 |


■後藤弘茂のWeekly海外ニュース■これがGPUのターニングポイント
|
●C言語でプログラムできる500GFLOPSのプロセッサ
NVIDIAの次世代GPU「GeForce 8800(G80)」がついにそのベールを脱いだ。その正体は、驚くほど革新的だった。Unified-Shader(ユニファイドシェーダ)型アーキテクチャでDirectX 10準拠というだけではない。G80は、それを超えたフィーチャを多数備えていたからだ。そして、G80の新フィーチャの多くは、GPUを、より汎用的なコンピューティングに応用するのに向いている。
 |
| G80 Graphics Pipeline(※別ウィンドウで開きます) PDF版はこちら |
 |
| 【動画】G80の流体シミュレーションデモ(WMV形式、約1.03MB) |
G80の最大のポイントは、極めて高いグラフィックスパフォーマンスを維持しながら、より広い汎用性を獲得したことだ。G80は「シェーダ言語でアクセスできる高性能グラフィックスチップ」と、「C言語で利用できる膨大な浮動小数点並列プロセッサ」という2つの側面を持つ。言い換えれば、グラフィックスプログラマだけでなく、ジェネラルなプログラマに対して開かれたプロセッサになった。これを示すために、NVIDIAは、G80のデモでは流体シミュレーションをフルにGPUで行なうデモを見せた。ゲームに使われ始めたような簡易な流体シミュレーションではなく、以前ならスーパーコンピュータクラスだった粒度の小さい煙のシミュレーションデモだ。
G80では、プログラマはC言語で、500GFLOPSを超える浮動小数点演算パフォーマンスを扱うことができる。ワンチッププロセッサでは最高峰の「Cell Broadband Engine(Cell)」の約2倍のパフォーマンスだ。しかも、従来のGPUのように、汎用的な処理ではいきなりパフォーマンスが落ちることがないアーキテクチャを備える。
これまで、GPUとしての性能を持ちながら、広い汎用性を実現することはできなかった。試みはあったが、汎用性を高めるとグラフィックス性能が削がれてしまった。そのため、これまでのメインストリームのGPUは、プログラム性が限定された固定機能プロセッサとして進化してきた。
しかし、G80は、それを破りながら、高いグラフィックス性能も保つことが可能であることを立証した。NVIDIAを率いるJen-Hsun Huang氏(Co-founder, President and CEO)は昨年(2005年)、「GPUは21世紀のDSPになる」と語っていたが、そのビジョンはG80で実現し始めた。GPUの歴史の、1つのターニングポイントになることは間違いないだろう。NVIDIA自身も、G80の革新性を十分に認識している。
「マーケティングサイドでは新製品を出す度に『今回の製品は革新的』と謳うが、実際にはそんなのはマーケティングトークであって真実ではない(笑)。しかし、今回は違う。G80は真に革新的な製品だ。そして、これから先のNVIDIAの製品の基礎となる」とNVIDIAの技術開発部門のトップであるDavid B. Kirk(デイビッド・B・カーク)氏(Chief Scientist)は語る。
 |
 |
| NVIDIAのJen-Hsun Huang氏 | David B. Kirk(デイビッド・B・カーク)氏 |
●DirectX 10世代GPUに求められる以上のフィーチャを備えたG80
G80のスペックをGPU的に表すと下のようになる。
◎Unified-Shader型アーキテクチャ
◎DirectX 10(Direct3D 10) Shader Model 4.0準拠
◎128ストリームプロセッサ
◎96 ROP
◎384bitメモリインターフェイス
表に見えるGPUスペックだけだと、G80は、進歩しているものの、今後のトレンドとなるUnified-Shader型のDirectX 10世代GPUの1つにしか見えない。しかし、これはG80の表の姿、言ってみれば氷山のうちの水面に出ている部分であって、G80の全体像のごく一部しか表していない。G80の真に特徴的な部分は、じつはこうした表に見えるスペック以上の部分にある。簡単に特徴をまとめると下のようになる。
◎倍速動作のShader演算コア
◎極めて粒度の小さなマルチスレッディング
◎ライトバック制御が可能なキャッシュ
◎Shaderの命令セットアーキテクチャ(ISA)の公開とCコンパイラの提供
◎スカラ型のIEEE 754“準拠”ストリームプロセッサ
◎ハードウェアベースのコンテクストスイッチング
上に挙げたフィーチャはかなり特徴的であり、また、DirectX 10サポートのためだけなら実装する必要がない機能も多い。つまり、G80は単にDirectX 10対応のUnified-Shader型GPUではない。
これは、NVIDIAがG80世代で見ているのがDirectX 10によるグラフィックス処理だけではないことを意味している。それを象徴するのがCコンパイラの提供だ。G80のプログラミングモデルは、従来のGPUのようにDirectX/OpenGLのAPIとシェーダ言語を通じたものに限らない。NVIDIAは、Cコンパイラを提供し、プログラマがCPUと同様にCでプログラミングできるようにする。DirectX 10とは全く分離したアプローチだ。
もっとも、これらのフィーチャも、GPUの今後のテクノロジとして予想されていなかったわけではない。コンテクストスイッチはNVIDIAは以前から実装していたし、倍速Shaderは次世代のGPUでは予想されていた。マルチスレッディングの粒度の縮小とライトバックキャッシュ、ISAとコンパイラの公開、IEEE準拠も、今後2~3年のGPUの技術トレンドとしては想定できていた。
しかし、G80が驚異的なのは、そうした将来GPUで予想されていた進化の要素を全て含んでいることだ。また、高パフォーマンスを維持した効率的な実装が極めて難しい要素を多数含んでいる。開発に時間がかかると推測していた要素も、全て詰め込んだのがG80だ。そのため、ほかのGPUが、短期間にこれらのフィーチャに追いつくのはかなり難しいと推定される。
●G80アーキテクチャを隠し通したNVIDIA
このコラムを含めて、多くの記事が2カ月程前まではNVIDIAのG80はUnified-Shader型ではなく、独立型Shaderアーキテクチャを採ると予想していた。その理由は簡単で、同社の技術部門を率いるDavid B. Kirk氏が、インタビューの度にUnified-Shader型の難点を指摘していたからだ。例えば、Kirk氏は今年3月に、次のように語った。
「Unified-Shaderハードウェアはいつ頃が適切なのか、それが問題だ。私も、将来は、GPUがよりシンプルな設計となり、より少ない種類のプロセッサになるだろうと思う。しかし、それには時間がかかり、一度にはできない。変化は漸次的に起こるだろう」、「また、(Unified-Shaderにすると)コストが大きい。Unified-Shaderはフレキシブルだが、必要以上にフレキシブルだ」
通常、GPUベンダーは自社の次期製品への期待を高めるために、先進の技術を取り入れる場合は、幹部がそれを匂わす発言をすることが多い。ところが、今回のG80では、NVIDIAはそれと全く逆の方法を採った。エグゼクティブが、できる限り、G80のアーキテクチャを気取られないように、煙幕を張っていた。記事をミスリードして、アーキテクチャを想定できないようにした。
G80のベールがはがされてみると、NVIDIAがそれだけ必死にG80を隠した理由がよくわかる。G80は、それだけ野心的な試みであり、NVIDIAとしてはライバルにわずかでもその内容を知られたくなかったに違いない。
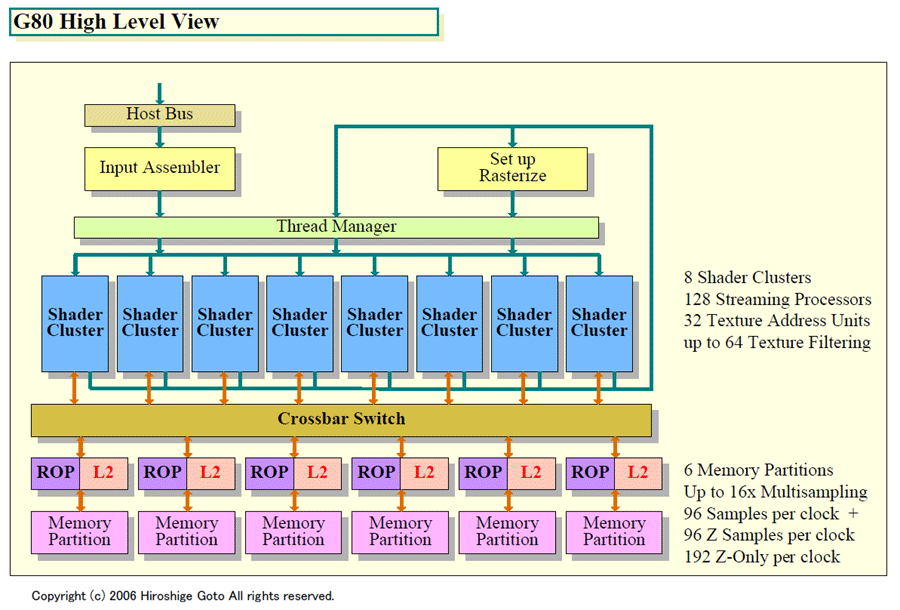
●クラスタ化されたG80の全体像
G80の全体構造を大きなレベルで見ると下の図のようになる。G80は、8個のShaderクラスタと6個のメモリパーティションに密着したROP(Rasterizing OPeration)サブシステムを持つ。その間をクロスバースイッチで結んだ構成で、この基本スタイルは、NV40/G70系(GeForce 6/7)と同じだ。
 |
| G80 High Level View(※別ウィンドウで開きます) PDF版はこちら |
G80のNV40/G70系との大きな違いは言うまでもなく、演算ユニット「Programmable Shader」がUnified-Shaderになっていることだ。DirectX 10のDirect3D 10(D3D10)では、頂点処理を行なう「Vertex Shader」、プリミティブ処理を行なう「Geometry Shader」、ピクセル処理を行なう「Pixel Shader」の3種類のShaderが定義されている。G80を始めDirectX 10準拠のGPUでは、これらのShaderを、統合された1種類のShaderで処理する。1種類のUnified-Shaderが、処理によってVertex/Geometry/Pixel Shaderの各Shaderとなる。
G80のShaderクラスタは、それぞれが完全に同じ機能を備えたクラスタとなっている。Shaderクラスタは、スレッド(エグゼキューション)マネージャによって制御されている。スレッドマネージャが、各Shaderクラスタの中の演算エレメントに対してのスレッド割り当てを管理し、またリソースをトラック、コンテクストを保持する。
Vertex/Geometry Shaderからのアウトプットは、セットアップ/ラスタライズを行なうユニットを通してピクセルに変換され、再びシェーダクラスタに戻される再帰型の構造となっている。
シェーディング処理されたピクセルは、クロスバスイッチを経由して対応するメモリパーティションに密着したROPユニットに送られる。また、ROPを通さずに直接メモリに書き込むこともできる。
●スカラプロセッサで構成したShaderクラスタ
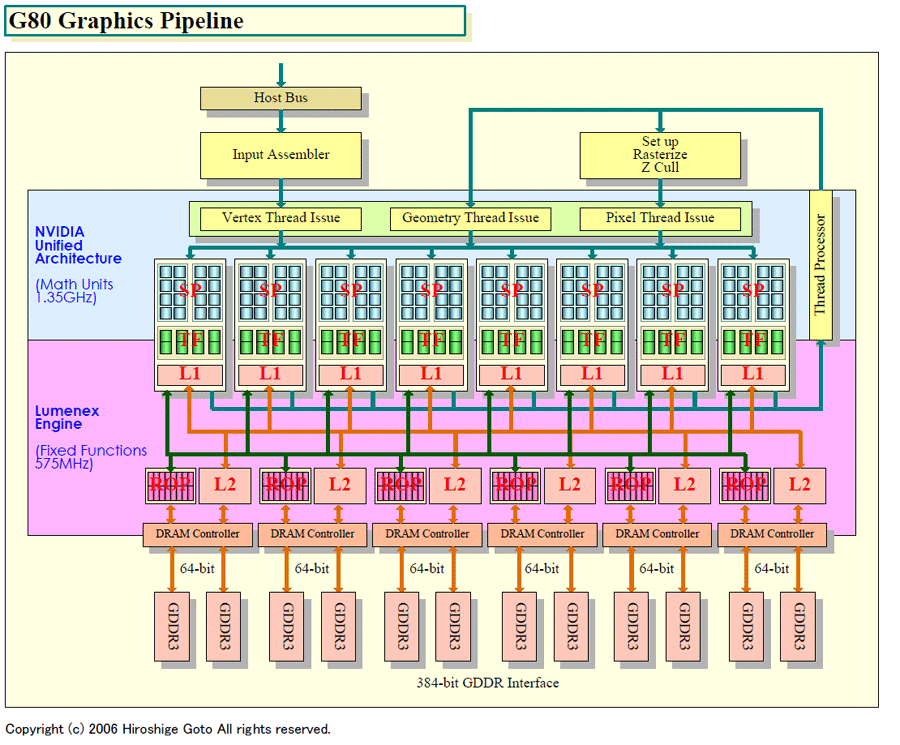
G80のグラフィックスパイプラインをもう少し詳しく見ると下の図のようになる。
 |
| G80 Graphics Pipeline(2)(※別ウィンドウで開きます) PDF版はこちら |
各Shaderクラスタには「SP」すなわち「Streaming Processor」または「Stream Processor」と呼ばれる演算プロセッサが16個並んでいる。この他にテクスチャユニットとL1データキャッシュがセットになってShaderクラスタを構成している。
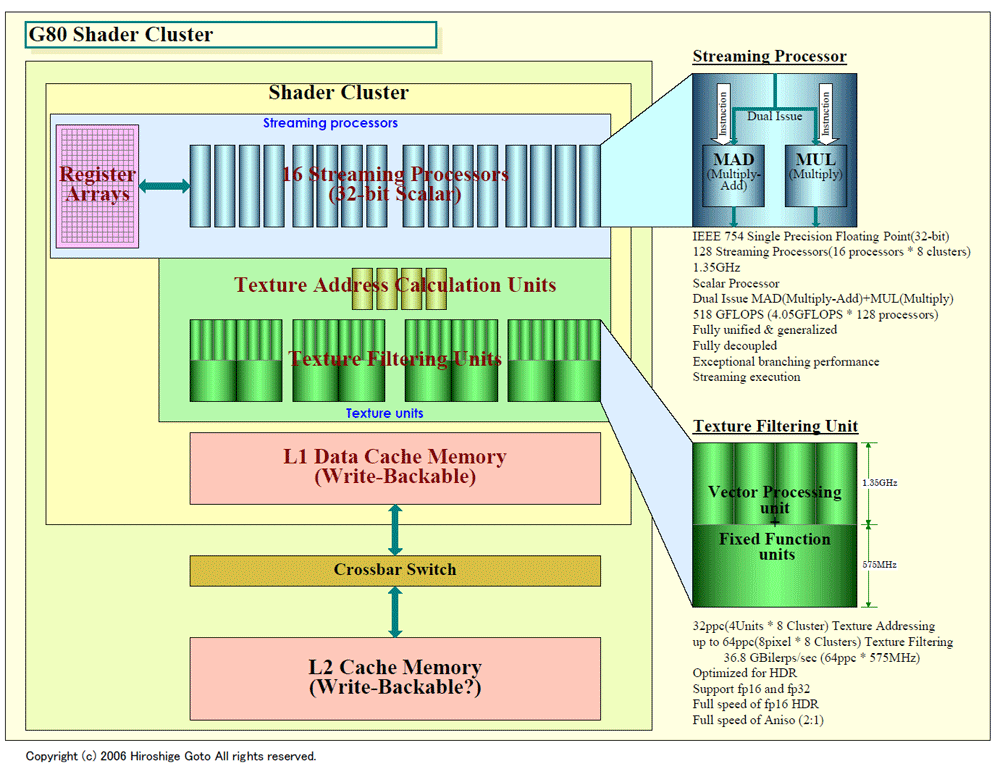
下がG80のShaderクラスタの詳細図だ。NVIDIAは今回Shader内部の図を公開していないため、NVIDIAからの情報を元に独自に作成した。
 |
| G80 Shader Cluster(※別ウィンドウで開きます) PDF版はこちら |
Shaderプロセッサで目立つ違いは、SPがスカラ型である点と、テクスチャパイプと完全に分離されている点だ。従来のGPUは、ベクタ型の演算ユニットを備えていたが、G80のストリームプロセッサはスカラ型の32bit浮動小数点演算プロセッサとなっている。各SPは、32bit単精度の演算ユニットを2つ備え、両ユニットに対して命令の並列発行が可能なデュアルイシュープロセッサとなっている。演算ユニットは片方が積和算(MAD:Multiply-Add)ユニット、もう片方が積算(MUL:Multiply)ユニットとなっている。
NVIDIAは、今回、SPとテクスチャユニットの中の数値演算ユニット部分を1.35GHzで動作させている。これは数値演算ユニット部ならCPUと同様に高クロック化が容易であるためだ。それ以外のGPUの固定機能ユニット部は575MHzで動作させている。固定機能部分は高速化が難しいためだ。
つまり、従来なら固定機能ユニットに足を引っ張られてGPU全体を低クロックで動作させなければならなかったのを、G80では演算コアのクロックドメインを分離して倍速(2.34倍)動作をさせている。演算コアの倍速化は、Unified-Shader型の今後のGPUでは、おそらく一般的になって行くと見られる。ちなみに、NVIDIAは高クロックの演算コア部には「NVIDIA Unified Architecture」、通常クロックの固定機能部には「Lumenex Engine」というマーケティングネームをつけている。両ブロックの切れ目がテクスチャユニットの真ん中にあるのは、演算ユニットと固定機能ユニットの分かれ目がそこにあるからだ。
テクスチャアドレスユニットは4ユニット。毎クロックサイクルに4個のアドレスの生成が可能だ。テクスチャフィルタリングユニットは、最大で8ピクセル/サイクルのFP16テクスチャのフィルタリングが可能だ。
●ライトバックが可能なキャッシュメモリ
ROPユニットは、各メモリパーティション毎にクラスタ化されている。ROPのスペックはかなり異常で、G80全体で最大96個のカラーサンプルと96個のZサンプルの処理が可能となっている。メモリ帯域に対してのROPの処理能力が大幅に増えているのは、Zとカラーの圧縮技術が向上し、前世代より2倍の圧縮が可能になったためだという。
また、アンタイエイリアシング(AA)は最大16xが可能となっているが、これは新しい「CSAA(Coverage Sampling Antialiasing)」を導入したことによる。CSAAでは、プリコンピュートによって、AAのボトルネックとなるメモリ書き込みを減らす。
NVIDIAは、GeForce 6800(NV40)からDRAMコントローラをメモリパーティションに分割して扱うアーキテクチャを採っている。各メモリパーティションは64bit幅のDRAMインターフェイス単位となっている。GeForce 7800 GTX(G70)まではメモリパーティションは4つで合計256bit幅のDRAMインターフェイスだった。しかし、G80ではメモリパーティションが6個に増え、それに伴いDRAMインターフェイス幅も384bitに増えている。
NVIDIAはAMD(旧ATI)のように32bit幅のDRAMインターフェイス単位に分割はしなかった。AMDが32bit幅にしたのはデータプリフェッチの粒度が大きくなるGDDR4への対応のためだ。GPU側のインターフェイス幅とGDDRアーキテクチャには密接な関係がある。NVIDIAはGDDR4を見送ったことでDRAMインターフェイスの制御単位も64bitに留めたことになる。
 |
| G80 Pixel Engine(ROP)(※別ウィンドウで開きます) PDF版はこちら |
G80では、ROPユニットと並列してL2データキャッシュがある。G80では、L1データキャッシュがShaderクラスタ側にあり、キャッシュも階層構造になっている。G80のキャッシュは、伝統的なGPUのキャッシュとは大きく異なる。また、CPUともキャッシュ階層や制御は異なっている。
最大の違いは、G80のキャッシュがライトバック可能なこと。伝統的なGPUのデータキャッシュ(テクスチャキャッシュ)はリードバッファで、Shaderがモディファイしたデータをライトバックできなかった。モディファイしたデータは、直接メモリに書き込んでいた。それに対して、G80の場合は、データをキャッシュにライトバックできる。それも、必ずライトバックするのではなく、プログラム毎に制御が可能となっている。これは、汎用的な処理の場合には、大きな威力を発揮する。
●CコンパイラとライブラリをNVIDIAが提供
下は、G80のプログラミングモデルのオーバービューだ。今回、NVIDIAはGPU向けにスタンダードなC言語のコンパイラやライブラリを提供する。同社は、この一連の技術を「CUDA (クーダ:compute unified device architecture)」と呼んでいる。
 |
| G80 Programming Model(※別ウィンドウで開きます) PDF版はこちら |
ではCUDAのCコンパイラは、NVIDIAがGeForce FX 5800(NV30)で導入した言語「Cg」の場合と何が違うのか。まず、Cgでは新しい言語を定義してコンパイラを提供したが、今回は標準的なC言語のコンパイラを提供する。Cgはグラフィックス処理向けのシェーディング言語だったが、今回は汎用処理向けとなっている。従来は、非グラフィックス処理の場合もシェーダプログラムとして書き、グラフィックス処理のように見せかける必要があったが、CUDAのモデルではそうした面倒はなくなる。
また、これまではGPUのネイティブのISAは隠蔽し、プログラマからはグラフィックスAPI以外は見えないようにしていた。それに対して今回は非常に薄いランタイムでラップしただけで、より低いレベルでハードにアクセスできるという。また、コンパイラでCPUのオブジェクトコードも生成することで、GPUとCPUでモジュールを入れ替えてロードバランスするようなライブラリの作成も容易にするという。
CUDAによるCコンパイラの提供によって、GPU上でのより汎用的なコンピューティングは飛躍的に容易になる。ちなみに、CUDAによる汎用コンピューティングの場合は、プログラム側からはG80のパイプラインは次のように見えるという。
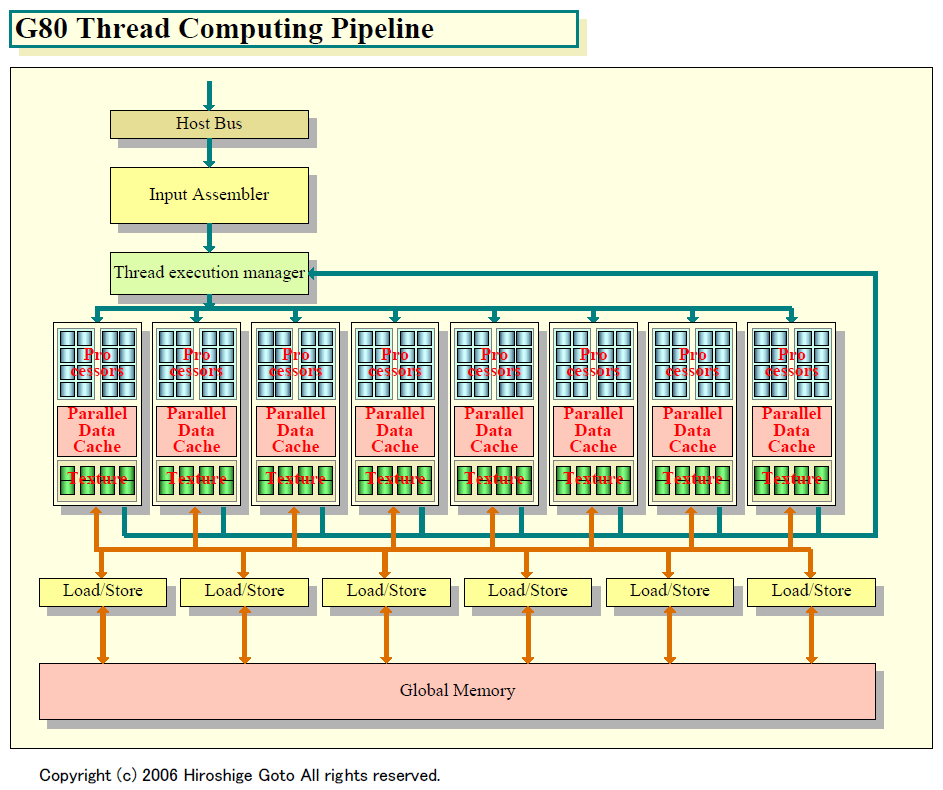 |
| G80 Thread Computing Pipeline(※別ウィンドウで開きます) PDF版はこちら |
G80はTSMCの90nmプロセスで製造され、トランジスタ数は6億8,100万(681M)。コンサバティブな90nmプロセスなのは、G80にはそれだけ検証期間が必要だったためだ。ダイサイズ(半導体本体の面積)は巨大で、下のウェハ写真で分かる通り、450平方mmを超え500平方mm近い。GPUでは過去最大だ。しかし、消費電力はトランジスタと比べるとかなり抑えられている。
 |
| GeForce 8800の特長(※別ウィンドウで開きます) PDF版はこちら |
 |
| GeForce 8800の消費電力(※別ウィンドウで開きます) PDF版はこちら |
概要を眺めただけで、G80はかつてないモンスターチップであることがわかる。しかし、G80の真に革新的な部分は、さらにディテールに入ってみないとわからない。G80では、汎用コンピューティングとグラフィックスのどちらでも、極めて効率的に最高パフォーマンスを得られる工夫がされている。次回は、Shaderアーキテクチャのディテールをレポートしたい。
□関連記事
【11月9日】NVIDIA、DirectX 10世代GPU「GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/nvidia1.htm
【11月9日】【多和田】Direct X10世代GPU「NVIDIA GeForce 8800」
http://pc.watch.impress.co.jp/docs/2006/1109/tawada89.htm
(2006年11月9日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.