 |


■後藤弘茂のWeekly海外ニュース■コプロセッサの時代を開く、AMDの「Torrenza」イニシアチブ |
●コプロセッサに重点を置くAMDの新戦略
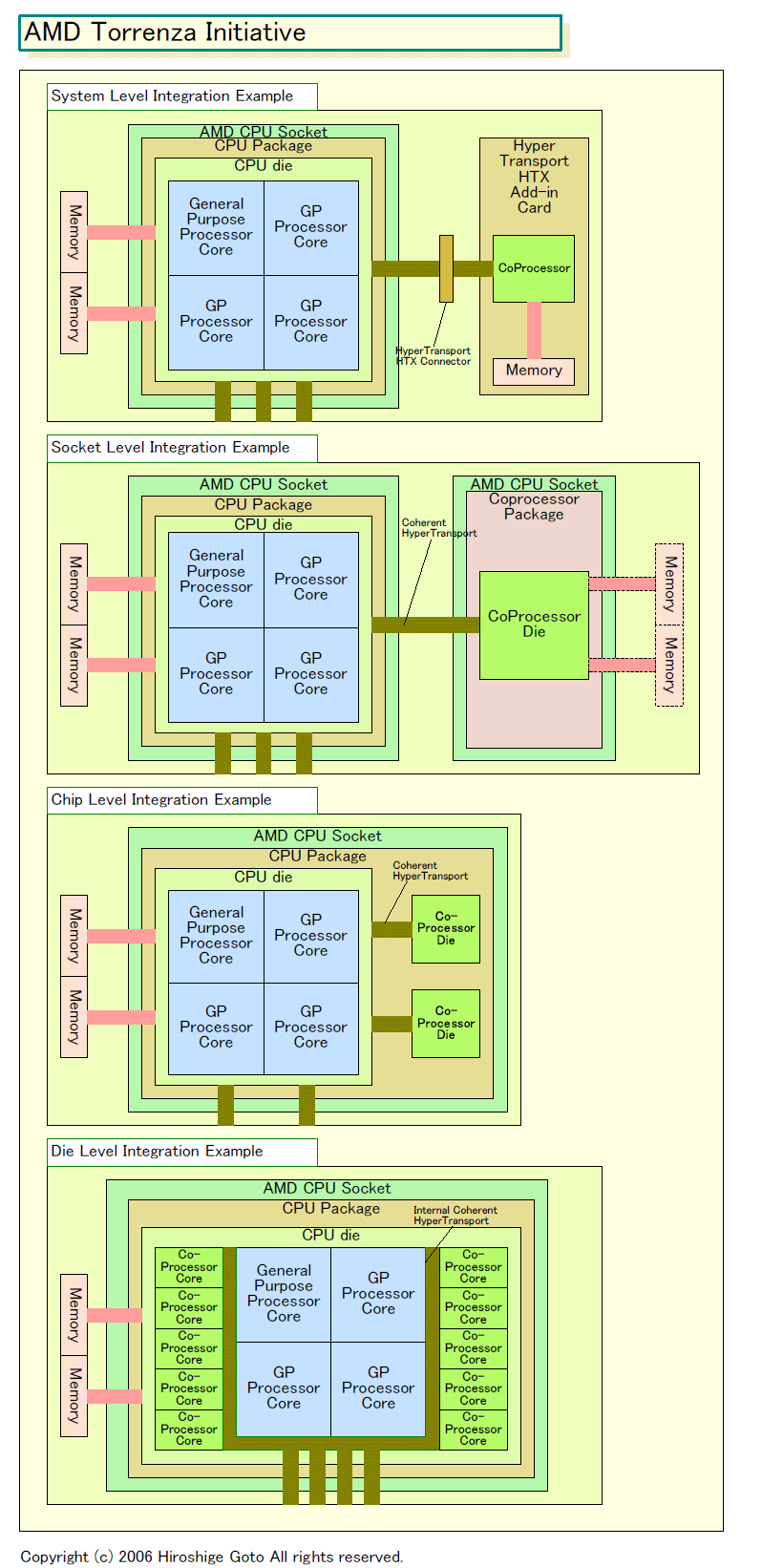
AMDは、包括的なコプロセッサイニシアチブ「Torrenza(トレンザ)」を推進しようとしている。Torrenzaのポイントは4つ。(1)新しいアプリケーションに特化したアクセラレータ(=コプロセッサ)の導入で、消費電力を抑えながら特定分野のパフォーマンスを劇的に上げる。(2)コプロセッサを密接に統合するためのインターフェイスとして「Coherent HyperTransport」をライセンスすることで、サードパーティがコプロセッサを容易に開発できるようにする。(3)拡張カードからAMD CPUソケット向けパッケージ、AMD CPUへの統合まで、さまざまなレベルでAMDプラットフォームにコプロセッサを統合できるようにする。(4)コプロセッサのエコシステムが回るようにすることで、AMDプラットフォームにコプロセッサが花開くようにする。
 |
| AMD Torrenza Initiative (※別ウィンドウで開きます) PDF版はこちら |
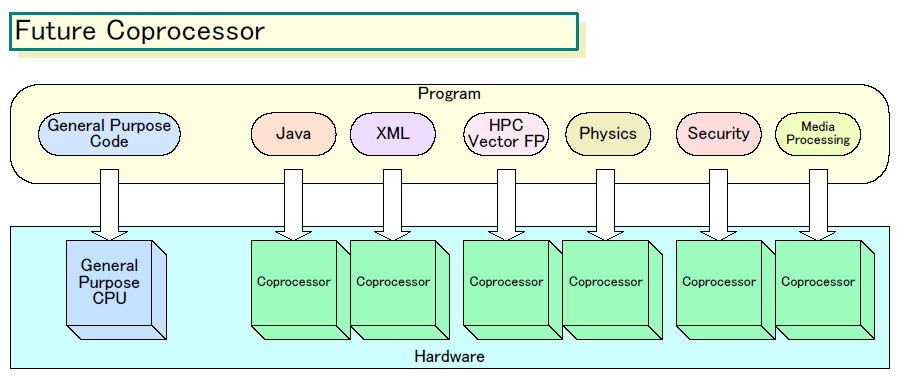
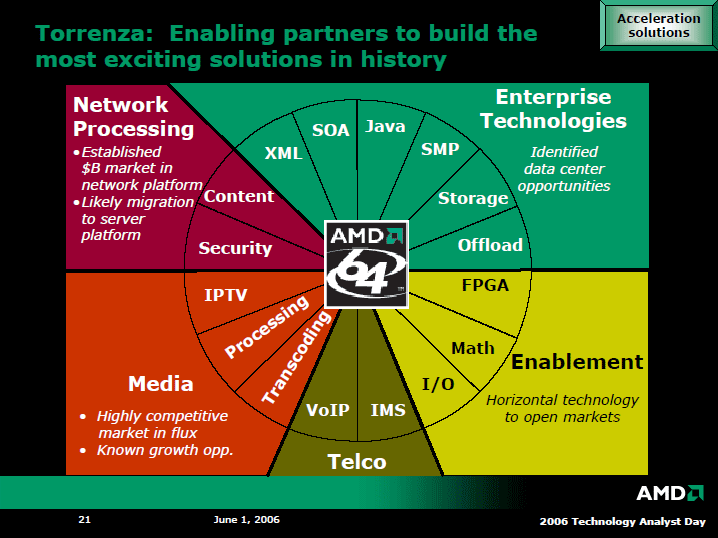
AMDが想定するコプロセッサの適用分野は広範囲だ。「Java」、「XML」、「ハイパフォーマンスコンピューティング(HPC)向けベクタ浮動小数点演算」を軸に、そのほか「メディアプロセッシング」、「ゲーム向け物理シミュレーション」、「セキュリティ」などをAMDは挙げている。コプロセッサによって、JavaやXMLといった新しいプログラミングモデルの効率的な実行や、HPCなど特定分野の性能強化、PCのメディア処理やゲームの高速化などを狙う。
 |
| Future Coprocessor (※別ウィンドウで開きます) PDF版はこちら |
AMDは、プログラミングモデルの変化やアプリケーションニーズの多様化、x86 CPU市場の拡大とともに、単一の汎用CPUアーキテクチャで全てをカバーできる時代は終わりつつあると考えている。特定アプリケーションを高速化するコプロセッサを導入することで、柔軟に多様な市場ニーズに対応して行こうとしている。また、汎用プロセッサでは処理が重いアプリケーションを、専用化したコプロセッサに移すことで、システム全体のパフォーマンス/消費電力も向上させる。現在のCPUの最大の課題である省電力化も、コプロセッサで向上させるわけだ。
従来のアクセラレータが、PCIやPCI Expressなど汎用インターフェイスに頼らなければならなかったのに対して、Torrenzaでは、より密な結合をサポートする。AMDがCPU同士の接続に使用しているCoherent HyperTransportをコプロセッサベンダにライセンス。CPUとコプロセッサの間で、メモリのコヒーレント(一貫性)を取ることで、より密接に結合され、高パフォーマンスなコプロセッシングができるようにする。AMDのCPUソケットにコプロセッサを挿入したり、マルチチップモジュールでCPUパッケージにコプロセッサを統合、あるいはCPUのダイ(半導体本体)にコプロセッサを統合する。
 |
| Coming Soon:“Torrenza” (※別ウィンドウで開きます) PDF版はこちら |
●多様化するニーズにコプロセッサで対応
AMDのTorrenza戦略の背景にある思想はシンプルだ。それは、多様化するニーズと市場には、プロセッサも多様化で対応しなければならないということだ。
 |
| AMDのPhil Hester(フィル・へスター)氏 |
「伝統的な“単一サイズで全てに対応する(one size fits all)”モデルは、すでに終わった」とAMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer)は語る。
多様化に対応するために、AMDはCPU設計をモジュラー化して、多様なコンフィギュレーションのCPU開発を可能にした。モバイルからサーバーまで、市場毎に異なるCPUを投入することで、ユーザーニーズにきめ細かく対応する。そして、Torrenzaでコプロセッサを容易に導入できるようにすることで、市場毎のアプリケーションの多様性にも対応する。コプロセッサを使うことで、特定アプリケーションのパフォーマンスを効率的に引き上げる。
「アプリケーションに特化したコプロセッサの例としては、まずJavaやXML、ハイパフォーマンスの科学技術系コンピューティング市場でのベクタ浮動小数点演算などが挙げられる。潜在的には、メディアプロセッシングアプリケーションなども、将来は考えられるだろう。データセンターなどのワークロードを分析した結果、こうした(コプロセッサ)機能を念頭に置いて次世代プロセッサを開発する必要があることが明白となった」とHester氏は説明する。
 |
| Diversity of Workloads and Oppotunities for Specialized Processor PDF版はこちら |
つまり、AMDは実際にコンピューティングパフォーマンスが必要とされるアプリケーションを研究した。その結果、JavaやXMLの普及によるプログラミングモデルの変化、HPCのようにAMDが新たに浸透した新分野のニーズ、メディアプロセッシングのように今後需要が高まるアプリケーション分野、などが見えてきた。そして、これら新しいアプリケーション分野については、汎用プロセッサを強化して性能を上げるよりも、アプリケーションに特化したコプロセッサのアプローチが有効だと判断したというわけだ。そのため、コプロセッサを前提としたプロセッサやシステムの開発が必要と、現在のAMDは考えているようだ。
 |
| “Torrenza”: Enabling partners to build the most exciting solutions in history(1) PDF版はこちら |
●電力効率がよいコプロセッサ
また、AMDはコプロセッサが有効だと判断した理由は、パフォーマンス/消費電力の効率のためであることも説明している。
「我々が専用化したアクセラレータにフォーカスする理由の1つは、(アクセラレータが)非常に電力効率の面で優れているためでもある。コプロセッサは、パフォーマンス/ワットではかなりの利点がある。適正に設計すれば、目覚ましいパフォーマンス向上だけでなく、かなりの省電力も達成できるはずだ。一定の電力の範囲で、特定のアプリケーション性能は劇的に上げられるだろう」(Hester氏)
AMDが6月に日本で開催した「AMD Opteronクラスタ・カンファレンス2006」でも、HPC向けの浮動小数点演算コプロセッサを開発するClearSpeedの製品の利点として、パフォーマンス/消費電力が示された。例では、ClearSpeedを使うことで、パフォーマンス(LINPACKベンチ)を4倍に伸ばしながら、消費電力を32KWから29KWに下げていた。
電力効率は、汎用プロセッサとアプリケーション特化型プロセッサの比較で常に語られるポイントだ。汎用プロセッサの方が柔軟に多様なアプリケーションに対応できるが、同じアプリケーションを処理する場合はより多くの電力を消費しがちだ。ある程度アプリケーションに特化したプロセッサは、柔軟性は低くなる代わりに電力効率はぐっと上がる。両者はトレードオフの関係にある。AMDは、電力効率が重要となった今は、アプリケーションに特化したコプロセッサが適切なアプローチだと判断した。
こうして見ると、AMDのコプロセッサ戦略は、単に、システムにコプロセッサを加えられるようにするというだけでなく、プロセッサやシステムをどう作ってゆくかという根底の発想を切り替えたものだとわかる。新しいアプリケーションについて、一定の消費電力の枠の中で、劇的にパフォーマンスをアップさせるには、汎用プロセッサと専用化したコプロセッサの組み合わせが最適とAMDは見ているようだ。
Intelも「Many-core」では、汎用プロセッサコアと特化したサブプロセッサコアを組み合わせることを考えている。しかし、Intelは現在のところ、少なくともCPU本体に統合するコアについては、AMDほどアプリケーションに特化させることは考えていない。ここが思想が分かれるところに見える。
●サードパーティを巻き込むことを主眼とするTorrenza
開発リソースの大きいIntelは、自社プラットフォーム向けソリューションは自社で開発しようとする。それに対して、リソースが限られるAMDは、サードパーティに頼る比率が高い。TorrenzaでもAMDは、同社のアーキテクチャをよりオープンにすることで、サードパーティを集結させようとしている。AMDプラットフォームに対して、さまざまなコプロセッサが各社から登場すれば、AMDの競争力が高まるというシナリオだ。
実際には、JavaやXML、HPC向けなどはすでにアクセラレータが存在する。Torrenzaでは、そうしたアクセラレータを、物理的にシステムに統合しやすいように、AMDはプラットフォームを整える。システムへのコプロセッサの統合を、さまざまなレベルでステップバイステップで進められるようにする。システムレベルの統合からパッケージレベル、そしてダイレベルの統合へと道を敷く。Torrenzaの根幹は、そのためのインターフェイスとして「Coherent HyperTransport」をサードパーティにライセンスすることにある。
AMDのHester氏は、現在のアクセラレータの問題は、高パフォーマンスなコプロセッサを、サードパーティが容易に開発できるインフラが欠けていることだと指摘する。
「すでに、何社かが新しいワークロードであるJavaやXMLを高速化する専用サーバーを発表している。これらの製品は素晴らしいが、業界は問題も抱えている。それは、各ベンダーが完全なシステムを作らなければならないことだ。簡単に(アクセラレータを)提供できるインフラを欠いている。
アクセラレータを使う“n+1”システムでは、n台の伝統的なサーバーから、特定のワークロードを追加の専用(アクセラレータ)システムに渡す。この場合の問題は、汎用サーバーとアクセラレータの連携にある。汎用プロセッサと専門化コプロセッサの間を、効率的に結ぶことが望ましい」
 |
| AMDのMarty Seyer氏 |
これまでは、CPUとの間で、コヒーレントアクセスができる標準的なインターフェイスがないために、効率的なコプロセッサが作れなかった。そこで、AMDは、Coherent HyperTransportをライセンスすることで、より高性能で汎用性の高いコプロセッサへの道を開く。コヒーレンシを保って共有メモリにアクセスできるようにすることで、データアクセスのレイテンシを最小にする。
AMDが6月頭に開催したカンファレンス「Analyst Day」では、AMDのMarty Seyer氏(Senior Vice President, Commercial Segment)が、「Torrenzaの一部としてCoherent HyperTransportをライセンスしつつある」と宣言した。
●ソケットフィラーがコプロセッサの次のステップ
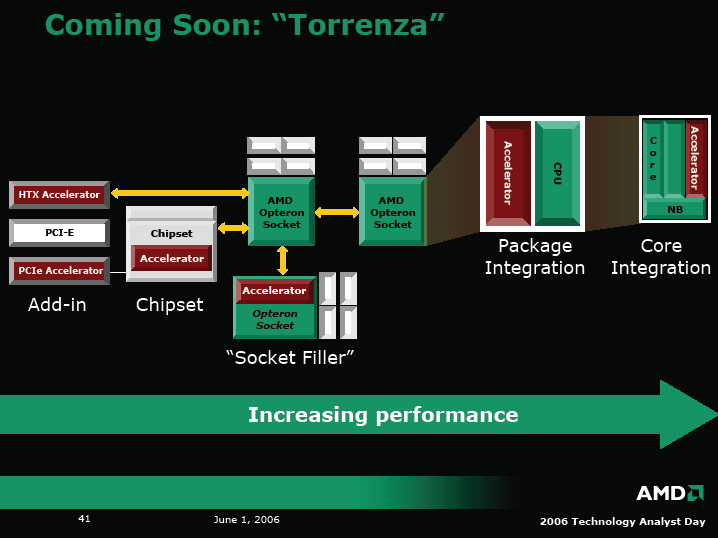
AMDが想定するコプロセッサの統合形態は次のようなステップとなっている。
(1)PCI Expressなど業界標準バスのスロットにアドイン
(2)HTX(HyperTransportの拡張スロット仕様)にアドインしてCPUとHyperTransportで直結
(3)HyperTransportで接続するチップセットに統合
(4)AMD CPU用ソケットに装着してCPUとCoherent HyperTransportで直結
(5)CPUパッケージに同封してCPUとCoherent HyperTransportで直結
(6)CPUと同じダイ(半導体本体)に統合してインターナルCoherent HyperTransportで直結
上がより簡易な統合で、下に行くに従って密接な統合へと進んでゆく。
「今日の段階では、HTX HyperTransportコネクタやPCI Expressなどを通じてコプロセッサをアタッチすることができる。次のステップとして、我々のパートナーのいくつかは、サウスブリッジチップにアクセラレータを統合することも検討している。
HTXは最初のステップだが、時間とともに、よりパフォーマンスが得られる、もっとタイトな統合の方向へ向かって行くだろう。Opteronプロセッサを置き換えて、(AMD CPUソケットに挿入する)『プラグインソケットフィラー(Plug-in Socket Filler)』だ。そして、将来はマルチチップパッケージによって、CPUとは異なるシリコンダイを効率的にCPUダイと統合することができるだろう。
 |
| Today: HyperTransport HTX Enables First-Generation System-level Co-processing PDF版はこちら |
さらにその先は、統合しても利にかなうようになった時点で、コプロセッサをCPUダイそのものに統合する。我々は、将来のCPUをモジュラーアプローチで設計しており、CPUに将来のニーズのためのほかの機能ブロックを加えることができるようにしている。だから、容易にコプロセッサをオンチップに統合できる」とHester氏は語る。
Coherent HyperTransportベースのコプロセッサでは、AMD CPUソケットと互換のパッケージにすることで、AMD CPUを置き換えることができる。すでにソケットフィラーはDRCのFPGAベースコプロセッサなどで始まっており、AMDはこの形態が将来普及することを期待している。
●Intelもコプロセッサを検討し始めた
AMDのAnalyst Dayでは、DRCのソケットフィラー型FPGAコプロセッサを、Opteronベースのスーパーコンピュータで採用したCrayが登場。スカラコードはOpteronで実行し、ベクタコードをコプロセッサで実行することで劇的なパフォーマンスを達成できると説明した。Crayによると、ソケットフィラーにしたことで、コプロセッサ用に特別なインターフェイスを開発することなく、迅速にスパコンを開発できたという。
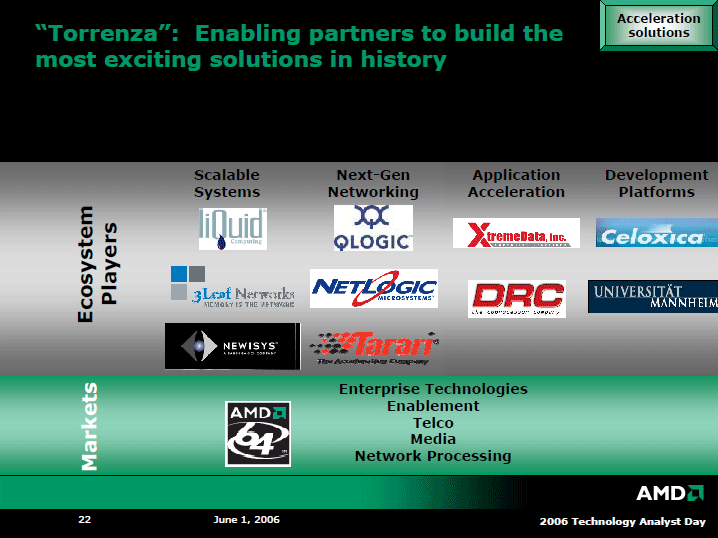 |
| “Torrenza”: Enabling partners to build the most exciting solutions in history(2) PDF版はこちら |
 |
| “Torrenza”: Enabling partners to build the most exciting solutions in history(3) PDF版はこちら |
また、Seyer氏はAnalyst DayでNetlogicのPCI Expressベースのアクセラレータカードを示し「今、我々はHyperTransportをオープンにした。パートナーは、(HyperTransportの)プラットフォームで製品を開発することができる。コアシリコンと密接に接続することで、ネットワークセキュリティを10倍に向上させることができる。2プロセッサのうち、片方のソケットをセキュリティデバイスにするといったことができる」と説明した。
 |
| Direct Connect Computing Introducing “Torrenza” PDF版はこちら |
AMDは、PCでも、2つのCPUソケットと2リンクのPCI Expressで最大4個のCPUコア、4個のGPUを搭載する“4×4”プラットフォームを推進している。2つ目のCPUソケットは、デュアルプロセッサだけでなく、コプロセッサにも使うというのがAMDの構想だ。
AMDは、TorrenzaでCPUソケットまでオープンにする。Hester氏は、このオープン性がIntelとは異なると強調する。
ただし、あるIntel関係者は、同社も何らかの形でコプロセッサを、よりタイトに接続できるようにするプランを持っていることを示唆する。コプロセッサの有効性を、Intelも注目するようになりつつあるようだ。もっとも、IntelのプランはCPUソケットを他社が使えるようにするものではないという。
Intelは次々世代の2008年以降のサーバーCPUでは、シリアルインターフェイス「CSI」を導入し、CPU同士を直接接続できるようにする。その時点では、メモリインターフェイスとしてFB-DIMMインターフェイスもCPU側に内蔵する。AMD CPUと極めて似た構成になるわけだ。
もし、IntelがCSIをライセンスし、CPUにコプロセッサを接続できるようにすることを考えているなら、Torrenzaと同じ方向を向いていることになる。CPUソケットを使わないとすると、かつてのIntelのコプロセッサソケットのような、専用ソケットをCSIテクノロジベースで考えている可能性もある。CSIは物理的にはPCI Expressとよく似ていると言われており、PCI Expressを実装したベンダにとっては馴染みやすい可能性もある。 CPUベンダーのこうした動きからは、コプロセッサが業界の潮流になりつつあることがわかる。20年前のようなコプロセッサの時代が、再びやって来るのかもしれない。
□関連記事
【6月2日】【元麻布】AMDが2008年以降のロードマップを公開
http://pc.watch.impress.co.jp/docs/2006/0602/hot431.htm
【6月1日】【海外】拡大が進むAMDのコプロセッサ構想
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
【5月8日】DRC、Opteronソケットに実装するFPGAコプロセッサ
http://pc.watch.impress.co.jp/docs/2006/0508/drc.htm
(2006年7月13日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.