 |


■後藤弘茂のWeekly海外ニュース■マルチスレッディング化が性能の重要な鍵となる新世代GPU |
●GPUの効率化のためにマルチスレッディングが必要
GPUは、ひたすらマルチスレッディングへと猛進している。マルチスレッド化することで、演算ユニットを効率的に稼働し、GPUのパフォーマンスを引き出すためだ。ATI TechnologiesはRADEON X1800(R520)系に、「Ultra-Threading(ウルトラスレッディング)」と呼ぶ非常に粒度の小さなマルチスレッディング技術を採用した。RADEON X1800のPixel Shaderでは、マルチスレッディング化によって90%以上の実行効率を達成するという。NVIDIAも、「GeForce 6800(NV40)/GeForce 7800(G70)」系では、マルチスレッディングを採用している。
GPUがマルチスレッディングへと走る理由は明瞭だ。GPU内部がプログラマブルな演算ユニットであるProgrammable Shader中心の構成になった結果、Shaderの効率化が重要なパフォーマンスの鍵となった。プログラマブルな演算ユニットは、固定機能のパイプラインと異なり、効率的に稼働させることが難しい。CPUで、演算ユニット数を増やしただけでは性能が上がらないのと同様に、GPUも、演算ユニットだけを増やしても性能が上がりにくくなる可能性が高い。演算ユニットを効率的に稼働させるために、CPUと同様にマルチスレッディングが必要になったというわけだ。しかも、GPUのソフトウェア環境は、依存性のないタスクを無数に持つため、CPUよりも、マルチスレッド化によって並列に処理がしやすい。マルチスレッディングの効用が高いわけだ。
プログラマブルプロセッサ化したGPUでは、メモリアクセスのレイテンシや命令フローの乱れがボトルネックとなる。CPU同様に、そこをスレッディングによってカバーする必要がある。特に、GPUの場合はマルチスレッディングは、レイテンシの隠蔽だけでなく、命令レベルのスケジューリングで生じるロスまでカバーしようとしている点が、CPUと大きく異なる。また、1スレッドに含まれるピクセルや頂点の数がGPUによって異なっている。これが、マルチスレッディングの効率に大きく影響する。
もっとも、GPUがマルチスレッドを求める最大の理由は、CPUと同様にメモリレイテンシの隠蔽であることは変わりがない。CPUでメモリアクセスが最大のパフォーマンスの障壁であるのと同様に、GPUでもメモリアクセスが必要となるテクスチャフェッチが最大のボトルネックとなっている。
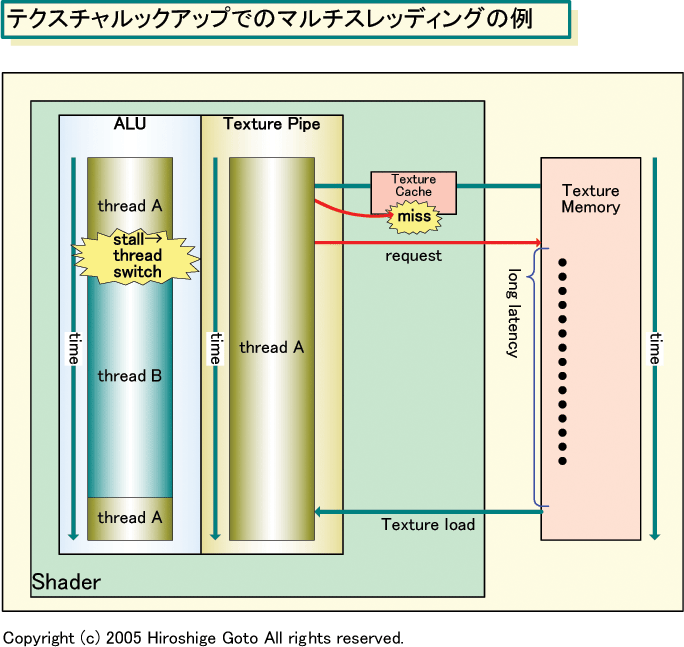
「Pixel Shaderの効率向上のカギは、レイテンシを隠蔽することとムダサイクルを避けること。Pixel Shaderでの非効率性の大きな原因の1つは、テクスチャフェッチだ。もし、Pixel Shaderがテクスチャ値を参照する必要があり、その値がテクスチャキャッシュになく、グラフィックスメモリを参照しなければならない」(ATI 「X1800 Shader Architecture Whitepaper」)。「外部メモリ参照が必要な場合、キャッシュにヒットすれば数サイクルで(データが)レディになる。しかし、キャッシュミスした場合には、(データのロードまで)最大で数百サイクルと非常に長いレイテンシとなる。ALUはその待ち時間の間、することがなくアイドル状態になってしまう。そのため、数百サイクルの間、(ALUに)他に行なわれることが必要になる」(Bob Drebin氏, Fellow, Discrete Graphics Engineering)
この問題を解決するため、R5xxでは、テクスチャフェッチでメモリアクセスが生じると、Shader ALU側のスレッドを切り替える。テクスチャデータがレディになった段階で、再びShader ALUを元のスレッドに戻す。そのため、見かけ上は、ALU側はレイテンシがなかったように、アイドル状態に陥ることなくフルに稼働し続けることができる。
 |
| Shaderでのマルチスレッディング PDF版はこちら |
●メモリアクセスが生じたらスレッドを切り替え
CPUの場合、マルチスレッディングでメモリレイテンシを隠蔽する場合も、スイッチして走らせるスレッド数自体が限られている。PCのソフトウェア環境の場合、メインで走るスレッドは1~2なので、それほど隠蔽できない。それに対して、GPUでは膨大な数のスレッドが並列しているので、いくらでも切り替えることができる。「グラフィックスではレイテンシは友だ。CPUではメモリを読みに行ったら、何もできない。GPUでは、アルゴリズムの工夫で解決できる」とDrebin氏は言う。
そのため、CPUではできるだけキャッシュで吸収して、外部メモリアクセス自体を減らそうとしている。キャッシュヒットした場合には、CPUではスレッドスイッチしない。ところが、GPUの場合には、切り替えるスレッドが豊富にあるので、キャッシュヒットした場合もマルチスレッディングする選択肢がある。
「もし、ALUの各サイクル毎にALU命令を実行したいと望むなら、キャッシュヒットした場合も、スレッドを切り替える方がいい。我々の見解は、もし、ALUに何か他にさせることがあるなら、スイッチするというものだ」とDrebin氏は説明する。
もっとも、この部分は、ATI内部でも異なる説明がある。「キャッシュヒットの場合のレイテンシは非常に小さい。だから、キャッシュヒットではスイッチしないと思う」とATIのRaja Koduri氏(Senior Architect)は語る。マルチスレッディングについては、ATIの開発者の中でさえ、説明に食い違いがある。しかし、重要なことは、GPUではそこまでアグレッシブなマルチスレッディングが可能であるという点だ。逆を言えば、アグレッシブにマルチスレッディングするから、512wayもの膨大なマルチスレッディングが必要になるわけだ。
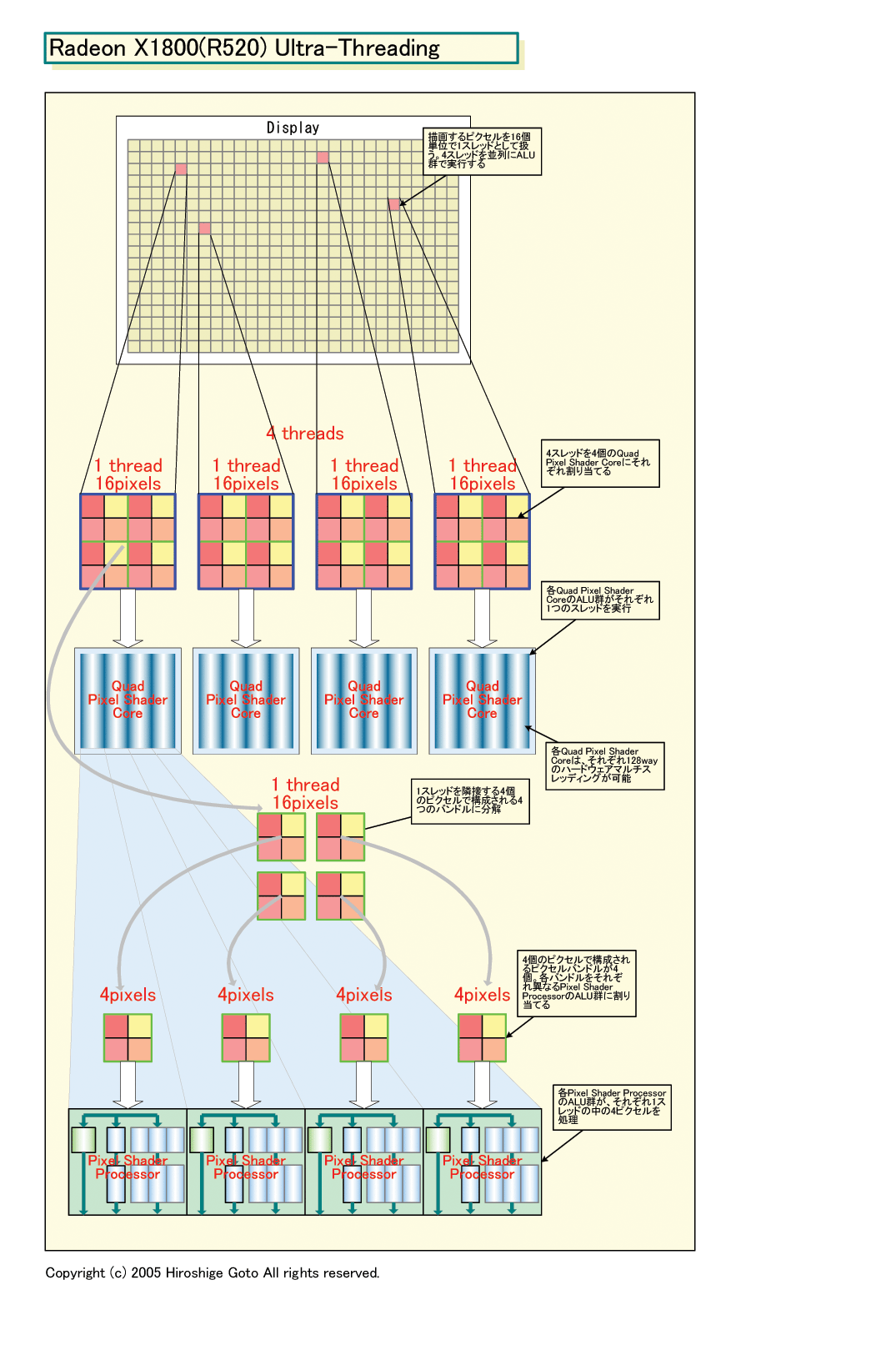
上の図では、テクスチャフェッチの間、1スレッドを切り替えているだけだが、実際には、数百サイクルの間に、ALUとテクスチャユニットが次々にスレッドを切り替えていると見られる。R520のPixel Shaderの場合、合計16個の「Pixel Shader Processor」を4個ずつバンドル、4ユニットの「Quad Pixel Shader Core」に編成している。各Quad Pixel Shader Coreユニットは、最大128スレッドをオンザフライで扱うハードウェアマルチスレッディングが可能だ。つまり、テクスチャ待ちの間に、最大127スレッドを切り替えて走らせることができる。
●Dispatch Processorがスレッドを制御
R5xxファミリーの場合、Pixel Shader Engine内での、こうしたスレッドのハンドリングは、Pixel Shader Engineに新たに設けられた「ディスパッチプロセッサ(Dispatch Processor)」が行なう。
「Dispatch Processorが(ALUの)状態を管理、1つのコアがデータ待ちや他のタスクのコンプリート待ちのためにアイドル状態になったと察知すると、迅速に、新しいスレッドをそのコアにアサインする。もし、アイドルスレッドがデータを待っているなら、データがアベイラブルになるまで一時的にサスペンドさせる」(ATI)
 |
| R5xxファミリーのUltra threading PDF版はこちら |
GPUのマルチスレッディングには、レイテンシの隠蔽の他に、動的分岐などによるShaderのムダサイクルの発生を抑える効用もある。そのため、ATIはGPUマルチスレッディングで、小さなスレッドサイズと、分岐でのスレッドスイッチを採用した。
ATIによると、GPUの非効率性のもう1つの大きな原因は動的分岐だという。動的分岐はShader Model 3.0(MicrosoftのDirectXのShaderスペックの最新版)の最も重要な新フィーチャの1つ。SM 3.0では、Pixel Shaderが演算値に応じて異なる分岐やループを実行する、動的なフロー制御を行なう命令を備える。動的分岐には、処理が必要ないピクセルに対するシェーディングをスキップできるなど、さまざまな利点がある。しかし、その一方で、伝統的なGPUの命令ストリームレベルの並列性を壊してしまう。Drebin氏は次のように説明する。
「動的フロー制御では、スレッド内のピクセルが、同じシェーダプログラム中の、異なる部分を実行する。動的フロー制御には、必要のないピクセルに、長い複雑なシェーダプログラムを走らせなくて済む、あるいは、複数の小さなシェーダ(プログラム)を1つの大きなシェーダにまとめるといった利点がある。
しかし、一方で、ネガティブインパクトもある。なぜなら、しばしばピクセルは、プロセスを(同タイミングに)合わせるために、他のピクセルを待たなければならないからだ。動的フロー制御があると、片方に条件分岐したピクセルが、もう片方の分岐を待たなければならない」
●CPUとは異なるGPUのストリーム制御
非常にわかりにくいが、GPUの基本的なストリーム制御の仕組みを知ると、ある程度は推測ができる。GPUは、汎用コンピューティングのために作られたCPUと異なり、ストリームプロセッサだ。つまり、1つのプログラムカーネルで、多数のデータ(ピクセルや頂点)に対して処理を行なうスタイルのプロセッサだ。そのため、複数のデータに対して、基本的に同じコードパスで処理を行なうことを期待していると見られる。つまり、各ピクセルが、異なるコードパスを通ることは、あまり想定しないで、制御を行なってきた。
実際、RADEON 9800(R350)の時に、ATIの技術スタッフは、R300/350系のPixel Shaderは、4ピクセルを揃えてプロセッシングする仕組みになっていると説明していた。4つのPixel Shaderバンドルに対して、4個のピクセルをディスパッチ、4ピクセルが処理を終えた段階で揃ってShaderバンドルからリタイヤさせる仕組みだという。4つのタスクを完全にインオーダで揃えて制御していたわけだ。この仕組みは、おそらくNVIDIAも同様だったと思われる。
こうした単純な制御は、各ピクセルや頂点が、動的に分岐せず、同じシェーダ(プログラム)でひたすら直線的に処理するこれまでは有効だった。どのピクセルも、基本的には同じコードパスを通るため、プロセッシングのステップが揃うからだ。Shaderのスケジューラの構造も簡略にできる利点もあった。out-of-order(命令順番を入れ替えて実行する)型CPUのように、ALUからの出力をout-of-orderで行なうと、CPUのように制御が非常に複雑になってしまうからだ。
ところが、SM 3.0になって、動的分岐が入り、タスクによってコードパスが違ってしまう可能性が出てきた。その場合、ピクセルによってプロセッシングステップ数にばらつきが発生してしまい、ロスが生じると推測される。GPUが現在抱えている問題は、こうしたケースでムダプロセスが発生してしまうことだと見られる。
●スレッドサイズと動的フロー制御の関係
この問題の解決のため、ATIは、まずスレッドサイズを小さくすることを採用した。前回説明したように、GPUでは、スレッドとしてバッチ処理するピクセル(または頂点)の数が決まっている。スレッドサイズはGPU毎に異なり、R5xx系は16ピクセル/スレッドだが、他社は4,096ピクセル/スレッドだという。
「命令フロー制御のアクセラレーションの鍵は、多数のスレッドをより賢いアルゴリズムで走らせることだ。スレッドサイズを小さくし、(分岐処理のための)専用ロジックを設ける。(スレッドサイズを小さくすることで)スレッド数が増えても問題にはならない。スレッド間には依存性がないからだ」とDrebin氏は言う。
下のスライドが、スレッドサイズと動的分岐の効率の説明の図だ。これは、シャドウマッピングのシェーダ(プログラム)で、影になっているピクセルはシャドウマッピングし、影になっていないピクセルにはしないという条件分岐を含んでいる。
 |
| スレッドサイズと動的分岐の効率 PDF版はこちら |
GPUの場合、スレッド内のピクセルが揃って同じコードパスで処理される場合に、もっとも効率がよくなる。つまり、スレッドの全ピクセルが完全に影の中か、完全に影の外の場合に、効率よくプロセッシングできる。逆に、影にかかったスレッドは、ピクセルによってコードパスが異なってしまう。そのため、効率が悪くなる。
「影から外れたピクセル群はブルー。影の中のピクセル群はグリーン、こちらはシェーダのボトムパートだけを実行する。ピンクのスレッドが問題だ。なぜなら、このスレッドの中のピクセル群は、どちらか片方(のパス)か、両方をプロセスする必要があるからだ。スレッドサイズを小さく保つと、非効率エリアが減る」(Drebin氏)
スレッドのサイズがR5xx系のように16ピクセルと小さいと、多くのスレッドは、完全に影の中か、完全に影の外になる。つまり、効率がいいスレッドとなる。影との境界領域にかかっていて、効率が悪いスレッドの数は限られる。ところが、256ピクセル程度のスレッドサイズになると、影にかかり、効率が悪いスレッドがかなり多くなる。そして、4,096ピクセルの大きなスレッドサイズになると、全部が効率の悪いスレッドになってしまうというわけだ。
●分岐の場合もALU側のスレッドを切り替え
つまり、現在のGPUではスレッドサイズを小さくすれば、それだけ動的分岐の効率が上がることになる。スレッドの粒度は、GPU毎に大きく異なり、ATIの場合はR5xxが16ピクセル/スレッド、Xbox 360 GPUが64ピクセル/スレッド。それに対してNVIDIAは4,096(4k)ピクセル/スレッドと、ずっと大きいという。
「64ピクセル/スレッドも悪くはない。Xbox 360 GPUが狙っている高解像度画面では、64ピクセルは比較的小さい数字だからだ。しかし、4kピクセルとなると、かなり問題が発生してしまうだろう」とDrebin氏は指摘する。
今後のGPUにとって、動的フロー制御は非常に重要となる。より複雑なシェーダ(プログラム)を作ることができるようになるからだ。そのため、スレッドサイズを小さくすることは、重要な鍵となると見られる。
「ゴールは、(スレッドの)サイズをできる限り小さくすることだ。それぞれのGPUアーキテクチャによって、抱えている問題の性質が異なるために、(スレッドの粒度も)異なる。しかし、鍵が、できる限り小さくすることは変わらない」(Drebin氏)
それなら、どんどんスレッドサイズを小さくしてしまえばいいかというと、そうも行かない。「スレッドの粒度を小さくすることには、トレードオフがある。より多くのリソースを必要とする」とATIのAndrew B. Thompson氏(Director, Advanced Technology Marketing)は語る。
おそらく、究極は、1ピクセル/スレッドで、その場合には、CPUと同じような柔軟性の高い制御ができるようになる。しかし、そのためにはCPUと同様の複雑な制御システムが必要で、おそらく、それはGPUにフィットしないだろう。
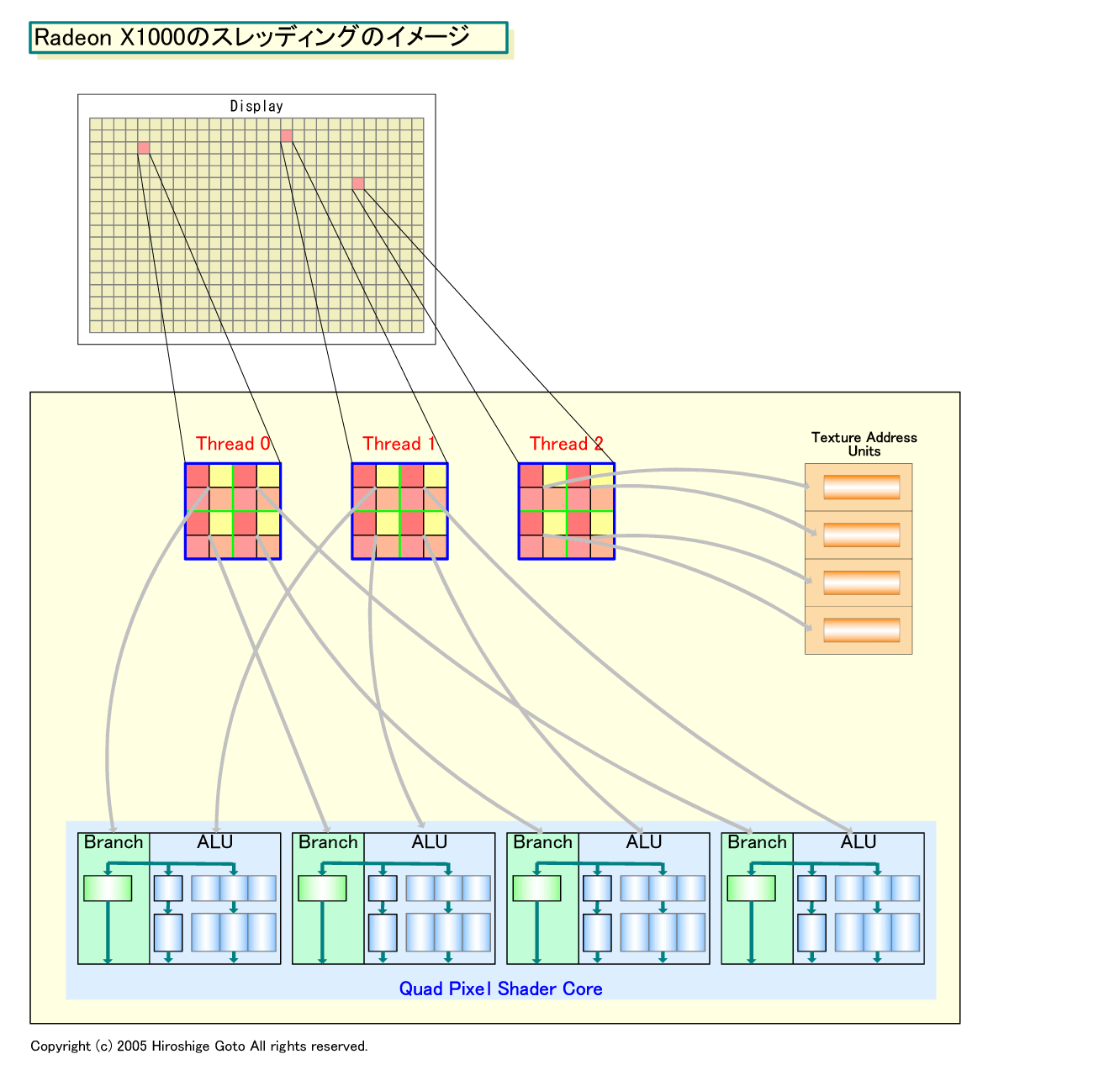
また、R5xxの場合は、分岐でもマルチスレッディングすることができる。つまり、ALUとテクスチャユニットのスレッドを分離する他に、分岐ユニットも別なスレッドを走らせることができるという。
「特定の時点を取ると、RADEON X1800では4スレッドが同時に実行されている。しかし、それはALUだけの話だ。命令フロー制御は異なるスレッドを実行できるし、テクスチャルックアップについても異なるスレッドを実行できる」とDrebin氏は言う。
つまり、ブランチプロセッシングで時間がかかる場合には、ALU側は別なスレッドの処理を進めることができるわけだ。
「我々は、他にも実行しなければならない演算が山のようにある。だから、(分岐を待っている間も)プロセッシングを続けることができる。分岐条件のための値がレディになったら、再びフロー制御に戻る。ちょうど、テクスチャ参照(でのスレッド切り替え)と同じようになる。これによって、フロー制御でのパフォーマンスペナルティがなくなる」(Drebin氏)
 |
| R520のUltra threadingのイメージ PDF版はこちら |
●膨大なレジスタの搭載はGPUのトレンド
GPUのスレッドの粒度は、GPUの内部アーキテクチャとも密接に関連している。R5xx系のアーキテクチャでは、16ピクセルのスレッドを、4個のPixel Shader Processorを含むQuad Pixel Shader Coreユニットで実行する。1個のShader Processorが4ピクセルずつ処理する形だ。ATIは、この4ピクセルパープロセッサを、最適な数と、現在は考えているようだ。Xbox 360 GPUも同様のアプローチを取るからだ。
「Xbox 360 GPUでは、64ピクセル(または頂点)を16 Shader ALUバンクで実行する。ちょうど4倍で割り切れる数で、RADEON X1800と同じだ。(スレッディングに対する)基本的な考え方は似ている」(Drebin氏)
マルチスレッド化のトレードオフの1つは、もちろんレジスタだ。動的にスレッドをゼロレイテンシで切り替えるためには、各スレッドの各ピクセル毎のテンポラリ値であるコンテクストを保持する必要がある。R5xxでは、膨大な数の物理レジスタを搭載、レジスタをマッピングすることで、低コストなスレッド切り替えを実現している。
ちなみに、Xbox 360 GPUは最大94スレッドをオンザフライで制御(頂点スレッドが31、ピクセルスレッドが63)し、そのために24,576本のベクタレジスタを備える。GPUダイ(半導体本体)のかなりの面積がレジスタで占められている。
「これは最先端のGPUでは普通のことだ。膨大なレジスタが必要で、そのためにダイを割く必要がある」とDrebin氏は語る。
レジスタの塊へと、マルチスレッド自体のGPUは変化しつつある。今後も、この傾向はますます強まるだろう。近い将来には、数千スレッドをハンドルするGPUが登場するかもしれない。
□関連記事
【10月17日】【海外】RADEON X1800(R520)アーキテクチャの鍵“Ultra-Threading”
http://pc.watch.impress.co.jp/docs/2005/1017/kaigai217.htm
【10月7日】【海外】メモリ効率向上にフォーカスしたR520アーキテクチャ
http://pc.watch.impress.co.jp/docs/2005/1007/kaigai216.htm
【10月6日】【海外】R520ことATIの新GPU「RADEON X1800」の登場
http://pc.watch.impress.co.jp/docs/2005/1006/kaigai215.htm
【10月6日】【多和田】新世代アーキテクチャを採用したATI「RADEON X1800」
http://pc.watch.impress.co.jp/docs/2005/1006/tawada62.htm
(2005年10月24日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.