 |


■後藤弘茂のWeekly海外ニュース■シェーダプログラムの進化と連動するGPUのマルチスレッディング化 |
●シェーダプログラムの進化に対応したGPUアーキテクチャの進化
 |
NVIDIAの新GPU「GeForce 8800(G80)」は、シェーダプログラム(GPUで走るグラフィックスプログラム)が進歩し、GPUの使い方が発展すればするほど高速になる。その主な理由の1つが、マルチスレッドアーキテクチャだ。
例えば、従来のGeForce 6/7(NV4x/G7x)では、条件分岐命令を使うと、パフォーマンスが落ちるケースが多い。しかし、G80では原理的にこうしたペナルティが少ない。また、G80では、1つのGPU上でグラフィックスと非グラフィックスプログラムを併存させても、原理的には高速に動作するはずだ。これらは、いずれも、マルチスレッド化したShaderプロセッサ制御の結果だ。
そのため、GPUがG8x世代へとシフトして行くと、ソフトウェアデベロッパ側の自由度が広がる。原理的には、分岐を多用し、またプログラムが非常に長いシェーダを書いてもスムーズに走る。また、GPU上の物理シミュレーションがデフォルトで使えると考えて、ソフトウェアを作ることもできるようになる。
●880ピクセルとバッチ粒度が大きいG70のアーキテクチャ
なぜ、シェーディング言語やプログラミングモデルの進化と、GPUのマルチスレッドアーキテクチャの進化は連動する必要があるのか。それは、GPUがCPUとは大きく異なる方法で、Shaderプロセッサを制御しているからだ。
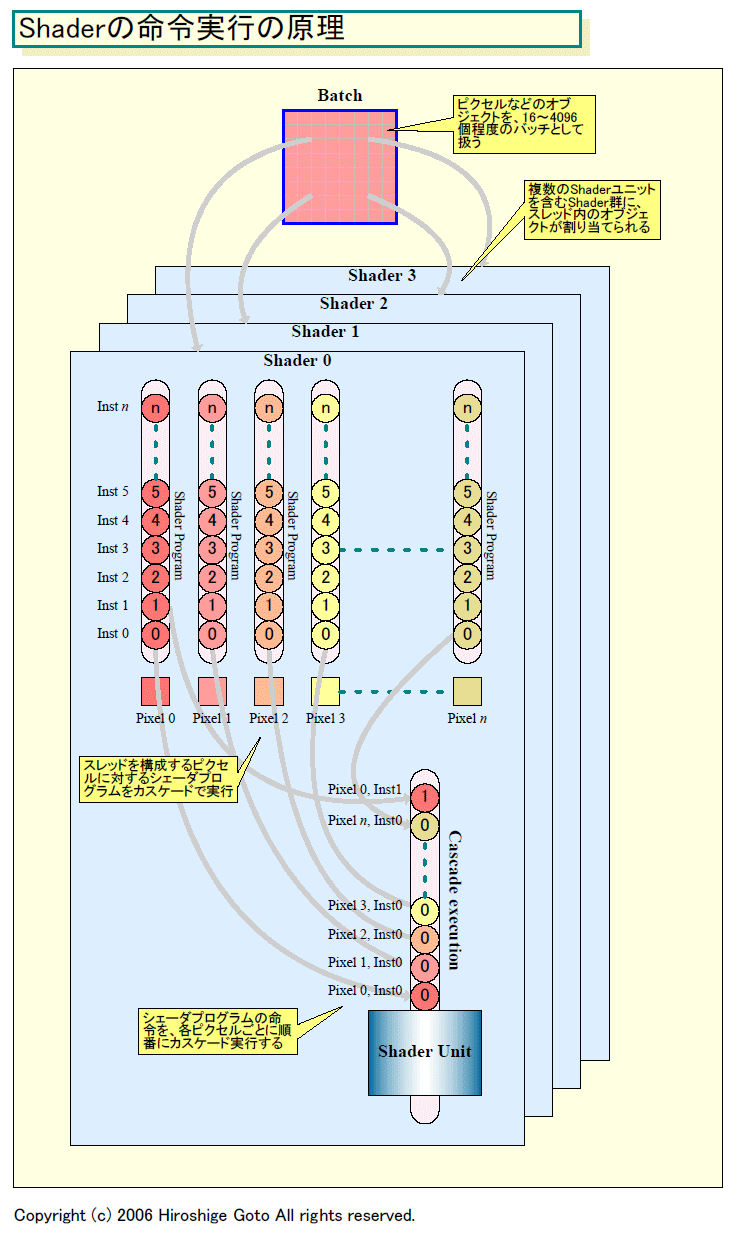
前回レポートした通り、GeForce 6/7(NV4x/G7x)では、NVIDIAはPixel Shaderプロセッサの内部で、処理対象のピクセルを自動的に切り替えるカスケード型の実行方式で、メモリレイテンシを隠蔽していた。NVIDIAは、このアーキテクチャもマルチスレッディングと呼ぶ。NVIDIAのNV40の論文(「THE GEFORCE 6800」, John Montrym & Henry Moreton, IEEE MICRO MARCH-APRIL 2005)では、各ピクセルに対して、シェーダプログラムのスレッドを1つ発行すると説明している。1ピクセルにつき1スレッドで、NV4x/G7xでは、これが最も低いレベルの“マルチスレッディング”となる。ただし、GPUメーカーや人によって、マルチスレッディングという単語の示すものは異なる。
NV4x/G7xでは、レイテンシをカバーするために、Shaderプロセッサクアッドに対して割り当てるピクセルの粒度を大きく取っていた。NVIDIAの技術ペーパー「Technical Brief NVIDIA GeForce 8800 GPU Architecture Overview」によると、G7x系のPixel Shaderプロセッサでは880個のピクセルが1バッチとしてプロセッシングされるという。「バッチ(スレッドとも呼ぶ)」は、Shaderプロセッサに発行するオブジェクト(ピクセルや頂点)の塊を指す。880個が1バッチということは、1個のShaderプロセッサが220個のピクセルをまとめて処理することを意味する。
なぜかというと、G7x系GPUでは、SIMD型Shaderプロセッサが4個で1クラスタに構成されているからだ。GPUは、通常4ピクセルをセットでプロセッシングするため、4個のShaderプロセッサがGPUのクラスタの最小単位となる。880ピクセルを4 Shaderプロセッサで割ると、1つのShaderプロセッサ当たり220ピクセルをオンザフライで走らせている計算になる。
言い換えれば、G7xは220ステージのパイプラインで、220個のピクセルをカスケード式に処理している。もちろん、Shaderプロセッサを220ステージに処理を細分化できるわけではないので、220ステージのほとんどはFIFO型キューになっていると推定される。命令実行が終わるとキューに入れ、220サイクル後に戻ってくるリング形式のキューだ。
●GPUに適したカスケード式の命令実行
カスケード実行では、n個のオブジェクトを実行する場合、nサイクルのレイテンシを隠蔽できる。だから、220個のオブジェクトをカスケードするなら、同じオブジェクトに対するプログラムの命令0と命令1の実行は220サイクルの間隔が開く。
命令0がテクスチャアクセス命令で、命令1がそのテクスチャを使う命令だった場合は次のようになる。命令0でテクスチャユニットに対してメモリアクセスのリクエストを出した後、220サイクル以内にテクスチャがメモリからロードされると、命令1は待つことなく実行できる。テクスチャキャッシュにヒットすれば数サイクル、DRAMにアクセスした場合は100サイクル以上。220サイクル間隔なら、低クロックなGPUなら間に合う可能性が高いと推定される。ただし、220ステージでも吸収できない場合には、この方式ではカバーできない。
 |
| Shaderの命令実行の原理 (別ウィンドウで開きます) PDF版はこちら |
カスケード型の切り替えによるメモリレイテンシの隠蔽の利点は、制御が非常に簡単なことだ。
CPUのマルチスレッディングのように、柔軟にスレッド(オブジェクト)を切り替えるケースを考えてみよう。その場合、1個のスレッドがメモリ待ちでストールした場合に、それを検知して、コンテクストをスワップ、別スレッドに切り替えるといった制御を行なう必要がある。また、リソースを監視して、データがロードされたら、ストールしていたスレッドに処理を戻すといった制御を行なわなければならない。CPUのように2~4個程度のスレッドでこうした制御を行なうのはまだ簡単だが、GPUのように数百ものスレッドを切り替えようとすると、制御は極めて複雑になる。
それに対して、カスケードさせる方式なら、制御のほとんどは単純な決め打ちなので、それほど複雑にならない。Shaderプロセッサは、各サイクル毎に処理するオブジェクトを自動的に切り変える。制御としては、各オブジェクトに割り当てた物理レジスタを、1サイクル毎に順番にリネームして、オペランドのレジスタに入れ替えると推測される。メモリレイテンシは、カスケード実行によって自動的に隠蔽され、メモリからのデータを使う命令を実行する頃には、データは既にロードされている。オブジェクトの数は決め打ちで、リソース管理でも複雑な制御を行なう必要がない。
そのため、メモリレイテンシの隠蔽という目的を達成するのに、もっともローコストな方法はカスケード実行となる。
「何千ものスレッド(オブジェクト)がある場合には、これ(カスケード)がもっとも効率的な方法だからだ。1つのShaderあたり、多くのスレッドを同時に実行しようとしたらカスケードが向いている」とNVIDIAのDavid B. Kirk(デイビッド・B・カーク)氏(Chief Scientist)は語る。
GPUは伝統的に、小さなプログラムで、大量のデータを連続してプロセッシングするストリーム処理に最適化されてきた。カスケード実行はこうした形態に最適化した方式だ。しかし、シェーダAPIの進化とともに、この方式には問題が起き始めた。動的な分岐がシェーダAPI側でサポートされたためだ。
●カスケード型の実行と相性が悪い条件分岐
一般にGPUのShaderプロセッサは、条件分岐命令が苦手だった。CPUでも条件分岐はコストが大きいが、従来のGPUの分岐ペナルティはもっとはるかに重い。その主因は、GPUではShaderプロセッサをバッチ単位で制御していることにある。
「従来のカスケードの場合、もし少ない数のスレッドしかないか、または(シェーダプログラムが)分岐した場合は、パイプラインにバブルが生じてしまう。そうした穴が(コンピューティングサイクルを)ムダにしてしまう」とKirk氏は説明する。
一般的に、カスケード実行では単純に、各オブジェクトに対する各命令を順番に実行するだけだ。そのため、シェーダプログラムに条件分岐命令が含まれる場合、カスケード実行では問題が生じてしまう。
なぜこうなるかは、カスケード実行の仕組みを考えればすぐにわかる。Shaderプロセッサは、シェーダプログラムの1個の命令をフェッチしたら、その命令でバッチに含まれる全オブジェクトに対して処理を行なう。1クロック毎に、オペランドを自動的に切り替えてフェッチして演算を行なう。1つのプログラムカウンタが、全オブジェクトで共有されているようなイメージだ。単純で効率がよい。
ところが、条件分岐命令が含まれると、話はやっかいになる。条件分岐があっても、全てのオブジェクトが同じ方向へ分岐する場合には話は簡単だ。プログラムカウンタをセットして、分岐先の命令をフェッチして、全オブジェクトに対して分岐先の命令を実行すると見られる。この場合は、条件分岐命令実行のオーバーヘッド(これも各GPUで異なる)だけで済む。全オブジェクトが分岐しなかった場合も同じことだ。
ところが、バッチの中のオブジェクトが、それぞれ異なる方向に分岐するとやっかいな話になる。分岐したオブジェクトと分岐しなかったオブジェクトで、次に実行する命令が違ってくるからだ。今までのように、単純にバッチの全オブジェクトに同じ命令を実行することができなくなる。何らかの制御が必要になる。
「G70では全てのShaderが全部が歩調を揃えた(動作)だった。だから分岐するとペナルティが大きかった」とKirk氏は語る。
●非常に効率が悪いGPUでの動的分岐の実行
GPUにおけるシェーダプログラムの動的分岐の問題については、NVIDIAよりAMD(旧ATI)がより積極的に情報を公開してきた。これは、AMD側が、より早く、Radeon X1000(R500)シリーズでこの問題に対応したからだ。例えば、AMDがWeb上で公開している、2006年10月の技術カンファレンスのプレゼンテーションでは下のように触れられている。
 |
 |
| Blocks of work in parallel in DX9... (別ウィンドウで開きます) PDF版はこちら |
Blocks of work in parallel... (別ウィンドウで開きます) PDF版はこちら |
 |
 |
| Understanding Dynamic Flow Control (別ウィンドウで開きます) PDF版はこちら |
DFC & Multi-Threading (別ウィンドウで開きます) PDF版はこちら |
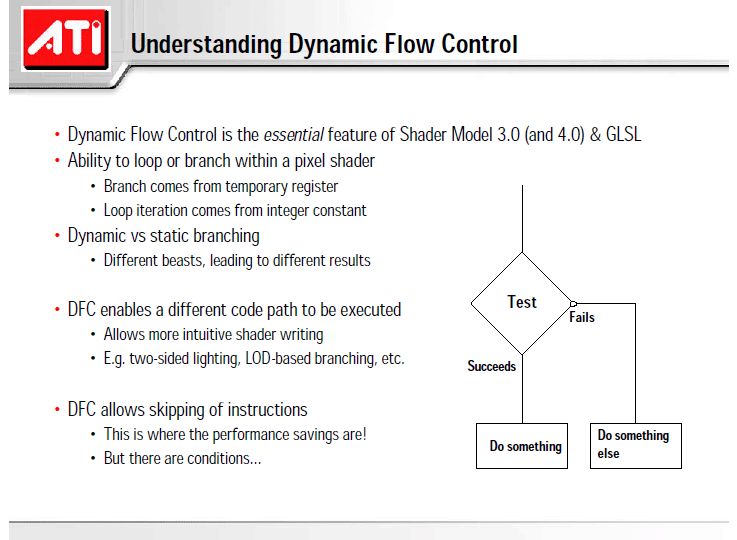
「if (a) then b else c」の論理で、常にトゥルーか常にフォールスなら、Shaderプロセッサはジョブを高速に実行できる。しかし、トゥルーとフォールスが混在すると、Shaderプロセッサの処理はハードになると説明されている。
条件分岐があると、オブジェクト毎に実行する命令が違ってくる。Shaderプロセッサでこれを実現する方法は2つある。1つは、Shaderプロセッサがプログラムカウンタをオブジェクト毎に持ち、命令をオブジェクト毎に入れ替える方法。分岐したオブジェクトについては、新たに分岐先の命令をフェッチする。この場合は、Shaderプロセッサ制御のシンプルさが失われてしまい、Shaderプロセッサが大型化する。もう1つは、バッチ中の全オブジェクトに対して両方のパスを実行してしまう方法。オブジェクト毎の分岐の結果によって、どちらのパスの演算結果をレジスタに書き込むかを制御するわけだ。IA-64 CPUのプレディケーション(predication)を動的に行なうような方法だ。この場合は、両分岐パスの全ての命令を実行するため、実行する命令数が膨大になるという難点がある。GPUの場合、後者の方法で実装していることが多いという。
いずれにせよ、どちらの方法を取ったとしても、Shaderプロセッサにとって動的分岐は負担が大きい。実行する命令数が多くなりGPUの効率が落ちる「分岐効率性(Branching Efficiency)」の問題が生じるか、Shaderプロセッサ制御が複雑になるからだ。
なぜGPUが、こんなブルートフォースの方法を取って来たかというと、シェーダプログラムでは条件分岐命令の多くは同じ方向へ分岐することが多いからだ。バッチに含まれる、ピクセルが、ほとんどのケースでは、同じ方向へ分岐するなら、多少無駄があっても、ハードを複雑にするより効率がいいというわけだ。例えば、バッチが100個あって、そのうち95個が片方向へしか分岐しない場合、オーバーヘッドが生じるのは残りの5個だけ。5%のケースのためにハードを肥大化させるのは無駄という考え方だ。
 |
| Spatial Coherency (別ウィンドウで開きます) PDF版はこちら |
●バッチ粒度を小さくしたR5xxとXenos
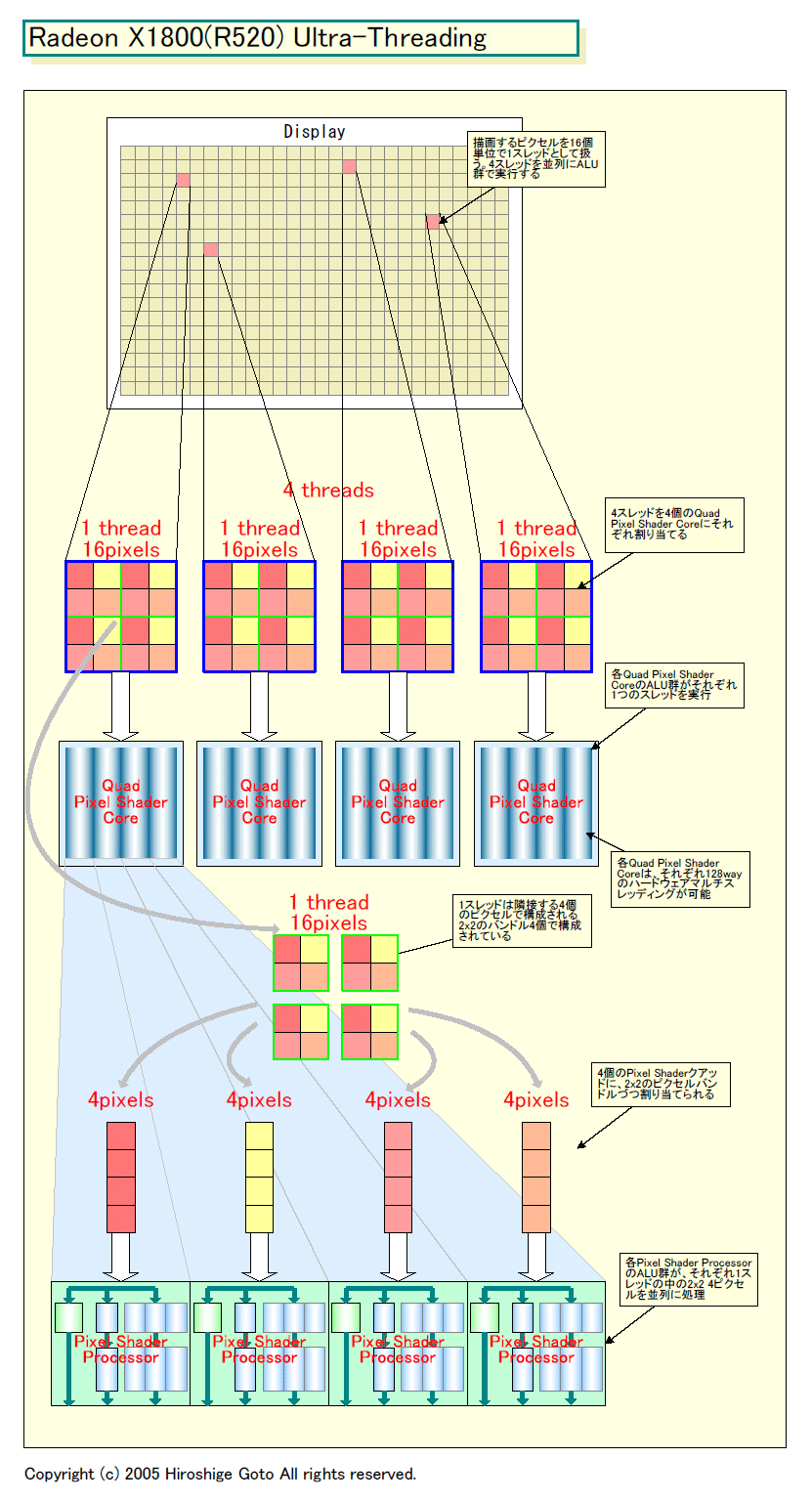
Radeon X1000(R5xx)系GPUやXbox 360 GPU(Xenos)では、この問題をバッチ(スレッド)粒度を小さくすることで解決した。R500ファミリでは、バッチのサイズは上のスライドにあったようにRadeon X1800(R520)で16ピクセル、Radeon X1900(R580)で48ピクセル、そしてR600で“ある数字”だという。Xenosではこれは64ピクセルだ。いずれも、NVIDIAの旧世代G7x系よりずっと小さい。
「4個のShaderプロセッサで構成されたバンドル1つに、16ピクセルのバッチ1個が割り当てられる。このバッチが1スレッドだ。1スレッドは4個の2×2ピクセルで構成されている」とRadeon X1800(R520)発表当時、AMDのアーキテクトは語っていた。
R520の場合、2×2のピクセルクアッドを、4個のShaderプロセッサでプロセッシングし、それを4サイクル続けるスタイルだ。R580の場合、Shaderプロセッサは12個単位となり、バッチサイズも3倍の48になる。Xbox 360 GPU(Xenos)の場合は、64ピクセルのスレッド(バッチ)を、16個のShaderプロセッサで構成されるクラスタに割り当てる。この場合も、各Shaderが4ピクセルずつプロセッシングする。実際には、4サイクル(4ステージ)かけて1クロックに1ピクセルずつプロセッシングしていると見られる。4ピクセルのクアッドを4サイクルで16ピクセル粒度となる。
これらのGPUはこのバッチの粒度で分岐を制御すると見られる。少なくとも、R5xx系はそう明記されている。そのため、バッチ粒度は「分岐粒度(Branching Granularity)」となる。
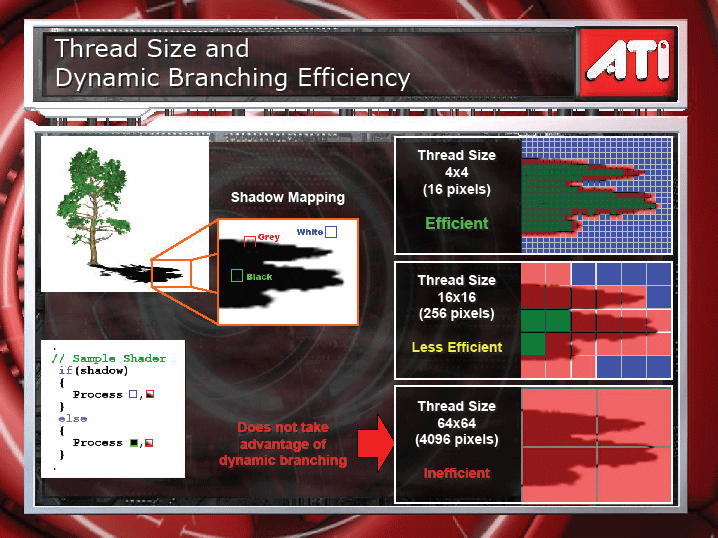
分岐粒度が小さくなると、分岐の効率はぐっと上がる。これは、AMDの下のスライドでよくわかる。これはシャドウマッピングの例で、右の図のタイルのうちブルーのタイルはシャドウがない部分、グリーンのタイルがシャドウの部分、レッドのタイルがシャドウとシャドウでない両方が含まれる部分。レッドの部分はシェーダプログラムの実行にオーバーヘッドが生じている部分で、ブルーとグリーンはオーバーヘッドがない。こうして見ると、粒度を小さくすればするほど、分岐の効率が上がることがわかる。右下の非効率なケースがNVIDIAのG7x系という比較となっている。
 |
| Thread Size and Dynamic Branching Efficiency (別ウィンドウで開きます) PDF版はこちら |
●メモリレイテンシを隠蔽するために動的なスレッディング
しかし、GPUがもともと大きなバッチ粒度を取っていたのは、メモリレイテンシを隠蔽するためだった。バッチのサイズを小さくすると、カスケード式に実行することで隠蔽できるレイテンシが短くなってしまう。すると、Shaderクラスタのプロセッシングの途中でメモリアクセス待ちなどが発生し、ストールが発生してしまう。
そこで、R500系の場合、Shaderクラスタに割り当てるバッチ(スレッド)を切り替えることで、この問題を解決する。伝統的なGPUの場合、Shaderのメモリアクセスはテクスチャフェッチなので、これは必然的にテクスチャデータ待ちとなる。R500系GPUでは、Shader側からテクスチャフェッチのリクエストを出した段階で、Shader側のスレッド(バッチ)を切り替えてしまう。R520なら16個のピクセル分のテクスチャフェッチのリクエストを出した時点で、スレッド(バッチ)を切り替える。
 |
| Radeon X1800(R520)Ultra-Threading (別ウィンドウで開きます) PDF版はこちら |
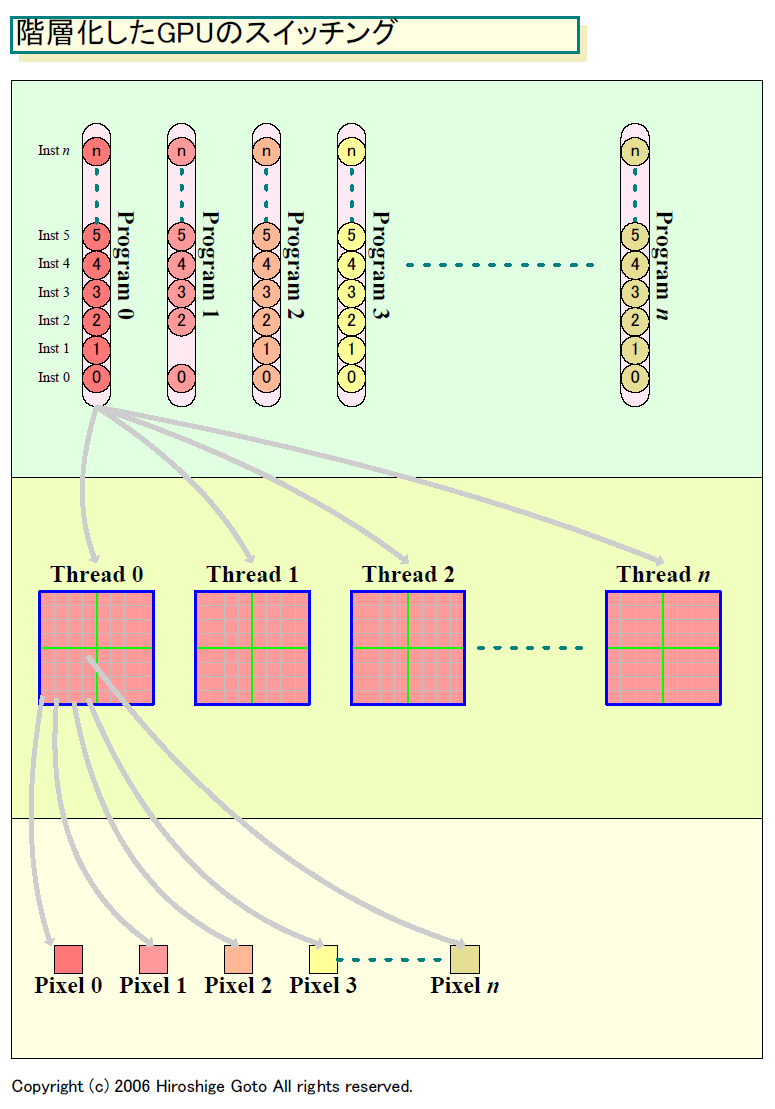 |
| 階層化したGPUのスイッチング (別ウィンドウで開きます) PDF版はこちら |
Shaderプロセッサ側はテクスチャ待ちの間、別スレッド(バッチ)のプロセッシングを行ない、その間にテクスチャパイプは独立してテクスチャのハンドリングを行なう。そのために、R500系のShaderの演算ユニット(ALU)とテクスチャパイプは完全に分離されている。Xbox 360 GPUも同様の構造になっている。G7xで、ALUとテクスチャが融合しているのは、この2つの間でスレッドを切り替えていないからだ。
AMDのこの実装方式は、スレッド(バッチ)の動的なハンドリングが必要になるため、GPUの複雑性を増してしまう。そのため、R520は、512ものスレッド(バッチ)をオンザフライで制御できるようにしている。R520は16 Pixel Shaderなので、各Pixel Shaderクアッド毎に128スレッドとなる。XenosはUnified-Shaderなので、頂点とピクセル合わせて最大94スレッド。
それだけの数のスレッドのマネージメントには、トランジスタのコストが必要になる。しかし、動的分岐の実行では有利となる。つまり、シェーダプログラムが進化すると、アーキテクチャの利点が活きてくることになる。
●分岐粒度が極めて小さいG80
それに対して、NVIDIAはG7x世代でもこうした動的分岐への最適化は、あまり行なわなかった。G7xはマイナーチェンジで、NV4x系のアーキテクチャを引きずっていたためと見られる。しかし、手をこまねいていたわけではなく、G80で一気に改善を図った。
「G80でも依然としてこのように(カスケード実行)している。なぜなら、これが最も効率的だからだ。しかし、G70とG80の違いは、実行しなければならない(バッチの)サイズにある。それは、分岐の粒度と関係している。G80では分岐の粒度はG70よりずっと小さい。だから、分岐による非効率もずっと小さい」「G80では、非常に小さなスレッド(オブジェクト)数の、軽量のコンテキストだ」とKirk氏は指摘する。
G80では、カスケーディングも行なうが、動的にスレッド(バッチ)を切り替えることでもメモリレイテンシを隠蔽するようだ。NVIDIAは、G80での分岐粒度は16または32ピクセルだと明かしている。粒度で比べるとR520と同等になる。
下がNVIDIAのスライドだ。この図には疑問もあるが、意味的には、G80の分岐粒度は大きくても32ピクセルなので、同方向へ分岐する4×4タイルが2個であっても分岐効率は100%になるという説明と見られる。もちろん、AMD側からも反論が出てくると見られる。
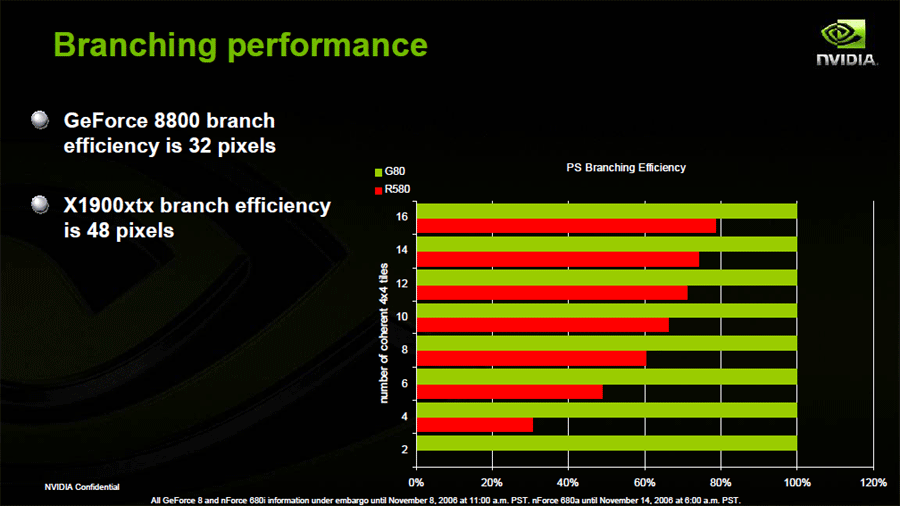 |
| Branching performance (別ウィンドウで開きます) PDF版はこちら |
NVIDIAはG80のマルチスレッディングの詳細は明らかにしていないが、このことから、G80でも、依然として粒度を保ってShaderプロセッサがカスケード式にプロセッシングを行なっていることがわかる。完全に1ピクセルずつ分解してプロセッシングを行なうわけではなさそうだ。一般的には、GPUでは2×2のピクセルクアッドは分解して効率的にプロセッシングすることが難しいため、2×2の4ピクセルが現実的な最小単位になると言われる。
●レジスタを動的にスレッドに割り当てる
NVIDIAは、G80では、粒度の小さなスレッドの、動的な切り替えも行なうことを明かしている。
「G80ではスレッドは自由に切り替えられる。命令自体はインオーダ(順番に)で実行するが、スレッドはアウトオブオーダ(順番を入れ替えて)で実行する」とNVIDIAのTony Tamasi氏(Vice President, Technical Marketing)は語る。
スレッドを切り替えることで、カスケードでは吸収仕切れない、メモリのレイテンシを隠蔽するという思想だ。G80のこうした基本的な考え方はR500やXenosと同じだと見られる。G80でも分岐粒度が維持されているため、おそらく、分岐粒度の単位でスレッド(バッチ)を切り替えるものと見られる。
スレッドを切り替えるため、G80の各Shaderクラスタには、共有の大きなレジスタファイルがある。
「レジスタ群は、ハードウェアのコンピューティング部分の共有レジスタとなっている。プロセッサ群に完全にビルトインされたリソースで、(Shaderクラスタから)分離されてはいない。
レジスタスペースは各スレッドに専用になっている。ただし、スレッド毎にレジスタ数は固定されていない。スレッド数が増えればレジスタ数が減る。もしスレッド数が多ければ、1スレッド当たりのレジスタ数が少なくなる。これはトレードオフだ。スレッド数が多ければ、メモリレイテンシをより隠蔽できる利がある。スレッド数が少なければ、それぞれのスレッドがより多くのリソースを使うことができる利がある。バランスだ。
これはXenosでも同じ構造となっている。Xenosは合計24,576本のベクタレジスタを持ち、それが動的にスレッドに割り当てられる。Xenosの場合は、頂点処理とピクセル処理のスレッド(バッチ)バランシングも、レジスタ群の割り当てで行なう。これは、プログラム側で明示的に行なうこともできる。
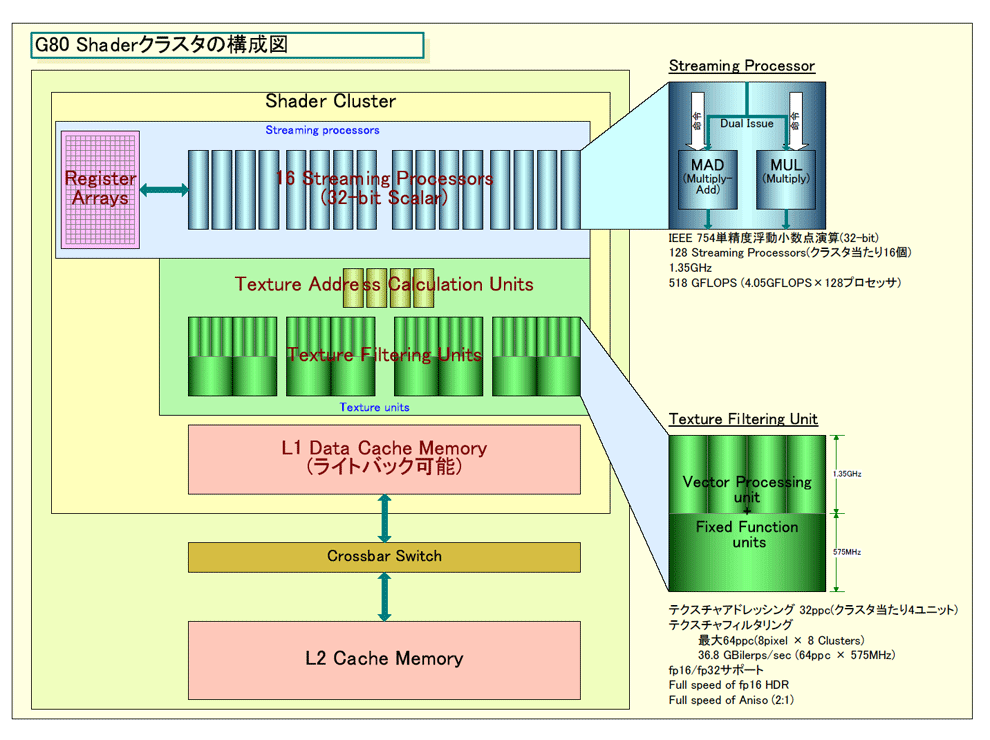 |
| G80 Shaderクラスタの構成図 (別ウィンドウで開きます) PDF版はこちら |
●1ピクセル単位での制御がGPUの理想
それに対して、G80ではスレッドとレジスタの連携は、全てハードウェア側で行なう。
「(スレッドへのレジスタ割り当ては)ハードウェアで管理する。我々のアーキテクチャの哲学は、できる限りハードウェアで行なうことだ。プログラマが、できる限り多くのことをコントロールできるようにしたいというのもわかる。しかし、プログラマがそうした選択を望まないのなら、ハードウェアが合理的な選択をできるようにしたい。多分、プログラマはそれを望まないだろう。なぜなら、それは非常に複雑だからだ。
我々は全ての管理をハードウェアで可能にしている。ロードバランシング、スケジューリング、スレッディング、全てがハードウェアでできる。そして、ハードウェアはかなりうまくやっている。なぜなら、プログラマをあてにしないでいいからだ。これはGPUの強みだと考えている。CPUの哲学とは非常に異なる。全てはハードウェアでスケジュールする。ハードウェアは、ある面、より自己認識的だ」とKirk氏は設計思想を語る。
つまり、G80では、スレッド(バッチ)のスケジューリングや、頂点やピクセルといったスレッド(バッチ)間のロードバランシングなど、全てをハードウェアで制御する。ソフトウェア側からは、ブラックボックス化されている。
また、G80では異なるコンテクスト(プログラム)のスレッドを、GPUの中で並列に走らせることもできる。
「G80が1つのシェーダプログラムの多数のピクセルを走らせている時に、シェーダプログラムを替えると、さらに多くのピクセルが立ち上げられ(実行パイプラインに)ミックスされる。
これは分岐粒度とは異なる。分岐粒度はクラスタに依存する。しかし、G80では、それぞれのShader(プロセッサ)に、同じプログラムを走らせる必要すらない。走らせるのは異なるプログラムでもいい。(走らせるプログラムやオブジェクト)全てが違っていてもいい。カスケードをする唯一の理由はレイテンシの隠蔽だ」とKirk氏は語る。
ここだけを聞くと、G80のShaderプロセッサは、完全に自由にスレッドやプログラムを入れ替えられるように聞こえる。しかし、分岐粒度が16~32と保たれているため、依然としてある程度の粒度で同期した処理を行なっている可能性が高い。また、異なるコンテクストのオブジェクトは、異なるShaderクラスタに割り当てられると推定される。いずれにせよ、マルチスレッド化されたShader群で、複数のコンテキストが並列に実行されることになる。
GPUにとって理想は、1ピクセル単位での制御だ。そうすればCPUと同様の完全な分岐効率が得られる。しかし、そうすると、Shaderプロセッサの複雑さが増大して、トランジスタ当たりのShaderプロセッサ数が減ってしまう。動的なスレッド切り替えが、何千スレッドにも達してしまい、制御機構が肥大化することになる。すると、GPU全体の演算能力が落ちて、本末転倒になってしまう。おそらく、近い将来で実現するのは、まず2×2のクアッド、4オプジェクト単位のバッチでの制御となるだろう。
GPUは演算パフォーマンスとコントロールフローの効率というトレードオフの間でバランスを取っている。以前は、演算にだけ偏重していたが、シェーダプログラムAPIの進化に合わせて、コントロールフローの効率化を図りつつある。GPUハードの進化がシェーダプログラムの進化に対して、遅れても先に行き過ぎても、GPUのパフォーマンスは落ちる。
そのため、GPUベンダーは、慎重にシェーダプログラムの進化と歩調を合わせる必要がある。今回、NVIDIAはDirectX 10への移行が、シェーダプログラムの飛躍点になると判断したようだ。
□関連記事
【11月21日】【海外】G80とG7xの最大の違いはマルチスレッディング
http://pc.watch.impress.co.jp/docs/2006/1121/kaigai320.htm
【11月14日】【海外】GeForce 8800世代のキーとなるマルチスレッディング
http://pc.watch.impress.co.jp/docs/2006/1114/kaigai317.htm
【11月9日】【海外】これがGPUのターニングポイント NVIDIAの次世代GPU「GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/kaigai316.htm
(2006年11月27日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.