 |

■森山和道の「ヒトと機械の境界面」■HRP-2 Prometの隠された能力 |
■出渕裕デザイン・ヒューマノイドの隠された能力 VVV(汎用3次元ビジョン)
まるで「三つ目がとおる」だ。「百聞は一見に如かずです」と、まず見せられた産業技術総合研究所・知能システム研究部門・3次元視覚システム研究部門の研究室は、3つで1組のステレオ・カメラで溢れていた。富田文明グループ長は「人間もなぜ三眼じゃないのかと不思議に思います」と半ば本気めいた顔で語る。
2002年12月9日、産総研らが開発を進めていたHRP-2、通称「Promet」(プロメテ)が公開された。全体のプロポーションこそ胴長短足気味だが、上半身部分はまさにアニメーションの世界から抜け出したような二足歩行ロボットである。
 |
 |
| HRP-2プロトタイプの顔の内部 | Prometの頭部。HRP-2プロトタイプと同等の3眼カメラが内蔵されているが、デザインの工夫によりスマートな外観となっている |
Prometの外見上の特徴が精悍な「顔」にあることは「ガンダム」「パトレイバー」世代ならば誰もが認めるところだろう。だが注目すべきポイントは外見だけではなく、内側にも隠されている。
ロボットが外界を認識して行動するためには外界センサー、つまり「目」や「耳」が必要だ。Prometの頭部には「目」となるカメラが納められている。バイザー部分に一つ、顔の両側の頬あて部分にそれぞれ一つずつ。合計3台だ。重さは700g。重量制限のためズームなどの機能はないが、Prometはこの3台のVGAモノクロカメラでステレオ立体視を行なって3次元情報を獲得、物体を認識している。実空間に存在する立体を「3次元の立体として」正確に知覚できる点が特徴だ。
なぜ三眼なのか。ステレオといえば二眼というイメージを持っている人が多いと思うが、実は二眼では、原理的に距離を計測できない場合があるのだ。たとえば人間のように横に2つの目を配置した場合は、水平な線が多い画像の距離計測が難しくなる。なぜか。ステレオ計測は左右の画像のズレから距離を計測する。だから左右に目をずらしても画像にズレが見られないものの距離は分からないのである。だから、上下にずれたところからもう一つ、エッジ方向と水平線の角度をずらした画像を撮って、対応エッジ点を探し、距離を推測するわけだ。人間でも分かりにくい場合は自分で動いて色んな方向から物体を見る。それと同じことである。
「要は人間の目を使う作業なら何にでも適用できるようなシステムです。画像処理には人工知能と同じく40年くらいの歴史がありますが、従来の画像処理は基本的には2次元の視覚、カメラ一台でいろんなことをさせようというもの。ですが3次元のものを対象にすると情報が不足するので、環境や対象に条件を設定しないと使えないわけです。我々は『無条件条件』、つまり対象が知らない背景の中にどんな位置・姿勢に置かれていても、どんな形状やテクスチャーを持っていても、たとえ運動していても、正確に認識できる視覚システムを研究開発しています。2次元システムではクリアできませんが、3次元ならばできます」 と、富田は胸を張る。
 |
 |
 |
| 8組×3台=合計24台のカメラからなるマルチステレオ・システム | ゴルフカートを改造した作業移動型自律走行システム。目標地点まで自動的に移動することができる | 自立走行車のズームレンズ付きアクティブ三眼ステレオカメラ |
 |
 |
 |
| 上記以外にも研究室には様々な三眼のステレオカメラがあふれている | ||
 |
|
| 昨年の公開時に協調搬送デモを実施したPromet | |
これまで協調搬送や起きあがり動作などのデモを見せてきたHRP-2だが、運動制御以外の知能に関する側面はあまり報道されていない。Promet公開当日にはパネルを認識して把持・運搬するというデモが披露されたが、目標パネルの発見はもちろん、そこまでの歩行経路計算、立ち位置の微調整などもPrometは自前で処理している。
それだけではなく実際には、工業製品のような多面体からなる物体から、ごく自然な自由曲面形状を持つものまで、およそ2mm以下の誤差で正確に認識する能力を持つ。たとえば、色々と雑多なものがある中からバナナなり特定の工具なりユーザーが指定するものを取り出して渡す、といったこともできるという。
なにせ誤差2mmで3次元形状を把握できるのだ。Prometは人間協調ロボットだが、人間そのものを認識することも事前に人間の「形状モデル」を与えていれば可能らしい。ホンダASIMOが認識能力を上げたと発表して話題になったが、あれと同じ程度のことはできるのだという。しかもASIMOと違って、3次元で顔の向き検出などを行なうことができる。実際に3次元視覚システム研究部門には人間など大型の物体の形状モデルを取り込めるマルチカメラシステムもある。同じく三つ一組からなるカメラで目標を取り囲んで画像を撮影することで形状データを計測、モデル化する。作ったデータの基本構造はCADで標準的な境界表現または曲面形状表現なので、VRやCADのデータとして吐き出すことも可能である。
 |
 |
 |
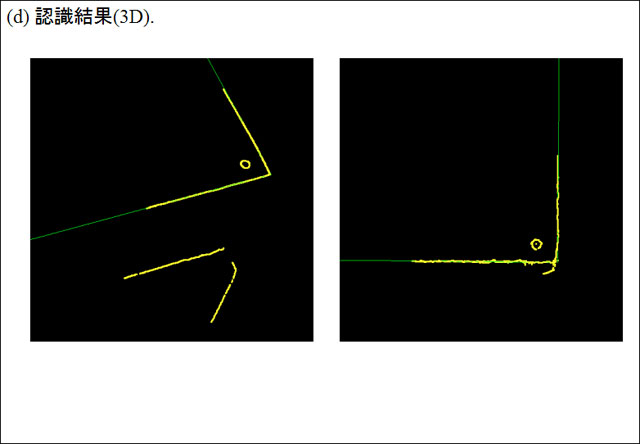 |
| HRP-2 Prometが実際に見ている映像。3つの映像から写っている物のエッジを検出し、内部に持っている「形状モデル」と照合、物体をパネルとして認識している | |
Prometが搭載している3次元視覚システムは「VVV(Versatile Volumetric Vision=汎用3次元ビジョン)」と呼ばれている。距離計測、形状計測、物体認識、運動追跡を行なうための汎用システムである。カメラやプラットフォームには依存せず、他のロボットやハンドアイシステム、視覚障害者用の支援システムなどにも応用できる。対象も航空写真からの地形や建物把握から顕微鏡下に至るまで幅広い。視覚グループからすればヒューマノイドは応用の一つでしかない。
物体の操作も、VVVを使えば簡単にロボットに教えることが可能だ。ロボットの目の前で、実際にモノを動かして見せるだけでいい。動きを見せてやるだけで、ロボット制御のパラメーターを全部与えることができる。これはタスクごとのプログラミングを必要としないハンドアイシステム「TORCS(Task-Orieted Robot Controll System)」と呼んでおり、これまでにブロックの積み上げ、空き缶を捨てるシステム、部品を穴に挿入するシステムなどを開発している。取り込みのサンプリングレートは通常のカメラなら1/30秒だが、高速度カメラを使えばもっと細かくすることも可能だ。
「どんな要求に対してもユーザーが『これこれしてね』と言えば、全部やってくれるようなシステムを目指しています」と河井良浩 主任研究員は言う。
 |
 |
| プログラミングレス・ハンドアイシステム「TORCS(Task-Orieted Robot Controll System)」 | プログラミングレス・ハンドアイシステムのシステム画面 |
■ロボットはマンガを理解できるようになるか? 幾何モデルと共通モデル
それだけではない。将来的には、「そこのコップを取ってくれ」といった曖昧な命令に対しても「『コップ』とはどんなものか、自分が見ているシーンの中に存在するか」までを自分で判断し、答えることが可能になるという。
人間は風景を見た瞬間、たとえば机の上に何があるか、一個一個のオブジェクトを分離して、それが何であるかまで含めて、認識している。環境の情報を全部理解している状態がデフォルトだ。だからこそ「ちょっとそこのボールペンを」と言われたときに、何の苦もなく取り上げて相手に渡すことができるのである。
 |
 |
| 富田文明 グループ長 | 河井良浩 主任研究員 |
そういうことができる、いわば本当の意味で賢くみえるロボットは現時点では存在しない。だがVVVはそれを目指しているという。しかも「数年のうちにはそれができるようになるんじゃないかと思います」と富田は言う。
物体の表現にはいくつかのレベルがあると富田は言う。まず一番基本的な表現が「幾何モデル」。正確に物体を計測した定量的な表現だ。その上が「物理モデル」。幾何モデルに対して、どこの部分が動くかとか重心はどこかといった物理的な情報を付加したものだ。さらにその上に「共通モデル」という表現形式があるという。
 |
| 3次元視覚プロセスの概念図 出展:「情報処理」 VOL.42 NO.4。高機能3次元視覚システムVVV |
「たとえば車を認識しようとしたとき、幾何モデルベースに基づくと世界中の車のモデルを持たなくちゃいけない。ですが共通モデルですと、見たことがない車でも『車』として認識することができるようになります。幾何モデルが定量モデルだとすると『定性モデル』と呼んでもいいと思います。工業的には幾何モデルでもいいわけですが、ヒューマンインターフェースとか自律ロボットとなると共通モデルが必要です。ロボットとの協調、対話のための共通モデル構築をいまやろうとしているところです」。
さらに共通モデルに名前を付けると自然言語になる、というのが富田らの考え方である。人工知能とビジョンの両者がくっつくためには共通モデルの完成が必要だという。現在の自然言語の研究では実体のない記号として言語を扱っている。だが共通モデルと言語を一体とすることができれば、言語に実体を与えることができる、というわけだ。共通モデルが実現できれば、コンピュータとの会話も自然なものになるという。
人間は線で書かれた簡単なマンガを見るだけで、そこに描かれているものがテレビであるとかカメラであるといったことを、一瞬で理解する。だが、現在のコンピュータには非常に難しい。定量的な角度や長さといったものに寄らない共通モデルが実現できれば、コンピュータがマンガを読むことができるようになる。いわば本当の意味で賢い目になるわけだ。人物の顔や動作の認識などももちろん共通モデルの領域である。では、どうやれば実現できるのか?
「それが研究課題です。共通モデルは、まず幾何モデルがないと実現できないというのが我々の考え方です。たとえば、直方体と円柱がこういうふうに組み合わさっていればカメラに見えるよといったことです。プリミティブな、定性的な関係と定性的な形ですね。その関係が重要だと考えています。関係は無限にあるわけじゃなくて、限られた組み合わせでどんな複雑なものでも表現できるんじゃないかというのが我々のアプローチです」。(富田)
物体に関する知識は無限だが、機能は有限だと富田は言う。基本的なデータを与えておいて、そこにユーザーが制約を与えることで成長していくようなシステムを考えているそうだ。学習というよりはチューニングしていくような感覚だ。
たとえば、コップやグラスと一言でいっても実に多種多様な形態のものがある。それらを一つのまとまりを持っているものとして、モデルの表現構造を決めてやる。つまりデータの構造化、いわばデータの入れ物のかたち、どういう入れ物にすべきかということが問題だという。そこにユーザーが制限をかけていくことで、たとえばコップは円柱形だが大きさは10センチ程度のものだ、といったことをチューニングしていくわけだ。
河井は「これまでの人工知能は、下が固まってないまま上からいきなりやろうとしたからダメだった。まあ色んなアプローチがあります。言語系から入っていく人もいるし、我々はビジョンから入ってそこへ近づいていこうとしてるわけです」という。
現時点ではまだ、実際に共通モデルが実現できているわけではない。人工知能が停滞しているなか、なかなか素直に首肯できずにいる筆者に対して富田は、 「幾何モデルベースだけにしても、我々のようなシステムが他にあるかというと、ないんですね。だから2~3年後にまた来てください。数年後にはお見せできると思います。ホラ吹きだと言われることもあって、あまり言わないようにしてるんですけどね。オオカミ少年とかね」と笑った。
これからのロボットは「自分で動き回ることのできるコンピュータ」として人間の相手をすることが期待されている。特にヒューマノイドの役割は実用だろうがエンターテイメントだろうが、そこ以外にない。ヒト型ロボットは「ヒューマノイド」という形式のコンピュータ・インターフェースだと言ってもいいだろう。
ヒューマノイドの目を作っているグループがやろうとしていることは、単に目だけではなく、頭の中身そのものを作り出すことだったわけだ。実際の生物においても「目は脳の出張所だ」と言われている。現時点ではPrometの頭部にはカメラしか収まっていない。だがその中身が充実してくる日は、そう遠くないのかもしれない。
□産業技術総合研究所・知能システム研究部門・3次元視覚システム研究部門
http://unit.aist.go.jp/is/vvv/index_j.html
□関連記事
【2002年12月10日】川田工業、出渕裕氏デザインの2足歩行ロボット「Promet」公開
http://pc.watch.impress.co.jp/docs/2002/1210/promet.htm
【2002年12月11日】ホンダ、新型ASIMOの機能を報道陣に公開
~ポスチャ・ジェスチャ認識技術などをデモ
http://pc.watch.impress.co.jp/docs/2002/1211/honda.htm
【2002年9月10日】働くロボット「HRP-2P」デモンストレーション公開
~ひとりで起き上がれるようになりました
http://pc.watch.impress.co.jp/docs/2002/0920/hrp.htm
【2002年4月11日】産総研、働く人間型ロボット開発の中間成果を発表
http://pc.watch.impress.co.jp/docs/2002/0411/hrp1.htm
【2002年3月19日】人と共同作業を目指すロボット「HRP-2プロトタイプ」発表
http://pc.watch.impress.co.jp/docs/2002/0319/hrp2.htm
(2003年1月23日)
[Reported by 森山和道]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.