西川和久の不定期コラム
Suno級の音楽生成AIがローカルで使い放題?「HeartMuLa」を試した
2026年1月29日 06:07

Sunoは、キーワードとジャンル的なタグを与えるとボーカル付きの音楽を生成するAIサービスだ。一部TVやラジオ番組などでも取り上げられているほど有名で、完成度も高く、すでに使われている方も多いと思う。これをローカルで対抗しうるモデル「HeartMuLa」がリリースされたので試用レポートをお届けしたい。
HeartMuLaとは!?
2026年1月14日にリリースされた「HeartMuLa」は、北京大学を中心とした研究チームによって開発された音楽生成AIで、以下4つのモデルから構成されている。
- HeartCLAP: 音声とテキストの整列モデル
- HeartCodec: 音楽コーデックトークナイザー
- HeartMuLa: 楽曲生成モデル。最大6分間の長尺音楽生成に対応
-英語、中国語、日本語、韓国語、スペイン語
-スタイル記述、歌詞、参照オーディオなど、制御条件下で音楽を合成 - HeartTranscriptor: 歌詞認識モデル
実際今回紹介する音楽生成は、HeartCLAP+HeartCodec+HeartMuLaを使う。HeartTranscriptorは音楽から歌詞の抜き出し(テキスト)用だ。
HeartCLAP+HeartCodec+HeartMuLaに与えるデータは、“歌詞”と“スタイルタグ”の2つ。後者はRock、J-Popなど楽曲のジャンル、Pianoなどの楽器を指定できる。すべてのスタイルタグを掲載すると長くなるのでここにまとめてある。興味のある人は参考にしてほしい。
つまり、歌詞とスタイルタグを指定すればボーカル付きの音楽が生成される……まさにSunoのローカル版だ。
さらに注目すべきは日本語対応!日本語の歌詞を入れれば、女性ボーカル/男性ボーカル問わず流暢な日本語で歌い出す。
モデルはここにあり、現在3Bが2種類登録されている。
HeartMuLa/HeartMuLa-RL-oss-3B-20260123
HeartMuLa/HeartCodec-oss-20260123
HeartMuLa/HeartMuLa-RL-oss-3B
HeartMuLa/HeartCodec-oss
HeartMuLa/HeartMuLaGen
HeartMuLa/HeartTranscriptor-oss
3Bと3B-20260123をどちらも試したところ、後者の方がスタイルタグの効きや音が良いような感じか!?リポジトリを要約すると、
- タグで指定したスタイルにより正確に従う
- 音楽のジャンル、ムード、楽器指定などがより明確に反映される
とのことらしく、筆者の試用感覚と一致。よって、現時点では3B-20260123推奨となっている。ちなみに、RLは強化学習(Reinforcement Learning)の意味だ。
また、執筆時点では未公開だが7Bも存在し、関係者によるとこちらはかなりSunoに迫るらしい。ぜひともオープンで公開してほしいところ。ライセンスはApache-2.0。
さて、これまでいくつかローカル生成によるミュージックビデオ(MV)を掲載したが、肝心の音楽はすべてSunoで作っていた。せっかくリップシンク可能な動画がローカルで生成できるにも関わらず、音は外部サービス任せだったというわけだ。
これがHeartMuLaの登場により、真に100%ローカル生成可能に!……というのが今回のお題。順追って説明するが、100%ローカルで可能になったため、ポイント消費や利用制限を気にすることなくMVを作れるのはいいものの、時間が溶ける溶ける……(笑)。
ComfyUIで試す
まずComfyUIのHeartMuLa Custom Nodeが公式から出ているのでこれを使ってみる。
$ cd ComfyUI/custom_nodes/
$ git clone https://github.com/benjiyaya/HeartMuLa_ComfyUI
$ cd HeartMuLa_ComfyUI
$ pip install -r requirements.txt
モデルのダウンロードは
$ cd ComfyUI/models/
$ hf download HeartMuLa/HeartMuLaGen --local-dir ./HeartMuLa
$ hf download HeartMuLa/HeartMuLa-RL-oss-3B-20260123 --local-dir ./HeartMuLa/HeartMuLa-RL-oss-3B-20260123
$ hf download HeartMuLa/HeartCodec-oss-20260123 --local-dir ./HeartMuLa/HeartCodec-oss-20260123
$ hf download HeartMuLa/HeartTranscriptor-oss --local-dir ./HeartMuLa/HeartTranscriptor-oss
以上4つのファイルをダウンロードする。もし古い3Bも試してみたいなら(Nodeで切替可能)、以下2つもダウンロードすればOKだ。
$ hf download HeartMuLa/HeartMuLa-oss-3B --local-dir ./HeartMuLa/HeartMuLa-oss-3B
$ hf download HeartMuLa/HeartCodec-oss --local-dir ./HeartMuLa/HeartCodec-oss
ComfyUIでのWorkflowは簡単で、HeartMuLa Music GeneratorからPreview Audioへ接続するだけ。
ほかのパラメータだが、最大時間は秒で指定するところ。たとえば240だと4分になる。ただし、これはきっちり4分の曲を作るのでなく、歌詞の内容に沿って生成するため多くはこれ未満になる。逆に60とかだと尻切れトンボになってしまうことが多い。Temperature: 1.0、Top-k: 50、CFG scale: 1.5はデフォルトのままでいいだろう。
取り急ぎ、適当にメモ書き程度の歌詞と、スタイルタグを入れ動作を確認したものの、歌詞はいったい誰が作るのか?問題が発生する。もちろん書ける人は思いつくまま入力すればいいのだが、筆者にそんな才能はない(笑)。

そこで思いついたのが、キーワードを与えると、歌詞とスタイルタグを自動的に作ってくれるCustom Node。もちろんLLMを併用する。
Claude Codeを使いリポジトリを解析させ、キーワードから歌詞とスタイルタグを生成できるようなシステムプロンプト(System Prompt)を作り、それをカスタムノード(Custom Node)へまとめ、GitHubへ公開した。

LLMはOpenAI API形式のendpointを指定。筆者の場合はM4 Maxで動いているLM Studio+gpt-oss-120bにしているが、ここは20bなどもっと小さいモデルでも日本語さえ理解できれば問題ない。環境に合わせて設定してほしい。モデルごとに“味”が変わるかもしれないので、何種類か試すのもありだろう。
試しに“雪 女性ボーカル 渋谷スクランブル交差点 明るい曲 アップテンポ”とすると、以下のような出力となった。
[Intro]
街の灯がリズムを刻む シンセが鳴り出す
[Verse]
渋谷の交差点で降る小さな雪
足元に光のビートが跳ねてく
心はウインドウ開けたように広がり
[Chorus]
手を伸ばせば届くメロディー
笑顔と風が踊るよ アップテンポで
夜空に描く白い星座、私の歌
[Verse]
信号が青になるたびに胸が高鳴り
人波の中でも君だけ見える
雪の結晶はリズムのアクセント
[Chorus]
光と音で繋ぐストーリー
明るく走れ、渋谷の星へ
この瞬間を永遠に刻んで
[Outro]
最後のコードが消えるまで 歌い続けよう
Pop,Bright,Female,Happy,Synthesizer,Drum,Dance,Asian,Dream
これなら、作詞できない筆者でも何とかなる(笑)。以下、HeartMuLa Music Generatorが生成した音楽だ(映像はイメージ静止画+MP3的な動画)。
いかがだろうか?GeForce RTX 5090を使うと、たった約99秒で2分31秒の音楽ができてしまう。女性ボーカルもなかなか(音楽関係者曰く、ピッチ調整しなくていいので最高ー!笑)。これが筆者のように昔少しバンドをやってたとは言え、作曲はコード進行程度、作詞できない的な人でもローカルでできてしまう。実力がある人なら元ネタにして、別の曲を作ることも可能。凄い時代になったものだ。
SunoそっくりなHeartMuLa-Studioを使う
先の環境でしばらく遊んでいると、SunoそっくりなUIを持つHeartMuLa-Studioが公開された。UIはキャプチャをご覧いただくと分かる通り、本当にSunoそっくり!(笑)。


起動方法だが、Dockerを使うのと、Python(
バックエンド)とnpm(フロントエンド)をCLIから起動……この2パターンがある。Windows環境では前者、DGX Spark互換機では後者での動作を確認した。なお、DGX Spark互換機でDockerを使うとビルド中にArm版がないライブラリがあるらしくエラーとなってしまう。
ちょっと気になる点があったため、issueに入れてあるが、
- シングルGPUだと無条件でHeartCodecがCPUで実行される=遅い
- HeartMuLa-RL-oss-3B-20260123を使っているにも関わらずCodecがHeartCodec-ossになっている。-20260123に合わせる必要がある
1はVRAM容量が十分ある場合CUDAで実行したい。修正箇所は、こちらの816行辺り
else:
# Without quantization, use lazy loading - codec stays on CPU
pipeline = HeartMuLaGenPipeline.from_pretrained(
model_path,
device={
"mula": torch.device("cuda"),
"codec": torch.device("cpu"), # "cuda"へ
},
dtype={
として、4bit化とoffloadをfalseにして起動する。
HEARTMULA_4BIT=false HEARTMULA_SEQUENTIAL_OFFLOAD=false python -m uvicorn backend.app.main:app --host 0.0.0.0 --port 8000
2は、同じコード内、こちらの33行辺り
HeartMuLa-oss-3BとHeartMuLa-RL-oss-3B-20260123は、MODEL_VERSIONSで切り替えているのに、HF_HEARTCODEC_REPO = "HeartMuLa/HeartCodec-oss"は固定になっている。-20260123を使うならここを"HeartMuLa/HeartCodec-oss-20260123"に書き換える。
と、こんな感じだ。あくまでも執筆時の情報なので、後日修正されるかも知れない。行番号などは参考程度に。
アプリを起動する前にOllamaを先にサーバーモードで動かし、適当なLLMをpullしておく必要がある。これは筆者の作ったCustom Nodeと同じく、キーワードから歌詞とスタイルタグをLLMから生成する仕掛けに利用する。
現在のところ見栄えはいいが、起動が少し面倒なのと、できることはComfyUIでの動作と大差ないので(作った曲が一覧で並ぶ程度?)、個人的にはComfyUI環境でHeartMuLaを試すことをお勧めしたい。
100%ローカル生成のMVを作る
さて、音楽ができたらやることは1つ!LTX-2 S2Vを使ったMV制作となる(笑)。前回は追記で後から掲載したこともあり、今回はWorkflowも含め作り方を説明したい。
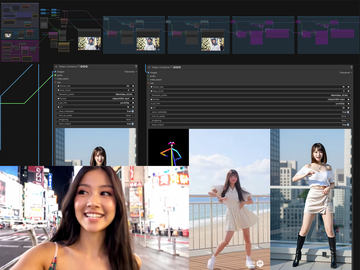
- 音楽を作り、Aメロ、Bメロ、サビなどのstart時間/end時間を把握する
- 例えばAメロ、Bメロ、サビ、ここで映像を切り替えるなら、リファレンス画像を3枚用意。顔など一貫性が必要な場合は顔LoRAを使うか(今回のケース)、Edit系のモデルを利用して画像を生成
- Aメロの部分だけS2V、Bメロの部分だけS2V、サビの部分だけS2V
- 3本結合する。この時、音がズレてないか、オリジナル音源と同時再生して確認(ズレてると音にエコーがかかる)
と、こんな感じだ。まず先と同様、ComfyUI+ComfyUI-LyricForge+HeartMuLa Music Generatorで作った音楽だけをフルで掲載する(映像は固定)。
次に各パートのリファレンス画像を用意する。今回6パートあるので6つだが、最初と最後が同じなので実際は計5つ。この辺りは実際繋げながら雰囲気を見るので一気に5枚作っているわけではない。






LTX-2 S2VのWorkflowは以下の通り。workflowのjsonをzip化したのをここ(右クリックや長押しの「リンク先を保存」などをお使いください)に貼るので参考にしてほしい。


LTX-2の基本部分で触っているのが、
- モデルは蒸留版を使わず、ベースモデル+蒸留LoRA(0.6)にしていること
- 通常指定解像度の2分の1のサイズで8 steps+後からx2を3 steps、つまり元の解像度に戻すためUpscaleしているのだが、ここでは指定解像度のまま8 stepsに
この2点。1は、蒸留モデルは効きが強すぎる感じがあり、ベースモデル+蒸留LoRA(0.6)として弱めている。
2は普通の方法だと解像感が落ちるような雰囲気があるため、あえて指定解像度のまま生成している。ただしこの場合、時間やリソースが余計にかかる。加えて動きが若干鈍るという話もある。好みでWorkflowを触った方がいいだろう。
多くはLTX-2 I2Vなのだが、S2V固有の物として左上に赤い背景のAudio部分がある。これはMel-Band RoFormerというモデルを使い、ボーカルと演奏などを分離する仕掛けだ。Mel-Band RoFormer Samplerを見ると出力にvocalsとinstrumentsの2つがあるのが分かる。
それぞれにAudio Adjust Volumeがあり、ボーカルは1、演奏は-100。つまりほぼボーカルのみの音を作っている。これは余計な音が入るとリップシンクしなくなるための対策だ。
ただし、リファレンス画像と曲によっては演奏を軽く乗せないとリズム感が出なかったり、ドラムのスティック捌きが合わなかったりするため(今回は間奏で-3へ)、音楽と出力された映像で調整が必要なケースもある。
できた6つの映像、手元にiMovie程度しかアプリがなく、これを使って編集している。主に連結なのだが、どうしても音ズレが発生するため各パート少し長め=マージンを持たし、元の音源を置き同時に再生、つなぎを調整……という面倒な作業となる(ズレるとエコーなどが発生する)。ここが無調整で連結できれば作業時間を大幅に短縮できるのだが……。
ズレをなくした後、映像側の音を削除、オリジナルの音源をそのまま使い、MP4で出力。この時はHDとなるため、アプリ(Unsqueeze)を使いフルHDにアップスケールし完成となる。

数箇所気になる部分が残っているが、リファレンス画像やPromptを変えながら動画をガチャったり、連結しては一部入れ替え……などを繰り返しここまでで8時間(笑)。AIを使い尺2分ほどとはいえ、実は楽な作業ではない。
もともとHD解像度で生成している関係もあり、細部が崩れたり指など怪しい部分もあるにはあるが、100%ローカルPCでここまでできるようになったのはお分かりいただけたと思う。
以上のように、HeartMuLaの登場により、Sunoを一切使うことなく、完全に100%ローカルでMVを制作可能になった。(細かいことをいい出せばまだまだだろうが)クオリティもご覧の通り。数カ月前まではちょっと考えられなかっただけにこの進歩は嬉しい限り。
しかも、2026年1月時点でこの状態。今年年末にはどうなっているのか?まったく想像がつかない。この手の制作が好きな人はどんどん時間を溶かしてほしい(笑)。