 |


■後藤弘茂のWeekly海外ニュース■G80とG7xの最大の違いはマルチスレッディング |
●目的によって異なるGPUのスイッチング
ストリームプロセッサであるGPUは、3つのレベルで何らかのスイッチングを行なっている。
(1)もっとも粒度が大きいのがGPU全体のコンテキストのスイッチング。GPUで実行するプログラムを切り替える。(2)次が、GPU内部の演算プロセッサである「Programmable Shader」が処理するオブジェクトの塊である「バッチ(Batch)」の切り替え。(3)最後が、Shaderがプログラムを実行する際に、処理対象のオブジェクトをオーバーラップさせるカスケード型の実行方式。
この3種類のスイッチングが複雑に絡んでいるため、GPUのマルチスレッディングは非常にわかりにくい。また、GPUによって(1)コンテキストスイッチングと(3)カスケード実行だけ、あるいは(2)バッチの動的な切り替えと(3)カスケード実行だけといった組み合わせでスイッチしている。必ずしも(1)(2)(3)の全てをサポートしているわけではない。また、(3)カスケード実行でも、カスケード式に実行するオブジェクトの単位や、その方式が異なる。つまり、マルチスレッディングと言っても、その実装は、各社で大きく異なる。
 |
| NVIDIAのDavid B. Kirk(デイビッド・B・カーク)氏 |
こうした違いが生じるのは、何のためにこうしたマルチスレッディングを実装しているのかという、目的に深く関係している。
なお、用語的な問題として、Microsoftはグラフィックスプログラムである「Shader(シェーダ)」を実行するプロセッサにも「Shader」という名前をつけてしまった。つまり、ソフトのShaderを実行するハードウェアもShaderと呼ばれている。NVIDIAのDavid B. Kirk(デイビッド・B・カーク)氏(Chief Scientist)は「この命名はおかしいと自分も思う。Shader(プロセッサ)はプロセッサと呼ぶべきだと思う」と語っていた。記事中では、プログラムについては「シェーダ(プログラム)」、プロセッサについては「Shader(プロセッサ)」と区別している。
●Windows VistaのGPU仮想化と絡むコンテキストスイッチング
(1)GPU全体のコンテキストスイッチングは、Windows Vistaと密接な関係を持つ。Windows VistaでGPUコンテキストの切り替えのハンドリングが、「GPU仮想化(GPU Virtualization)」として実装されるからだ。
仮想化と言っても、いわゆるCPUの仮想化、つまり、OSの下のレベルで仮想化するバーチャルマシンのハードウェアサポートとはレイヤーが異なる。アプリケーションから見えるデバイスをOSレベルで仮想化する。アプリケーションからは仮想化されたGPUを占有しているように見えるが、実際にはOSがハンドルしてアプリケーションをスイッチする。簡単に言えば、これまで“シングルタスク”だったGPUを、“マルチタスク”にするのがGPU仮想化だ。
「GPUの仮想化は、GPUが真のマルチタスクになるという意味だ。しかし、GPUがハードウェアコンテキストスイッチング機能を持たないと、(仮想化の)コンテキストスイッチングのためにGPUの処理時間が食われてしまい、実際にレンダリングする時間は非常に少なくなってしまう。仮想化を現実的に使うにはGPU側の対応が必要だ」とKirk氏は語る。
GPUのコンテキストスイッチングが“重い”のは、スイッチしなければならないコンテキストの量が膨大だからだ。シェーダプログラムの実行の途中でスイッチしようとすると、数十個もある各Shaderプロセッサのそれぞれのコンテキストを保持しなければならない。円滑にスイッチするためには、ハードウェアサポートが重要となる。
Windows VistaのGPU仮想化を、GPUハードでサポートするのがGPUのハードウェアコンテキストスイッチングという関係になる。実際には、MicrosoftはOS側のモジュールとドライバの世代によって、仮想化のサポートを段階的に切り替える。ちなみに、ハードウェアコンテキストスイッチングによるGPU仮想化をサポートするのは、「DirectX 10.1」とドライバモデル「WDDM2.1(Windows Display Driver Model 2.1)」となる。
コンテキストスイッチング自体のサポートは、NVIDIAは以前から行なっていると説明している。AMD(旧ATI)もXbox 360 GPU(Xenos)で、8コンテキストのスイッチングをサポートしていることを明かしている。Microsoftがコンテキストスイッチングを要求し始めたことで、今後はGPUの標準機能になると予想される。NVIDIAの最新のGeForce 8800(G80)も、この機能をサポートしている。
「我々は(コンテキストスイッチングを)ハードウェアサポートしている。G80でのコンテキストスイッチングはMicrosoftの要求仕様に合致しているし、一部は要求仕様を上回っている。ハードウェアは、ソフトウェアが必要とする機能を事前に備えていなければならないからだ」とKirk氏は説明する。
ちなみに、OSによるGPUの仮想化では、SLIのようなマルチGPUも使いやすくなる。OS側でタスクを、仮想化した複数のGPUに割り振れば、並列に走らせることができる。つまり、現在のマルチタスクOSが、マルチプロセッサやマルチコアCPU上で、タスク並列で性能を上げるのと同じことができるようになる。
●1個のGPUでグラフィックスとフィジックスの切り替えが容易に
コンテキストスイッチングのハードウェア実装には、Windows Vista以外にも意味がある。それは、GPUでの、より汎用的なコンピューティングだ。例えば、GPUは今後、グラフィックス処理だけでなく、物理シミュレーションなど、計算量の多い処理を行なうようになっていく。こうした処理は、現在はSLIのような複数ビデオカードで行なっているが、より広く普及させるためには、1つのGPUで同時に処理できるようにする必要がある。その場合、グラフィックスと非グラフィックスといった並列する処理を円滑に切り替えるにはコンテキストスイッチングのサポートが重要となる。
例えば、G80では「CUDA (クーダ:compute unified device architecture)」と呼ぶ非グラフィックス向けプログラミングモデルが導入される。CUDAのプログラムは、G80では別なコンテキストとして、DirectX上などのシェーダプログラムとハードウェアコンテキストスイッチングによって同じG80上で円滑に走らせることができる。
「CUDAのプログラムは、シェーダ(プログラム)と並列して走る。単にもう1つのコンテキストとして、コンテキストスイッチングで実行されるだけだ」(Kirk氏)
さらに、コンテキストスイッチングは、後述するShaderプロセッサ側のマルチスレッディングと連携することができる。つまり、異なるコンテキストを、マルチスレッディングによって同時並列で走らせることも可能になる。NVIDIAのG80はこれをサポートしている。
「G80が1つのシェーダプログラムの多数のピクセルを走らせている時に、シェーダプログラムを替えると、さらに多くのピクセルが立ち上げられ(実行パイプラインに)ミックスされる。G80では、Shader(プロセッサ)に同じプログラムを走らせる必要すらない。異なるプログラムを同時に走らせることもできる」(Kirk氏)
従来のGPUのほとんどは、一度に1つのプログラムしか走らせることができない。だが、G80の場合は、Shader群に、同時に複数のプログラムを並列的に走らせることができる。この場合、プログラム単位で見ると、CPUの「SMT(Simultaneous Multithreading)」的な並列実行となる。Shaderプロセッサを独立したプロセッサコアと考えるなら、マルチコア的な並列処理だ。こうした機能を持つと、ゲームなどでグラフィックスと物理シミュレーションの両方を1つのGPUで走らせる時も、効率を落とすことなく処理できることになる。
●メモリレイテンシを隠蔽することがGPUの効率化では最重要
(3)GPUのShaderプロセッサのカスケード実行は、主にメモリレイテンシの隠蔽のために行なわれる。プロセッサにとって、メモリレイテンシがストールの最大の原因になるからだという。
「インターリーブ(この場合はカスケードのこと)する理由は、主にメモリレイテンシの隠蔽のためだ。その事情は、G80でも同じだ。なぜなら、メモリレイテンシは好転しないからだ、むしろ悪化している。より進んだDRAM技術に移行すると、メモリレイテンシが長くなり、もっともっとスレッディングしなければならなくなる」とKirk氏も指摘する。
GPUのメモリは、DDRからDDR2/GDDR2、GDDR3へとどんどん高転送レート化している。しかし、DRAMのアクセスレイテンシは変わらないか長くなる傾向にある。外部メモリにアクセスすると、プロセッサコアのサイクルで最大数100サイクルものレイテンシが生じてしまう。シェーダプログラムの場合、アクセスはテクスチャフェッチで発生する。テクスチャを使う命令は、メモリからテクスチャがフェッチされフィルタされるまで、待たなければならない。その間、GPUのShaderがアイドル状態になってしまうと、GPUのパフォーマンスが大きく削がれてしまう。
この問題は、Shaderプロセッサが高速化するとどんどん大きくなっていく。特に、G80のようにShaderプロセッサを従来の倍速である1.35GHzで動作させている場合、ギャップはさらに倍に広がってしまう。つまり、従来の倍のレイテンシサイクルを隠蔽しなければならない。
こうした理由から、GPUではカスケード式にパイプラインでプロセッシングすることが一般的になっている。実際には、GPUは、固定パイプ時代からこうした実行形態を取っており、Shader GPUにも持ち込まれた。NVIDIAはカスケード型で実行していることを明かしており、AMDも同じスタイルだと言われている。NVIDIAのKirk氏は、2年前のインタビューで次のように語っていた。
「GPUはストリームプロセッサだ。ストリームプロセッシングでは、プロセッサをビジーに保つために、(CPUとは)異なるソリューションが必要となる。ストリームプロセッサがCPUと異なるのは命令フロースルーだ。我々はマルチプルコンテキストを一度に走らせることでレイテンシをカバーする。
CPUの場合は1つのプログラムしか走らせないので、命令1の直後に命令2を実行する必要がある。しかし、Shaderでは、ピクセルAに対する命令1の後に、ピクセルBに対する命令1を実行、次にピクセルCに対する命令1といった形で実行できる。100ピクセル分も命令1の実行が続くかもしれない。そうすると、100サイクル後に、最初のピクセルAに対する命令2が来ることになる。だから、レイテンシがあってもカバーできる」
●オブジェクトを1サイクル単位でカスケードして実行
GPUでは、非常に多くのオブジェクトを並列に処理する。ピクセルプロセッシングなら、数百万ものピクセルがあり、それぞれが依存性を持たない。そのため、GPUのShaderプロセッサは膨大な数のオブジェクトを、切り替えることができる。グラフィックス処理の場合、レイテンシはそれほど問題ではなく、スループットが重要となる。そのため、カスケード式にShaderプロセッサでスレッディングすることで、レイテンシを隠蔽する方法が有効となる。
例えば、ピクセルプロセッシングの場合、1つのShaderプロセッサにはピクセル0からピクセルnまでの多数のピクセルが割り当てられる。また、GPUでは、Shaderプロセッサのクラスタは1度に1種類のシェーダ(プログラム)しか実行しない。シェーダ(プログラム)には、命令(Inst)0から命令nまでの多数の命令が含まれる。つまり、1つのプログラムの命令0から命令nまでを、ピクセル0からピクセルnまでに対して実行することになる。
Kirk氏が説明した通りだとすると、GPUは、ピクセル0からピクセルnまでのピクセル群のうち、最初に、ピクセル0の命令0を実行し、次にピクセル1の命令0を実行と、順番に同じ命令を実行し、ピクセルnまでを終える。命令0の実行を全てのピクセルに対して終えたら、再びピクセル0に戻って、今度は命令1の実行をスタートし、あとは同じことを繰り返す。これは1サイクル毎にオブジェクトを切り替えていると見ることもできる。
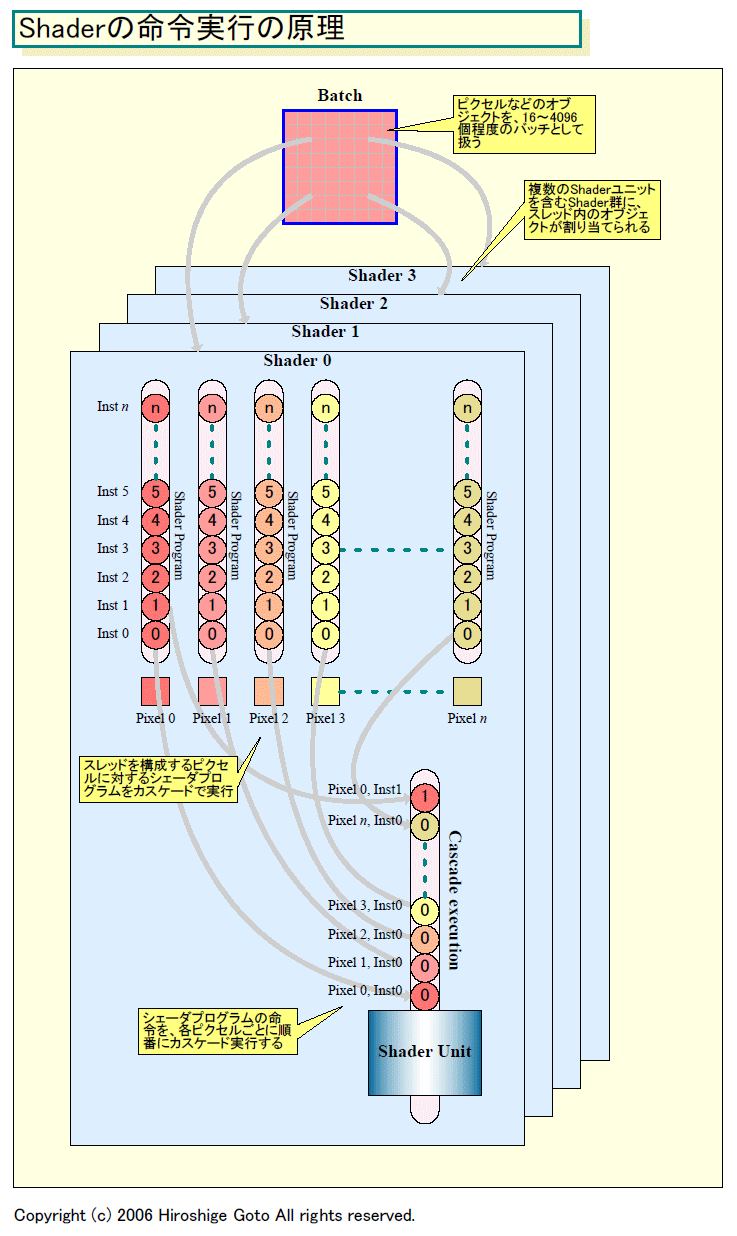 |
| Shaderの命令実行の原理 (別ウィンドウで開きます) PDF版はこちら |
この構造によって、Shaderプロセッサではメモリレイテンシを隠蔽できる。カスケード実行では、n個のオブジェクトをプロセッシングするためにnサイクルかかる。そのため、カスケードするオブジェクトの数が十分に多ければ、そのレイテンシの間にメモリにアクセスできるからだ。命令0がテクスチャアクセス命令で、命令1がテクスチャを使う命令だった場合、カスケードしていると命令1までnサイクルの間隔が開く。だから、nが十分な数であるなら、メモリアクセスのレイテンシを吸収できることになる。
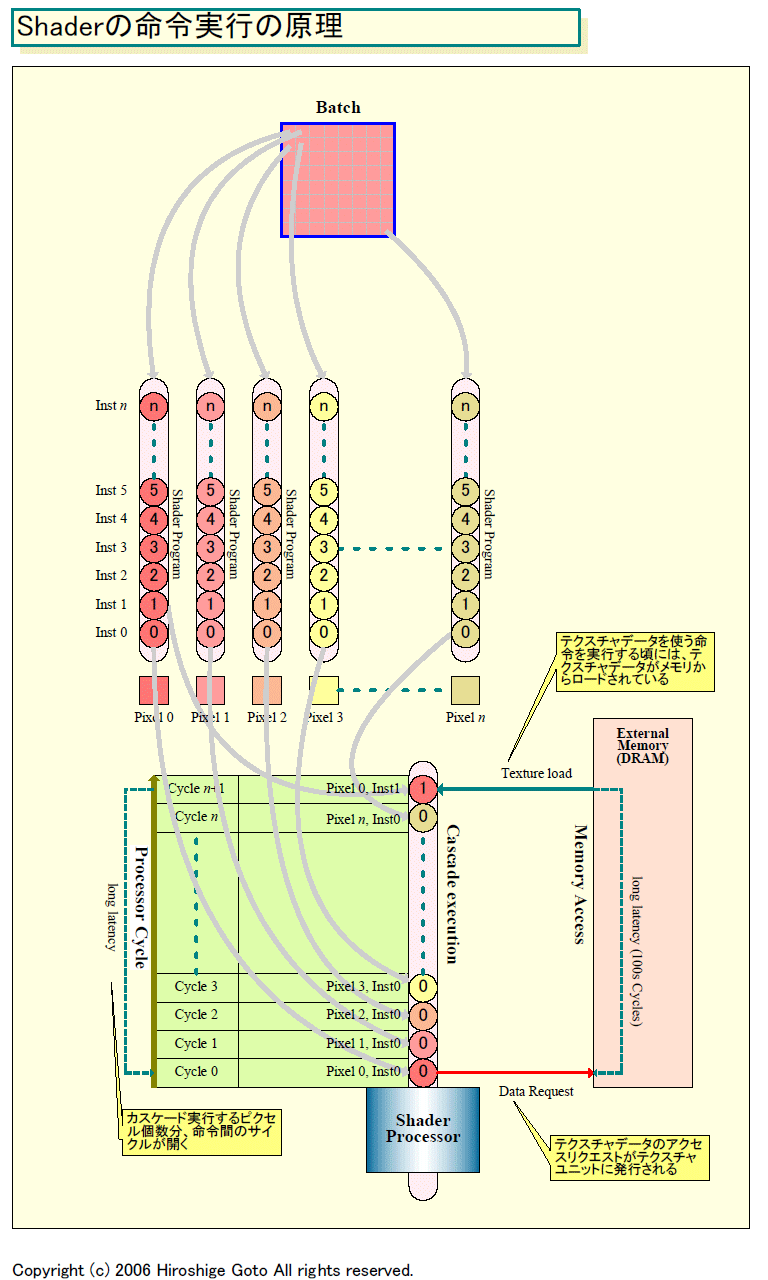 |
| Shaderの命令実行の原理(2) (別ウィンドウで開きます) PDF版はこちら |
もっとも、実際には、Shaderプロセッサ自体は、パイプライン化されていて、複数のステージがオーバーラップする。グラフィックスのプログラミングモデルの場合、個々のオブジェクト単位でシェーダ(プログラム)でのプロセッシングが行なわれる。そのため、細分化されたステージで、異なるオブジェクトを並列に実行するようなイメージとなる。
つまり、GPU的に見ると、これは単なるパイプライニングで、カスケードするオブジェクトの数だけのステージがあり、ステージ数はイコール命令実行のレイテンシということになる。実際、GPU用語では、そうした呼び方をすることも多い。そうした見方では、下の図のように見える。パイプラインを充填するのに、多数のオブジェクトが必要になるというイメージだ。
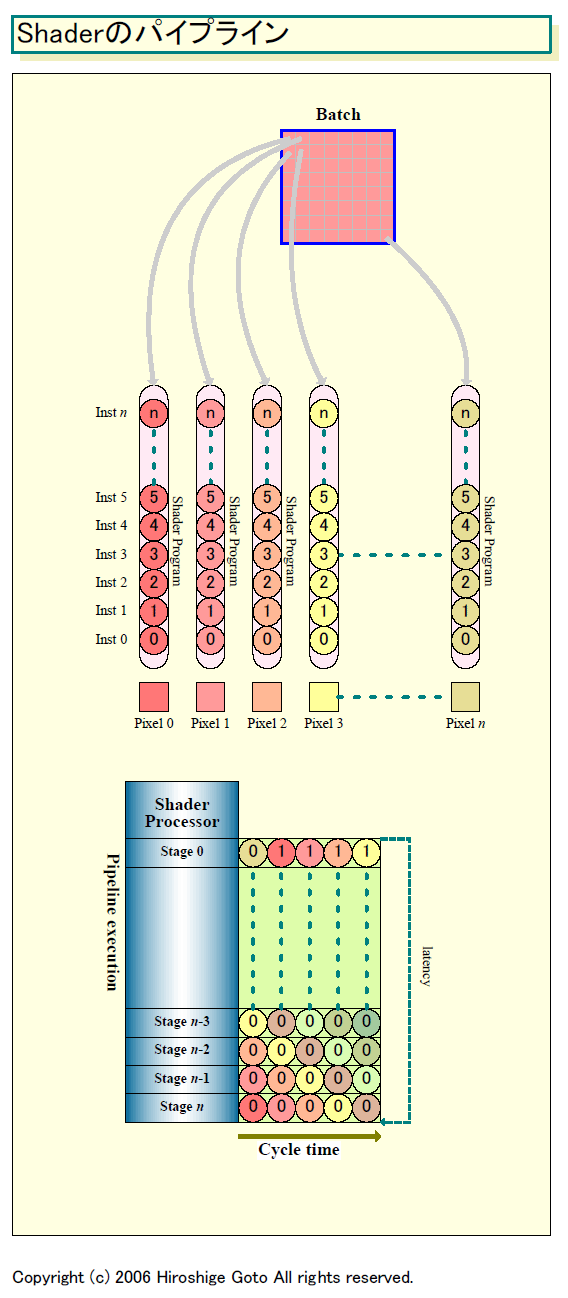 |
| Shaderのパイプライン (別ウィンドウで開きます) PDF版はこちら |
また、シェーダプログラム側から見ると、同じプログラムで次々に処理するオブジェクトを切り替えることになる。プログラム中の命令0で、ピクセルを0からnまでプロセッシングし、それから命令1のプロセッシングを行なうわけだ。リングバッファに各ピクセルのステイタスが格納されており、それをぐるぐる回してプロセッシングして行くようなイメージだ。
いずれにせよ、GPUのShaderプロセッサでは、こうした実行方式を取っているため、多数のオブジェクトを一度に制御しなければならない。
●バッチをShaderクラスタに割り当てることで制御
Shaderプロセッサに対して割り当てるオブジェクト群は、通常「バッチ(Batch)」と呼ばれる。もっとも、AMDではバッチを「スレッド」と呼ぶことも多い。また、ややこしいことにNVIDIAではこのバッチを「クラスタ」と呼ぶこともある。「分岐粒度(Branching Granularity)」も、ほぼ同じ意味合いで使われることがある。
実際には、GPUでは、このバッチは複数のShaderプロセッサのバンドルである、Shaderクラスタに割り当てられる。
一般的にShaderプロセッサは、4ユニットで構成する「クアッド(quad)」単位でバンドルされている。通常のGPUでは、Pixel Shaderプロセッサは4wayのSIMD(Single Instruction, Multiple Data)演算ユニットであり、その4way SIMDプロセッサが4個でクアッドになっている。これは、2×2で隣接した4個のピクセルを一度に処理するためだ。4個単位で処理すると、テクスチャデータのフェッチやフィルタリングの際の効率がよくなるためだという。
通常のGPUでは、SIMDのShaderプロセッサのクアッドが、4ピクセル単位で並列に処理を行なう。そのため、Shaderプロセッサの制御するオブジェクトの数は、通常、最小単位が4ピクセルとなる。さらに、そのクアッドの数を増やすことで、プロセッシングを並列化する。
GPUでは通常、1つまたは複数のクアッドで、Shaderプロセッサのクラスタが構成され、クラスタ単位でバッチの制御が行なわれる。例えば、Radeon X1800(R520)ではShaderクアッドが1クラスタだが、Radeon X1900(R580)では3個のShaderクアッドが実質的に1クラスタとなった。つまり、R520では4個のShader、R580では12個のShaderが、クラスタとしてまとめて制御されていることになる。
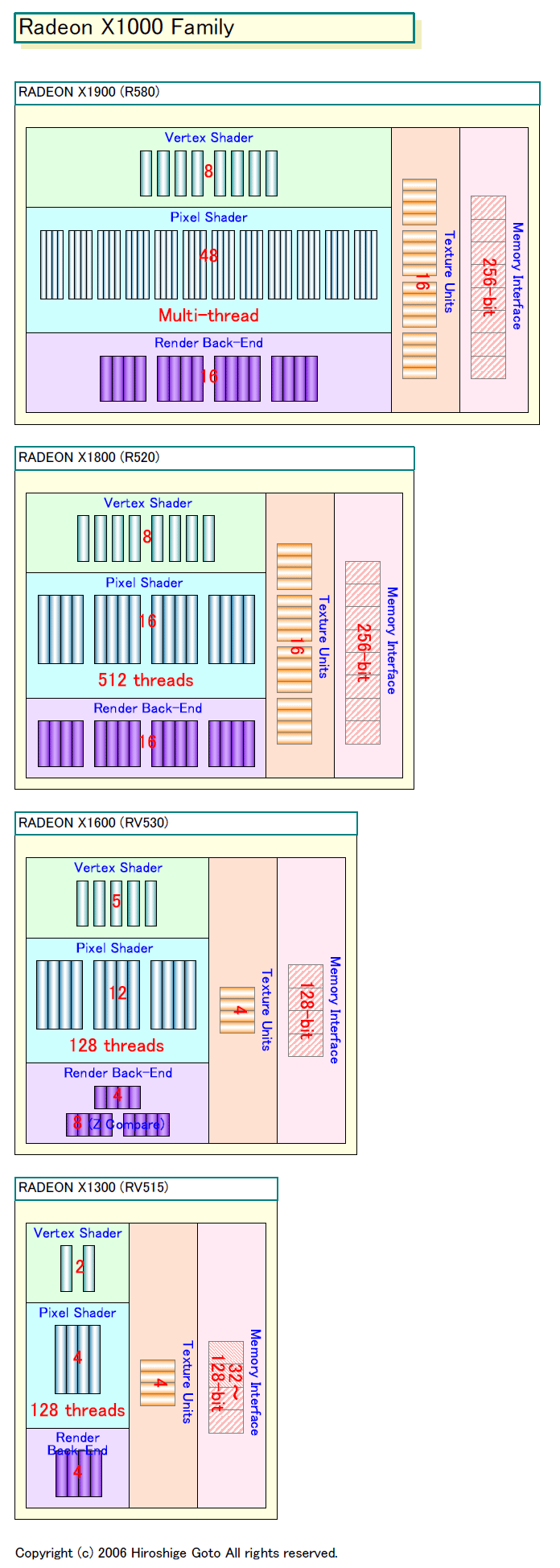 |
| Radeon X1000 Family (別ウィンドウで開きます) PDF版はこちら |
Shaderプロセッサがある程度の粒度を持っており、さらに個々のShaderプロセッサがパイプラインで多数のオブジェクトをオンザフライで扱う。バッチは、クラスタ内のShaderプロセッサの数×パイプライン段数(カスケード実行数)となるため、バッチの粒度はある程度大きくなる。もっとも、これはGPUとしての効率を上げるためだ。
ピクセルプロセッシングなら、隣接するピクセルのタイルがバッチとしてクラスタに割り当てられる。このバッチサイズをある程度大きく取るのは、Shaderクラスタのプロセッシングの際に、データの局在性を高めないと、テクスチャキャッシュなどの効率が悪くなってしまうためだという。隣接したピクセル同士なら、同じテクスチャを使う可能性が高まる。
●220ステージで880個のピクセルをインフライトで扱うG70
Shaderプロセッサをクラスタ構成し、Shaderプロセッサに対してある程度の粒度のバッチを割り当て、Shaderの演算コア(ALU)がそのバッチに含まれるオブジェクトをカスケード式に実行する。こうしたGPUの基本的なスタイルは、最新のG80でも変わらない。
 |
| Shader:decoupled & multithreaded (別ウィンドウで開きます) PDF版はこちら |
「カスケードをする唯一の理由はレイテンシの隠蔽だ。G80でも依然としてこのように(カスケード実行)している。なぜなら、何千ものスレッドがある場合には、これがもっとも効率的な方法だからだ。1つのShaderあたり、多くのスレッドを同時に実行しようとしたら、カスケードだ」とKirk氏は語る。
ただし、どの程度のバッチの粒度でカスケードするかは、従来のNVIDIA GPUとG80で全く異なる。
「基本的には、G70とG80がやっていることのコンセプトは同じだ。しかし、G80ではずっとクラスタが小さくなっており、そのために効率がよくなっている。そこが大きく異なる」とKirk氏は語る。
ここでKirk氏が触れているクラスタとは、この記事の用語ではバッチを示すと見られる。従来のNVIDIAのGPUは、バッチの粒度が非常に大きかった。NVIDIAのホワイトペーパーによるとG70世代ではバッチは880ピクセルで構成されていたと言う。G70は4個のShaderプロセッサで構成されるShaderクアッドが1個のShaderクラスタとなっていた。そのため、これは1個のShaderプロセッサが220ステージで構成され、220個のピクセルをオンザフライで走らせていることを意味している。220ピクセル×4 Shaderプロセッサ = 880ピクセルが粒度となる。
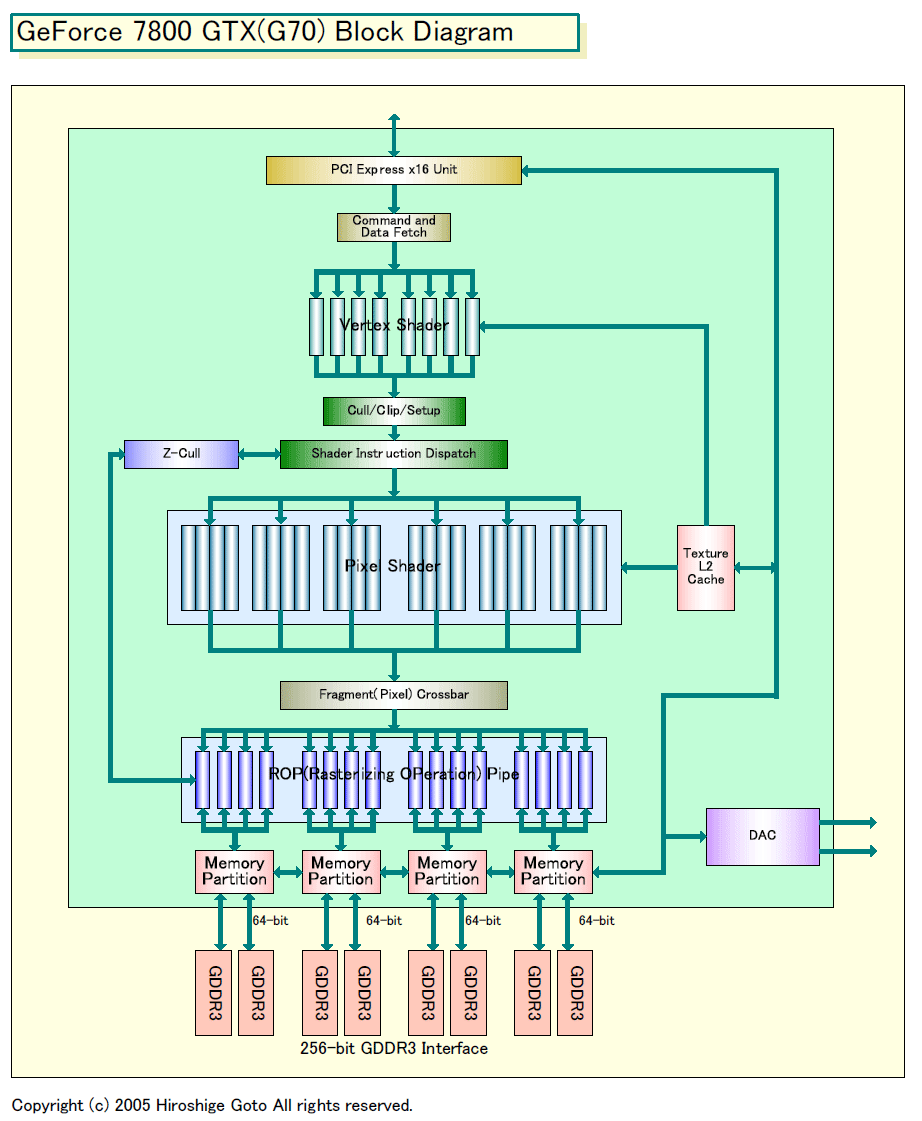 |
| GeForce 7800 GTX(G70)Block Diagram (別ウィンドウで開きます) PDF版はこちら |
それに対して、G80の場合、粒度は16または32ピクセルとなっている。G80では、16個のスカラ型のStream Processorでクラスタが構成されているので、データが4wayの場合の帯域は4ピクセルとなる。つまり、通常のGPUのShaderクアッドと同程度の演算リソースで、1つのクラスタが構成されている。そのため、パイプラインでカスケードする深さは4または8ピクセル(ステージ)となる。
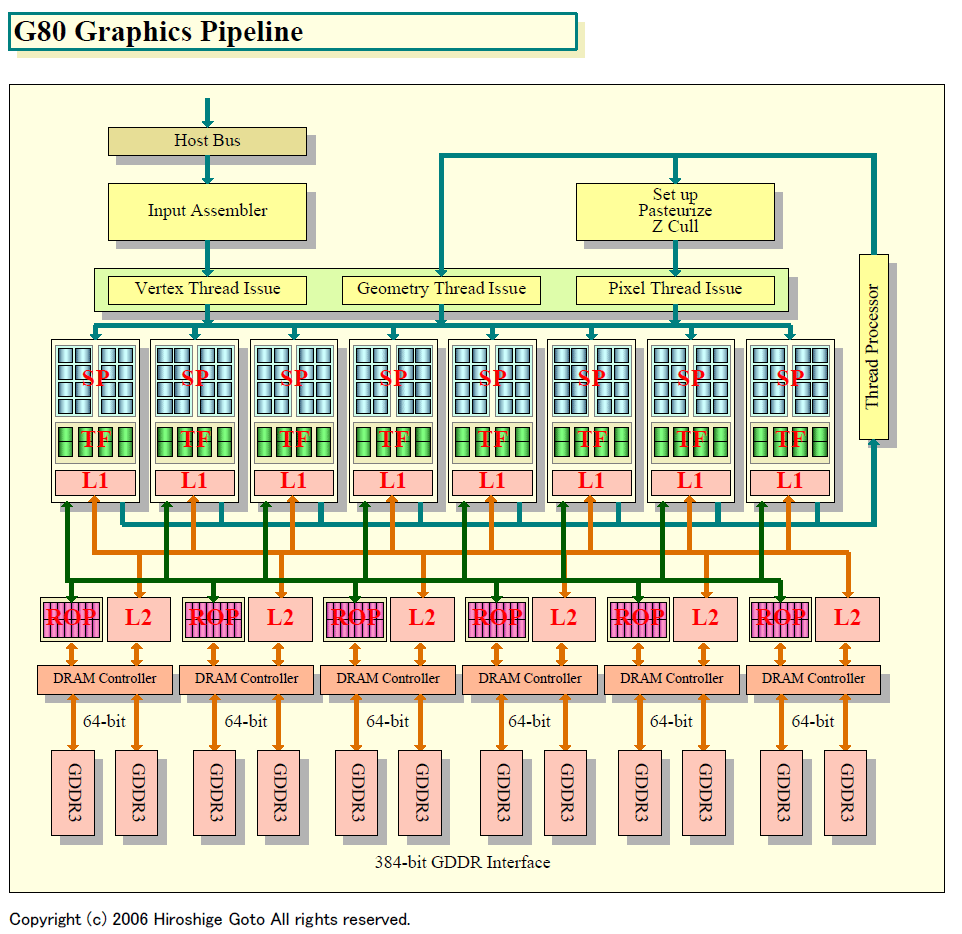 |
| G80 Graphics Pipeline (別ウィンドウで開きます) PDF版はこちら |
G70とG80で、どうしてここまで極端な違いが生じているのだろう。それは、G80では、Shaderプロセッサで動的なマルチスレッディング(バッチ切り替え)がサポートされ、演算コアとテクスチャユニットが分離され、Shaderクラスタの構成が大きく変えられたからだ。逆を言えば、Shaderプロセッサの制御の方式を変えたために、G80ではShaderプロセッサの構成が大きく変わったとも言える。
□関連記事
【11月14日】【海外】GeForce 8800世代のキーとなるマルチスレッディング
http://pc.watch.impress.co.jp/docs/2006/1114/kaigai317.htm
【11月9日】【海外】これがGPUのターニングポイント NVIDIAの次世代GPU「GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
【11月9日】NVIDIA、DirectX 10世代GPU「GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/nvidia1.htm
(2006年11月21日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.