 |


■後藤弘茂のWeekly海外ニュース■NVIDIAの「GeForce 8800 GT(G92)」と
|
●手頃価格でハイパフォーマンスのGeForce 8800 GT(G92)
NVIDIAは、新GPU「GeForce 8800 GT(G92)」を発表した。GeForce 8800 GTを一言で形容すると、GeForce 8(G8x)アーキテクチャのハイエンドクラスのパフォーマンスをミッドレンジの価格帯(NVIDIAの発表したカード価格は199~259ドル)に持ってきた製品だ。PCI Express Gen2を実装するとともに、従来のハイエンドG8xに欠けていた「VP2(Video Processor 2)」などを加えた。消費電力は105Wで、ボードはシングルスロットデザインになった。つまり、手頃価格で、G8x系の全フィーチャとパフォーマンスが手に入る、“お買い得”設定のGPUだ。
特に目立つのは、G92のシェーダプロセッシングパフォーマンスの高さだ。シェーダプロセッサの個数は、ハイエンドのGeForce 8800 Ultra/GTXの128個に対して、G92は112個。これを1.5GHzのシェーダコアクロックで動作させるため、シェーダプロセッシングの理論性能は、GeForce 8800 GTX(1.35GHz)とほぼ変わらない。シェーダパフォーマンス的には、ハイエンドのGPUだ。
 |
 |
| 公開されたGeForce 8800 GTのスペック | GeForce 8800 GTはVP2を搭載 |
もちろん、その裏にはプロセス技術の進歩がある。従来のGeForce 8800(G80)系はTSMC 90nmプロセスで製造されていた(下位のG84/86は80nmプロセス)が、G92ではそれをTSMCの65nmプロセスに移行させた。G92の搭載トランジスタは754M(7億5,400万)と、G80の681M(6億8,100万)を上回る。G80より増えたのは、ビデオ系やPCI Express Gen2の実装のためだと思われる。現時点では、NVIDIAのGPUで、最大規模のトランジスタ数のGPUだ。
しかし、65nmプロセスに移行したことで、ダイサイズ(半導体本体の面積)が縮小し、低コスト化を図ることができた。また、メモリインターフェイスを、ハイエンドG80の384-bit幅から256-bit幅へと抑えることで、搭載するメモリ粒度をより小さくした。
 |
| GeForce 8800 GT(G92)OverView ※別ウィンドウで開きます PDF版はこちら |
GPUは、ボード価格帯として、ハイエンド(299ドル以上)、ミッドレンジ(199~299ドル)、メインストリーム(100~199ドル)、バリュー(99ドル以下)の4階層がある。GPUベンダーは、3~4種類のGPUダイ(半導体本体)で、この4階層をカバーする。伝統的には最廉価GPUは100平方mm程度のダイサイズ(半導体本体の面積)、ミッドレンジが120から160平方mm、ハイエンドは最近では400平方mm以上に達している。今回のG92は、トランジスタ数から推測すると、価格帯はミッドレンジだが、ダイとしてはおそらく現在のハイエンドGPUと従来のミッドレンジGPUの中間に来ると推測される。つまり、NVIDIAは、G92には、製造コストに対して、かなり戦略的な価格をつけている。
| 名称 | GeForce 8800 GT | GeForce 8800 Ultra | GeForce 8800 GTX | GeForce 8600 GTS | GeForce 8500 GT |
|---|---|---|---|---|---|
| コードネーム | G92 | G8x | G80 | G84 | G86 |
| API(HWで実装) | DirectX 10 Shader 4.0 | DirectX 10 Shader 4.0 | DirectX 10 Shader 4.0 | DirectX 10 Shader 4.0 | DirectX 10 Shader 4.0 |
| コアクロック | 600MHz | 612MHz | 575MHz | 675MHz | 450MHz |
| シェーダクロック | 1,500MHz | 1,500MHz | 1,350MHz | 1,450MHz | 900MHz |
| シェーダ/コア比 | 2.50倍 | 2.45倍 | 2.35倍 | 2.15倍 | 2.00倍 |
| メモリクロック | 900MHz | 1,080MHz | 900MHz | 1,000MHz | 400MHz |
| メモリ転送レート | 1,800MHz | 2,160MHz | 1,800MHz | 2,000MHz | 800MHz |
| メモリインターフェイス幅 | 256bit | 384bit | 384bit | 128bit | 128bit |
| メモリ帯域(GB/Sec) | 57.6GB/sec | 103.7GB/sec | 86.4GB/sec | 32.0GB/sec | 12.8GB/sec |
| 標準搭載メモリ量 | 512MB | 768MB | 768MB | 256MB | |
| Stream Processor数 | 112 | 128 | 128 | 32 | 16 |
| TPC数 | 7 | 8 | 8 | 2 | 1 |
| GFLOPS(SP) | 336.0 GFLOPS | 384.0 GFLOPS | 345.6 GFLOPS | 92.8 GFLOPS | 28.8 GFLOPS |
| ROPs | 16 | 24 | 24 | 8 | 8 |
| Video Processor | VP2 | VP1 | VP1 | VP2 | VP2 |
| PCI Express | Gen2 | Gen1 | Gen1 | Gen1 | Gen1 |
| ファウンダリ | TSMC | TSMC | TSMC | TSMC | TSMC |
| 製造プロセス技術 | 65nm | 90nm | 90nm | 80nm | 80nm |
| トランジスタ数 | 754M | 681M | 681M | 289M | 210M |
| ダイサイズ | 470平方mm | 470平方mm | 160平方mm | 122平方mm |
●マイクロアーキテクチャ的にはほぼG80と同じ
G8x系アーキテクチャでは、演算コアはスカラ型のシェーダプロセッサ「Streaming Processor (SP)」群で構成されている(SPのほかにサブの「Super Function Unit(SFU)」もある)。G8xアーキテクチャでは、8個のSPを「Streaming Multiprocessor」(SM)」として束ねており、8個のSPは各サイクルに同じ命令を実行する。言い換えれば、8個のSPが1個の命令ユニットの下でSIMD(Single Instruction, Multiple Data)型に構成されている。SMには、NVIDIAの汎用的なプログラミングモデル「CUDA(クーダ:compute unified device architecture)」で利用できる16KBの共有メモリも含まれる。
 |
 |
 |
 |
| G8x系アーキテクチャでは、演算コアはスカラ型のSP群で構成される。SPのほかにサブの「Super Function Unit(SFU)」も搭載される。また、8個のSPを「Streaming Multiprocessor」(SM)」として束ね、これにはCUDAで利用できる16KBの共有メモリも含まれる | |
伝統的なGPUでは、各シェーダプロセッサの中の演算ユニットもSIMD型またはVLIW(Very Long Instruction Word)型の構成となっている。典型的にはSIMD演算ユニットで、例えば、「RGBA」の各データに対する演算を同時に行なう。それに対して、G8xアーキテクチャでは、各シェーダプロセッサSPはスカラ型となっている。そのため、SIMD型演算命令の場合も、SP内部的にはディベクタライズ(devectorize)された命令を実行する。
当然、G8x系では実行レイテンシ自体は伸びるが、グラフィックスタスクはレイテンシトレラントなので、実害は少ない。また、プロセッサを小さくし、SP数を増やすことで、同時に実行するスレッド(1個の頂点/ジオメトリ/ピクセル等に対するタスクをNVIDIAではスレッドと呼ぶ。CPUのスレッドとは意味が異なる)数を増やして、全体のスループットを上げている。命令レベルの並列性は割り切って削り、スレッドの並列性を追求したのがG8xアーキテクチャだ。この点が、命令レベルの並列性を強めたAMD(旧ATI)のRadeon HD 2900(R600)系と好対照となっている。
 |
| GeForce 8800 GTのテクスチャユニットの構成 |
G8x系では、2個のSMとテクスチャユニットで、シェーダクラスタが構成されている。クラスタは「TPC(Texture Processor Cluster)」と呼ばれており、これがG8xシェーダアーキテクチャの最小構成単位だ。GeForce 8800 GTX(G80)ではTPCが8個、GeForce 8600(G84)では2個、GeForce 8500 GT(G86)では1個となっている。
GeForce 8800 GTでも、こうしたG8xアーキテクチャの基本は変わっていない。G9番台の型番がつけられているのが不思議なほど、NVIDIAが説明するマイクロアーキテクチャ上の変化は小さい。
「スケジューラとロードバランシングを改善した。全般に、命令発行レートが上がった」、「TPCの構成や、内部の共有メモリのサイズなどは変更していない。今のところ、同じアーキテクチャを保っている」とNVIDIAのTony Tamasi(トニー・タマシ)氏(Vice President, Technical Marketing)は説明する。
NVIDIAの説明を聞く限り、G92のコア自体は、G8xマイクロアーキテクチャの、非常にマイナーなバージョンアップだ。もっとも、これ自体は不思議ではない。NVIDIAは、CUDAプログラミングモデルを通じて、今までよりはるかに詳細なGPUアーキテクチャを公開しつつある。そのため、以前より内部のマイクロアーキテクチャを小刻みには変更しにくくなりつつある。CUDAのプログラミングモデルでの最適化に影響を与える可能性があるからだ。
●GeForce 8800 GTの奇妙なシェーダクラスタ構成
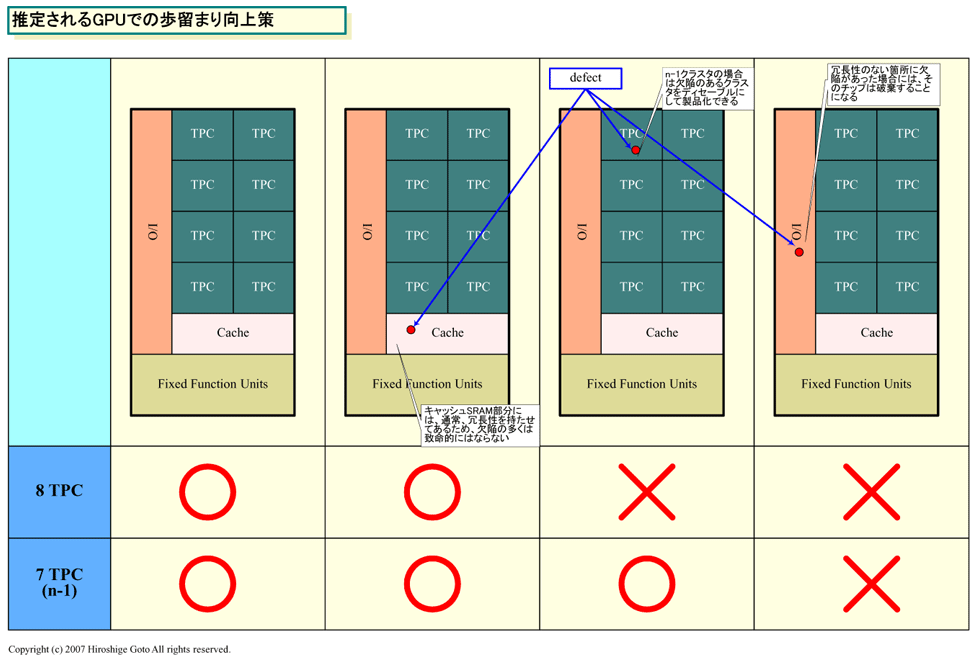
GeForce 8800 GTの構成には奇妙な点が1つある。それは、シェーダのクラスタである「TPC(Texture Processor Cluster)」が7個で構成されている点だ。G80では8 TPCだったのが、G92では1個減っている。奇数である7は、コンピュータでは異例な数字だ。通常は、2のべき乗、あるいは2の倍数でユニットを構成する。ところが、G92では1個少ない「n-1」個の構成となっている。
この構成でもっとも考えられることは、「冗長性」のために1 TPCをディセーブルにしている可能性だ。
LSIで、歩留まりを上げるために冗長性を持たせること自体は珍しいアプローチではない。ダイ(半導体本体)上には、製造プロセスの中でしばしば欠陥(Defect)が発生する。冗長性がなければ、欠陥のあるチップは破棄しなければならない。しかし、欠陥箇所に冗長性があれば、代替ブロックに切り替えることで製品化できる。
例えば、CPUのキャッシュSRAMの場合、代替用の冗長SRAMエリアを用意していることが多い。キャッシュSRAM上のどこかに欠陥があった場合、そのラインを代替ラインに切り替える。そのため、キャッシュ部分の欠陥は歩留まりにほとんど影響しない。
同様に、PLAYSTATION 3(PS3)のCPU「Cell Broadband Engine(Cell B.E.)」は、8個のSPE(Synergistic Processor Element)のうち1個を冗長用に使っている。7個のSPEしか使わないため、1個のSPE上に欠陥があるCell B.E.もPS3に使うことができる。
G92の奇妙な構成からは、PS3向けCell B.E.と同様に8個のTPCのうち1個を冗長性のために使っている可能性が推測できる。この場合、7個のTPCしか実装しないGPUよりダイサイズ(半導体本体の面積)は大きくなる。しかし、ダイに占めるTPCの割合が高く、ウェハの欠陥率がある程度以上の場合、7 TPCでダイを小さくするより、8 TPCのうち1つをディセーブルにしたほうが歩留まりがずっと高くなる。なぜなら、通常はダイの大半を占めるTPCの部分が、歩留まりに影響しなくなるからだ。そのため、G92はミッドレンジGPUとしては大きめのダイであっても、歩留まりがいいと考えられる。
実は、こうした冗長化はGPUベンダーが常に行なっている。通常、GPUベンダーは、欠陥がないダイを、フルフィーチャのハイエンド版として発売する。そして、欠陥があるダイは、シェーダプロセッサ数などを減らしたバージョンとして発売する。今回、アプローチが異なる理由はわからない。
 |
| 推定されるGPUでの歩留まり向上策 ※別ウィンドウで開きます PDF版はこちら |
●NVIDIAが予告していた次のモンスターGPUはどこに?
NVIDIAは昨年(2006年)、GeForce 8800 GTXの発表直後に、次のGPUについて予告していた。「翌年(2007年)の後継GPUはワンチップで1TFLOPSのパフォーマンスになる」とNVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は語っていた。その当時は、NVIDIAはG8x系の演算性能にSP以外の要素もカウントしていたため、G80の理論値を約518GFLOPS(1.35GHz時)としていた(現在の計算方法では345.6GFLOPS)。そのため、1TFLOPSのGPUということは、G80の2倍の演算パフォーマンスのGPUを出すと説明していたことになる。これは、GPUの伝統的なパフォーマンスカーブに沿ったものだ。
G80は128個のSPを搭載しているので、同じシェーダ動作クロックなら256個のSPを搭載しているはずだった。ラフに言って、G80の2倍の規模のGPUを計画していたことになる。
また、NVIDIAは、64-bit倍精度の浮動小数点演算を次のGPUに実装することも今年(2007年)6月に明かしていた。その当時、Kirk氏は次のように語っていた。「我々は、年末(2007年末)までに倍精度を実現することを明らかにした。これは、単精度の複合(によるソフトウェアソリューション)ではなく、実際に倍精度のハードウェアになるだろう」
しかし、見てわかる通り、1TFLOPS(現在の数え方では700GFLOPS)と64-bit浮動小数点演算のハードウェア実装のどちらも、今回の発表には含まれていない。もっと正確に言えば、今回発表されたのは、改良型マイクロアーキテクチャのハイエンドGPUではなく、ほぼ同じマイクロアーキテクチャのアッパーミッドレンジGPUだ。
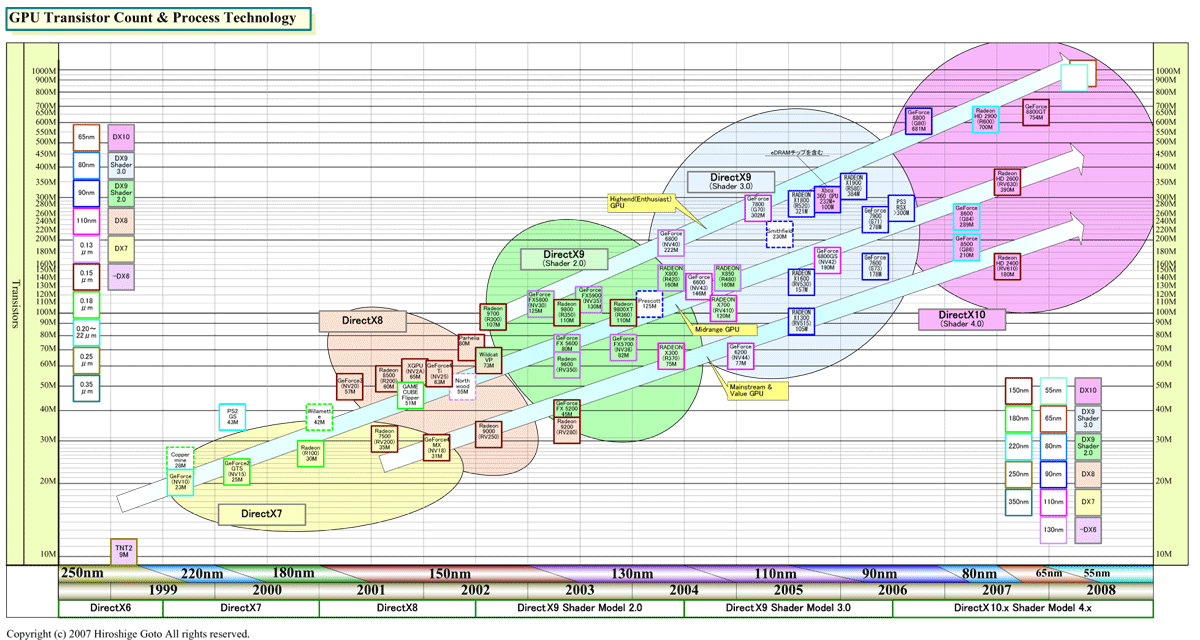
GPUのトランジスタ数を見ても、今回が異例なことがわかる。ハイエンドGPUのトランジスタ数は、ほぼ一定のペースで伸び続けている。従来のペースが維持されるなら、次のハイエンドGPUはおそらく900M(9億)から1,000M(10億)トランジスタをワンチップに積むはずだ。しかし、今回のG92はそれを下回っている。トランジスタ数の推移を見ると、今回のG92は、GeForce 7800 GTX(G70)に対するGeForce 7900 GTX(G71)のような位置付けだ。だとすれば、G71の後にG80が来たように、G92の次にはより大きなGPUが登場すると考えるのが自然だ。
では、64-bitのNVIDIAの次は、どうなっているのだろう。
 |
| GPU Transistor Count & Process Technology ※別ウィンドウで開きます PDF版はこちら |
●64-bitサポートの次世代GPUは近いうちに
NVIDIAのTony Tamasi氏は次のように説明する。「64-bitの計画はアナウンスのままだ。我々は、IEEE精度の倍精度(浮動小数点演算)をハードウェアでサポートする。今回ではないが、近いうち(soon)だ」と語る。G92の後ろに、64-bitのハイエンドGPUが控えているわけだ。ちなみに、ATI(現AMD)側の次のハイエンドGPU「R680」も倍精度浮動小数点演算をサポートすると言われている。
現段階では、NVIDIAの倍精度の実装方法はわかっていない。64-bit演算専用のハードを搭載することは、トランジスタ数を考えると現実的ではない。そのため、既存の32-bit演算ユニットを活かした形で64-bitサポートを実現すると見られる。
従来のGPUハードの場合は、32-bit単精度浮動小数点の4way(128-bit)のSIMDまたはVLIW(Very Long Instruction Word)のユニットを備えていた。そうしたハードで64-bit演算をサポートする場合は、32-bitの演算ユニットを2個バインドして64-bit演算を実行するように拡張できる。AMD(旧ATI)はこの方式を採ることができる。
NVIDIAアーキテクチャの場合はどうなのか。G8x以降のNVIDIAアーキテクチャの場合、各SPは32-bit単精度浮動小数点演算のスカラプロセッサで、各SPが個別のスレッドを実行している。ここでも、想定できるのは、2個のSPをバインドして64-bit演算ができるように拡張することだ。ただし、その場合は、Streaming Multiprocessorの制御を従来とは変える必要が出てくる。倍精度命令の時だけ、SPをバインドした制御を行なう必要がある。
●フラグシップを欠いたNVIDIAの発表
ハイエンド製品がずれ込んだ結果、今回のNVIDIAの発表はフラグシップを欠いたものとなっている。本来的には、年末商戦期に次のハイエンドGPUを間に合わせるのがビジネスの常套だが、今回はそうではない。もっとも、この事情はATIも同じだ。ATIの次のフラッグシップである「R680」は来年(2008年)早期となっている。
ただし、ハイエンドGPUが年末商戦からずれたことは、さほど致命的な問題ではないだろう。現状で、GPUパフォーマンスが不足していると考えるユーザーはそれほど多くはない。元々、ボリュームが出る売れ筋商品はハイエンドではなく、ミッドレンジ以下だ。そもそも、年に1回ハイエンドGPUを一新するというパターン自体が、すでに崩れている。
GPUベンダーが今回、ミッドレンジを先行させるのは、PCI Express Gen2への移行も絡んでいる。NVIDIAはAGP→PCI Expressへの移行時も、ネイティブPCI Expressの実装はミッドレンジGPUで先行した。インターフェイスが一新される場合は、ホスト側(この場合は主にIntelチップセット)との検証に時間がかかる。インターフェイス絡みで、設計変更が加わる可能性も高い。そのため、ハイエンドGPUで先行するのは難しいとの判断だったと思われる。
NVIDIAは、PCI Express Gen2への移行も同じパターンを踏襲したようだ。ちなみに、旧ATIはPCI Expressへはネイティブ対応で迅速に移行したが、その代わりにGPUコアのマイクロアーキテクチャの拡張は最小に止めた。GPUコアは枯れたアーキテクチャにして、リスクを最小に止めた。
このように、インターフェイスの変わり目は、一般に、GPUアーキテクチャが足踏みをする時期となる。
また、GPUアーキテクチャ自体の更新も、スパンが長くなっている。以前は、NVIDIAとATIともに、1年サイクルで命令セットもマイクロアーキテクチャもともに完全に一新したGPUを投入していた。
しかし、現在のNVIDIAは、GeForce 6(NV4x)のベースアーキテクチャをGeForce 7(G7x)でも継承し、2年半も継続した。その間に開発リソースを集中して、アーキテクチャ上の飛躍であるGeForce 8(G8x)を開発。今後は、G8x系アーキテクチャを、おそらく2~2年半は拡張しながら継続すると推測される。そうしたロングスパンのアーキテクチャのライフサイクルの中では、G8x系の次の拡張が来年(2008年)前半になるのもうなずける。GPUのサイクルは、CPUのそれにかなり似てきている。
□関連記事
【10月30日】NVIDIA、1スロットのハイエンドビデオカード「GeForce 8800 GT」
http://pc.watch.impress.co.jp/docs/2007/1030/nvidia.htm
【10月30日】NVIDIA GeForce 8800 GT速報レビュー
http://pc.watch.impress.co.jp/docs/2007/1030/nvidia2.htm
【4月16日】【海外】スケーラブルに展開するNVIDIAのG80アーキテクチャ
http://pc.watch.impress.co.jp/docs/2007/0416/kaigai350.htm
(2007年10月31日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.