 |


■後藤弘茂のWeekly海外ニュース■2008年中に95%をデュアルコアにする
|
●1世代2年毎に下にスライドするマルチコアCPU
Intel CPUの2008年ロードマップでは、デュアルコア化がさらに進展する。Celeronブランドでデュアルコアを投入することで、全デスクトップCPUのうち95%近くがデュアルコアまたはクアッドコアCPUへと移行する。
Intel CPUのデュアルコア化が急進展している理由は明瞭だ。それはデュアルコアのダイサイズ(半導体本体の面積)が、45nmプロセスではバリューCPUのレンジに入るからだ。そして32nmプロセスではクアッドコアがメインストリームCPUのダイサイズになり、22nmでは計算上はオクタ(8)コアがメインストリームクラスになる。もっとも、実際の製品としてはGPU統合版のデュアルコアCPUがメインストリームからバリューを占めるようになるだろう。GPU統合デュアルコアも32~22nmではバリュー市場に浸透できるダイサイズとなる。
 |
| Intel デスクトップCPUの移行予想 ※別ウィンドウで開きます PDF版はこちら |
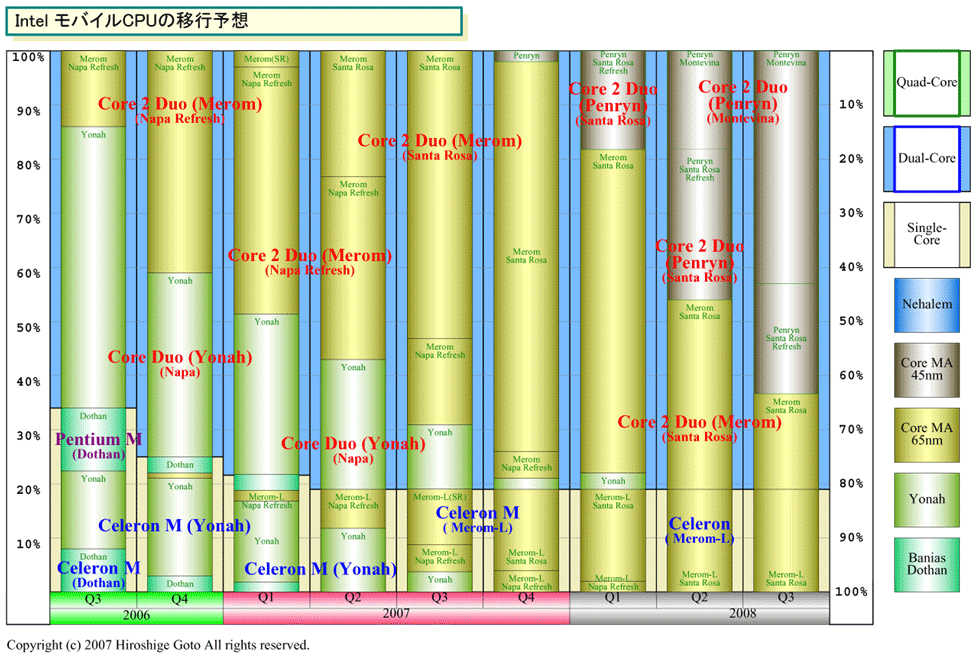 |
| Intel モバイルCPUの移行予想 ※別ウィンドウで開きます PDF版はこちら |
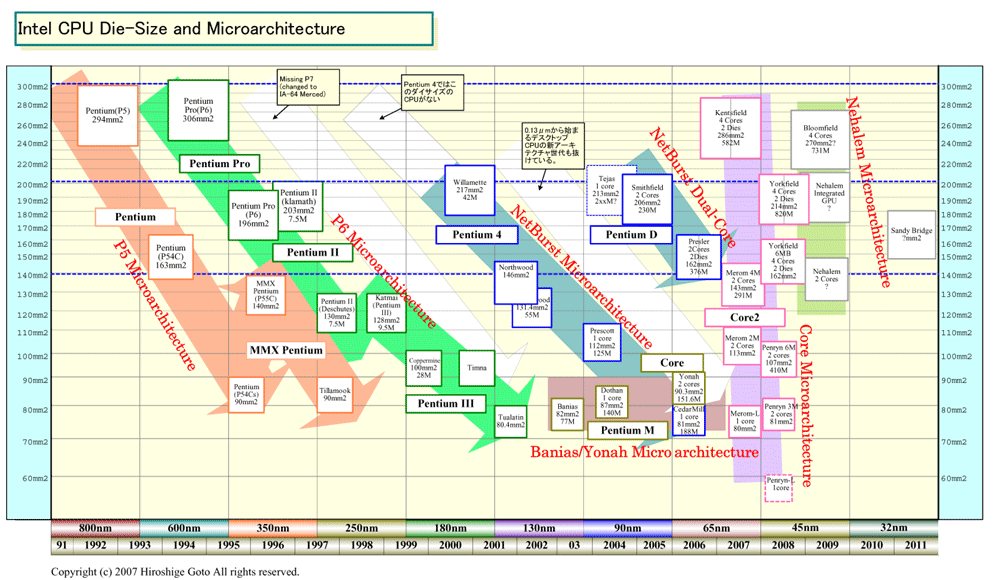
CPUのダイサイズは製造コストと密接に絡み、ダイサイズはターゲットとする市場の目安となる。Intelの伝統的なパターンは、新マイクロアーキテクチャCPUが300平方mm程度のダイでハイエンドとして登場し、200平方mm前後でパフォーマンスセグメントに浸透してメインストリーム市場に入り始め、140平方mm前後でメインストリーム市場を押さえてバリュー市場に浸透し始め、100平方mm前後でバリューセグメントに行き渡るというものだ。1世代で約70%ずつダイを縮小する。
これをIntelのデュアルコアCPUに当てはめると、ほぼセオリー通りとなっている。90nmプロセスでは、デュアルコアCPUはパフォーマンスCPUのダイサイズだった。65nmプロセスでは、フルスペックのデュアルコアCPUがメインストリームCPUに最適なダイサイズになった。45nmプロセスでは、カットアウト(小容量キャッシュ)版デュアルコアCPUがバリューCPUのダイサイズになる。数字で示すと、200平方mm台(2MB L2、90nm)→140平方mm台(4MB L2、65nm)→80平方mm台(3MB L2、45nm)と、IntelデュアルコアCPUのダイは小さくなり、1セグメントずつ下に降りてきている。
45nmデュアルコアでのローエンドとなる3MB L2キャッシュのPenryn 3Mのダイ(81平方mm)は、65nmのシングルコアCPUである「CedarMill(シーダーミル)」「Merom(メロン)-L」とほぼ同サイズ。このサイズは、Intel CPUの伝統的なボトムのサイズで、バリューCPUの価格帯に落とし込む時には、このサイズを目安としている。
チップ製造コストも80平方mm程度のダイサイズになると30~40ドル程度に収まるという。そのため、Intelは60ドル以下のバリュー価格で売ってもペイするようになる。Intelはそれを見越して、デスクトップCPUをバリューセグメントまでデュアルコア化しようとしている。まず、枯れてイールド(歩留まり)が上がった65nmプロセスのデュアルコアCPUをバリューに浸透させ。45nmが成熟し製造キャパシティが増えたところで、より低コストな80平方mmの45nmデュアルコアへと移行させると見られる。
 |
| Intel CPU ダイサイズとアーキテクチャ ※別ウィンドウで開きます PDF版はこちら |
●45nmでコストが下がるCore MAのクアッドコアCPU
IntelはデュアルコアCPUをバリューセグメントまで浸透させるのとは対照的に、クアッドコアCPUの比率を一定水準に留める。IntelのデスクトップCPUの出荷計画全体で見ると、クアッドコアは2008年末でも全体の7~8%程度だ。この理由も明白だ。それは、クアッドコアCPUの製造コストが依然としてパフォーマンスCPUのレンジに留まるからだ。
もう少し詳しく説明すると、IntelがクアッドコアCPUを、現在のCore MAで作り続けるなら、クアッドコアの製造コストをメインストリーム市場レベルにまで下げることができる。しかし、IntelはクアッドコアをNehalemマイクロアーキテクチャに移行させるつもりであり、クアッドコアNehalemのコストは下げにくい。そのため、安易にクアッドコアCPUの比率を高めることができないと推測される。
Core MAの65nm版クアッドコアCPU「Kentsfield(ケンツフィールド)」は、実際にはCore 2 Duo(Conroe:コンロー) 2ダイをワンパッケージに封止したMCM(Multi-Chip Module)だ。以前のMCMは、パッケージに封止してからでなければ厳密なテストができなかった。テストの結果、封止したダイのどちらかが不良となるとチップ自体を破棄しなければならなかった。そのため、MCMの歩留まりはシングルチップの場合と同様に悪かった。しかし、Intelは、Pentium Dデュアルダイ導入の際に、検査技術が進んだ現在では良品ダイ(KGD: Known Good Die)を2個選別して組み合わせることができるため、MCMは逆に歩留まり面で有利になると説明した。
シングルダイのチップの場合、ダイサイズが2倍になると欠陥がダイ上にある確率が増える。そのため、歩留まりがぐっと下がり、1枚のウェハから採れるチップ数が減り、製造コストが上がる。それに対して、KGDを2個組み合わせる場合は、歩留まりの比率は、半分のサイズのダイの歩留まりと同じとなる。その分、コストでは有利となる。
 |
| チップのダイサイズと歩留まり ※別ウィンドウで開きます PDF版はこちら |
もちろん、MCMでは、KGD検査コストとMCM化のコストが加わる上に、MCMの歩留まりもコストに影響する。しかし、Intelの主張通りなら、それでも、Kentsfieldの製造コストはシングルダイで同面積のチップより低いと考えられる。
Kentsfieldは、143平方mmのConroeのダイが2個なので、合計のダイサイズは286平方mm。これは、ちょうどNehalemのクアッドコア「Bloomfield(ブルームフィールド)」と同程度のサイズだ。しかし、コストで見ると、KentsfieldはBloomfieldより低いと推測される。IntelがKGDを低コストに検査できるなら、200平方mmクラスのダイのCPUと同程度のコストの可能性もある。
同様に、45nmプロセスのクアッドコア「Yorkfield(ヨークフィールド)」は、45nmの6MB L2版Core 2 Duo(Penryn:ペンリン)のダイ(107平方mm)2個で構成されている。2個のダイの合計は214平方mmで、製造コストは200平方mmのシングルダイCPUより低いと考えられる。Intelはさらに、3MB L2版のPenryn 3Mをデュアル構成にした廉価版のクアッドコア(Q9300)も投入する。Penryn 3Mのダイは81平方mmであるため、製造コストはさらに減少する。個々のダイ自体は製造コスト30ドル台のCPUのサイズなので、Intelはやろうと思えばクアッドコアCPUを100ドル台のメインストリーム価格帯に押し込むことができるだろう。
●ダイサイズが一回り大きくなるNehalem
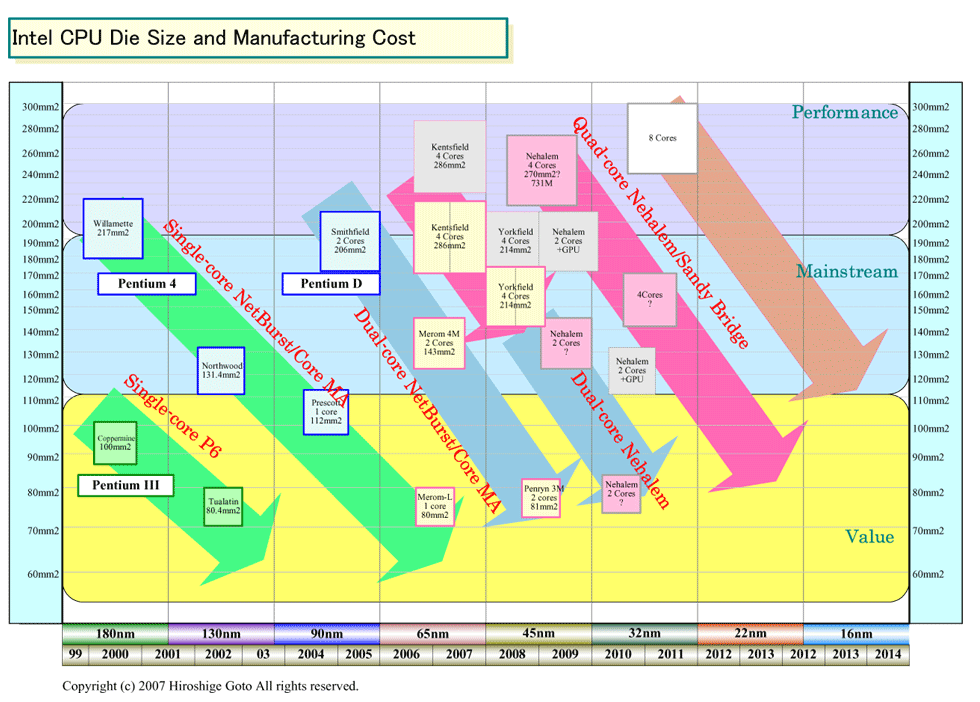
こうして見ると、IntelのMCM版CPUは、一段下のシングルダイCPUと同レベルのコストになると考えられる。こうした製造上のポイントを考慮してMCM版CPUの位置をずらしたのが下の図だ。KentsfieldやYorkfieldは、実際のダイサイズより下の、製造コスト的に見合うと思われる位置にずらしてある。
 |
| Intel CPU ダイサイズと製造コスト ※別ウィンドウで開きます PDF版はこちら |
緑の矢印がシングルコアCPU、青がデュアルコアCPU、ピンクがクアッドコアCPUを示している。こうして見ると流れは明瞭だ。Core MAとNetBurstのデュアルコアCPUは、90nmでパフォーマンスCPU、65nmでメインストリームCPU、45nmプロセスでバリューCPUに向いた製造コストになる。NetBurstとCore MAの青の矢印は、右下がりに3世代でトップからボトムへと降りてきている。
一方、ピンクのクアッドコアの矢印は、65nmでパフォーマンスCPU、45nmでメインストリームCPUのコストに降りてくるが、Nehalemでリセットされる。Nehalemのクアッドコアは、45nmプロセスでパフォーマンスCPUレンジだからだ。上の図にあるように、Nehalemでクアッドコアは再びパフォーマンスレンジに戻ってしまう。
そのため、Intelには選択肢が2つある。1つは、NehalemのクアッドコアをパフォーマンスPCに、Core MAのクアッドコアをメインストリームPCに持って来ることだ。しかし、Intelはおそらくそうはしないだろう。Nehalemのデュアルコアへの移行が阻害されるからだ。
命令セットアーキテクチャとフィーチャはできるだけ統一するのがIntelの流儀なので、2009年から先はメインストリームもNehalemへとシフトを進めるはずだ。Nehalemへのシフトを進めるためには、IntelはCore MAに対してのNehalemの優位性を明確にする必要がある。その場合、旧世代のCore MAのクアッドコアがメインストリームの部分に存在すると都合が悪いはずだ。アーキテクチャのシフトを促進するためには、Core MAをNehalemの下、デュアルコアでバリューPCクラスを占めるCPUと位置付けるだろう。そのため、IntelはクアッドコアはCore MA系からNehalem系へ完全に移行させると推測される。
Nehalemのクアッドコアは、45nmでパフォーマンスCPU、32nmでメインストリームCPUへと移行する。Nehalem系の後に登場する32nmプロセスCPU「Sandy Beach(サンディビーチ)」はCPUコアが小さいと言われているため、おそらく、同じペースでマルチコア化が進むだろう。そうすると、22nmではバリューCPUも原理的には可能となる。しかし、IntelはバリューにはクアッドコアCPUではなく、GPU統合のデュアルコアCPUを持ってくるだろう。
GPU統合版では、GPUコアの分、CPU側のダイサイズが増えてCPUの製造コストは増える。しかし、GPU統合では、チップセット数が1個に減るため、全体のコストは減るか、一定に保たれると推定される。ちなみに、Intelが低コストにKGDをピックアップできるのなら、GPU統合もMCMでスタートする可能性は高い。すでに説明した理由で、ダイが大きくなる場合、その方が、トータルのコストを減らすことができるからだ。
一方、NehalemのデュアルコアCPUは、45nmでメインストリームのレンジとなり、32nmの「Westmere(ウェストミア)」世代でダイサイズがバリューレンジになる。32nmプロセスで、ボトムエンドまでNehalem系がCore MAを置き換えることになるだろう。
●CPUコア自体がCore MAより大きなNehalem
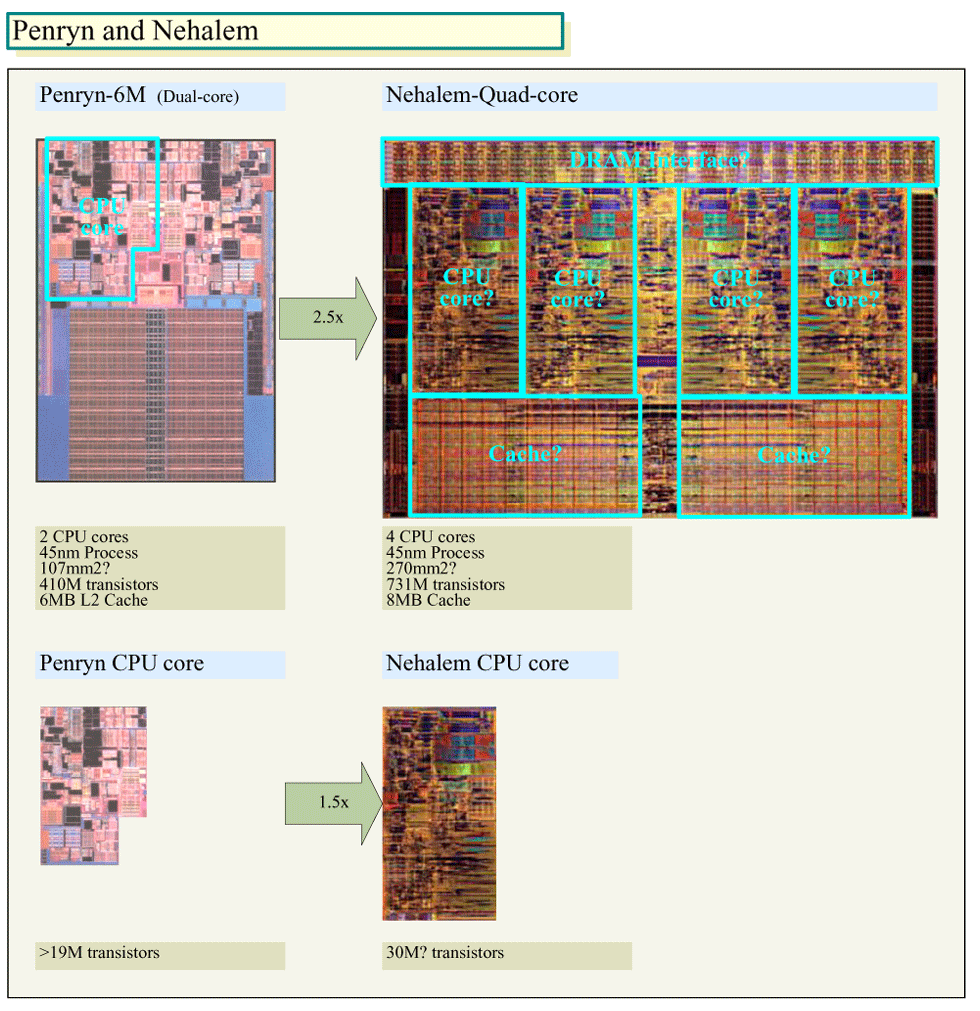
Nehalemになると、Core MAよりダイが1世代分大きくなると推定されるのは、複合した理由による。理由の1つは、ノースブリッジ機能の統合による。Nehalemのダイを見ると、ダイの上辺に位置するDRAMコントローラ部分が全体の面積の10%程度を占めていることがわかる。また、ダイの中央に位置するCPUコア間の調停を行なうコントロールロジックもかなりの面積を占めている。加えて、ダイの両端のQuickPath Interconnect(QPI)リンクがある。つまり、ノースブリッジの分だけダイが増えている。この分のコスト増は、システム全体で見ると、チップセット側のコスト減である程度相殺されると見られる。
しかし、それだけではない。NehalemアーキテクチャではCPUコア自体が、Core MA世代と比べると約1.5倍と大きい。CPUコアが大型化したために、Nehalemでは同じCPUコア数のCore MAより必然的にCPU自体が大型化する。
 |
| PenrynとNehalemの比較 ※別ウィンドウで開きます PDF版はこちら |
もっとも、新CPUが肥大化すること自体は、2000年までは当たり前のパターンだった。新しいマイクロアーキテクチャのCPUコアは、旧マイクロアーキテクチャCPUコアの2倍のサイズというのが通例だった。例えば、180nmと130nmプロセスのNetBurstとP6(Pentium III)を比べると、同じシングルコアでもNetBurstの方が約2倍のサイズだ。
例外はCore MAだ。シングルコアで比較した場合に、Core MA CPUのダイサイズはNetBurstとほぼ変わらない。つまり、P6→NetBurstではCPUのダイ面積は2倍に増えたのに、NetBurst→Core MAではほぼ同じだった。そのため、Core MA世代でマルチコア化が急進展した。それに対して、Core MA→Nehalemでは、CPUコアは1.5倍に増える。以前ほどではないが、Core MAのようにCPUコアの拡大を押さえ込んだアプローチとは明瞭に異なる。
アプローチの違いは、CPUのスタートポイントの違いにも現れている。伝統的に、Intel CPUは本格的に量産に入るのは200平方mmのダイからで、NetBurstも初代のWillamette(ウイラメット)は217平方mmだった。それに対して、Core MAは最初のMerom(メロン)が143平方mmと、いきなりメインストリームのダイからスタートしている。これは、Core MAを開発したのが、モバイルCPUを手がけてきたIntelイスラエルチームだという事情が関係していると推測される。もともと、モバイルCPUとして設計されたため、メインストリームのサイズからスタートした可能性が高い。
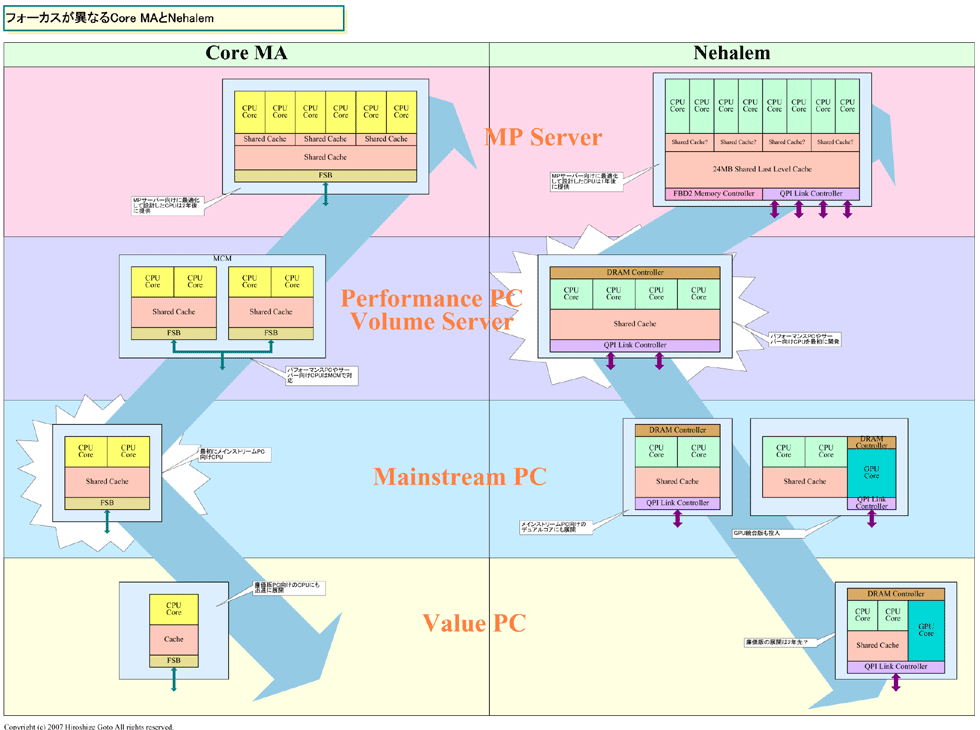
●フォーカスが異なるCore MAとNehalem
このことは、Core MAとNehalemでは、フォーカスするターゲットが大きく異なることも示している。
Core MAは、最初にメインストリームPC向けのデュアルコアCPUが投入され、パフォーマンスPCやボリュームサーバー向けのクアッドコアはMCMで作り、バリュー向けのシングルコアもやや遅れて派生させた。そして、2年遅れでMPサーバー向けに最適化設計されたヘクサコア(6コア)の「Dunnington(ダニングトン)」を投入する。
それに対して、NehalemはパフォーマンスPC&ボリュームサーバー向けに最適化したクアッドコアを最初に投入。遅れてメインストリームPC向けのデュアルコアを派生させ、1年遅れでMPサーバーに最適化したオクタコア「Beckton(ベックトン)」を投入する。バリューセグメントにNehalemアーキテクチャを投入するのは、おそらく32nm世代になる。
Nehalemは、アーキテクチャ的にもCPU同士をQPIで直接接続し、DRAMコントローラを統合することで、より大規模なサーバー構成を取りやすくしている。また、SMT(Simultaneous Multithreading)を実装することで、よりスレッド並列性を高めている。メモリインターフェイスも3チャネルDDR3と、無理をしても拡張している。
こうした特徴を持つNehalemのフォーカスは、明らかにパフォーマンスPCやサーバー&ワークステーションにある。Core MAとはアプローチが異なる、むしろ伝統的なIntel デスクトップ&サーバーCPUのアプローチに近い。
 |
| フォーカスが異なるCore MAとNehalem ※別ウィンドウで開きます PDF版はこちら |
こうしたダイサイズのカーブから、Intelの製品戦略はある程度推測できる。おそらく、IntelはCore MAでもクアッドコアの出荷を一定量に抑え、Nehalemのクアッドコアにバトンタッチ。メインストリームにはNehalemのデュアルコアを投入し、バリューにCore MAのデュアルコアという配置にすると推定される。
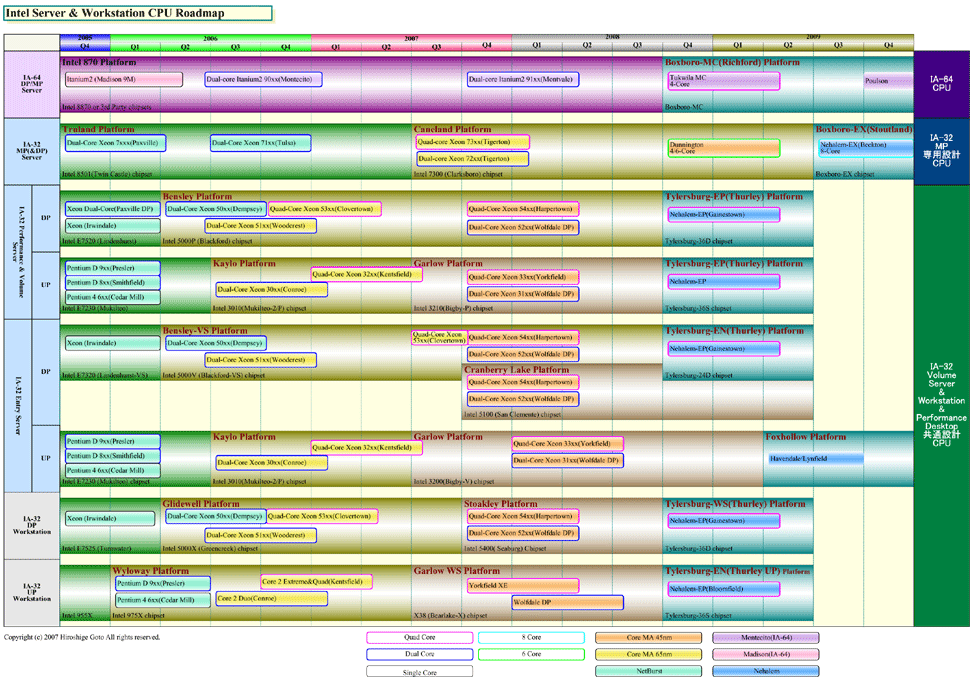 |
| Intel Server & Workstation CPU Roadmap ※別ウィンドウで開きます PDF版はこちら |
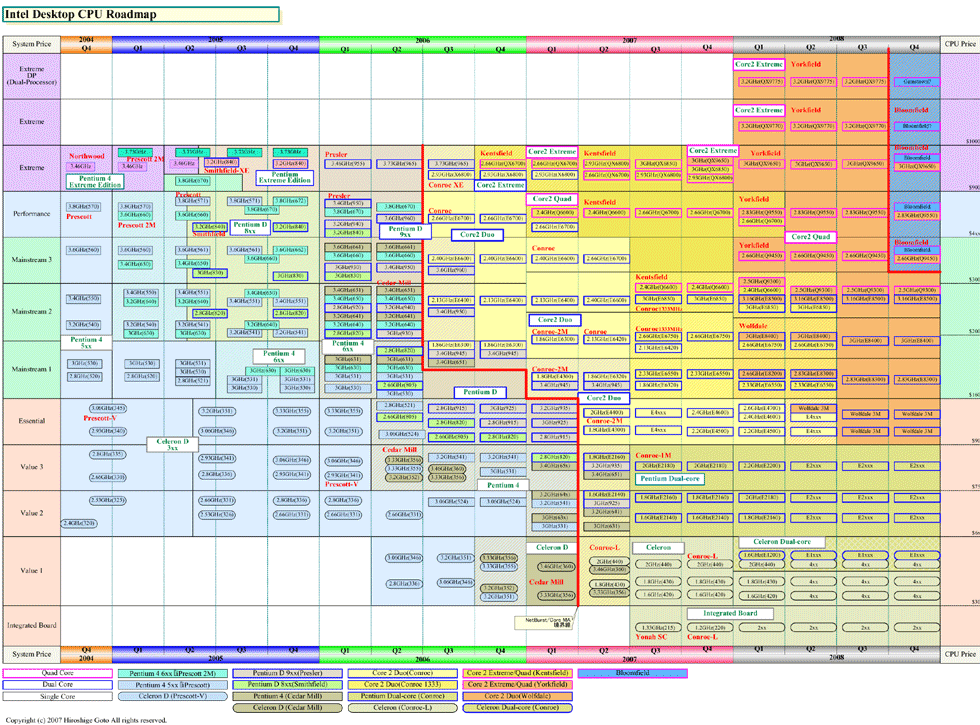 |
| Intel Desktop CPU Roadmap ※別ウィンドウで開きます PDF版はこちら |
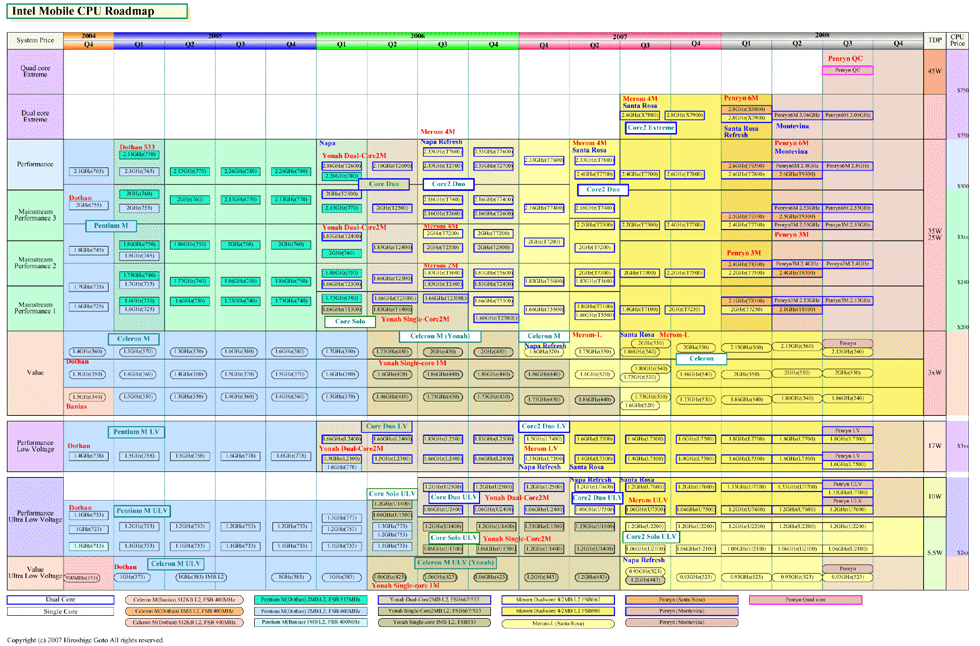 |
| Intel Mobile CPU Roadmap ※別ウィンドウで開きます PDF版はこちら |
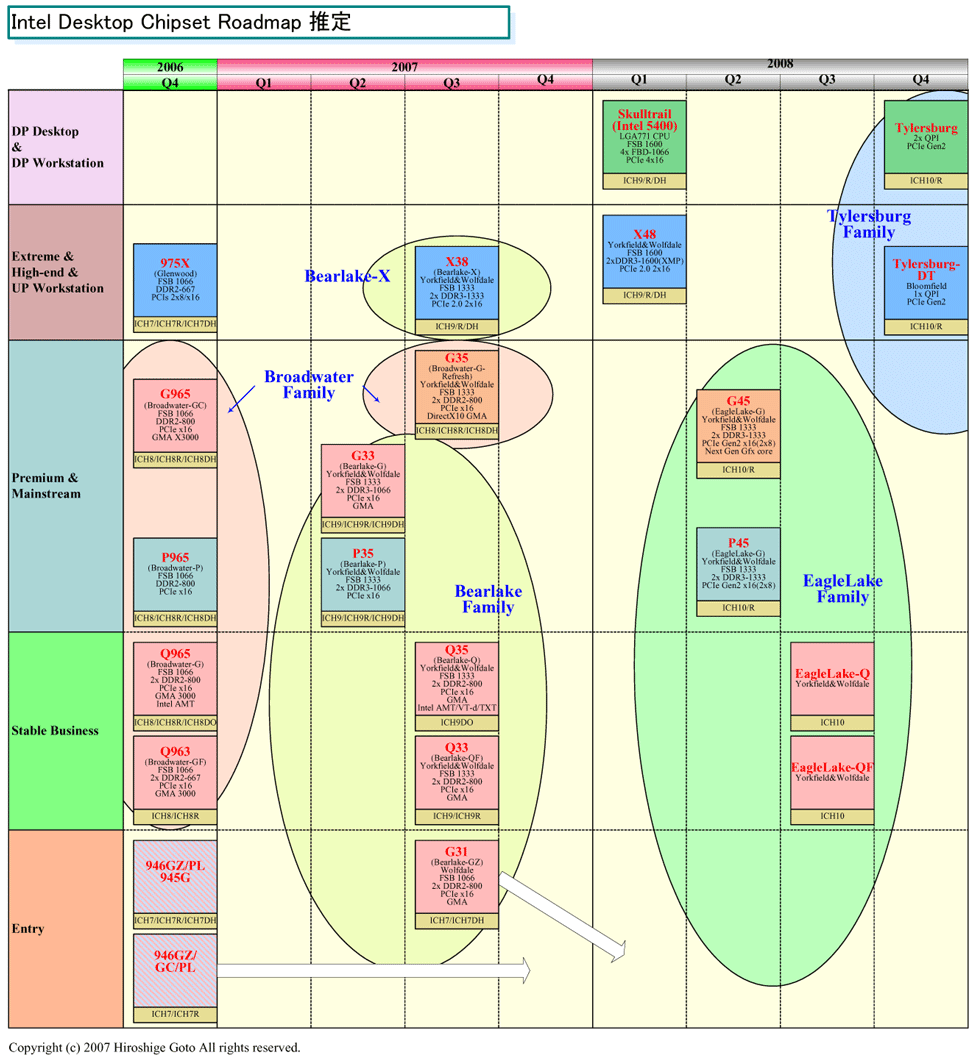 |
| Intel Desktop Chipset Roadmap ※別ウィンドウで開きます PDF版はこちら |
□関連記事
【10月26日】【海外】Intel版「8x4」で広がる2008年のCPUロードマップ
http://pc.watch.impress.co.jp/docs/2007/1026/kaigai397.htm
【10月22日】【海外】8コア×8ソケットで64コア128スレッドの「Beckton」
http://pc.watch.impress.co.jp/docs/2007/1022/kaigai395.htm
【10月2日】【海外】デュアルコアからオクタコアまでスケーラブルなNehalem
http://pc.watch.impress.co.jp/docs/2007/1002/kaigai390.htm
(2007年11月9日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.