 |


■後藤弘茂のWeekly海外ニュース■メモリ効率向上にフォーカスしたR520アーキテクチャ |
●GPUの成功のカギはメモリの効率化
「グラフィックスの多くはメモリ効率だ。メモリを高効率に保つことが、成功へのカギとなる」
ATI TechnologiesでRADEON X1800(R520)の開発を担当したBob Drebin氏(Fellow, Discrete Graphics Engineering)はメモリの重要性を強調する。R520では、GPU性能の向上のために、メモリ回りの拡張にフォーカスした。GPU内の演算リソースの性能が向上すると、演算リソースに対してデータをフィード(あるいはバック)するために、メモリアクセスの必要が増えるからだ。演算ユニットであるProgrammable Shaderを拡張するなら、メモリにフォーカスすることは当然の流れとなる。逆を言えば、メモリが十分に効率化されていないと、演算リソースがフルパフォーマンスを発揮できないことになる。
スペック表には現れにくい、R520のメモリ回り拡張点を整理すると、次のようになる。
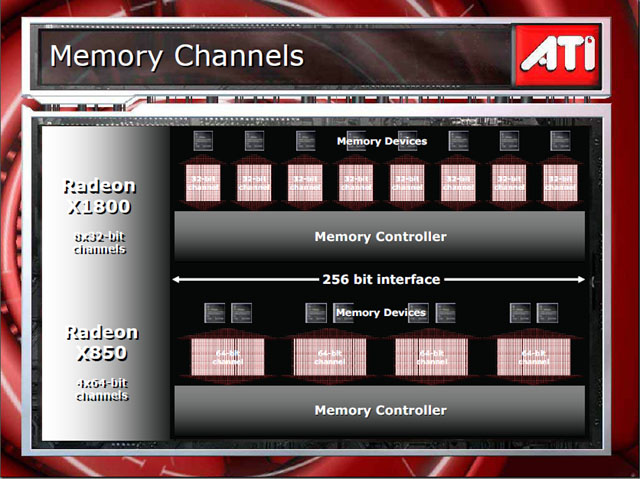
(1)DRAMコントローラを1チャネル32bit幅に細分化
(2)DRAMからのデータ転送をリングバスで効率化
(3)DRAMアクセスの調停をインテリジェント化
(4)キャッシュをフルアソシエイティブ化
この中でも重要なのはリングバスによる、データ転送の改良だ。クロスバースイッチからリングバスなどへの移行は、バスに接続するデバイスが増えると自然な流れだ。例えば、Cellプロセッサも、9個のCPUコアとメモリインターフェイス、I/Oバス間をリングバスで接続している。デバイスが増えるにつれて、複雑性が劇的に増すクロスバーより、リングバスの方が利点が増すからだ。
●1チャネルが32bitのDRAMコントローラ
 |
| Memory Channels |
R520では、まずDRAMコントローラ自体の構成が変わった。
R420までは、ATI GPUのDRAMコントローラは1チャネルが64bit幅で構成されていた。x32のDRAMチップなら2個が1チャネルに載っていたわけだ。それに対して、R520ではDRAMコントローラは1チャネル32bitになった。より細分化したアクセスが可能になったことになる。これにはいくつかの意味がある。
ひとつはデータフェッチの粒度を下げること。現在のDRAMメモリは、DRAMセルアレイからのデータフェッチ幅を広げることで、インターフェイスの高速化に対応している。DDRでは1サイクルで2n個のデータをフェッチしていたのが、GDDR2以降は4n個のデータをフェッチしている。その分、データの粒度は上がっている。チャネルを細分化することは、それを相殺して粒度を下げる効果があると推測される。DRAMコントローラの設計にもよるが、原理的には粒度を下げれば、データアクセスの中の無駄を低減できる。メモリ帯域を、より効果的に使うことができるようになる。
また、1チャネル32bitとなると、ビデオメモリをx32 DRAMチップ1個で構成するローコストコンフィギュレーションも可能になる。つまり、OEM側の低コスト化要求に応えやすくなる。DRAMチップの容量はそこそこ順調に増え続けているため、チップ数を減らしたいというニーズは強まっている。
●DRAMからのデータ転送はリングバスで行なう
 |
| Ring Bus Memory Controller |
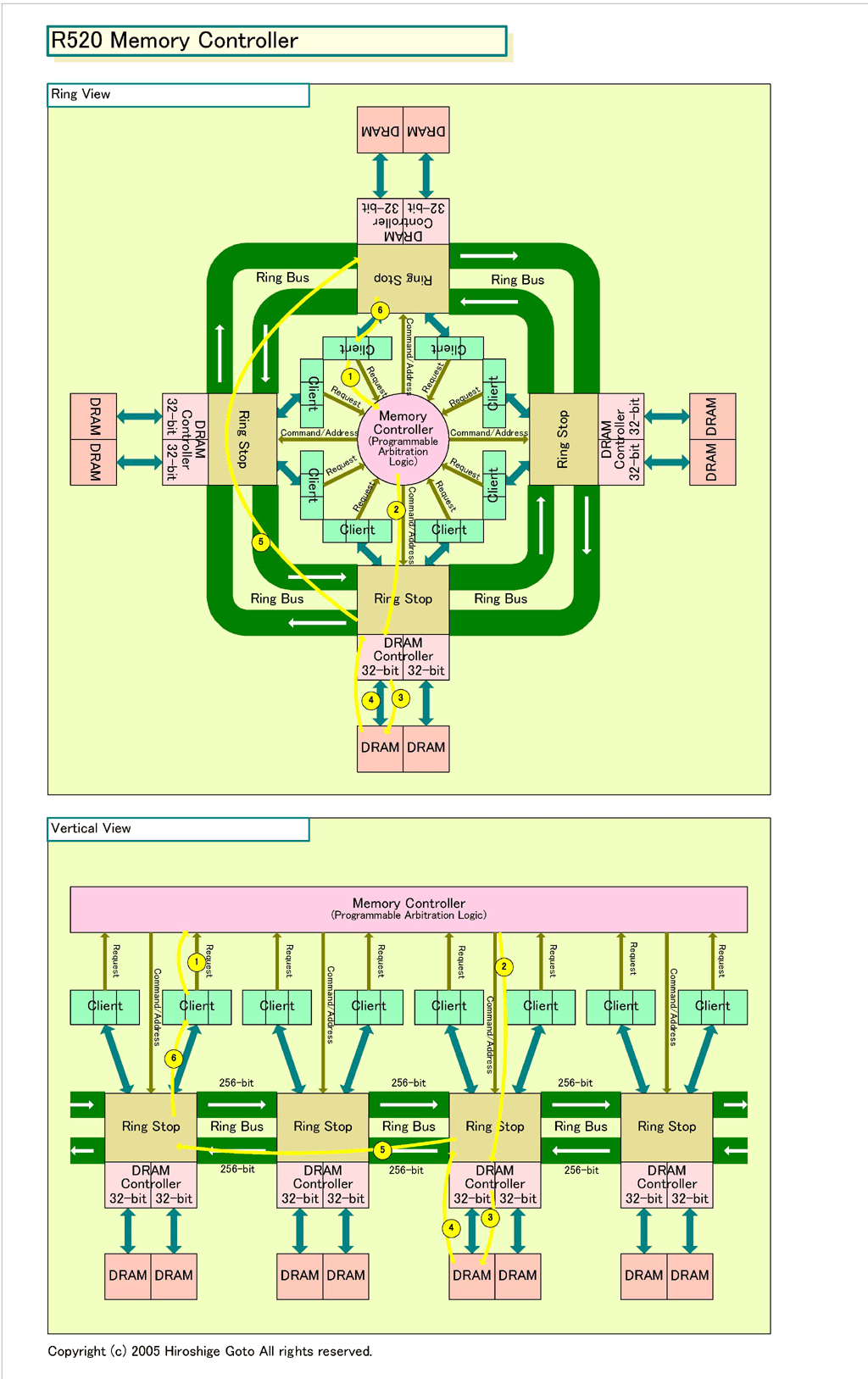
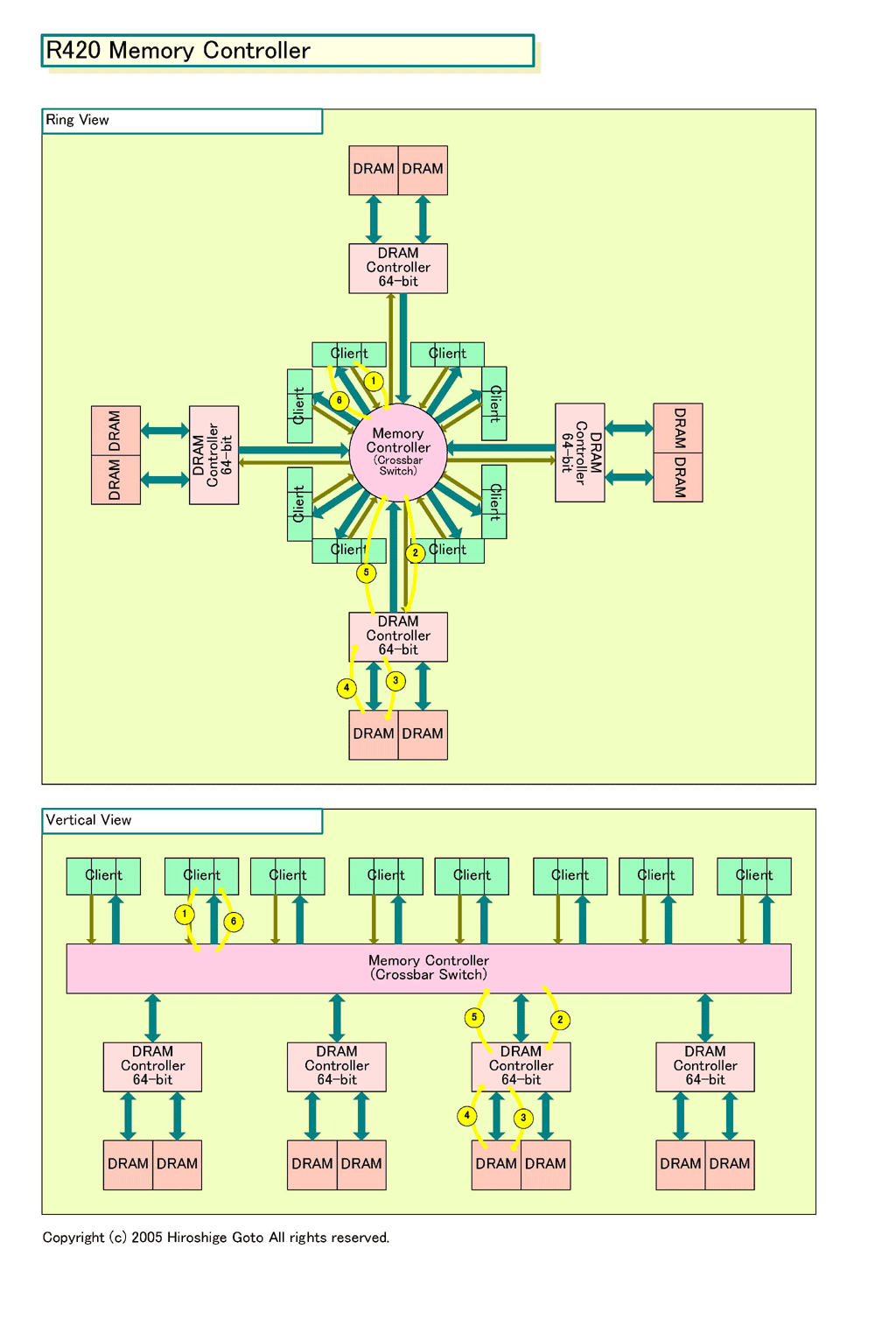
ATIは、今回R520のメモリアーキテクチャを、リング型のアーキテクチャ概念図を使って説明している。しかし、この図だと、従来のブロック図とかけ離れているため、ややわかりにくい。そこで、R520とR420の両方について、通常のバーチカル型の概念図を作り、並べてみた。それぞれの図の「Ring View」と「Vertical View」は、同じものを、別な視点から描いたものだ。
 |
 |
| R520 Memory Controller PDF版はこちら |
R420 Memory Controller PDF版はこちら |
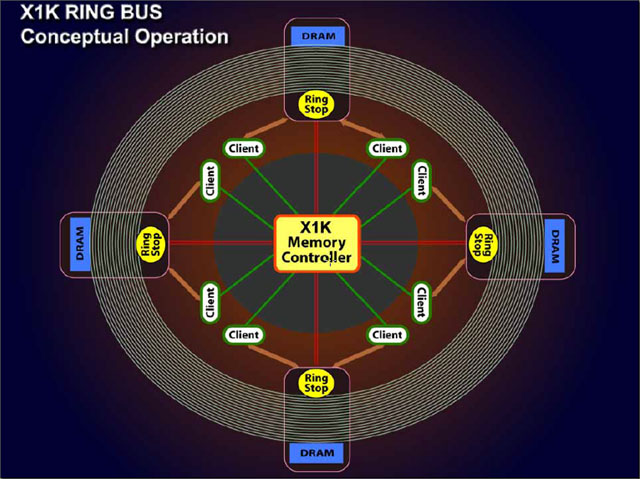
R520で新たに加わった「リングバス(Ring Bus)」は、4個のノード「リングストップ(Ring Stop)」をこのバスで接続している。リングストップには、それぞれ32bit/チャネルのDRAMコントローラが、2ユニットずつペアで接続されている。
リングバスは、片方向バスで外回りと内回りがペアとなってぐるりと循環する山手線型。片方向256bitで、双方向で512bit幅となる。リングストップからリングストップへのデータ転送では、2つのリングから最短のパスを選んで転送する。これは、通常のリング型バスと同じだ。
GPU中でメモリにアクセスする必要がある「クライアント(Client)」ユニットは、Zバッファユニットやテクスチャユニットなど多数存在する。ハイエンドGPUでは、クライアントが32ユニットにもなるという。これらメモリクライアントは、4つのリングストップとメモリコントローラの双方に接続されている。リングストップ-クライアント間はデータバス、クライアント-メモリコントローラ間はコマンドバスだ。DRAMからのデータは、メモリコントローラの制御で、リングバスを経由してクライアントに転送される。
「データは、リングバス上で転送される。決してメモリコントローラは経由しない。メモリコントローラは、(DRAMコントローラに対して)アドレスを発行し、(DRAMからのデータは)特定のリングストップへ転送させるだけだ」とATIのDaniel Taranovsky氏(Product Manager, Discrete Desktop Graphics Group)は語る。
では、具体的にどんな仕組みになっているのだろう。クライアントがメモリ上のデータが欲しい場合、(1)まず、メモリコントローラにリクエストを出す。(2)メモリコントローラはどのDRAMにデータがあるかをチェック、リングストップに接続されているDRAMコントローラにアドレスを転送する。(3)DRAMコントローラはDRAMにアクセス、(4)DRAMからのデータをリングストップを経由して、(5)リクエストを出したクライアントが接続されているリングストップへと転送する。(6)クライアントはリングストップからデータを転送される。
R520では、このようにメモリコントローラは、メモリアクセスリクエストを管理し、DRAMコントローラの制御とリングバスの転送をコントロールする。
これを、従来のR4xx系のメモリアーキテクチャと比べてみよう。R420では4つのDRAMコントローラ(64bit)がメモリコントローラに接続されていた。ATIによると、R420では、全てのメモリクライアントは、メモリコントローラに接続されている。メモリコントローラの実態はクロスバースイッチだ。
(1)クライアントからのメモリアクセス要求が来ると、(2)メモリコントローラは、該当のデータが格納されているDRAMを特定、そのDRAMが接続されているDRAMコントローラにアクセスする。(3)DRAMコントローラはDRAMにアクセス、(4)データをDRAMから読み出す。(5)DRAMコントローラはデータをメモリコントローラに転送、(6)メモリコントローラはデータをクライアントに転送する。
●メモリコントローラの複雑性を軽減
R420のスタイルでは、全てのデータは中央化されたメモリコントローラを経由することになる。それに対してR520のリングバスでは、データはメモリコントローラを経由することなく、リングバス経由でデリバーされる。クロスバースイッチによる集中化を避けることができる。
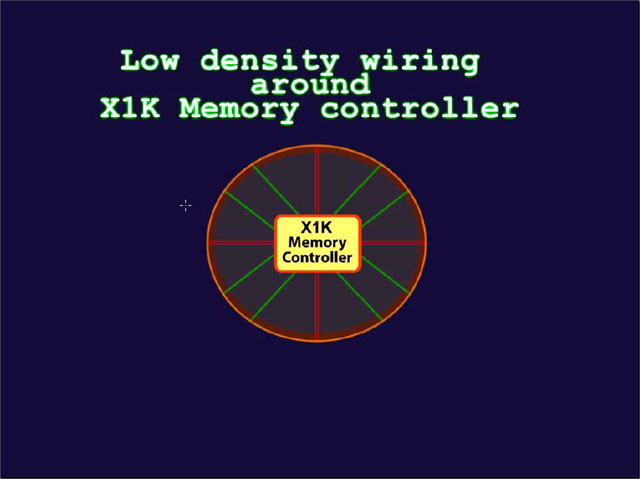
従来スタイル(クロスバースイッチ)の問題は、メモリコントローラ回りの配線が異常に複雑で高密度になり、その結果、消費電力と発熱が増大してしまう点だとATIは指摘する。R420系ではメモリコントローラの周辺は、何千もの配線が絡み合い、数十個のメモリクライアントとDRAMコントローラをスイッチングしている。高密度の配線とスイッチは、膨大な電力を消費してしまう。
通常、チップの動作周波数のリミットとなるのは、ホットスポットと呼ばれる、チップ上で最も発熱の多いエリアの熱だ。GPUの場合はメモリコントローラがホットスポットで、GPUクロック向上の障害になっているという。CPUも同様だが、ホットスポットを分散できれば、クロックを上げやすくなる。
R520スタイルのリングバスアーキテクチャでは、メモリコントローラにはデータは集中しない。コマンドバスをクロスバースイッチで結ぶだけだ。そのため、メモリコントローラ回りの配線はずっとシンプルになり、ホットスポット化を避けられる。実際に、R520では600MHz以上のクロックを達成している。
 |
 |
| 従来のクロスバースイッチ式アーキテクチャー | |
 |
 |
| R520で採用されたリングバスアーキテクチャー | |
●将来のメモリ高速化への対応も容易に
また、リングバスの採用は、GPUの今後の複雑化とメモリの高速化への対応も容易にするという。現在、問題なのは、外部DRAMの転送レートがどんどん高くなり、GPU内部ユニット数もどんどん増えていることだ。
以前は、DRAMの転送レートはGPUの内部コアクロックとさほど変わらなかった。しかし、現在のハイエンドGPUのメモリ転送レートは、コアクロックの2倍以上になっている。「メモリをチップコアよりも速くしたいと思ったら、配線をさらに増やすか、ロジックをさらに加えるか、どちからしかない。すると、(クロスバースイッチでは)さらに配線密度が高まることになる」とDrebin氏は語る。メモリインターフェイスが256bit幅でコアクロックの2倍の転送レートの場合、コア内部の配線は512bit幅でないと対応し切れない。もし、GDDR4世代で3倍レートになったら、理論上768bit幅が必要となる。
しかし、リングバスならこの問題にも柔軟に対応ができるという。「リングバスには柔軟性がある。必要ならもっとリング幅を広げることもできる。メモリをもっと高速にすることが容易だ」とDrebin氏は指摘する。現在のR520は、メモリが256bit幅でコアの約2.x倍の転送レート。それに対してリングバスは256bitが双方向でコアクロック。ほぼつりあう形となっているが、これを拡張すれば、3倍速のメモリにも対応ができることになる。
メモリクライアントが増えることも、クロスバー型では問題だ。まず、GPU内部の並列性が倍々で高まると、メモリクライアントの数も倍々で増えていく。GPUアーキテクチャの変化も、問題を複雑にする。従来のGPUは、処理パイプの最初にデータを入れると、あとはテクスチャやZコンペアなど特定の処理以外はメモリにタッチすることがなかった。しかし、現在のトレンドは、ジオメトリパイプからも、テクスチャリードしたりメモリに書き出せるようになりつつある。そのため、メモリクライアントは並列性の向上を越えるペースで増えている。しかし、リングバスのノード(リングストップ)に分散してクライアントを接続するなら、クライアント数が増えても複雑化を軽減することができる。
メモリ回りでは、物理的にチップ上の配線長が長いことも困難を増していた。物理的には、DRAMコントローラはGPU上に分散せざるを得ない。これは、DRAMインターフェイスの信号線のアウトをGPUのエッジに配置する必要があるからだ。DRAMインターフェイスは信号線数が多いため、エッジ長をかなり必要とする。256bitインターフェイスになると、ダイの2辺を使うのが一般的で、そうするとDRAMコントローラは少なくとも2カ所に分かれることになる。実際、ダイレイアウトが公開されているXbox 360 GPUを見ると、DRAMコントローラは1エッジに1個ずつ分散されている。
それに対して、中央化されたメモリコントローラは、多くのユニットと接続する必要がある。そのため、チップ上で比較的センターに近い場所に配置されることになる。クロスバースイッチになると、必然的にチップ上のデータバスの引き回しも長くなる。だが、リングバスを使うことで、データバスについてはDRAMコントローラ間を結ぶだけにするなら、配線はより容易になると見られる。
もっとも、リングバスにもいくつか問題点はある。最大の課題はレイテンシが増えることだ。しかし、GPUではそれは大きな問題ではないという。
「グラフィックスの利点は、レイテンシを許容できることだ。そもそも、(データアクセスの)全体のプロセスから見れば、バス上の転送(レイテンシ)は比較的小さい。アービトレーション(調停)など他の部分でもレイテンシがあるからだ。もし、(リングバスが)柔軟性を高めて高速化を可能にするなら、バス上の転送は問題にはならない」(Drebin氏)
R520の場合は、非常に広いマルチスレッディングでメモリレイテンシを隠蔽する。そうしたアーキテクチャ上の工夫によって、レイテンシは問題にならなくなっているようだ。
●DRAMアクセスの調停をインテリジェント化
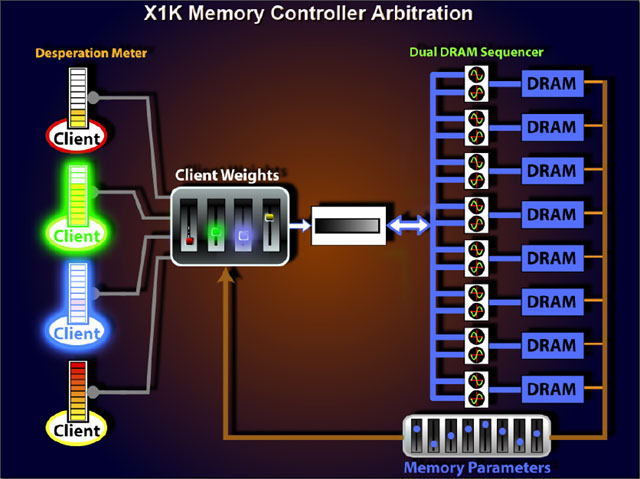
また、R520のメモリコントローラではDRAMアクセスの調停をプログラマブルアービターによってインテリジェント化している。
複数のクライアントからメモリ要求があった場合、それぞれのメモリアクセスをチェック、優先度を決める。データロードが遅くなるとストールするケースなど、デバイスやアプリケーションによっての重要度を判別する。
また、DRAM側の状態もメモリパラメータによりチェックする。クライアントのプライオリティとDRAMの状態の両方から、重要度が高く、なおかつ効率的なメモリアクセスパターンを見つけ出す。
 |
 |
 |
| R520のメモリコントローラのアービトレーション | グリーンとブルーのクライアントからメモリリクエストが来ると、メモリコントローラがプライオリティを決定する | 次にメモリパラメータをチェック |
 |
 |
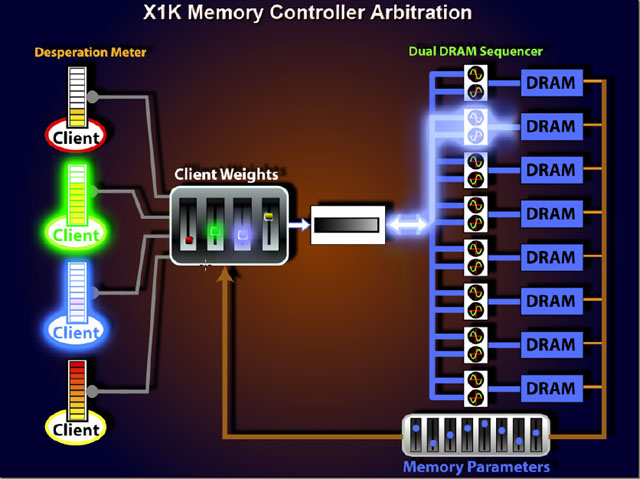
| ブルーの優先度が高く、DRAM側の効率も高いと判定すると、ブルーのデータを読み出す | 次にグリーンのクライアントのデータを読み出す |
こうした調停はプログラマブルにできるため、クライアントの重みづけやメモリリクエストの効率性は、アプリケーション毎に最適化ができるという。アプリケーションによって異なるメモリアクセスのパターンに適応させることができる。
面白いのは、このインテリジェントアービターも、またレイテンシを増やす要素だということ。R520の思想は、徹底してレイテンシを増やしても効率性を追求する点にある。GPUはもともとレイテンシを許容できるうえに、R520ではワイドなマルチスレッドによって、さらにレイテンシを隠蔽ができるようになっている。マルチスレッド化が、こうしたメモリ効率性の追求を可能にしたわけだ。
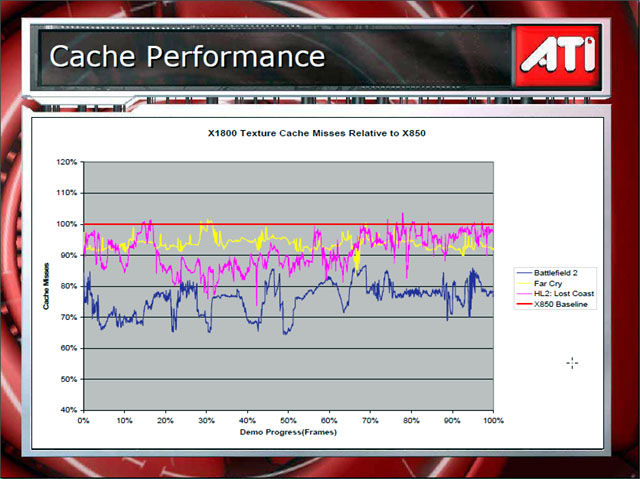
R520ではキャッシュメモリも改良された。R520では、テクスチャ、カラー、Z&ステンシルのキャッシュがある。従来のATI GPUのキャッシュは、ダイレクトマップとn-Wayアソシエイティブキャッシュの組み合わせだった。つまり、キャッシュラインは、特定の外部DRAMブロックに対応するように限定されていた。だが、R520からは、キャッシュはモダンCPUと同様に、フリーアソシエイティブキャッシュ(Fully Associative Cache)となった。自由に外部ビデオメモリのブロックに対応するようになった。
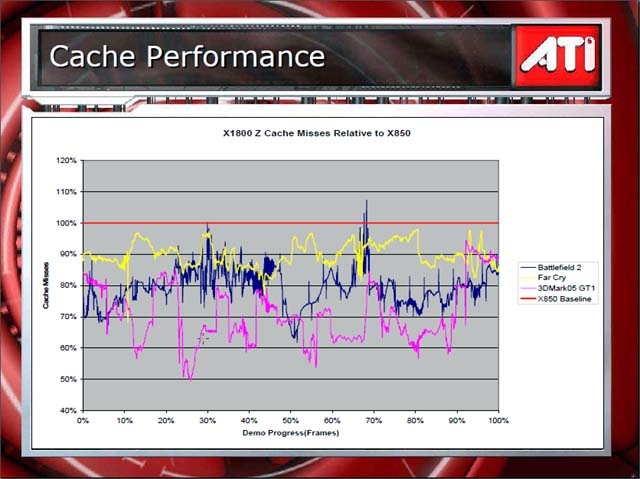
その結果、キャッシュヒット率は大幅に向上したという。下はキャッシュミスのレートのグラフ。RADEON X850のベースラインが赤の水平線。アプリケーションによるが、キャッシュミス率がR520では場合によっては20%以上も下がっている。
 |
 |
 |
| Cache Design | キャッシュミスレートグラフ | |
この改良は、これまでのメモリ仕様とは逆にレイテンシを短縮する。R520はスレッディングによるレイテンシ隠蔽だけでなく、実際のレイテンシも下げる方向にも拡張されている。これは、同じATIデザインでも、スレッディングに特化して、キャッシュ量は大きく削ったXbox 360 GPUとの違いだ。
この他、R520では早期の隠面消去であるHierarchical Zを改良、より精度を向上させることで余計なピクセル描画を、より減らしている。これも、メモリ帯域への圧迫を減らす効果がある。また、Zデータの圧縮効率を1:8へと向上させている。
□関連記事
【10月6日】【海外】R520ことATIの新GPU「RADEON X1800」の登場
http://pc.watch.impress.co.jp/docs/2005/1006/kaigai215.htm
【10月6日】【多和田】新世代アーキテクチャを採用したATI「RADEON X1800」
http://pc.watch.impress.co.jp/docs/2005/1006/tawada62.htm
(2005年10月7日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.