ニュース
Intel、288コアの「Xeon 6」と、性能4倍のAIアクセラレータ「Gaudi 3」
2024年4月10日 00:35

Intelは、4月8日~4月9日(現地時間)に、米国アリソナ州フェニックスにおいて「Intel Vision 2024」を開催している。会期2日目となる4月9日の午前には、同社CEO パット・ゲルシンガー氏ら同社幹部による基調講演などが行なわれ、「Sierra Forest」のコードネームで開発してきた次世代Xeonの製品名が「Intel Xeon 6プロセッサー」になることなどが発表された。
あわせて、IntelのAI向けアクセラレータ「Gaudi」シリーズの最新製品となる「Gaudi 3」も正式発表された。Gaudi 3は微細化され、2つのダイが1つのパッケージに封入されたことで演算器やメモリ帯域が倍になり、性能が大きく向上していることが特徴となる。
Eコアだけで構成されるSierra ForestはXeon 6のブランド名で投入

Intelのデータセンター向けCPUは、最新製品のEmerald Rapidsまで「第x世代Intel Xeon Scarable Processor」というブランドの呼ばれ方をしてきた。クライアントPCでは第x世代(x th Gen)という表記が廃止されることになったが、Xeonでも同様に製品の前に世代名がつけるのは廃止され、今後は「Intel Xeon x プロセッサー」のようによりシンプルな名称に変更される。
その最初の製品になるのが、2024年前半にIntelが投入を計画している開発コードネーム「Sierra Forest」で、「Intel Xeon 6プロセッサー」(以下Xeon 6)という名称となった。


Xeon 6は、クライアントPC向けのCPUで言えばEコアだけで構成されるCPUで、1つのパッケージにダイ(144 CPUコア)を2つ実装することで、1パッケージで288コアという高密度を実現したことが特徴になる。第2世代Xeon Scarable Processorと比較して、CPU単体での電力効率が2.4倍になり、ラックあたりの電力効率は2.7倍になるとIntelは説明している。
前世代比較で性能を4倍にしたGaudi 3

IntelはAI学習向けのAIアクセラレータとして、イスラエルのHabana Labsを買収して得た「Gaudi」シリーズを展開している。Gaudiは、Google CloudのTPU、AWSのTrainium、Microsoft AzureのMaiaといったAI学習(そして一部は推論にも利用されている)専用と位置付けられているAIアクセラレータと同等の製品だ。汎用プロセッサをAIに転用しているGPUに比べると、電力効率が高いのが特徴となる。
| Gaudi | Gaudi 2 | Gaudi 3 | |
|---|---|---|---|
| プロセスノード | 16nm | 7nm | 5nm |
| コンピュートエンジン(TPC) | 8 | 24 | 64(1ダイあたり32) |
| MME(Matrix Math Engine) | 1 | 2 | 8(1ダイあたり4) |
| HBM | 32GB(HBM2) | 96GB(HBM2e) | 128GB(HBM2e) |
| HBM帯域幅 | 1TB/秒 | 2.45TB/秒 | 3.7TB/秒 |
| シェアードメモリ(SRAM) | 24MB | 48MB | 96MB |
| Ethernet | 10×100Gb | 24×100Gb | 24×200Gb |
| TDP | 350W | 600W | 900W(OAM) 600W(PCIe) |
今回発表されたGaudi 3は、Gaudiシリーズの第3世代で、2022年に発表されたGaudi 2の後継となる製品だ。


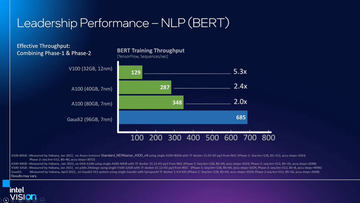
最大の特徴は、Gaudi 2のダイが7nmだったのに対して、Gaudi 3では5nmに微細化されたことで1つのパッケージに2つのダイを実装したことだ。ただし、ソフトウェア的に見た場合には、1つのチップとして認識されるので、従来のGaudi 2用のソフトウェアをそのまま活用することが可能だ。


こうした改良により、Gaudi 2と比較して演算器(TPC=Tensor Processor CoreないしはTensor Processing Core)は24だったのが64に、行列演算を行なうMMEが2から8に増加したほか、シェアードメモリとなるSDRAMの容量が48MBから96MBに、メモリ容量も96GBから128GBに、メモリ帯域も2.45TB/秒から3.7TB/秒にいずれも向上している。それにともなって性能が引き上がり、Gaudi 2と比較してBF16演算時には性能が4倍になるという。





また、Gaudiシリーズの特徴の1つであるEthernetを利用したスケールアップ/スケールアウト時のスペックが向上しているのも見逃せない。
NVIDIAのGPUは、NVLinkとNV Switchでスケールアップしたあと、InfiniBandでスケールアウトできるようになっており、それによりかなり多くのGPUを並列に走らせて1つの巨大なGPUとして利用できるスケーリング性能がアドバンテージの1つになっている。
一方Gaudi 2では、そのチップ単体で24ポートの100Gb Ethernetのポートが用意されており、ケースやラックの内部でスケールアップするのに使い、ラックそのものからスケールアウトするときにも活用できる。
Gaudi 3では、Ethernetポート数は24ポートで同じだが、ポートの仕様が200Gb Ethernetに強化されている。これにより、1ノードで8台のGaudi 3を構成する場合、RetainerとOSFPのルーターを活用することで、すべての通信が200Gbpsを保ったままの構成が可能になる。
さらに8つのGaudi 3から構成されるノードをEthernetスイッチとして利用することで、16ノードに、512ノードにとスケールアウトしていくことが可能で、高コストなInfiniBandに比べて低コストな汎用品であるEthernetが利用できるため、スケールアップ時のコストメリットがあるとIntelは説明している。
NVIDIA H100と比較して性能でも、電力効率でも上回っているGaudi 3


IntelはGaudi 3の性能を、NVIDIA H100やH200と比較して紹介している。H100やH200のデータはNVIDIAが公開しているデータに基づく。H100との比較では、FP8を利用した学習においてLlama2-7Bモデルで1.5倍、Llama2-13Bモデルで1.7倍、GPT3-175Bモデルで1.4倍と、最大1.7倍の性能向上を実現するという。






H200と推論時で比較した場合、Llama2-7BモデルとLlama2-70Bモデルはほぼ同等かH200がやや速く、Falcon 180BモデルではGaudi 3が平均して1.3倍高速で、H100と推論時で比較した場合は平均して1.5倍高速だという。また、推論時の電力効率をH100と比較した場合、最大で2.3倍優れているとIntelは説明した。



Gaudi 3には3つのバージョンが用意される。1つはOAM互換のモジュール形状でHL-325Lとなる。FP8の演算時に1,835TFLOPSを実現し、128GBのHBM2e、24×2200GbpsのNICなどのスペックになっており、TDPは900Wとなる。
そのHL-325Lを8つ搭載したベースボードがHLB-325で、NVIDIAのDGX H100やHGX H100と同じようなサーバー機器を実現するのに利用される。
もう1つの単体製品はHL-338で、PCI Expressのアドインカードとなる。TDPは600Wだが、900WのOAMと同じくFP8時の性能は1,835TFLOPSが実現されている。


Intelによれば、OAMのHL-325Lの空冷版はすでに顧客向けにサンプル出荷されており、第2四半期にはHL-325Lの液冷版のサンプル出荷が開始される。製品版は空冷版が第3四半期に、液冷版は第4四半期の大量出荷が計画されている。PCIeアドインカードのHL-338は2024年後半に出荷される見込みだ。製品版は、Dell Technologies、Hewlett Packard Enterprise(HPE)、Lenovo、SupermicroといったOEMメーカーから出荷される予定。