 |


■後藤弘茂のWeekly海外ニュース■R520ことATIの新GPU「RADEON X1800」の登場 |
●Shader Model 3.0に対応し仕様を拡張
ATI Technologiesの新アーキテクチャGPU「RADEON X1800(R520)」がついに登場した。
以前、このコーナーではR520世代から、統合型Programmable Shader(GPUのプログラマブル演算ユニット)アーキテクチャになると予測したが、それは間違いだった。R520は、従来型のIndependent Shaderアーキテクチャ(頂点処理のVertex Shaderとピクセル処理のPixel Shaderに分離されている)を取る。Unified-Shaderへと移るのは次の「R600」世代になりそうだ。
理由は明瞭で、Unified-Shader型マイクロアーキテクチャが効果を発揮するのは、DirectX 10以降のAPIセットだからだという。DirectX 10では、API上では論理Shaderが統合されUnified-Shaderになる。同じ命令セット、同じフィーチャが各Shaderで共通に使えるようになる。また、Vertex/Geometry Shaderから、メモリにデータの書き込みができる「ストリームアウト」が加わる(現行のGPUはVertex Shaderからメモリに書き出しができない)。こうした機能を実装しようとすると、ハードウェア側もUnified-Shaderにするのが自然な流れとなる。しかし、それまでは現行のIndependent Shader型が適していると判断したという。
R520の論理アーキテクチャ上の最大の革新はMicrosoftの「DirectX 9」のシェーダスペック「Shader Model 3.0(SM 3.0)」に対応した点。従来のATI GPUはShader Model 2世代だったが、R520でSM 3.0をいち早くサポートしたNVIDIAに追いつくことになる。SM 3.0サポートでの大きな変化は、Shaderでの動的フロー制御命令(条件分岐)のサポートと、Pixel Shaderの内部演算精度の32bit化(4wayベクタで128bit)。これによって、ATI GPUでも、Shaderを使って汎用コンピューティングを行なうGPGPUが容易になる。
また、最先端の90nmプロセス(TSMC)で製造することで高クロック化も達成する。フラッグシップのRADEON X1800 XTでは標準で625MHzをサポートする。周波数で、NVIDIA系に差をつける戦略だ。また、ATIの新ビデオ技術プラットフォーム「AVIVO」に対応し、デュアルビデオカードソリューション「CrossFire」もサポートする。
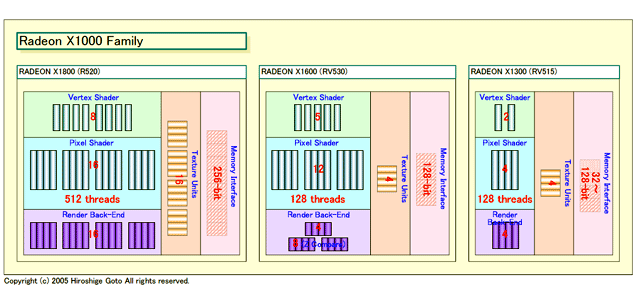 |
| Radeon X1000 Family構成比較図 PDF版はこちら |
●GPUの効率性の向上にフォーカスしたアーキテクチャ
R520全体の構造は、Vertex Shaderが8、Pixel Shaderが16、レンダーバックエンド(固定レンダリング機能)が16。従来的な言い方をすれば、16パイプラインGPUだ。そのため、16パイプだった前世代のRADEON X800(R420)系から、SM 3.0になった以外は、見かけ上大きく変わっていないように見える。NVIDIAが「GeForce 6800(NV40)」から「GeForce 7800 GTX(G70)」で、Pixel Shader数を16から24へと一気に引き上げたことと比べると、マイナーな変化に見える。しかし、実際には、スペック上見えにくい部分でアーキテクチャが大きく革新されている。特に、プロセッサとしての効率性の向上のための改良が目立つ。
「新アーキテクチャでは、効率性(efficiency)にフォーカスした。(Shaderの)アイドルタイムを減らし、メモリアクセス管理を大きく向上させた」とR520の開発を担当したBob Drebin氏(Fellow, Discrete Graphics Engineering)は総括する。
ATIで、テクノロジマーケティングを担当するAndrew B. Thompson氏(Director, Advanced Technology Marketing)も、G70と比較したR520の設計を次のように説明する。
「演算ユニットは比較的トランジスタ数が少ないため、(G70のように)増やすのは簡単だ。しかし、GPU全体を効率的に走らせるようにすることは難しい。我々は、今回、GPUを常にフルに走らせる効率性の部分に力を注いだ」
R520は、ユニット数を増やすより、ユニットの効率を高めることにフォーカスした設計ということだ。マーケティング上は、数字に現れにくいため、うまい戦略ではないが、ハイエンドGPUはリアルパフォーマンスが重要なので、これで行けると判断したのだろう。特に目立つのは、マルチスレッディング機能の向上とメモリコントローラ回りの改良だ。
R520のPixel Shader Engineは、合計で512スレッドをオンザフライで制御できる。CPU的な言い方をするなら、512wayのハードウェアマルチスレッディング機能を備える。膨大な規模のマルチスレッド化だ。ワイドなマルチスレッディング化によって、R520ではメモリレイテンシを隠蔽し、Shaderプロセッサを常に効率的に走らせ続けることができる。
メモリコントローラでは、DRAMコントローラを従来の64bit/チャネルから32bit/チャネルに細粒化。メモリアクセスの粒度を下げた。さらに、8個のDRAMコントローラを4個のユニット(リングストップ)に接続、各リングストップ間をリングバスで接続する。
メモリにアクセスするクライアントユニット(レンダーバックエンドなど)は、それぞれ4個のリングストップに直結される。メモリコントローラは、クライアントからのアクセス要求を受け取ると、DRAMからデータを読み出し、リングバスを経由してクライアントが接続されているリングストップへと転送する。この構造の利点は、複雑なクロスバースイッチを削減し、メモリコントローラをより低消費電力で効率的なものにすることにある。
これら、R520独自の効率性のフィーチャについては、次の記事で詳説したい。
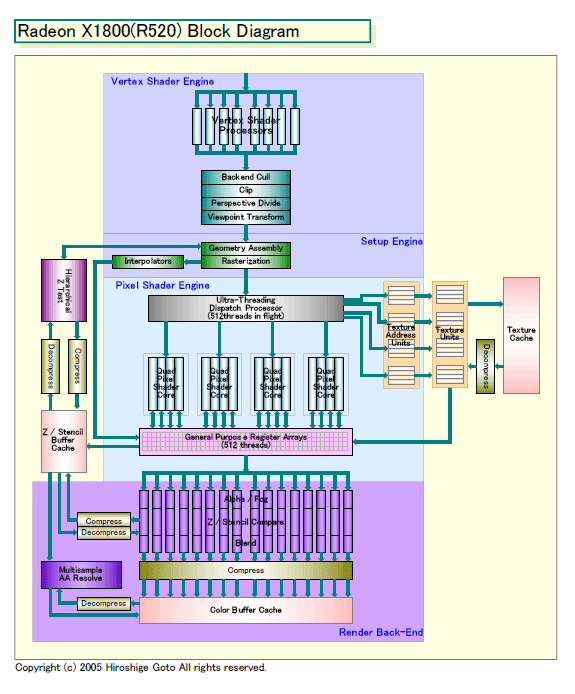 |
| Radeon X1800(R520)ブロックダイアグラム PDF版はこちら |
●NVIDIAと異なるVertex Shaderのフィーチャ
R520のVertex Shaderは、ユニット数こそRADEON X800の6個から8個へと増やされたものの、機能の拡張は小さい。32bitデータ4個を同時に処理できる4wayベクタ演算ユニットが1ユニット、32bitデータ1個を処理するスカラ演算ユニットが1ユニットの構成。両ユニットに対して同時に命令を発行できる。SM 3.0に対応したことで、動的な命令フロー制御が可能になった。また、頂点データを再利用するバーテックスインスタンシングも実装、物理レジスタも拡張されている。
NVIDIAのNV40/G70のVertex Shaderは、テクスチャメモリにアクセスするバーテックステクスチャフェッチ機能をサポートする。ATIは、今回、この機能には対応しなかった。バーテックステクスチャフェッチは、頂点データを変成してさまざまな形状を生成するディスプレイスメントマッピングなどに使うことができる。ATIのDrebin氏は、Vertex Shaderのテクスチャフェッチは要求機能ではなく、メモリアクセスを持つPixel Shader側で頂点プロセッシングを行なう(Render to Vertex Buffer)によって対応できると説明する。ただし、その場合はパフォーマンスペナルティがある。
GPU全体のアーキテクチャを考えると、ATIがこの機能を省いた理由は明瞭だ。テクスチャフェッチのためには、Vertex Shaderにもテクスチャユニットを実装し、テクスチャキャッシュとメモリコントローラへのパスを作る必要がある。テクスチャユニットは、フィルタリングまで含めると膨大なトランジスタが必要となるため、フル機能で実装することは難しい。ATIは、使えるトランジスタ数を考えると、プログラマ側が使いやすい性能でバーテックステクスチャフェッチを実現するのは難しいと判断したという。
また、テクスチャメモリへのアクセスはレイテンシが長い。そのため、実装すると、Vertex Shaderがメモリアクセスの度にストールしてしまい、性能が著しく下がってしまう。NVIDIAの場合は、この問題を解決するためにVertex Shaderにも、マルチスレッディング機能を実装している。ハードウェアマルチスレッディングのためには、余計な物理レジスタファイルの実装が必要となり、これもコストが高い。
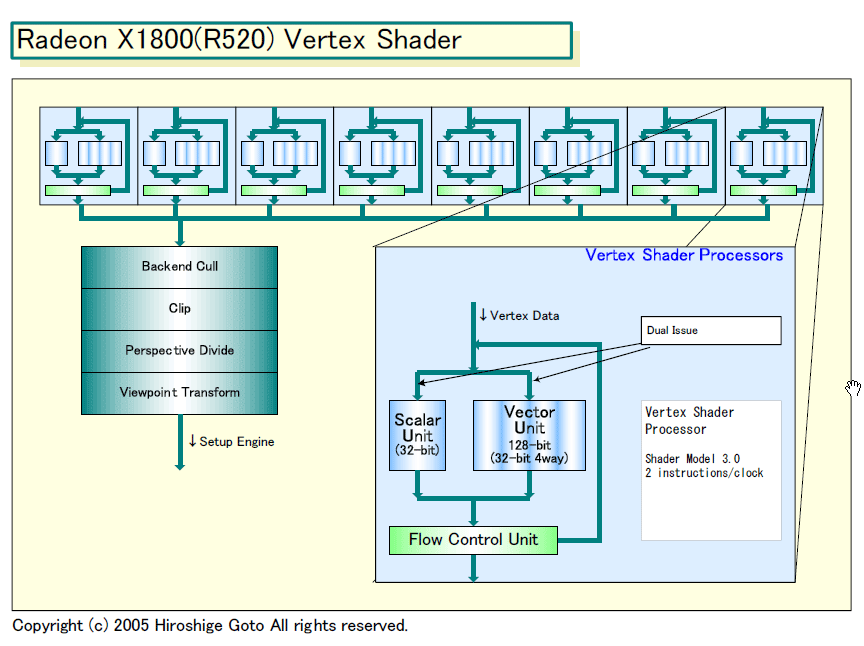 |
| Radeon X1800(R520)バーテックスシェーダー構成図 PDF版はこちら |
●最大6命令発行のPixel Shader
R520のPixel Shaderは、SM 3.0に対応したことで内部演算精度が24bitから32bitになった。また、ブランチユニットが加わり、動的な命令フロー制御をサポートできるようになった。Vertex Shaderと同様に条件分岐が可能になったため、複雑なシェーダプログラムを作ることができるようになった。また、ブランチユニットは完全に独立しており、分岐パスと並列にブランチ処理ができる。これも、GPUの効率化に寄与するアーキテクチャだ。
Pixel Shader内部は、複数の演算を並列化できる構造となっている。内部に32bit 3wayのSIMD演算ユニットを2個、32bitスカラ演算ユニットを2個搭載する。4wayのSIMD演算を行なう場合は、SIMDとスカラの両演算ユニットを組み合わせて行なう。ALU 1は加算(+インプットモディファイヤ)、ALU 2は積和算/加算/積算が可能だ。また、概念上はPixel Shader processorから分離されたテクスチャユニットがある。R520ではPixel Shaderとテクスチャユニットが同数備えられている。
これら演算ユニットは、それぞれ並列に動作ができる。そのため、最大ではピクセルシェーディングで、3way SIMDの加算、スカラの加算、3way SIMDの積和算、スカラの積和算、ブランチ、テクスチャの6命令を発行/実行できる。ただし、CPUのようにアウトオブオーダ型のハードウェアスケジューリングを行なうわけではないので、並列化は依存性のない場合に限られると見られる。
類似の構造を取るG70のPixel Shaderは、2つの4way SIMDユニットとmini ALUと呼ぶスカラユニットがそれぞれ積和算ができる。しかし、G70ではShaderの片方がテクスチャユニットとリソースを共有している。テクスチャユニットが分離したR520とは異なる。ただし、R520のテクスチャユニットは、FPテクスチャの場合はMIPマップはできるがフィルタリングができない。そのため、FPテクスチャのフィルタリングは、Pixel Shader側で行なう仕組みとなっている。R520も、Shaderリソースを、完全にフリーに演算だけに使えるわけではない。
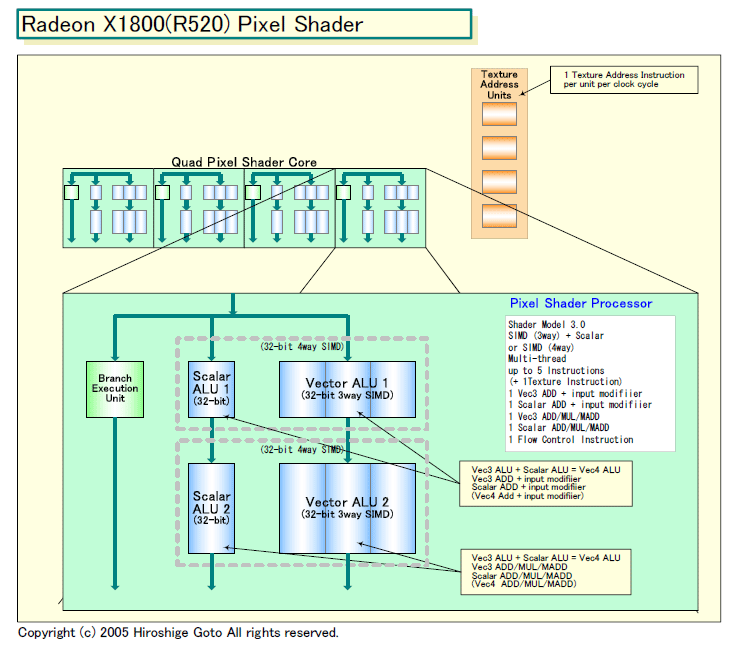 |
| Radeon X1800(R520)ピクセルシェーダー構成図 PDF版はこちら |
●イレギュラーな構成のミッドレンジ向けGPU「RV530」
今回、ATIが発表したRADEON X1000ブランドのファミリは、全部で3GPU、7SKU(Stock Keeping Unit=商品)。GPUはハイエンド向けのRADEON X1800の他に、ミッドレンジ向けの「RADEON X1600(RV530)」、メインストリーム&バリュー向けの「RADEON X1300(RV515)」。それぞれダイ(半導体本体)が異なるという。
GPUベンダーの場合、一種類のダイから、パイプラインやShaderの構成が異なる複数のGPUを派生させることがある。パイプやShaderの一部をディセーブルすることで派生品(derivative)を作る。しかし、今回は3GPUとも異なるダイだという。
面白いのは、各GPUのShaderと他のユニットのバランス。ハイエンドのR520は、Vertex Shaderが8、Pixel Shaderとテクスチャユニット、レンダーバックエンドがいずれも16。すっきりと揃ったバランスのいい構成となっている。
これはローエンドのRV515も同様で、Vertex Shaderが2、Pixel Shader、テクスチャユニット、レンダーバックエンドがいずれも4と、ちょうどR520を1/4にした構成となっている。
それに対して、RV530はShader数だけが多い。Pixel Shaderは12、Vertex Shaderは5と、R520の半分ではなく3/4程度の構成。ところが、テクスチャユニットとレンダーバックエンドは4(ただしZコンペアは8)と、逆に下位モデルのRV515に近い構成となっている。通例から考えれば、Vertex Shader 4、Pixel Shader/テクスチャ/レンダーバックエンドが8というのが論理的な構成だが、そうなっていない。シェーダプロセッシングに特化した構成となっている。
ソフトウェア側のShaderへの負担が増えている現状を反映した構成だというが、比較的チープな演算ユニットを増やして、他を抑えたと考えることもできる。トランジスタ数的にも、R520が320M(3億2,000万)なのに対して、RV530は半分の157M(1億5,700万)、RV515はさらに少ない120M(1億2,000万)となっている。もちろん、RV530からさらに、8Shaderの派生品が出てくる可能性もある。
この他、3GPUで、マルチスレッディング機能にも違いがある点も重要だ。R520と他のGPUでは、オンザフライで制御するスレッド数が4倍も違う。RV530は、マルチスレッド化によるShaderの効率化では、やや不利ということになる。スレッディングは、Shaderプロセッサのコンテクストの多重化を必要とするため非常にコストが高い。
●よりアグレッシブになったATIのGPU戦略
ATIは、過去1~2年で微妙に製品の基本戦略を変更して来た。特に今回のRADEON X1000シリーズで目立つのは、プロセス技術と製品戦略。
従来、ATIは、新プロセス技術の採用にそれほどアグレッシブではなかった。常に先端プロセスを追っていたNVIDIAより、1フェイズ遅れて新プロセスを使うのが通例だった。新プロセス技術を最初に使う時は、比較的枯れたアーキテクチャを載せ、逆に新アーキテクチャを載せる時は、成熟したプロセス技術を選択した。リスキーな新プロセスに対しては慎重に構え、安全パイを選ぶのがATIのポリシーだった。
しかし、ATIは110nmあたりから戦略を転換、NVIDIAに先んじて採用した。さらに、今回90nmでも先行した。
「130nmまでは、ATIはプロセステクノロジのリーダではなかった。しかし、我々は戦略を変えた。ATIの製品に最高の技術を採用することにし、110nmでは最初に採用した。今回、90nmでも最初に採用し、さらにトップツーボトムで全製品ファミリを90nmにした。その結果、より高い動作周波数による高パフォーマンスと、より小さなダイ(半導体本体)を達成できた」とATI Technologiesでデスクトップビジネスを統括するRich Heye(リッチ・ハイ)氏(Vice President & General Manager, Desktop Business Unit)は語る。
プロセスを微細化すると、高クロック化と低コスト化が容易になる。ハイエンドのRADEON X1800 XTで、625MHzの高クロックを達成できた。前プロセス世代の130nmと比べると、約1.2倍の高クロック化ができたのは90nmプロセスのおかげだ。その逆にトランジスタ数はR520で320M(3億2,000万)と、130nm世代より倍増した。ミッドレンジ以下のRV530とRV515は、小さなダイサイズ(=低コスト)を保つことができたと見られる。
製品戦略も大きく変わった。従来、ATIは、ハイエンドGPUとミッドレンジGPUには新アーキテクチャを投入するが、メインストリーム&バリューGPUには従来アーキテクチャ製品を持ってきていた。しかし、今回は、前述した通り、一気に全ラインに新アーキテクチャGPUを投入する。従来は、新アーキテクチャが上級ブランドから1年以上かけて徐々にボトムまで浸透する「ウォータフォール」戦略だった。
これは、NVIDIAの戦略変化に追従したと見ることもできる。NVIDIAも以前はウォータフォール型だったが、GeForce FXファミリからは、トップツーボトムで比較的短期間に全製品ラインに新アーキテクチャを導入する戦略へと切り替えた。
NVIDIAの狙いは、新アーキテクチャGPUのインストールベースを一気に拡大することで、ソフトウェアデベロッパが新アーキテクチャに迅速に対応するように促すことにあった。現在のGPUは、Shaderアーキテクチャが毎世代進化するため、シェーダプログラムがアーキテクチャ世代で変わってしまう。自社アーキテクチャへのプログラムの最適化を進めさせるには、新アーキテクチャをできるだけ速く浸透させる必要がある。
ATIも、今回はハイエンドからバリューまでアーキテクチャを揃えたことで、このベネフィットを受けることができる。3GPUは、いずれもフィーチャは全く同じで、Shaderの内部構造も同じ。異なるのはユニット数とパフォーマンスだけとなる。
効率性にフォーカスしプロセッサとしての性能向上を図ったATIのR520。R520から見えるのは、GPUもCPUと同様に、効率性を最重視するフェイズに入り始めたことだ。
 |
 |
| デモンストレーション画面1,2 パルテノン宮殿のデモ「Parthenon」。90Mポリゴンのデータセットを、Vertex Shaderを使った独自のLOD(Level of Detail)技法で描画可能なレベルに落とし込んでいる。ポリゴンモデル上で色が異なるのがLODのレベル差を示している |
|
 |
 |
| デモンストレーション画面3 RadeonのキャラクタRubyのデモも新ストーリーに。圧縮済みのムービーはこちら(約71MB) |
デモンストレーション画面4 リアルな雨を表現した「Toy Shop」のデモ。デモ中では700以上のシェーダ(GPUプログラム)が使われている。ガラス窓の上をしたたる水滴は、GPU上での水滴シミュレーションで表現している。圧縮済みのムービーはこちら(約90MB) |
□関連記事
【10月6日】【多和田】新世代アーキテクチャを採用したATI「RADEON X1800」
http://pc.watch.impress.co.jp/docs/2005/1006/tawada62.htm
(2005年10月6日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.