 |


■後藤弘茂のWeekly海外ニュース■デュアルコアK8とは大きく異なるAMDのモバイルコア
|
●K8とはレイアウトが大きく異なるモバイルコア
AMDは来年(2007年)の中盤以降に、ノートPC向けに設計を最適化したモバイルコアを投入する。これは、65nmプロセスで製造され、デュアルコア構成で、通常電圧版だけでなく、ULV(超低電圧)版とLV(低電圧)版も投入される。また、コア全体の設計は、従来のK8コアとは大きく変わる。AMDのモバイルCPUは、65nmプロセスでは、まず、現在の「Rev. F(Revision F)」とほぼ同じ設計の「Rev. G」をリリース、次にモバイルコアに移行する。
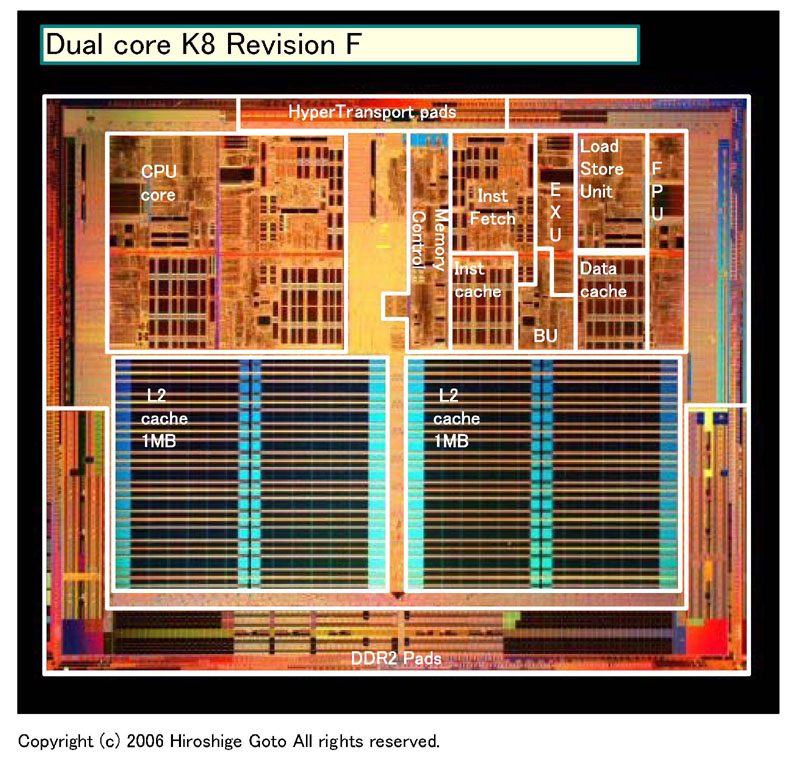
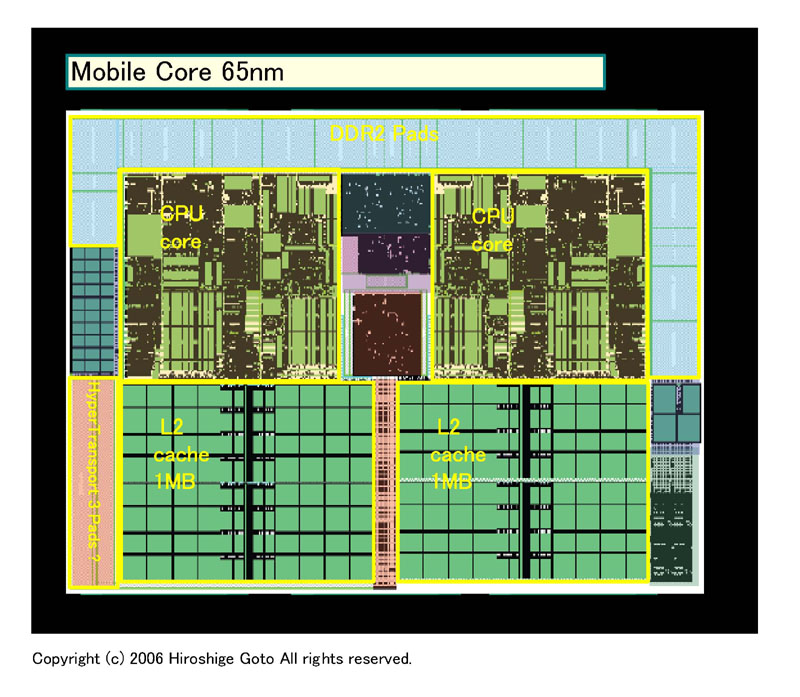
下がRev. Fとモバイルコアの比較図だ。
 |
 |
| K8 Rev.F (※別ウィンドウで開きます) PDF版はこちら |
モバイルコア (※別ウィンドウで開きます) PDF版はこちら |
レイアウトは大きく変わり、従来はL2キャッシュの回りに配置されていたDRAMコントローラがCPUコアの周りに移された。HyperTransportパッドはCPUコアの上から、コアのサイドへ移動。両CPUコアの間にあるノースブリッジ機能は、大きくレイアウトが変わった。また、全体に圧縮された設計となり、Rev. Fより各ブロックが詰まった印象となった。
Rev. Fは90nmプロセス、モバイルコアは65nmプロセス。そのまま縮小すると、同じ設計のCPUならダイサイズ(半導体本体の面積)は半分になる。しかし、モバイルコアは従来のデュアルコアK8より圧縮された設計となっているため、よりダイサイズが小さくなると推測される。Rev. Fの場合、1MB×2 L2キャッシュ版は、ISSCC(IEEE International Solid-State Circuits Conference)での発表を見ると220平方mmのダイサイズなので、モバイルコアのダイは100平方mm前後か、それ以下と推測される。Intelの「Core 2(Merom:メロン)」は4MB L2キャッシュのデュアルコアで148平方mmなので、AMDのモバイルコアの方が一回り小さい可能性が高い。
●サーバーとモバイルに異なるファンクションブロックを用意
 |
| Phil Hester(フィル・へスター)CTO |
これは、システムオンチップ(SoC)ではごく一般的な手法だ。AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))も「マイクロプロセッサのシステムオンチップアプローチだ」と、SoCの手法を取り入れたことを認める。インターフェイスが明確に定義されているため、AMDは各ブロックを組み換えて、異なるCPUを比較的少ない労力で開発できる。「『レゴ』ブロックのように、同じビルディングブロックを違った組み合わせにすることで、異なる(CPU)製品を作り分けることができる」とHester氏は6月の「VIA Technology Forum(VTF)」のキーノートスピーチで語った。
そして、AMDは2007年の新コア開発にあたっては、2系統のファンクションブロック群を用意した。サーバー&デスクトップ用のファンクションブロック群と、モバイル用のファンクションブロック群だ。両系統は共通するブロックもあるが、異なるブロックもある。サーバー&デスクトップでは、同じファンクションブロックを使って、クアッドコアとデュアルコアを作り分ける。一方、モバイルでは、サーバー&デスクトップとは異なるファンクションブロックを使って、まずデュアルコア版を作る。
サーバー&デスクトップのブロックと、モバイルのブロックで異なるのは、パフォーマンスに比較的重点を置くか、省電力を追求するかの違い。例えば、サーバー&デスクトップでは、CPUコア自体が大きく機能拡張される。浮動小数点演算性能は2倍となり、その他にもパフォーマンスのために各種拡張が加わる。IntelのCore Microarchitecture(Core MA)に近く、現行のRev. F(Revision F) K8コアからは、かなり飛躍する。それに対してモバイルコアでは、CPUコア自体はRev. F世代とそれほど変わらないという。
●機能的にはほぼRev. F相当のモバイルコアのCPU
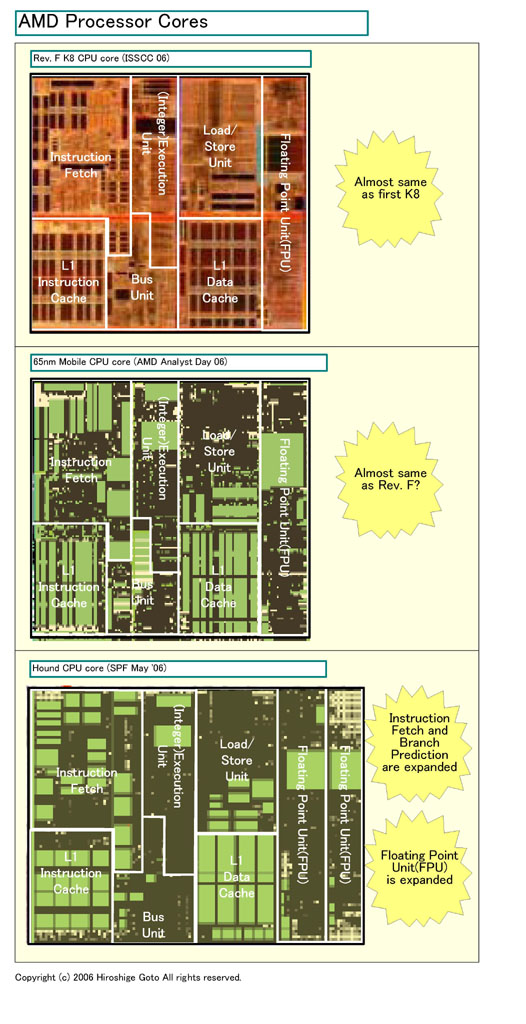 |
| AMDプロセッサコアの比較 (※別ウィンドウで開きます) PDF版はこちら |
モバイルコアのCPUコアについて、Hester氏はインタビューで次のように説明する。
「実行ユニットの観点から言うと、モバイルコアのプロセッサコアは大まかに言って(Rev. Fと)同じだ。なぜ変えなかったかというと、我々はIntelの(NetBurstアーキテクチャの)ように、高速化のための深すぎるパイプラインが、電力を無駄に消費するという問題を抱えていなかったからだ。我々のコアは、すでに高効率に最適化されている。だから、電力効率のためにCPUコアを再設計する必要はないと判断した」
K8系CPUコアは、もともと浅いパイプラインで、NetBurstより電力効率がよい。そのため、CPUコア自体を再設計する必要がないとAMDは決定したというわけだ。
実際、モバイルコアのCPUコア部分のレイアウトを見ても、Rev. FまでのK8系のCPUコアとそれほど変わらないように見える。下が、各コアのCPUコアの比較図だ。一番上がRev. FのCPUコア、真ん中がモバイルコアのCPUコア、一番下がサーバー&デスクトップコアの「Hound(ハウンド)」のCPUコアだ。
サーバー&デスクトップのCPUコアが明瞭に拡張されているのに対して、モバイルのCPUコアはブロックの大きさや配置がほぼ変わらないことが見て取れる。これは、モバイルコアでは、CPUコアに大きな拡張はないというHester氏の言葉を裏付けている。
拡張の少ない、よりシンプルなCPUコアの方がトランジスタ数も少ないため、消費電力は抑えやすい。実際、Intelも、モバイル向けのPentium M系は、NetBurstよりシンプルで効率がよかったP6(Pentium Pro/II/III)系をベースにして設計をスタートさせている。
しかし、Intelは「Core 2(Merom:メロン)」では、かなりCPUコアの機能を拡張している。またモバイルのCore 2は、デスクトップの「Core 2(Conroe:コンロー)」と基本的に同じ機能を備えている。Core 2は、アーキテクチャ的にはAMDのサーバー&デスクトップコアと同等かそれ以上の拡張が行なわれている。
そのため、単純なパフォーマンス比較では、AMDのモバイルコアは、IntelのCore 2と対比すると厳しい戦いになることが予想される。Core 2は、SIMD浮動小数点演算ユニットの128bit化で浮動小数点演算性能を高め、4wayのデコード&発行帯域を備えたパイプラインで整数演算性能も高めているからだ。対するAMDモバイルコアのアーキテクチャ上の性能は、Rev. Fから大きく出ないことになる。
しかし、その分、AMDのモバイルコアのCPUコアの方が、規模が小さい分だけ、原理的には消費電力を抑えやすい。もっとも、実際には、CPUコアの省電力制御も大きく影響するため、単純には比較ができない。
ちなみに、IntelはMeromに4MB L2キャッシュを載せているのに対して、AMDモバイルコアはレイアウトを見ている限り2MBしか載せていない。これは、AMDはDRAMコントローラをCPUに統合しているため、メモリアクセスレイテンシが短いからだ。AMDの場合、Intelほど大量のL2キャッシュを載せてメモリレイテンシを隠蔽する必要性は高くない。ただし、IntelのMeromのL2キャッシュは共有で、ワークロードに合わせて、各コアのL2キャッシュサイズを変えられる利点がある。
●CPUコア以外の部分の省電力機能を強化
CPUコア自体の機能はRev. F/G世代と同じでも、コア全体では、モバイルコアは、かなり変更されている。特に、AMDが力を注いだのは、電力の個別制御と、CPUに内蔵するノースブリッジ機能の省電力化だった。
「モバイルコアの設計では、主に3つの要素にフォーカスした。1つ目は、パワープレーン(電力供給のブロック)を大きく分割した。それぞれのCPUコアとコントローラが、個別のパワープレーンを持つ。次はCPUに内蔵するノースブリッジのメモリコントローラを、省電力と電力効率にフォーカスして最適化した。それからパワーを食うI/Oリンクを制御して、システムのワークロードに応じて動的に電力消費を変えられるようにした」とHester氏は語る。
AMDがモバイルコアで強化したのは、下の3点。
(1)パワープレーンの分離
(2)メモリコントローラの省電力化
(3)I/OリンクHyperTransportの省電力制御
 |
| Power Efficiency Improvements in AMD's Next Generation Mobile Processor (※別ウィンドウで開きます) PDF版はこちら |
まず、パワープレーンの分離から見ていこう。
AMDは、CPUへの電力供給を、複数のパワープレーンに分割して制御することで、消費電力を抑える。モバイルコアだけでなく、サーバー&デスクトップコアでも、それぞれのCPUコアとノースブリッジブロックで、パワープレーンを分割している。各ブロックのステートの変化に応じて、電力を制御する。ただし、現状では、パワープレーン毎に供給電圧を動的に変化させるような制御は行なっていない。「供給電圧はどのパワープレーンも同じ」(Hester氏)という。CPUコアの省電力化は、アクティブ時の各CPUコアの動作クロックの動的な切り替えと、アイドル時のステート切り替えに頼っている。電圧の切り替えは、各コアとノースブリッジを揃えて行なう必要がある。これは、Intelも同じだ。
電圧を変えないのは、現状ではCPUパッケージなどの対応が難しいからだという。
「(新コアは)機能的には異なるパワープレーンを備えている。しかし、今日では、各パワープレーンはパッケージレベルでは一緒にされている。だから、チップの上層レイヤーのレベルで見るなら、我々は各コア毎に(電圧の)異なる電力を供給できるが、パッケージでは、それはできない。
パッケージ技術で見ると、現状では、各パワーバスに対して個別の電力を供給できるだけの数のパワー/グランドピンの数がない。将来いつかは、もっと洗練されたパッケージによって(各パワープレーンに)個別に(異なる電圧の)電力を提供することができるようになるだろう。おそらく、サーバーに特化した製品になるだろうが」(Hester氏)
しかし、CPUに複数の異なる電圧で電力を供給しようとすると、マザーボード側に対応できるボルテージレギュレータモジュール(VRM)が必要となる。複数のVRMはコストがかさんでしまう。もっとも、将来的には、この問題を解決する手段はある。CPUパッケージに小型化したVRMを統合したり、さらにCPUのダイにVRMを統合してしまう方法だ。しかし、Hester氏はそれについては次のように答える。
「今日では、(オンチップVRMは)全然(無理)だ。シリコンサイズを考えれば、そうしたタイプのシリコン(オンチップVRM)を使う方向へは向かわないだろう。コストと消費電力の適正なトレードオフを考えると、チップ外に複数のVRMが必要となる」
●メモリコントローラとHyperTransportをモバイル設計に
AMDがモバイルコアで特に集中したのは、インターフェイス回りの省電力化だった。それは、インターフェイス部分の電力消費に、改善の余地が大きいと判断したからだという。
「我々は、CPUコア自体よりも、むしろ、ノースブリッジ部分で電力を節約できることを発見した。特にデュアルコアの場合、プロセッサは多くの時間、アイドル状態にある。アイドル時には、CPUコアの電力をできる限り下げることができる。だから、次にすることはメモリとI/Oの消費電力を下げることだった。メモリコントローラをモバイル向けに最適化し、HyperTransportリンクをよりインテリジェントにした」とHester氏は語る。
そのため、すでに説明したように、AMDはファンクションブロックのうち、メモリコントローラとHyperTransportを、モバイル向けに再設計した。Hester氏は次のように説明する。
「コアを完全に再設計する必要はなかった。ファンクションブロックのうち、いくつかの技術はサーバーコアと共有している。しかし、特定のブロックについては、モバイル向けのパワーマネージメントに完全に最適化した。大きな変化は、メモリコントローラの再設計と、HyperTransportのよりインテリジェントな制御だ。
モバイルコアのメモリコントローラは、モバイルスペース向けの新設計だ。HyperTransportについては、HyperTransport 3のコアマクロはサーバーとモバイルで共通だが、(HyperTransport 3の)コアの制御についてはモバイルスペースに特化している」
HyperTransportリンクについては、モバイルコアは、CPUコアの状態に応じたパフォーマンス制御を行なう。
「例えば、複数のタスクが同時に走っているような場合、両CPUコアはフルスピードで走り、HyperTransportもフルスピード、メモリ(コントローラ)もフルスピードで動作する。しかし、CPUコアをあまり使わない時は、CPUコア自体がスローダウンし、I/Oトラフィックが減るに従ってHyperTransportリンクもスローダウンする。具体的には、HyperTransportの外部クロックを下げて転送レートを下げる。
さらに、キーボード入力を待っているような状態の場合、両コアともにアイドル状態になる。このケースでは、I/Oトラフィックもなくなるため、HyperTransportリンクも、それ自身でアイドル状態に置き、シャットダウンする。この状態では、電力消費は、DRAMリフレッシュサイクルだけになる」(Hester氏)
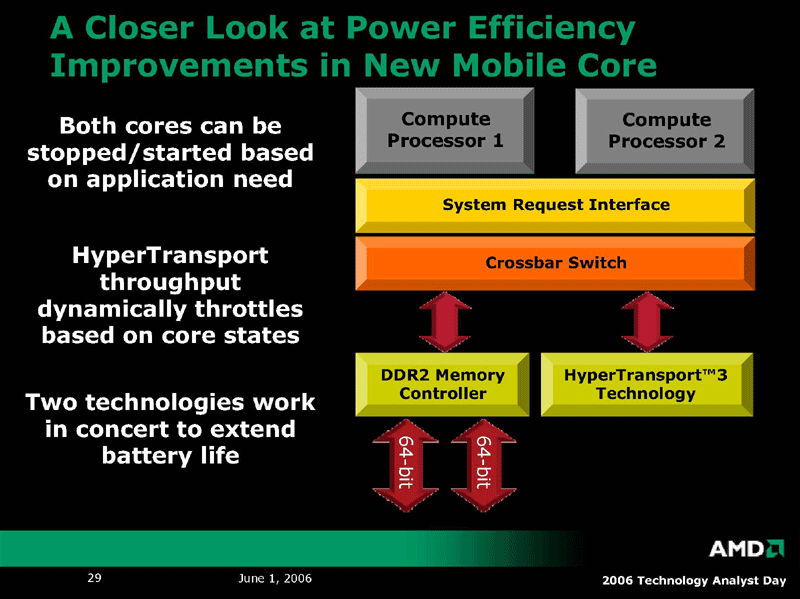 |
| A Coser Look at Power Efficiency Improvements in New Mobile Core (※別ウィンドウで開きます) PDF版はこちら |
●見えてきたAMDのモバイルコアの実像
こうして概観すると、AMDのモバイルコアの正体が見えてくる。Rev. F/G世代のデュアルコアK8をベースに、CPU設計をモジュラー化、モバイルに最適化したメモリコントローラとHyperTransport制御を加えることで省電力化を図るCPU、それがモバイルコアだ。また、ダイサイズも従来のデュアルコアK8よりコンパクトにすることで、製造コストを下げ、より低価格レンジまでカバーしやすいようにする。
しかし、省電力化については、AMDの説明を聞く限り、まだIntelのモバイル系CPUに、一日の長は残っているように見える。Intelは、Core 2では、さらにアグレッシブな省電力テクニックを使うことを説明している。例えば、Intelは「Core(Yonah:ヨナ)」世代からL2キャッシュについて、デュアルコアに最適化した非常に高度な省電力制御を行なっている。CPUコアの内部も、Core 2では基本的には各ブロックへのクロック供給がストップされた状態にあり、実行時にターンオンされる。Intelの方が、よりアグレッシブな省電力制御を行なっている。
しかし、一方では、AMDはノースブリッジ機能をCPUに取り込んでいることによる、省電力化が見込める。余計なCPU-ノースブリッジチップ間接続による電力消費がなく、また、CPUコアのステートに合わせた、ノースブリッジ機能の電力制御がしやすい。
AMDのモバイルコア対IntelのCore 2の戦いがどうなるかはまだわからない。しかし、明瞭なこともある。それは、AMDが2007年のおそらく後半となるモバイルコアまで、持たせなければならないということだ。IntelのCore 2に対して、1年後というギャップが、AMDにとっては痛い。
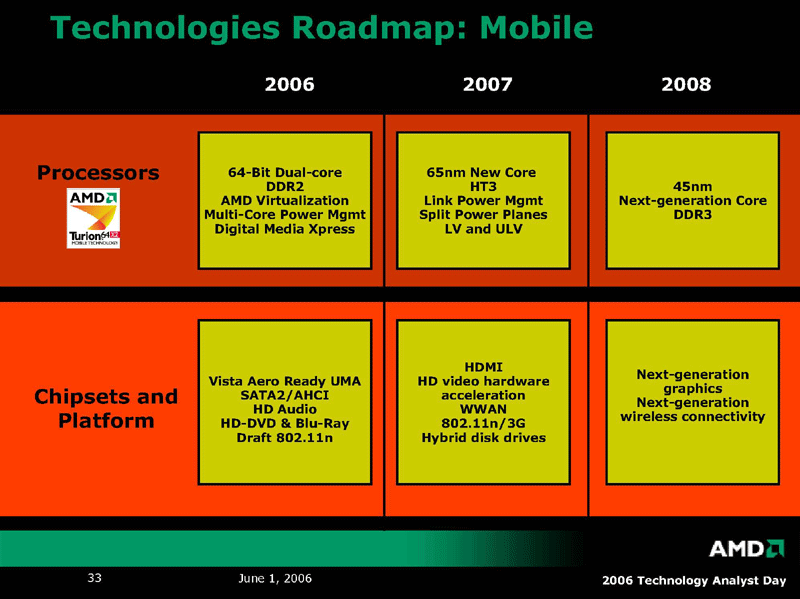 |
| Technologies Roadmap:Mobile (※別ウィンドウで開きます) PDF版はこちら |
□関連記事
【6月16日】【海外】設計のモジュラー化で市場に最適化したCPUコアを
~AMDの新戦略(1)
http://pc.watch.impress.co.jp/docs/2006/0616/kaigai282.htm
【6月1日】【海外】拡大が進むAMDのコプロセッサ構想
http://pc.watch.impress.co.jp/docs/2006/0601/kaigai275.htm
【5月31日】【海外】Rev. Fの次の次に来るAMDの次世代コア「Hound」
http://pc.watch.impress.co.jp/docs/2006/0531/kaigai273.htm
(2006年6月22日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.