西川和久の不定期コラム
動画生成AIのWan 2.2で画像を生成していたら、真打Qwen-Image登場!20Bを誇るモデルの画質やいかに!?
2025年8月14日 06:00

少し前に「Wan 2.1」というアリババグループの動画生成AIモデル(txt2vid)で画像生成(txt2img)する記事を掲載したが、時同じくして「Wan 2.2」がリリースされた。これで同様にtxt2imgして遊んでいたところ、何とアリババグループから画像生成AIの真打、Qwen-Imageが登場!今回はこの辺りの話をしてみたい。
今年2025年の生成AI画像動向、パート2
Wan 2.1の記事では、2024年はオープンな生成AI画像のモデルが続々登場したものの、2025年は「Lumina-Image 2.0」「HiDream-I1 Full/Dev/Fast」の2つだけ……と寂しい状況を書いた。開発コストがかかり、それを回収するのに独自のサービス(もしくは有料API)でのみ使用可能とするケースがほとんどになったためだ。
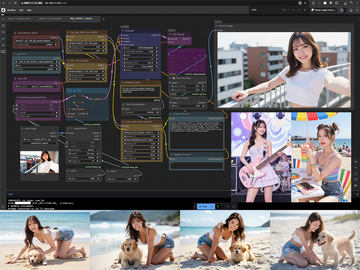
そのような中、元々動画生成AIのWan 2.1をtxt2imgのAI的に使い、画像を生成すると意外と良かった……というのが前書いた内容となる。
ちょうど記事が掲載されたタイミングで、予告通りWan 2.2がリリース(2025年7月28日)されたので、同じくtxt2imgを試す、というのを本記事の前半としたい。
記事の後半は、そうして遊んでいた8月5日。いきなり同社から生成AI画像モデルQwen-Imageがリリースされ、しかも20Bパラメータという高性能で登場したので、その話をしてみたい。
実は8月1日にもう1つ、Black Forest Labs(BFL/FLUX.1を作った企業)とKrea AIがコラボした「FLUX.1 Krea [dev]」もリリースされている。 ただこれはあくまでもFLUX.1 [dev]を、Krea AIがファインチューニングした派生モデルなので(良くはなっているものの)今回は省略。
執筆時点で今年2025年のオープンな生成AI画像は、
- Lumina-Image 2.0
- HiDream-I1 Full/Dev/Fast
- FLUX.1 Krea [dev] (8月1日)
- Qwen-Image (8月5日)
となる。毎年夏はいろいろAI界隈が騒がしいのだが、今年(2025年)も例外なく祭りとなった(LLMではGPT-5、gpt-oss-20b|120b、Opus 4.1なども出ている)。
Wan 2.2
まずWan 2.2の本来の目的となる動画について。2.1との違いは以下の通り。
| Wan 2.1 | Wan 2.2 | |
|---|---|---|
| アーキテクチャ | 標準的な拡散モデル | MoE(Mixture-of-Experts) |
| モデルサイズ | 14B/1.3B | 14B/5B |
| エキスパートモデル | なし | 高ノイズ(レイアウト担当)/低ノイズ(細部担当) |
| 制御システム | 基本的なプロンプト制御 | シネマティックコントロールシステム |
中でも一番大きな違いは、checkpointが2つになったこと。標準的なComfyUI Workflowはこんな感じになる。

左側2つの赤い部分は、高ノイズ用と低ノイズ用のcheckpoint。Wan 2.1は1つだったので、txt2img化を企てる筆者にとっては謎だらけとなる。その後、調べて分かったのは、
- Wan 2.1のLoRAが使える(もちろんWan 2.2用に作り直すのが望ましい)
- 高ノイズ用と低ノイズ用、両方に同じLoRAを当てる必要がある(Wan 2.2用で分けて作りそれぞれに当てるのが王道)
この2点。Wan 2.1用のLoRAがとりあえず流用できるため助かるものの、この場合、どちらにも同じLoRAを当てるのが操作上面倒だ。この部分だけ切り出したWorkflowが上側になる。LoRAが複数あった場合、LoRAファイルはもちろん、重みも合わす必要があり、手間だ。
そこで普段使っているLoRA Stackを改造して、扱いやすくすることにした。もちろんコードの改造はClaude Codeにお任せ。以下、依頼した内容となる。
以下のリポジトリにComfyUI Custom NodeのLora Loader Stackがあります。機能を確認してください。
https://github.com/rgthree/rgthree-comfy
https://github.com/rgthree/rgthree-comfy/blob/main/py/lora_stack.py
以下の仕様に変更してください
1.modelの入出力を2系統へ
2.Loraはmodelのどちらにも同じ内容を設定する
3.clipは共通
独立したComfyUIのCustom Nodeにしてください
LoRAを6つ使える様にしてください
またrgthreeは被るのでknishikaとしてください
以上のプロンプトの一撃で改造完了!半年ほど前までComfyUIのCustom Nodeはなかなかうまく行かなかったのだが、最近はリテイクもなくサクッとできるように。改良版Workflowを見ていただければ分かるように、モデルの入力と出力が2系統となり、操作するLoRAは共通で楽に操作できる。


高ノイズ用と低ノイズ用、2つのcheckpointがあるため、人によっていろいろWorkflowのパターンがあるのだが、現在筆者が使っているのはこんな感じだ(Workflowと改良版LoRA Stackはここに置いてある)。







以前の記事で“暗い部屋にポツンと一人……的なダークな感じの絵も苦手”と書いたが、ご覧のように見事に出る(Wan 2.1も)。これにはちょっとしたコツがあり、プロンプトにいろいろ書くとそれを見せようとしてどんどん明るくなる癖がある。シンプルなプロンプトにすれば作例の通り。
モノクロは“monochrome photo”ではなく“monochrome video”と書く。もともとtxt2vidモデルなので当然なのだが、画像を生成しているとそんなことを忘れて、いつも通り前者を書いてしまう(笑)。
Qwen-Image
Qwen-Imageは、Wan 2.1/2.2同様、アリババグループが開発した生成AI画像モデルだ。Qwenという名はLLM系が有名で、最近だと「Qwen3-236B-22-2507」や「Qwen-Coder」などが挙げられる。画像生成については、同社のサービス内で Wan 2.1 Plus/Wan 2.2 Plusとあるだけ。まさかこのタイミングで、オープンなのをリリースするとは誰も考えていなかったのではないだろうか。
性能も凄まじく、「SDXL」が3.5B、「SD 3.5 Large」が8B、「FLUX.1 [dev]」が12B、「HiDream-I1」が17Bなので、20BのQwen-Imageはオープンなモデルの中では最大となる。
ComfyUIで生成するのに必要な各モデルは以下の通り。
qwen_image_fp8_e4m3fn.safetensors (20.4GB)
qwen_2.5_vl_7b_fp8_scaled.safetensors (9.38GB)
qwen_image_vae.safetensors (254MB)
fp8でこのファイルサイズ、fp16になると倍になりかなり巨大だ。fp8を使ってVRAM 24GBのGeForce RTX 4090でギリギリのサイズとなる。なおVRAM容量が少ない場合は、既にGGUF版が用意されているので興味のある人は検索してほしい。
テキストエンコーダは何と「qwen_2.5_vl_7b」。つまり同社の画像認識対応LLMがまんま入っている。これによりプロンプトは英語と中国語に対応。日本語もそれなりに使用できる。

ComfyUI本体がQwen-Imageに対応済みなので、Workflowはごく一般的なものだ。唯一異なるのはmodelとKSamplerの間に「ModelSamplingAuraFlow: 3.10」が入っている程度。なお、ComfyUIの起動オプションで「--fast」を入れている場合は外さないとノイズだけの画像が生成されるので要注意!
このWorkflowで1,024×1,536を生成するとGeForce RTX 4090で約50秒。テキストエンコーダにqwen_2.5_vl_7bが入っていたので、嫌な予感はしていたものの、かなり重い印象だ。
Comfyの解説ページにある「qwen_image_distill_full_fp8.safetensors」を使うとcfgを1.0にできるため倍速で生成可能になる(cfgは1.0以外だとネガティブプロンプト(Negative Prompt)に対応するため倍の生成時間が必要)。
加えて、執筆中にリリースされたQwen-Image-Lightning LoRAを使うと8 steps, cfg 1.0で行けるため約4倍速、つまり15秒で生成可能。どちらも少し絵柄は変わるものの、これだけ生成時間が変わると速い方を使いたくなる(笑)。

以下作例を6点。すべてQwen-Image-Lightningを使い、後述する顔LoRAを若干当て、肌LoRA変わりにしている。






Wan 2.2のtxt2imgと比較して一番違うのは肌。Wanはツルツルしていたものの、こちらはかなりリアルになっている。細かい描写もこちらが上。つまりWan 2.1のtxt2imgの時に欠点で書いたことが見事に解消されている。生成時間もQwen-Image-Lightning(重み1.0だと硬調になるので0.4前後がいいかも知れない)のおかげでWan 2.2のtxt2imgより速くなった。
ここまでハイクオリティだと次にやりたくなるのは当然顔LoRA。当初、いつものai-toolkitが内部的には対応!と情報があったものの、肝心の設定.yamlはなし。パラメータが分からない。sd-scriptsのkohya氏作、musubi-tunerは今(8月10日)対応したばかり。
前者のGitHubにある対応コードを眺めながら一番近そうな?HiDream用の.yamlを書き換えて学習させてみた。具体的には、
1. config/examples/train_lora_hidream_48.yamlを適当にリネームしてconfigへ
2. 以下を書き換え(steps 3000はデフォルト)
steps: 3000
lr: 1e-4
name_or_path: 'Qwen/Qwen-Image'
extras_name_or_path: 'Qwen/Qwen-Image'
arch: 'qwen_image'
LoRAファイル名やサンプル生成のタイミング(250を500へ)、プロンプトなどは適当に変更。ただし、VRAMは32GBを超えるため、今回は「GoogleColab A100(40GB)」を使用した。3,000 stepsで約2時間半と結構かかる。ほかの細かいパラメータは合っているかどうか不明だが、学習結果は良好で、無事、顔LoRAを作ることができた。


現在Qwen-ImageはControlNet未対応、FLUX.1 Kontext同様、編集機能もあるらしいが、やり方が不明など、FLUX.1に劣る部分もあるのだが、画像自体はあきらかにQwen-Imageの方が上。加えてPromptの反応度も圧倒的に良い。既に筆者はFLUX.1 [dev]は使わなくなっており、Qwen-Imageばかり使っている。
そうそう、Wan 2.1/2.2とQwen-Imageの気になるセンシティブ規制度合いだが、無規制(笑)のWan 2.1/2.2に対して、Qwen-Imageは少し規制がかかっている。とは言え、既にCivitaiにはLoRAが出ており、今後改善されるだろう。
以上のようにハイクオリティな画像を得られるQwen-Imageだが、生成するにしても学習するにしてもハイエンドなGPUがないと厳しいのには変わりない。そんな中、たまたまXで見かけて試用したのがWaveSpeedAI 。
FLUX.1 [dev]はもちろん、Wan 2.1など、いろいろな画像/動画生成に対応し、FLUX.1 (Krea)[dev]、Wan 2.1 txt2img、そしてQwen-ImageのLoRAあり生成と学習(Kreaなし)もOK。Qwen-Image以外はimg2imgあり。APIも使え、ComfyUIのCustom Nodeもある。


これで生成1枚約0.025ドル(1ドルで40枚)、LoRA学習1ドル(1,000 stepsで1ドル)。しかも学習が10分未満!高価なGPU買うよりこちらを使った方がいいのでは?と思ってしまった(笑)。
ちなみに筆者がそうこうしている間に、GeForce RTX 5090搭載PCの2TB SSDの調子が悪くなってしまった。これをどうしたか?が、おそらく今月4本目のネタになる。
以上のようにWan 2.2とQwen-Imageは、アリババグループがリリースした生成AI動画/画像モデルだ。特にQwen-Imageは、コミュニティの反応を見ていると、現在スタンダードなFLUX.1 [dev]の後継になりそうな雰囲気があり、今後どうなるか!? 非常に楽しみと言えよう。
