 |


■後藤弘茂のWeekly海外ニュース■対Core MAの切り札となるAMDの「Hound」コア
|
●拡張の方向性がIntelと共通するAMDの新CPUコア
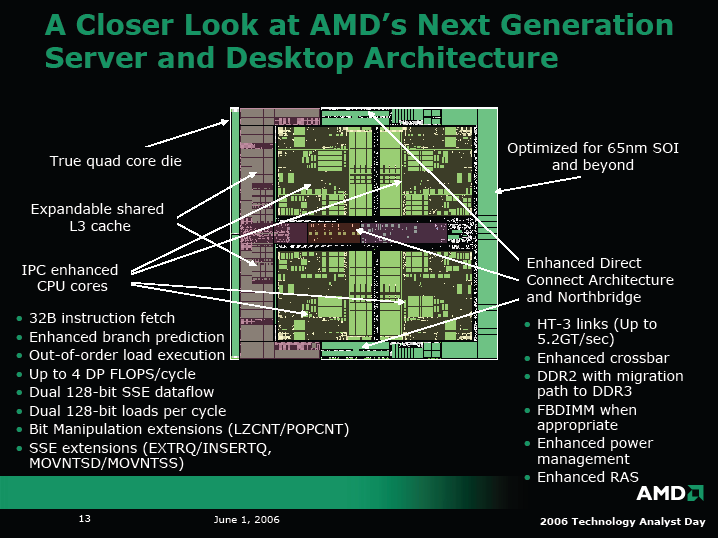
Intelの新CPUマイクロアーキテクチャ「Core Microarchitecture(Core MA)」を迎え撃つAMDは、2007年中盤にサーバー&デスクトップ向けの新コアを投入する。以前、「Rev. H(Revision H)」または「K8L」と呼ばれていた新コアでは、クアッドコア構成の「Hound(ハウンド)」ファミリがフラッグシップとなる。
新コアは、従来のK8系から、CPUコア自体のマイクロアーキテクチャを拡張している。拡張のポイントは、SIMD浮動小数点演算ユニットの倍増、投機ロード実行、分岐予測や命令フェッチ機能の拡張など。AMDのサーバー&デスクトップ新コアの基本的な拡張の方向性は、ほぼCore MAの拡張とオーバーラップする。
 |
| A Closer Look at AMD's Next Generation Server and Desktop Architecture(※別ウィンドウで開きます) |
また、Core MAのパイプラインの段数や内部命令セットの作り方などは、ある程度AMD K7/K8系と似てきており、x86系CPUアーキテクチャの収斂が進みつつあるように見える。また、AMDは新コアで、デュアルコアだけでなくクアッドコア製品を投入するが、この点もCore MAと似ている。そのため、AMDの新コアとCore MAは、非常に接近した戦いを繰り広げることになるだろう。
しかし、AMDの新コアとIntelのCore MAでは異なる点も多い。例えば、Intelは基本的にはCore MAをデュアルコア設計で導入、クアッドコアは2個のデュアルコアのダイ(半導体本体)を1パッケージに封止することで実現する。CPU設計のバリエーションを抑えるという、従来の路線を続ける。それに対して、AMDはデュアルコア設計のほかに、完全に1個のダイに統合したクアッドコアの2設計を導入する。
「サーバー&デスクトップ用のCPU設計では、2つのベーシックな設計ポイントがある。1つはクアッドコア設計で、サーバーとハイエンドのデスクトップ市場向け。もう1つはデュアルコア設計で、デスクトップ市場向け。どちらの設計も、2007年の中盤に導入する」とAMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer)は語る。クアッドコアはサーバー版が「Deerhound(ディアハウンド)」、デスクトップ版が「Greyhound(グレイハウンド)」で、AMDではクアッドコア系列を「Hound(ハウンド)」ファミリと呼んでいる。AMDはこのほかに、完全に別設計のモバイルコアを同時期に導入する。合計で3つの異なる設計のCPUをほぼ同時期にリリースすることになる。
Intelより設計リソースが少ないAMDが、3つの異なるダイ設計を平行させることができるようになる、そのカギはモジュラー設計だ。CPUコアの各ファンクションユニット間のインターフェイスをクリーンに定義。それによって、異なるユニットのコンフィギュレーションを容易にした。PC&サーバー向けのハイエンドCPUでモジュラー設計を取らない理由は、オーバーヘッドを減らして性能を最大化するためだ。しかし、AMDは設計のモジュラー化が性能に与える影響はないとしている。オーバーヘッドがあったとしても、モジュラー化によるコンフィギュレーションの容易性の方が、市場での利点が多いと判断したのかもしれない。
●浮動小数点SIMD演算性能の強化はx86 CPUの共通トレンド
AMDは、モバイルコアには現在のCPUコアとほぼ同じ機能のCPUコアを載せる。それに対して、サーバー&デスクトップでは拡張版CPUコアを載せる。以前のコラムで説明した通り、CPUコアの機能自体が大きく拡張される。そして、その拡張はCore MAとある程度方向性が揃っている。
AMDのサーバー&デスクトップCPUコアの強化点は大きく分けて以下の4つ。
(1)浮動小数点演算のパフォーマンスを2倍に
(2)アウトオブオーダ型ロード実行
(3)分岐予測と命令フェッチを拡張
(4)命令セットを拡張
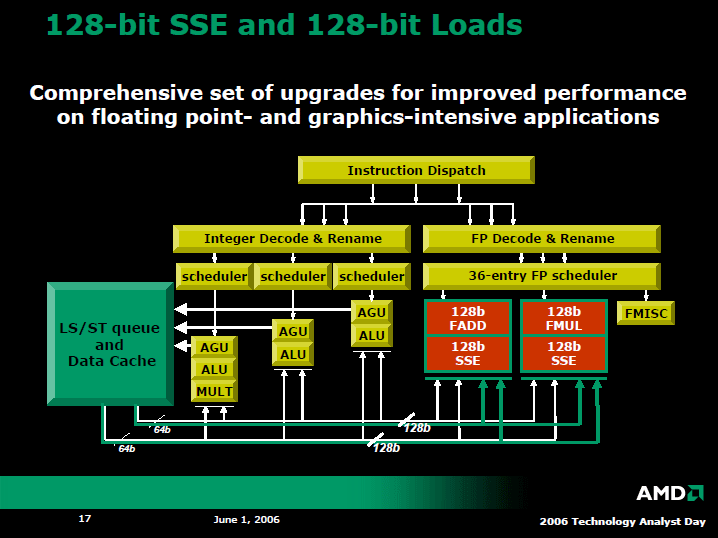
x86系CPUのパフォーマンスを向上させる要素はある程度限られている。そのため、トランジスタ数に余裕ができた場合、x86系CPUのどの部分を拡張するかは、各CPUメーカーである程度似通ってくる。AMDとIntel、それからVIA/Centaur Technologyの3社は、いずれも新世代アーキテクチャではSIMD浮動小数点演算パフォーマンスに注目。浮動小数点演算ユニット(FPU)を従来のx86 CPUの2倍に増やしつつある。
現在のx86 CPUは、64bit浮動小数点演算ユニット群で128bit SIMD演算を実行している。そのため、マックスの演算スループットは2サイクルで効率が悪い。それに対して、AMDの新コアは64bit×2=128bitの浮動小数点演算ユニット群を備え、1サイクルスループットで128bit SIMD演算を実行できる。これは、IntelのCore MA、Centaurの2007年新コア「CN」でも同じだ。
 |
| 128-bit SSE and 128-bit Loads(※別ウィンドウで開きます) PDF版はこちら |
また、演算幅の拡張にともない、3社ともそれぞれデータパスを64bitから128bitへと倍増させている。AMD新コアでは、L1データキャッシュからCPUコアへのパスは128bit×2で、2つの128bitロードを並列に実行できる。
ただし、相違も色々ある。AMDは浮動小数点演算ユニットを倍増させたが、整数演算ユニットと浮動小数点演算ユニットのスケジューラとイシュー(命令発行)ポートを分離する構造はK7/K8アーキテクチャから変えていない。それに対して、IntelのCore MAは整数演算系と浮動小数点演算系のスケジューラを統合している。
●アウトオブオーダロードの実装も2社で共通
アウトオブオーダ型のロードも、AMDとIntelに共通する強化ポイントだ。Hester氏によると、新コアに実装するアウトオブオーダ型ロード実行は、Intelの「Memory Disambiguation(メモリディスアンビギュエイション)」とほぼ同様の機能で、時間がかかるメモリからのロードのレイテンシを隠蔽、CPUコアの高速化を図ることができる。
通常、ロード命令より前のプログラム順番にストア命令がある場合、それ以上前にロード命令を繰り上げて実行することができない。それは、ストア命令がデータを書き込むはずのメモリアドレスから、先にデータをロードしてしまう可能性があるからだ。ストアで書き換える前に、データをロードしてしまうと、正しい値にならなくなる。だから、ロードをストアの前に出すためには、動的に依存関係を判定するメカニズムが必要になる。Houndコアでは、依存関係をチェックする内部レジスタを備え、ハードウェアでハンドリングするという。ソフトウェア側に手を加えることなく、自動的に投機ロードが行なわれることになる。
AMDは概要を明かしていないが、新コアで分岐予測も強化する。「メモリテクノロジが変化すると、分岐予測機構を変えることが理にかなうようになる」とHester氏は語る。ちなみに、IntelはCore MAでは、基本的にNetBurst(Pentium 4)系の分岐予測機構を実装している。Pentium M/Core(Banias:バニアス)系マイクロアーキテクチャよりも、NetBurstの方が強力な分岐予測を備えており、Core MAはそれを継承する。Core MAの方がNetBurstよりパイプラインが短く予測ミスのペナルティが小さいため、NetBurstよりCore MAの方が分岐の効率はアップする。つまり、分岐予測の強化の方向も、AMDとIntelで共通することになる。
AMDの新コアは、従来のK8より2倍の命令フェッチ幅を備える。一度に32bytesをL1命令キャッシュから取り込み、その中から命令をフェッチする。x86命令は可変長で、15bytesといった非常に長い命令まで含んでいる。そのため、命令フェッチ幅を広げることは、命令デコーダに、十分な命令を送り込む余裕を広げるが、分岐した場合に捨てるフェッチ部分が増えることも意味する。AMDの32bytesの命令フェッチは、IntelのCore MAの16bytesフェッチの2倍で、ややオーバーキルに見えるが、相応の理由があると思われる。
AMDは、命令フェッチは2倍に増やすものの、命令フェッチの下のx86命令デコーダ部は、3デコーダ構成のままに留める。
「命令デコーダにもいくつかのマイナーな拡張を行なったが、大きなものではない」とHester氏は語る。Hester氏は、最大デコード命令数も3命令/サイクルで変わらないことを認めた。これは、デコーダを4個に増やしたCore MAと大きく異なる点だ。
AMDは、K5マイクロアーキテクチャで4デコーダ構成を取ったが、それ以降はデコーダ数を増やすことに慎重な態度を取っている。デコード帯域を増やすか増やさないかは、AMDとIntel両社の新アーキテクチャの大きな差の1つとなっている。実際、IntelのCore MAは、4wayデコードにしたことで、デコーダ回りでかなり苦労している様子が見える。AMDが3wayに留まるのは、決して間違えた判断ではないかもしれない。
●DRAMアクセスレイテンシとキャッシュ量のバランス
Intelは最初の世代のクアッドコアCPUはマルチダイ構成を取る。これはIA-32系だけでなくIA-64系でも同じで、CPUアーキテクチャ上の完成度よりも、ダイバリエーションを増やさずにクアッドコアを迅速に導入することに集中する。一方のAMDは、CPU設計をモジュラー化することで、ダイバリエーションを増やすことを容易にし、オンダイのクアッドコアを迅速に導入する。
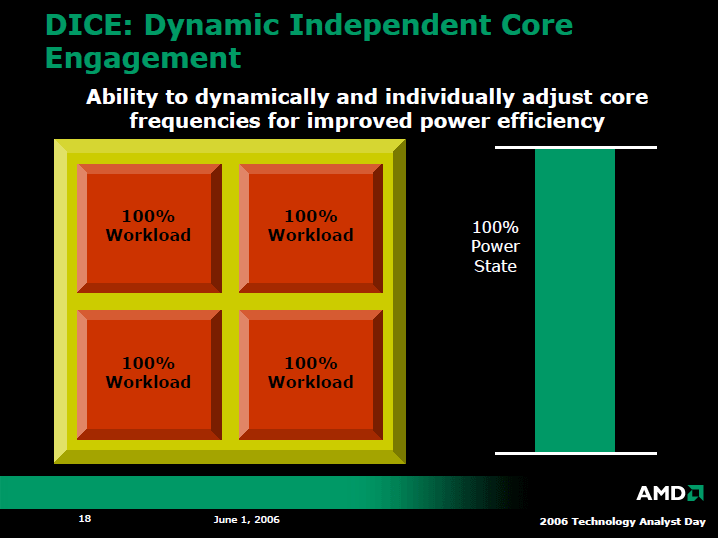
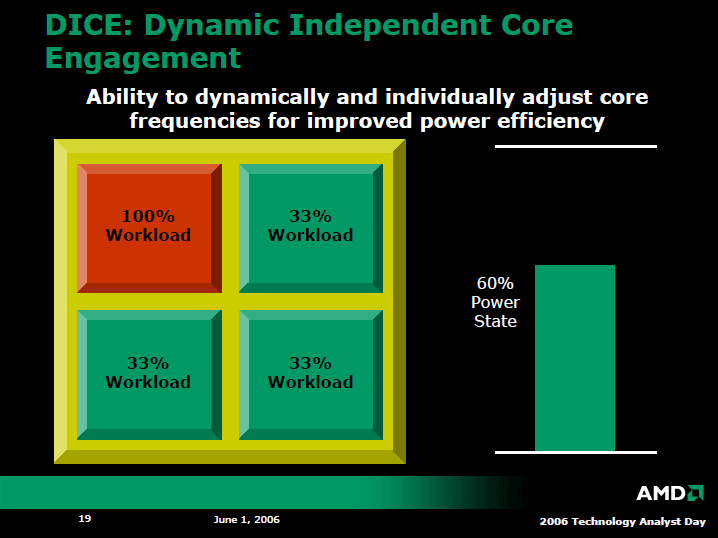
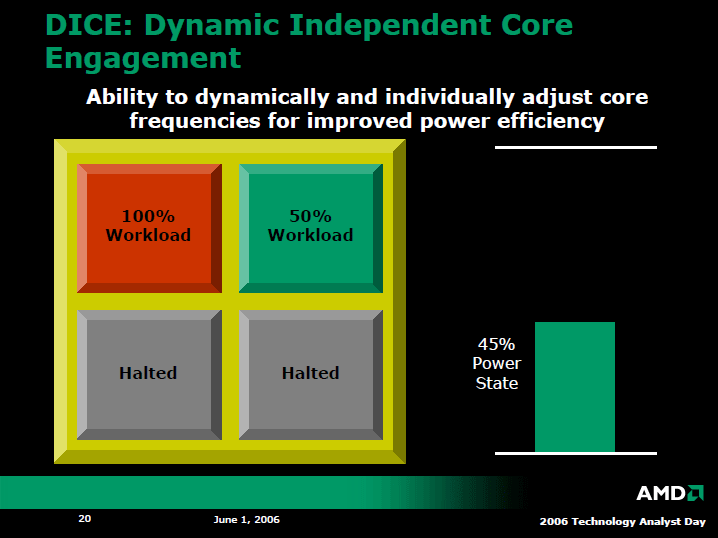
クアッドコアのHoundでは、各CPUコアのパワープレーンを分離し、それぞれ異なる周波数で動作させることで、電力消費を抑制する。ただし、それぞれのコアに供給する電圧は、現状では同一で、省電力効果は周波数でのみ得られる。また、CPUコアがアイドルになった時は、CPUコア単位でスタンバイに移行させて、さらに消費電力を抑える。このあたりのメカニズムの基本はIntelと似ている。
 |
| DICE:Dynamic Independent Core Engageement(1)(※別ウィンドウで開きます) |
 |
| DICE:Dynamic Independent Core Engageement(2)(※別ウィンドウで開きます) |
 |
| DICE:Dynamic Independent Core Engageement(3)(※別ウィンドウで開きます) |
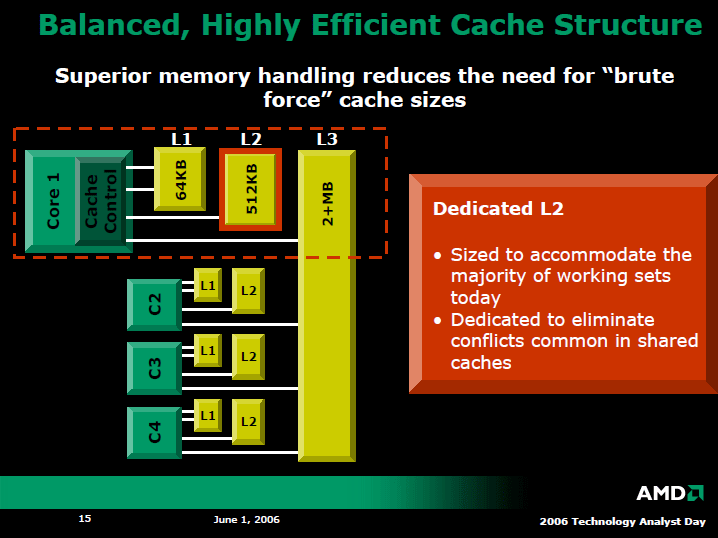
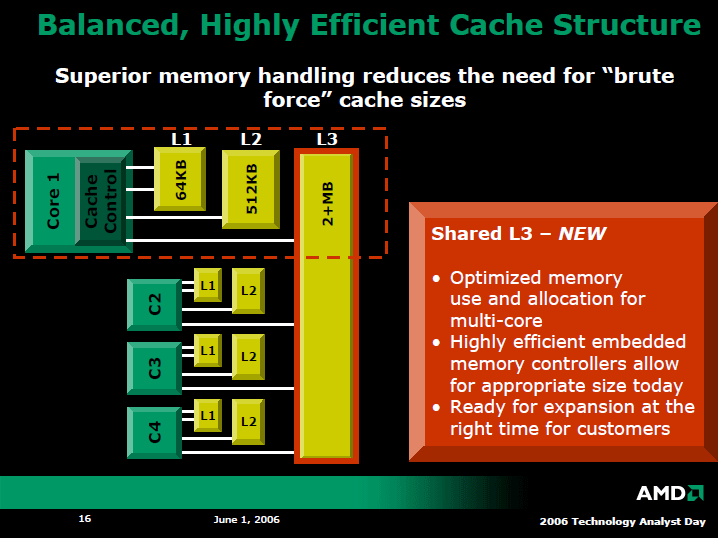
AMDはクアッドコアのHoundでは、AMD CPUで初めてL3キャッシュメモリを搭載した。しかし、最初の世代ではL3のサイズは2MBに留める。それに対して、IntelのMP向けCPUでは、今年登場する「Tulsa(タルサ)」で16MB L3と、数倍のキャッシュを載せる。AMDとIntelで、キャッシュ量には膨大な差がある。
「競合(Intel)は膨大なキャッシュを、あたかもパフォーマンス(上の利点)であるように言い換えている。しかし、彼らが、巨大なキャッシュを載せるブルートフォースアプローチを必要とするのは、メモリレイテンシが大きいからだ。我々は(DRAMコントローラをCPUに内蔵するアーキテクチャのため)メモリレイテンシがずっと小さい。そのため、キャッシュを無闇に増やす必要がない。システムレベルのバランスで見れば、(Intelより)小さなキャッシュ量で十分だ。これは、よりスマートな選択で、効果的なダイサイズソリューションでもある」とHester氏は説明する。
AMD CPUはDRAMに直接アクセスができるため、外部メモリレイテンシが低い。そのため、メモリレイテンシの多いIntelほどキャッシュを増やさなくて済むというわけだ。そして、キャッシュを減らせるため、AMDのサーバーCPUは、IntelのサーバーCPUより小さなダイサイズで済む。これは、製造キャパシティがIntelより小さいAMDにとって、非常に重要な利点だ。製造コスト的にも低く抑えることができるため、AMDの競争力を高める。ただし、将来的にはキャッシュ量を増やす可能性があることも、AMDは示唆している。
●クアッドコアのHoundでは2MBのL3を搭載
Houndでは、L1とL2は各CPUコアに固有、L3が4つのCPUコアで共有となっている。下のスライドだと、各コアがキャッシュコントローラを内蔵して直接L3に接続されているように見えるが、実際にはそうではない。L3はキューにサイドポートで接続された構成になっているという。
 |
| Balanced, Highly Efficient Cache Structure(1)(※別ウィンドウで開きます) |
 |
| Balanced, Highly Efficient Cache Structure(2)(※別ウィンドウで開きます) |
 |
| Balanced, Highly Efficient Cache Structure(3)(※別ウィンドウで開きます) |
従来のAMDアーキテクチャでは、L2キャッシュとメインメモリに対して、ある程度オーバーラップしてアクセスをかけることで、メモリアクセスレイテンシを減らしていた。Hester氏によると、Houndコアでは、L3とメインメモリに同時にアクセスをかけてレイテンシを減らすという。これは、CPUコアにDRAMコントローラを実装したAMDアーキテクチャの利点だ。
HoundのCPUコアでは、2MBのL3キャッシュを設ける一方、L2キャッシュは各コア512KBと、従来のサーバー向けCPUコアより少量になっている。
「これ(キャッシュ量)は、(トランジスタの)バジェットとワークロードを通じての、キャッシュシステムのモデリングを行なって決めた。キャッシュの量に、数学的な根拠はないはずだ。決められた(CPUに搭載できる)SRAMの総量の中で、異なるキャッシュコンフィギュレーションとワークロードをモデル化した。例えば、同じSRAM量でも、モデルのパラメータを変えて1 MBのL2と異なる量のL3にすれば、異なるパフォーマンスが理論上導き出される。そうしたモデルの中で、ベストなパフォーマンスとなる組み合わせを取ったに過ぎない」
経済的に製造できるコアのダイサイズ(半導体本体の面積)には限界があるので、搭載できるSRAMメモリの総量は決まってしまう。AMDはその総量を、L2とL3にどう配分するかをシミュレーション、サーバーの典型的なワークロードの中でパフォーマンスが最高になる組み合わせを導き出したら、このバランスだったというわけだ。AMDはIntelのように400平方mmを超えるようなダイサイズのCPUは作らず、サーバー向けでも200平方mm台に留める。そのため、キャッシュ量は制約される。
●ワンホップでのアクセスのためにHyperTransportを4リンクに
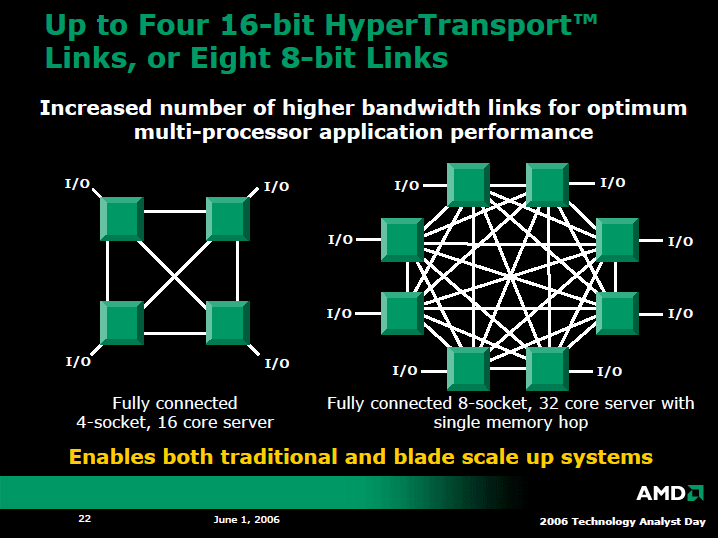
AMDはCPUソケットを更新して、各セグメント毎にサポートできるHyperTransportリンクの数を変えた。サーバー向けのSocket Fでは最大4リンクの×16bit HyperTransport、デスクトップ向けのSocket AM2は最大3リンク、モバイル向けのSocket S1は1リンクが可能だ。また、サーバーでは、リンクを分割することで、8リンクの×8bit HyperTransport構成も可能となっている。
その結果、サーバーでは、最大8ソケット、それぞれがクアッドコアなので最大32 CPUコアの構成が、ワンホップリンクで可能になる。つまり、1つのCPUが他のCPUに、ダイレクトにワンホップでアクセスする構成で、8ソケットまで実現できる。
 |
| Up to Four 16-bit HyperTransport Links, or Eight 8-bit Links(※別ウィンドウで開きます) |
AMDの場合、メモリはCPUに接続されているため、これは重要だ。8ソケットシステムで、他のCPUに接続されたメモリにアクセスする場合も、Houndなら必ずワンホップでアクセスできる。それだけメモリレイテンシが短く、余計なトラフィックも避けられる。Hester氏は、その結果、Hound世代では、優れたスケーラビリティが得られるようになったと強調する。
「4リンクのうち、1リンクはI/O接続に使うので、3リンクをCPU間のインターコネクトに使うことができる。だから、3つのプロセッサまでをダイレクトに接続できるようになる。8リンクの場合は7プロセッサをダイレクトに接続できる。この構成で重要なことは、各プロセッサのメモリ間のアクセス時間が、最悪でもワンホップと短くなることだ。
それぞれのプロセッサが、他のプロセッサのローカルメモリに、最悪でも1回のホップでアクセスできる。我々は、こうしたフラットメモリモデルが、スケーラビリティで重要になると考えている」
AMDは、K8アーキテクチャを導入する際には、2ホップ以上のアクセスが必要なコンフィギュレーションでも、システムを構成できると説明していた。だから、K8は最大3リンクのHyperTransport構成だった。しかし、Hound世代からは、方針を転換、ワンホップでのアクセスが必要だと見るようになった。
「すでにAMDプラットフォームで8CPUコアのシステムがあるじゃないかと疑問に思うかもしれない。しかし、今日の構成の場合、(他のCPUに接続された)メモリの一部は2ホップと遠くにある。それでも、いいスケーラビリティが得られるが、ワークロードによっては、ユーザーが望むほどいいスケーラビリティではない。
もう少し説明すると、従来は大規模サーバーシステムのために、我々はMicrosoftと、ちょっとした量の作業を行なってきた。具体的にはシステムリソースのテーブルを設けて、OSにローカルメモリとグローバルメモリの特性を伝えている。OSは(そのテーブルをベースに)メモリプールを、そのメモリを必要とするプロセッサにできるだけ近く配置するように試みる。この方式は完全ではないが、大規模サーバーでのパフォーマンスを最適化する助けとなってきた。
しかし、(4リンクHyperTransportなら)全てのワークロードで、優れたスケーラビリティを約束できる。メモリモデルをよりフラットにするにつれて、パフォーマンスを最適化するためにしなければならないソフトウェア作業の量は減る。その分、少ないソフトウェアチューニングで、アプリケーションがスケールアップできるようになる。(Houndでは)32コアまでのスケールアップが容易に実現できるようになった」
実際には、これまではHyperTransport自体のカウンタフィールドも3bitだったので、最大で8プロセッサ構成止まりだった。Hound世代ではこれも拡張されたはずだが、AMDはどこまで拡張されたかは明らかにしていない。
「それ(アドレスフィールドのビット数がいくつであるか)は実装上の決定であって、アーキテクチャ上のものではない。個々の実装では各領域が定義されているが、アーキテクチャはより広い範囲で(実装上の定義を)できるようにする」(Hester氏)
つまり、アーキテクチャ的にはより大規模なマルチプロセッサ構成も可能だが、実装レベルでは異なると言う。
 |
| Up to Four 16-bit HyperTransport Links, or Eight 8-bit Links(※別ウィンドウで開きます) |
IntelのCore MAに対抗できるCPUコアと、オンダイ統合のクアッドコア構成を持つAMDのサーバー&デスクトップコア。AMDにとっては非常に強力な武器だが、問題はその投入時期だ。2007年中盤の投入は、IntelのCore MAに約1年の遅れとなる。それまで、AMDがIntelの攻勢に耐えきれるかどうかについて、マザーボードベンダーなどでも疑問視する関係者は多い。
しかも、近年のAMDは、投入すると発表していた時期からスリップすることが頻繁にある。2007年中盤というAMDの言葉を額面通り受け取っている関係者は少ない。AMDは、こうした不信も払拭して行く必要がある。
□関連記事
【6月22日】【海外】デュアルコアK8とは大きく異なるAMDのモバイルコア
http://pc.watch.impress.co.jp/docs/2006/0622/kaigai283.htm
【6月16日】【海外】設計のモジュラー化で市場に最適化したCPUコアを
http://pc.watch.impress.co.jp/docs/2006/0616/kaigai282.htm
【5月31日】【海外】Rev. Fの次の次に来るAMDの次世代コア「Hound」
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai273.htm
(2006年7月3日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.