するにGPUやAIアクセラレータ同士の接続に向けたインターコネクトである。たとえばIntelだと「Data Center GPU MAX」同士の接続にXeLink、AMDだとInfinity Fabricを利用して接続しているが、これは各社の独自のインターコネクトである。ちなみにそのIntelもGaudi 2/3はEthernetを利用した独自Link(物理層はEthernetだが、その上に独自プロトコルを通している)での接続となっている。これを統一のOpenな規格にしよう、というのがUALinkの目的である。
ではUECとUALinkをどう使い分けるかという話になるわけだが、Samuel Naffziger氏(SVP&Corporate Fellow&Product Technology Architect, AMD)曰く「シャーシ内部の接続がUALink、シャーシ間の接続がUEC」という使い分けになるのだそうだ。
ただUALink 1.0のリリースを読むと、「1.0 仕様では、AIコンピューティングポッド内で最大1,024個のアクセラレータの接続が可能になり、ポッド内のGPUなどのアクセラレータに接続されたメモリ間での直接ロードとストアが可能になります(Google翻訳)」とあって、さすがに1つのシャーシ内に1,024ものGPUを収めるのは無理だと思われるのでシャーシ間も考えているようだ。また「このグループは、AIコンピューティングポッド内のアクセラレータとスイッチ間のスケールアップ通信のための高速かつ低遅延の相互接続を定義する仕様を開発します」なんて表現もあるから、UALink Switchも登場することになる。もちろん小規模なPCIeスイッチみたいにチップで提供できるものもあるが、先の台数と併せて考えると、どう考えてもシャーシ外の接続もサポートしているとしか思えない。
そもそも「ポッド」という表現がなされているが、通常ポッドは1台ないし複数台のラックで構成されている(例:NVIDIA DGX SuperPOD)ことを考えると、現実にはシャーシというよりは複数台のラックから構成されるポッドの内部をUALink、ポッド間の接続がUECというのが現実的な目標なのだろう。
実際Kurtis Bowman氏(Director, Architecture and Strategy at AMD)が2024年11月に開催されたSC24におけるUltra Accelerator Link Consortiumの展示の写真をLinkedInに上げているが、最低でもシャーシ内、ひょっとするとシャーシ間の接続もカバーしているように見える。
ちなみに先の記事では2024年第3四半期にUALink 1.0の仕様が貢献したメンバー会社に配布予定だったが、どうも年内中(といってももう残りわずかだが)にリリースになったようだ(Bowman氏の上げた写真にも、「年末にリリース予定」になっている)。ただパブリックリリースが2025年第1四半期という予定は変わっていないし。そもそもSynopsysがIPをリリースしている時点で、ドラフトレベルであってもかなりバージョンが上がっている(IEEE風に言えばドラフト5.0とか6.0とかそういうレベル。PCI-SIG風ならドラフト0.9あたりだろう)と思われるので、大きな問題はないかと思う。
またUALinkの結成にあたり、AMDがInfinity Fabricの仕様を寄贈した(Naffziger氏によれば「寄贈したのはInfinity Fabricのフルスペックではなくサブセット」とのことだった)とあるが、その一方でUltra Accelerator Link Consortiumの「About UALink」ページを見ると、「IEEE P802.3djをベースとした物理層」という表記がある。
IEEE P802.3djはInternet Watchの記事で紹介しているが、レーンあたり200Gbpsの200/400/800/1600G Ethernetの規格である。

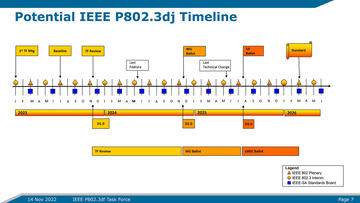
もっともIEEE P802.3djは「光Ethernet」であって、一方UALinkはあくまでも電気的な接続を念頭に置いている。なのでここで言う物理層というのはおそらくPMA(Physical Medium Attachment)層の仕様を指すものと思われる。
200Gbpsの信号を1本のレーンで、しかもチップレットの接続に使う数mm程度ではなく、ラック内のシャーシ間とかで通す(ということは最長数mのケーブルが必要)というのは現在の技術では論外であって、今だと56G PAM4×2、あるいは56G NRZ×4で200Gbpsを構成する格好になる。で、Bowman氏の上げた写真の中に「ピンからピンまで150ns未満になる見込みの低レイテンシスイッチ」とか書いてあって、これを実現しようとするとPAM4は不利になることを考えると、56G NRZ×4の構成がありそうなパターンかと思われる。
ここで疑問になるのは、UALinkにInfinity Fabricの仕様(のサブセット)を寄贈したという話である。物理層がこの56G NRZ×4だとすると、では寄贈したのは上位のプロトコルという意味なのか、それとも実はInfinity Fabricが56G NRZ×4で1レーンを構築しているという意味なのか。ただSynopsysのUALink IP Solutionの図を見ると、UALinkの規定はPHYまでで、その上位はアプリケーション任せになっているようにしか見えない。
少しずつ中身が見えてきたことで、かえって中身が分からなくなりつつあるUALink。仕様のパブリックリリースが待ち遠しい。