西川和久の不定期コラム
PhotoshopとStable Diffusionで生成AI対決。ジェネレーティブ塗りつぶしを試してみた
2023年5月31日 06:12

Adobeは5月23日、生成AIエンジン「Firefly」を活用した生成AI機能をPhotoshopへ組み込むことを発表し、既にPhotoshopのベータ版で利用可能になっている。試したところ、写真関連のワークフローをすべてひっくり返しそうな機能だったので、作例などを含めてご紹介する。さらに、Stable Diffusionとの比較についても書いたので、あわせてご覧頂きたい。
筆者の近況
本論に入る前に、筆者のローカル環境の話をしたい。3月、外付けGPUボックスにGeForce RTX 3070 Ti(8GB)を入れ、Ryzen 9搭載のミニPCでStable Diffusionを動かす話を書いた。そのとき触れているが、このGeForce RTX 3070 Tiは編集担当からの借り物だったこともあり、後釜としてGeForce RTX 3060(12GB)かNVIDIA RTX A4000(16GB、中古)かを悩んでいたところ、年度末日に何故か予算の倍(!)となるGeForce RTX 4070 Ti(12GB)を購入した。
というわけで、現在はGeForce RTX 3070 Tiを返却し、GeForce RTX 4070 Tiに入れ替えて使っている。メインのCore i9-12900搭載PCでも15万円するかしないかなのに、GPU単体に約14万円とは、清水の舞台から飛び降りるといった気分だ(笑)。

もちろん対費用効果は抜群で、神里綾華ベンチマークの結果は以下のようになった。
- Colab Pro/プレミアム(A100):6.24(it)/32秒(10枚)
- GeForce RTX 3070 Ti(USB4接続):6.32(it)/37秒(10枚)
- GeForce RTX 4070 Ti(USB4接続):8.83(it)/27秒(10枚)
その差は10秒で、つまりRTX 3070 Tiと比較して1枚1秒速くなっている。たった1秒なのだがバッチ処理で複数枚生成すれば積み重なり、最終的には結構な違いとなる。リアル系の画像をBatch size 8で生成すると28秒、すなわち1枚3.5秒で出力できる。当初、Apple M1 Proで1枚1分半かかっていたのが嘘のようだ(笑)。
これだけ速くなるとプロンプトで出したい絵を細かく調整すると言うより、大量にガチャをして引き当てるような作戦も可能となる。またVRAM 8GBから12GBへなったことも大きく、AI画像生成だけでなく学習や大規模言語モデルなど、いろいろなことが可能となり大満足している。


とは言え、VRAMはまだ足らないので16GB以上が欲しいところだ。速度を落としていいなら7月発売予定のRTX 4060 Ti(16GB)へダウングレードするか、でなければNVIDIA RTX A5000(24GB)となるとなるものの、どちらも現実味がなく、多分このまま使い続けるだろう。なお、GeForce RTX 4080以上は外付けGPUボックスに入らないため、選択肢に挙がっていない。
1点、残念なお知らせとして、以前の記事で無償のGoogle Colabを使いStable Diffusionを動かす話をしたが、現在AI関連はStable Diffusion/AUTOMATIC1111のみ使えなくなってしまった。どうやら利用者が増え過ぎて、リソースが足らなくなったのが理由らしい。
有償のColab Proにはこの制限はないものの、1,179円/月の枠を使い切ると使えなくなってしまう(もしくは追加購入が必要)。従ってそれなりに動かしたい場合は、比較的安価なクラウドGPUか、ローカルに環境を組むことになり、ハードルが高くなってしまった。
ただ考えようによっては、たとえばクラウドGPUが月額3,000円だと2年で7万2,000円かかる計算で、GeForce RTX 4060 Ti(16GB)の実売予想価格に届かない。2年の間にいろいろリソースもアップデートするはずだ。そう考えるとクラウドGPUも悪い選択肢ではない。
Photoshopのジェネレーティブ塗りつぶしが凄い!
AIによる画像生成に関しては、Adobeは現在ベータ版のFireflyを公開しておりアカウントがあれば利用できる。Microsoftも同様のサービスをBing Image Creatorとして展開中だ。どちらも当初試したものの、ちょっとした入力で利用規約違反が出たり、顔がStable Diffusionと比較して絶望的に駄目だったこともあり、以降全く触っていなかった。
そして忘れた頃にAdobeがPhotoshopの新機能としてジェネレーティブ塗りつぶしを発表。当日はふーんと思った程度だったが、実際ベータ版Photoshopを入れて試したところ、(良い意味で)とんでもない機能だったのだ。

ジェネレーティブ塗りつぶしは、一般的にインペインティング/アウトペインティングと呼ばれるもので、前者は画像にある不要な領域の置き換えまたは削除、もしくはほかのものを書き加える、後者は画像の外側に画像内のテイストをそのままに書き加える機能だ。どちらも人間が手で書けないことはないが、もの凄い技量と手間がかかる。ジェネレーティブ塗りつぶしではこの両方に対応し、プロンプトによる指示もできる(現在英語のみ)。
百聞は一見にしかず。簡単なサンプルを用意したのでご覧いただきたい。もともとの画像は縦長で撮影したもので、それに対してカンバスサイズで左右に余白を作り、余白部分を範囲指定し、後はEnterキーを押すだけ。結果は以下の通り。3パターン生成されるので好きなのを選ぶか、ないときにはさらに生成する。
かかった時間はM1 Pro搭載のMacBook Pro 14で約20秒(カンバスサイズ2,880×1,920ドット)。GPUはリソースモニターを眺めていると、Photoshopが常に使っているには使っているが(10〜20%前後)、かといってこの処理を始めてから負荷が上がることはなかった。クラウドベースということだろう。





また生成された画像は別レイヤーになっており、オリジナルには全く手を加えていないのも特徴的だ。いかがだろうか。あくまでもAIが元の写真から想像して書いたものであり、リアルな渋谷の状態ではないとは言え、この出来にはちょっと絶句した次第だ。
左右が足せるなら下方向もと、次はポートレートで実験した。オリジナルはバストアップの写真で、2:3の比率のまま周囲に余白を作った。上手く行けば、背景と胸元から下の部分が書き足されるはずだ。


結果はご覧の通り。またしても絶句だ。驚いたどころの話ではない。洋服の質感、光の状況まで引き継ぎ見事に書き足されている。
ただしほかの2候補に関しては手や腕の位置が駄目だったのでボツとなった。これはStable Diffusionでもよくある話で、とにかくAI画像生成は手/指が苦手だ。手に関してはその部分だけ範囲指定し、プロンプトでhandと入れ、何度かトライするとそれっぽいのが出る。全体的にいい感じであれば、後は個別にインペインティングで修正すればよい。
次はメカっぽい画像に挑戦。見事にバイクの前後が書き足されている。機械として正しいかは別問題で、あくまでも雰囲気と言う感じにはなるだろう。いくつかのパターンを試したところ、書き足す範囲が大きくなるほど駄作率が高くなる。特にメカニックなものは、今回の場合だと「確かにメカっぽいけど、それバイク?」と思うものが多かった。



さて、ここまでやってみて思ったのは、「顔しかない写真から全身は作れるのか?」という疑問だ。では早速実験してみよう。





もう圧巻。何も言うことはない。ただしプロンプトを空白のまま進めると利用規約違反が出た。おそらく写真から何を着てるか判断できず、AIが勝手に裸を書いてしまい、それを自ら違反と言っているのだろう。このようなケースは結構あり、明らかにプロンプトで変なものを入れたケースと、AIが勝手に自爆したケースは分けて欲しいところだ。
だが冷静に考えると、顔だけでここまでできてしまうとコラージュし放題となる。おそらく正式版(もしくはベータ版途中から)ではこういった使い方は利用規約違反になるのではないだろうか。
仕上げはゴミや妙な髪の毛などを範囲指定し、プロンプトのdeleteで消している。普通の削除とは違い、周囲にあわせて書き込まれているのが分かる。スタンプツールで周囲からペタペタ貼る地味な作業から開放される。今回は写っているものを消したが、たとえば右手前を適当な大きさに範囲指定し、「bicycle」とプロンプトを入れると逆に自転車が現れる。
参考までに逆のパターン、つまり顔がなくて体があるケースの場合、一応顔を書くには書くのだが、笑えるほどどうにもならない顔になるため、怖いもの見たさ以外は試さない方がよい。
現在多くの人が(面白がって)ベータ版を使っているので、Adobeは大量にフィードバックを受けているはずだ。製品版はかなり完成度が上がっていると予想される。本格的に使えるようになると、たとえば製品写真だと、本体だけちゃんと撮っておけば、後からいろいろなシーンをこの機能で書き足せる。カメラマンとしては仕事が減るためうーんと思うところだが、企業としては助かるのではないだろうか。



そう言えば、Googleも1枚の製品画像からAIを使って複数のバリエーションを生成するサービス「Product Studio」を発表した。今後、この手のものが続々と出そうな雰囲気だ。
PhotoshopでできるならStable Diffusionでもできる?
ジェネレーティブ塗りつぶしでいろいろ遊んでふと思ったのは、「Photoshopができて、Stable Diffusionができないことはないだろう」ということだ。早速検索してみると、(ほかにもあるかもしれないが)3つの方法が見つかった。
1つ目と2つ目は、img2imgのScriptに標準で入っているため、誰でもすぐに試すことができる。Script名は、「Outpainting mk2」と「Poor man's outpainting」。試したところ上下左右にちょっとしたドット数を加えるならOKなケースもあるが、ジェネレーティブ塗りつぶしほど大胆なことはできない。
そして3つ目は、Stable Diffusion Infinityだ。ただし、Stable Diffusionとは別で起動するWeb UIで、condaなどを使い環境を作ってのインストールとなる。またHuggingface tokenが必要となる。
以下がWindowsの場合のインストールおよび起動方法だ。ほかのOSはGitHubに説明があるので参照のこと。
git clone https://github.com/lkwq007/stablediffusion-infinity sd-inf
cd sd-inf
conda create -n sd-inf python=3.10.6
conda activate sd-inf
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
conda install scipy scikit-image
conda install -c conda-forge diffusers transformers ftfy accelerate
pip install opencv-python
pip install -U gradio
pip install pytorch-lightning==1.7.7 einops==0.4.1 omegaconf==2.2.3
pip install timm
python app.py --host 192.168.11.222 --port 7850 --local_model ../sd1111/models/Stable-diffusion/dayuAisamixV1_dayuAisamixV10.ckpt
※host、portは環境にあわせる。modelオプションでレンダリングに使用するModelを指定(ckptタイプのみ)。なくてもよい。
※Dayu_AisaMIXは、少しイラスト寄りだがリアル系のModelで、作者が自分の好みの顔が出るよう拘ったものらしい。筆者も割と好きで結構使っている。
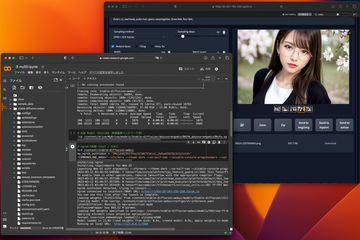
コマンドで指定したURLをWebブラウザで開くと下記のような画面が出る。GitHubのUsageには使用方法が書かれており、Huggingface tokenを入れたり、Custom Modelで別Modelを指定していたり(ckptタイプだけの対応のようだ)、model typeを選んだりと、いろいろしている。コンソールを見ると警告が出たり出なかったりと、どうも動作状況がよく分からないのだが、model typeでstablediffusion-inpainting+img2img-v1.5を選び「Click to Setup」を押せば動作はする。


実際の編集画面が2番目の画面キャプチャとなる。カンバスサイズは1,200×600ドットになっているので、変更したいときは、「Canvas Setting」で変更する。Photoshopのように読み込んだ画像サイズをその場で変更できないこともあり、事前に処理したい画像にこのカンバスサイズをあわせる必要がある。
準備ができたら「Upload Image」でアップロードする。あとは位置をあわせて「Confirm」する。ジェネレーティブ塗りつぶし同様、書き込みたい部分に枠をあわせ、「Sample number」を3へ設定し、「Outpaint」のボタンを押せば処理が始まる(当然GPUをしっかり使う)。なお、枠をあわせる際に「Resize Selection」からサイズ変更も可能だ。
Sample numberは3にすると、候補が3つ出るので好みを選ぶか「Retry」で再試行することになる(お好みにあわせて数字は変更すればよい)。このときのコツはPhotoshopでもそうだが、オリジナル画像に選択枠を少し被せることだ。また軽くプロンプトも入れた方がよい結果になりやすい。



上記はアウトペインティングだが、インペインティングも可能。その場合は先に消しゴムを使って塗りたい場所を削除した上で、その部分を枠で選択し、プロンプトを入れて「Outpaint」のボタンを押せばOKだ。
なおこのプロジェクトは最終更新日が2023年1月24日で、開発がしばらく止まっているようだ。UIも流石にPhotoshopと比較すると使いにくく、何か有名な写真編集系のアプリにこの機能を組み込んで欲しいところだ。
インペインティングで消すだけならもっと簡単
Stable Diffusionで画像を作っていると、画面の端に文字やロゴが出たり、薄めの衣装だと、ボディペインティングの様におへそやアバラが出たりと、ここだけちょっと消したいなと言うことがしばしばある。もちろんベータ版Photoshopのジェネレーティブ塗りつぶしでも消せるが、それも面倒と言うときにお勧めなのがこのLama Cleaner。Web UIで、画像をドロップし、消したい部分を塗るだけでパッと消える。
インストール方法は以下の通り。簡単だ。
conda create -n lama python=3.10.6
conda activate lama
pip3 install torch --index-url https://download.pytorch.org/whl/cu118
pip install lama-cleaner
lama-cleaner --model=lama --device=cuda --port=8080 --host=192.168.11.222
※portやhostは環境にあわせる。どこのフォルダからでも起動できる
コマンドで指定したURLを使ってWeb UIを開くと以下のような感じになる。シンプルで分かりやすく、作業後には気になる部分が綺麗に全部消えているのが分かる。





もちろんStable Diffusionで生成した画像だけでなく、イラストでも写真でも何でも使える。ちょっと余計なものを消したいときに非常に便利だ。
最後に、Stable Diffusionに関しては、3月にご紹介した以降、もの凄いペースで進化しており、全て追いきれない状況になっている。その最たるものがControlNetなのだが、これを書き出すと知っているだけでも本が1冊書けそうな量になってしまう。また何か機会があれば改めてご紹介したい。
そしてお気付きかと思うが、作例に使った画像、小彩 楓さん以降は全てStable Diffusionで生成したものだ。Model名はBRA。現在V5で公開中で、リアル系としてはちょっと類を見ないほどのリアルさが最大の特徴となる。
一般的にはChatGPTなど大規模言語モデル系が大きく扱われているが、AI画像生成もたった数カ月でこれだけの進化をしている。1年後、どうなっているのか想像もつかない状況だ。

以上、Photoshop Betaのジェネレーティブ塗りつぶしの凄さと、Stable Diffusion関連の情報を少しご紹介した。Photoshopでここまでできるなら、Stable Diffusionをプラグインで動かせば完璧じゃないかと検索したところ、すでに公開されていた。

GPU不要とあるが、正確にはStable Diffusion側には必要で、APIを使ってアクセスするPhotoshop側は不要となる。設定が面倒そうだが宿題としたい。
いずれにしても、もはや写真は真実を写すものではなくなってしまった。加えてワークフローも大きく変わりそうだ。AI生成と実写の区別がつかなくなるのも時間の問題だろう。カメラマンとしては複雑な気分になる新機能の登場となった。
試せるアカウントをお持ちの方は是非一度体験して欲しい。思わず「え゛」と声が出るはずだ。