 |


■後藤弘茂のWeekly海外ニュース■RADEON X1800(R520)アーキテクチャの鍵“Ultra-Threading” |
●マルチスレッディングを前面に押し出したR520
ATIは、RADEON X1800(R520)を“Ultra-Threading(ウルトラスレッディング)”アーキテクチャと呼ぶ。プロセッサとしての同GPUの、アーキテクチャ上の最大の特徴は、マルチスレッディングだからだ。CPUがマルチスレッドへと向かったように、GPUも急速にマルチスレッディング化を進めている。
むしろ、CPU以上と言っていいかもしれない。R520は、最大512スレッドをオンザフライで制御することが可能だ。PC向けのマルチコアCPUによるマルチスレッディングがせいぜい4スレッドオンザフライという状況で、R520の512wayというマルチスレッディング規模はとてつもなく巨大だ。膨大な規模のマルチスレッディングなので、Ultra-Threadingとネーミングしたわけだ。
ATIは、RADEON X800(R420)でもスレッディングをサポートしていたはずだが、R420の際にはほとんど説明はなかった。今回、R5xxでは、スレッディングを前面に押し出してきたのは、それだけこの部分にフォーカスして開発したことを示している。
CPUとGPUが、軌を一にしてマルチスレッディングへ向かったと言っても、GPUのマルチスレッディングは、CPUのそれとはかなり異なる。マルチスレッディングの重要な効用の1つは、メモリアクセスの長いレイテンシを隠蔽すること。これはGPUでもCPUでも共通している。しかし、その他の点は、大きく異なり、GPUの方がマルチスレッディングの効用ははるかに大きい。
 |
| RADEON X1800(R520)におけるPixel Shaderでのマルチスレッディング PDF版はこちら |
●マルチスレッディングが容易なグラフィックス処理
アーキテクチャの根本から見ると、GPUでは、マルチスレッディングの恩恵を受けやすい。それは、相互依存性のないタスクが無数に存在するからだ。ピクセルや頂点の数だけのタスクがあり、各タスク間に、スタティックなデータレベルの依存性がない。そのため、非常に幅広い並列処理が可能だ。また、GPUはキャッシュメモリ(多階層の場合もある)を搭載するが、リード-モディファイ-ライト(Read-Modify-Write)タイプの制御ではない。つまり、キャッシュ内容が書き換えられることがない。そのため、GPU内でコヒーレンシを取る必要がない。
GPUでは、プログラマがマルチスレッディングを意識しないですむことも大きい。CPUでは、マルチタスクを越えてマルチコアリソースを活かそうとすると、マルチスレッド化したプログラムを書かなくてはならない。ところが、GPUではスレッドインスタンスが自動的に生成されるため、プログラマがシーケンシャルなプログラムであるシェーダを書いても、マルチスレッディングになる。同じ3Dオブジェクトに適用したシェーダプログラムは、複数のスレッドに適用されるからだ。CPUと違って、マルチスレッディング化は、自動的に行なわれることになる。マルチスレッディング化での、プログラマへの負担はない。
つまり、GPUでは、CPUよりもはるかに簡単に膨大な数のスレッドをスイッチできるわけだ。PCのソフトウェア環境のように、せいぜい2way程度のスレッド並列性に制約されているわけではない。こうしたソフトウェア環境の背景から、GPUではマルチスレッディングがCPUよりも効果を上げやすい。512wayのマルチスレッディングも、それほど突飛なアーキテクチャではない。
●GPUのスレッドはピクセル/頂点のバッチ
CPUとGPUではスレッドの概念も異なる。GPUでのスレッドは、ピクセルや頂点のバッチと、そのワークロードに対するバッチプロセッシングを一般的に意味する。「X1000ファミリでは、Pixel Shaderは、4個のコアにクラスタされている。各コアは、16ピクセル単位でプロセッシングする。我々は、このバッチプロセッシングを“スレッド”と呼んでいる」とR520の開発を担当したBob Drebin氏(Fellow, Discrete Graphics Engineering)は説明する。
つまり、R5xx系では、16個のピクセルのブロックが、スレッドという名前で扱われている。このスレッドのサイズ、つまり1スレッドに何個のピクセル(または頂点)を含むかがGPUアーキテクチャによって決まっており、スレッドサイズが性能に大きく関係する。また、スレッドサイズとGPUのハードウェア構成には密接な関係がある。
さらに、RADEON X1000(R5xx)ファミリでは、MicrosoftのマルチメディアAPIであるDirectX 9 Shader Model 3.0のフィーチャに最適化した、高度なマルチスレッディング制御を行なう。最大のポイントは、スレッドの制御が、動的フロー制御の効率化と大きく重なる点だ。
DirectX 9 Shader Model 3.0では動的な命令フロー制御がProgramable Shaderに加わった。しかし、GPUでは、条件分岐のような命令レベルの動的フロー制御を行なうと、性能上のペナルティが非常に大きかった。しかし、マルチスレッディングによってこれも軽減できるという。後述するが、各ピクセル(または頂点)単位での無駄なウエイトサイクルを減らすことができるためだ。
GPUのスレッド内の制御は、インオーダ型でスレッド内のピクセル(または頂点)が、同じコードパスで処理されることを期待する単純な仕組みを取っている。そのために、動的分岐があると、ムダが発生するが、それをマルチスレッディングでカバーするという発想だ。R5xxでは、命令レベルで高度なスケジューリングはあまり行なわない代わりに、スレッドスケジューリングで効率化を図る。
このように、GPUではマルチスレッディングは、プロセッシング性能向上と密接に結びついている。CPU以上に、マルチスレッディングによる性能向上は大きいと推測される。
●R520のスレッド実行の仕組み
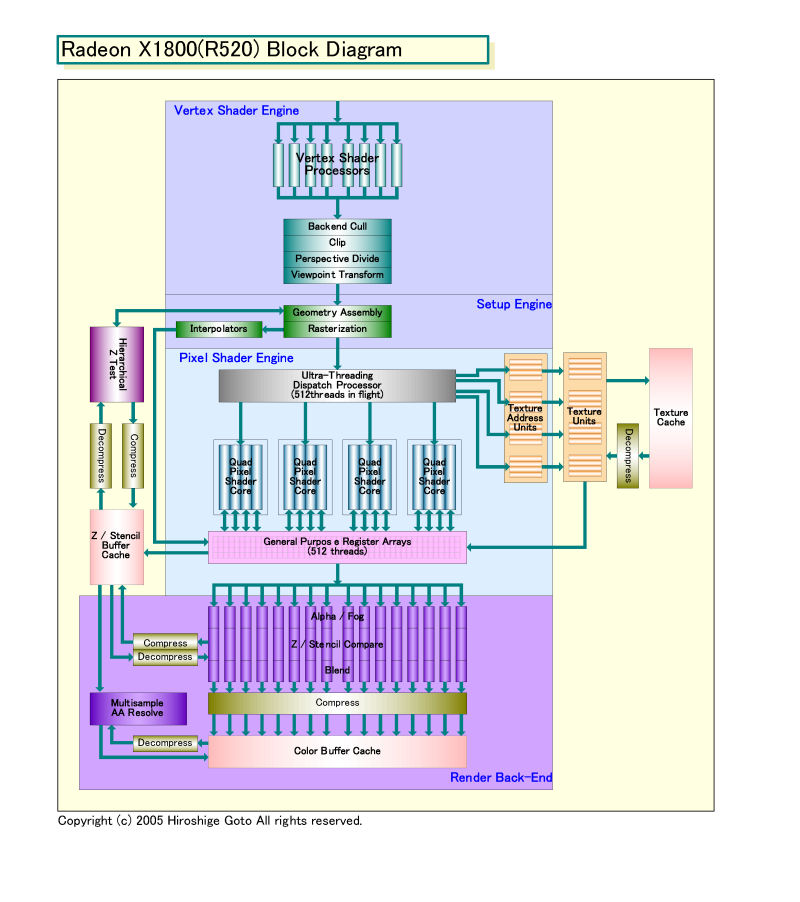
プロセッサのパフォーマンスは、いかに無駄なくパイプラインを稼働させることができるかにかかっている。そのためには、可能な限りパイプラインのストール(停止)を抑え、ムダなアイドルサイクルを減らすことが重要だ。RADEON X1000(R5xx)ファミリが、非常にワイドなマルチスレッディングをPixel Shaderに実装しているのは、このためだ。マルチスレッディングによって、RADEON X1800のPixel Shaderでは、90%以上の実行効率を達成できるという。
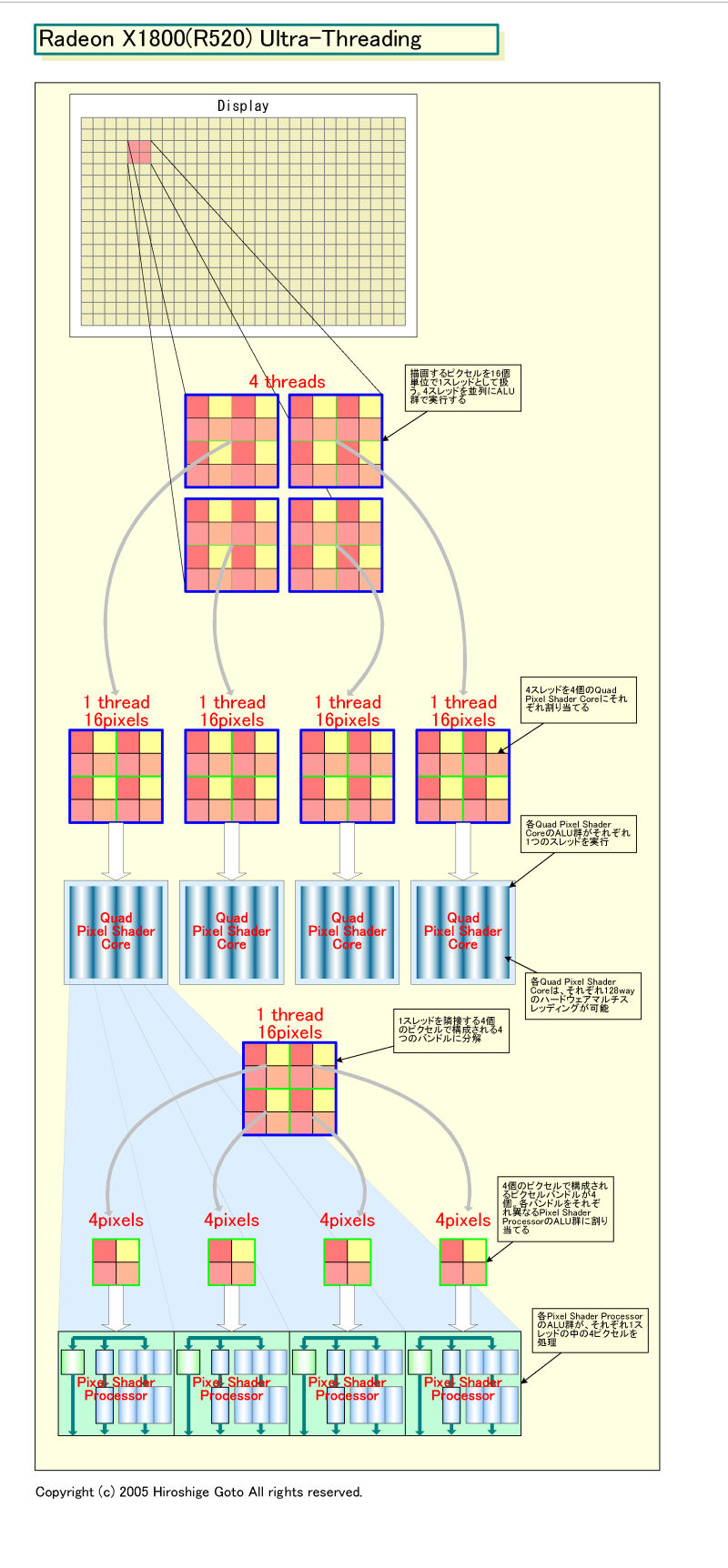
下の図が、RADEON X1800(R520)のPixel Shaderでのマルチスレッディングの概念図だ。R5xx系では、Pixel Shader側だけがマルチスレッディングを行なう。
 |
| RADEON X1800(R520) Ultra-Threading PDF版はこちら |
GPUでは、描画するピクセルはスレッドバッチへとグループ化される。R5xx系ではスレッドのサイズは、16ピクセル。2ピクセル×2ピクセルの塊が4個で、4ピクセル×4ピクセル=16ピクセルだ。この16ピクセルが1単位として、Shader Engineで制御される。ピクセルプロセッシングのワークロード全体を、より小さなタスクグループ(=スレッド)に分解すると考えてもいい。
R520は合計16個の「Pixel Shader Processor」を搭載している。各Pixel Shader Processorは4個づつバンドルされ、「Quad Pixel Shader Core」に編成されている。R520の場合は、4個のQuad Pixel Shader Coreを搭載する。スレッドの制御は、基本的に、このQuad Pixel Shader Coreをベースに行なわれる。Shader Processorベースではない。
「4個のShader Processorで構成されたバンドル1個に、16ピクセルのバッチ1個が割り当てられる。このバッチが1スレッドだ。1スレッドは4個の2x2ピクセルで構成されている」(Drebin氏)。「各Shader Coreが、それぞれ4×4ピクセルのスレッドを実行する」(ATI、Daniel Taranovsky氏(Product Manager, Discrete Desktop Graphics Group)
R520では、4個のQuad Pixel Shader Coreがあるため、数値演算については、最大4スレッドが並列に処理されることになる。「特定の時点ではRADEON X1800では4スレッドを同時に実行できる。ただし、これはALUだけの話だ、命令フロー制御は異なるスレッドを実行できるし、テクスチャルックアップについても異なるスレッドを実行できる」(Drebin氏)。後述するが、各Quad Pixel Shader Coreの中のALU群と命令フロー制御ユニット、コアとハンドシェイクする4個のテクスチャユニットで、それぞれ別なスレッドを実行することもできる。この図では、ALU演算についてだけを説明している。
また、図では4個のスレッドがそれぞれ隣接するように描いているが、実際には必ずしも隣接するとは限らない。各Shader Coreへのスレッド割り当ては、個別にどんどん変わって行くからだ。
●スレッドを4ピクセル単位に分解して実行
R520では512wayのハードウェアマルチスレッディングをサポートする。各Quad Pixel Shader Core(+テクスチャアドレスユニットクアッド)毎に128wayのマルチスレッディングが可能だ。「それぞれのユニット(Quad Pixel Shader Core)が最大128スレッド、合計で512スレッドとなる」とATIのアーキテクトRaja Koduri氏(Senior Architect)は語る。ちなみに、R520について、今年前半に行なわれたOEMへの説明では128wayのマルチスレッディングだったのが、発表時に512wayになっていた理由は、ここにありそうだ。
スレッドの制御は、Pixel Shader Engineの中核となるディスパッチプロセッサが行なう。エンジン全体で、512スレッドをトラックし、各ユニット群にディスパッチ・スイッチする。エンジン内のコアがアイドル状態になると、ディスパッチプロセッサがコア毎に、ストールしたスレッドから別なスレッドへと切り替える。そうやって、コアを常にビジーに保つわけだ。
1スレッドは、さらに4個の2ピクセル×2ピクセルのブロックに分解される。ATIのTaranovsky氏によると、それぞれの2×2のピクセルブロックが、各Pixel Shader Processorに割り当てられるという。つまり、1 Shader Processorにつき4個づつピクセルを処理することになる。
 |
| Taranovsky氏の説明したShader Core内でのスレッドの実行の仕組み |
ちなみに、こうしたスレッディングアーキテクチャの理解は、ATI内部でも完全に浸透していないと見られる。例えば、ATIの発表会で配布されたホワイトペーパーの一部では、各Quad Pixel Shader Coreが2×2のピクセルブロックを実行すると記述されていた。しかし、他のATIの技術スタッフは、いずれもコア単位でスレッド(4×4ピクセル)を実行すると説明しており、食い違っている。この記事では多数の説明を正しいと判断している。こうした食い違いは、R5xxの取ったマルチスレッディング化のアプローチがそれだけアグレッシブで、親しまれてしないことを示している。
ちなみに、NVIDIAでもスレッディングについての説明は、同社の担当者によって異なっており、浸透しているとは言い難い。NVIDIAも、GeForce 6800(NV40)からVertex ShaderとPixel Shaderに、ハードウェアマルチスレッディングを実装している。だが、ATIほど詳しい説明は、まだ行なわれていない。
次回は、R520でのマルチスレッディングが、実際にどのような効用をもたらすのかを解説したい。
□関連記事
【10月7日】【海外】メモリ効率向上にフォーカスしたR520アーキテクチャ
http://pc.watch.impress.co.jp/docs/2005/1007/kaigai216.htm
【10月6日】【海外】R520ことATIの新GPU「RADEON X1800」の登場
http://pc.watch.impress.co.jp/docs/2005/1006/kaigai215.htm
【10月6日】【多和田】新世代アーキテクチャを採用したATI「RADEON X1800」
http://pc.watch.impress.co.jp/docs/2005/1006/tawada62.htm
(2005年10月17日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2005 Impress Corporation, an Impress Group company. All rights reserved.