 |


■塩田紳二のPDAレポート■次世代XScaleプロセッサ、Bulverdeとは? |
現在、PDAに使われることが多いXScaleは、PXA255と呼ばれるプロセッサである。その後継とされるプロセッサが、コード名Bulverdeと呼ばれるものだ。Bulverdeは地名で、テキサス州に同名の市がある。
 |
| 今年2月のIDFで配布されたプレゼンテーションの1つ。BulverdeというプロセッサにワイヤレスMMXが搭載されていることがわかる |
このBulverdeは、すでに開発者向けボード(Mainstoneというらしい)の提供が開始されている。今年2月のIDFでは、基調講演などでBulverdeには触れられなかったが、後述するワイヤレスMMXについては、基調講演で概要が公開された。しかし、IDFのカンファレンス用プレゼンテーション資料では、堂々とこのコードネームが出ていたのだ。まあ、公式発言はしていないが、こういうコード名のプロセッサがあることは確かと言える。
さて、このBulverdeだが、新機能として以下のようなものがある。
(1) ワイヤレスMMX
(2) Mobile Scalable Link
2月のIDFの資料などから推測するに最高クロックは500~600MHz程度まで上がるのではないかと思われる。つまり、性能的には現在のPXA255の1.5倍ぐらいになり、ワイヤレスMMXに対応したプログラムなら、それ以上の性能向上が見込める。
最近のPDAは、どんどん負荷が高くなってきている。これは、Windowsのものにより近いWebブラウザが搭載されていたり、無線LANなどによる高速接続、VPN処理などもあるからだ。
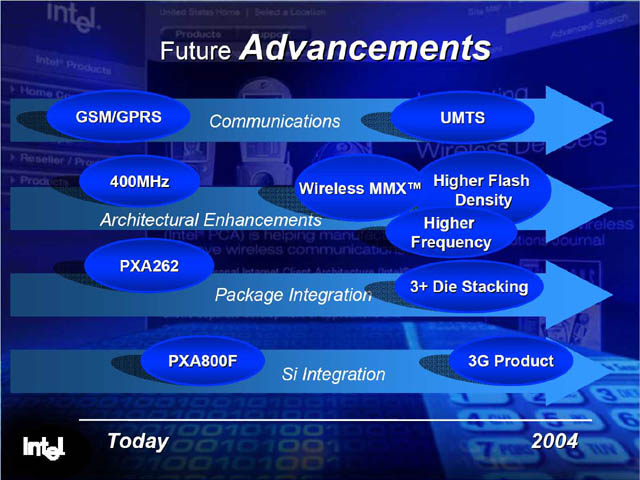 |
| 2月のIDFで、PCA担当のGadi Singer副社長が行った基調講演のプレゼンテーション。ここで、次世代のプロセッサでは、ワイヤレスMMXが搭載され、クロックが向上することが示されている。ちなみにUMTSとは、W-CDMA方式の携帯電話システムのEUでの呼び名 |
また、Word/Excelのファイルを閲覧するだけでなく、編集を可能にしたり、PDFの表示なども行なえるようになるなど、アプリケーションが要求する機能もどんどん高くなっている。これは、PDAが普及するにつれ、ユーザーの要求が高くなってきているからでもある。
かつては、PDAといえば、ごく一部の上級ユーザーが使っており、PDAにそうそう重い処理を行なわせることが無理だということをユーザー自身が理解していた。しかし一般ユーザーは、PDAの事情などにはおかまいなく、PCと同じようにWebブラウザが動いたり、Javaのアプリケーションが速く動くことを期待する。そうなると、自然とアプリケーションが高機能になり、CPUに対する要求が高くなってしまうのである。
しかしPDA用のプロセッサは、ノートPC用以上に省電力であることが求められ、簡単にクロックを高くするわけにはいかない。PCよりも部品が少ない分、CPUの消費電力が全体の消費電力に占める割合が高いからでもある。そこで、クロックを高くするなら、それ相応に電源電圧などを下げなければならない。これは、単純に考えれば、提供する最高クロックよりも高速に動作するデバイスを作ることに等しい。低電圧版のプロセッサと同じ原理である。
そこでIntelが出した1つの回答がワイヤレスMMXである。これにより、命令レベルでの処理効率を上げ、クロック向上なしに性能を向上させる方法である。
●ワイヤレスMMXとは?
ワイヤレスMMXとは、簡単にいえば、XScaleにMMXとSSEの整数演算機能を組み込んだもの。SIMD型の命令を使って、1命令で複数のデータを同時処理することで、処理効率を上げるわけだ。
MMX Pentiumで導入されたMMXとPentium IIIで導入されたSSEは、Intelが管理する命令セットに対しての拡張だったが、今回のワイヤレスMMXはXScaleやBulverdeのベースとなるAMRプロセッサの命令セットに対しての拡張になる。XScaleは、ARMバージョン5TEというARMが管理する命令体系を持っている。ここに命令を追加することは簡単にはできない。
そこで取られた方法が、ARMのコプロセッサインターフェースを使う方法である。ARMプロセッサは、外部にコプロセッサを置き、それに対してのデータ転送や命令実行を行なわせる命令を持っている。これを使うことで、ある程度自由にCPUの命令を増やせるのである。
現在のARMでは、最大16個のコプロセッサ(コプロセッサ0~15)を持つことができ、XScaleでは、このうち14、15をIA-32でいうCPUIDなどのために使っている。
ワイヤレスMMXは、コプロセッサ0と1を使う。2つ使うのは、コプロセッサインターフェースでは、個々のコプロセッサに16個のレジスタしか指定できないからである。ただ、これはARMアーキテクチャ上の話であって、実際にワイヤレスMMXを処理するモジュールが2つのコプロセッサに別れているわけではない。
ちなみにXScaleでは、もともと、コプロセッサ0を使って、演算命令を拡張している(これをXScale media instructionと呼んでいるようである)。40bitのレジスタを使って積和演算(かけ算した結果を足していく計算。マルチメディア処理で比較的使われる)を行なうもの。ワイヤレスMMXはこの命令に対する上位互換の命令を含んでいる。
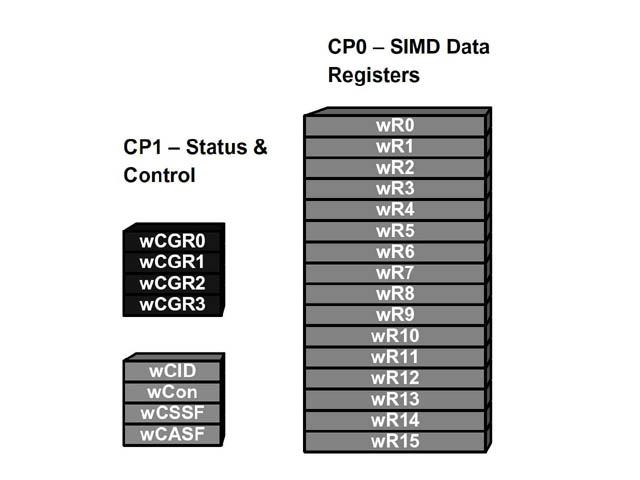
ワイヤレスMMXでは、16個の64bitレジスタ(従来のMMXレジスタ、XMMレジスタに相当)と4つの32bit汎用レジスタ、4つの制御用レジスタを使う。SSE/SSE2のXMMレジスタは、8個の128bitレジスタとなっているため、ビット的には16個の64bitレジスタで同じになる。IA-32では、MMXレジスタとXMMレジスタは物理的に別のものになっていたが、ワイヤレスMMXでは、この1組のレジスタのみを使う。4つの32bit汎用レジスタは、計算途中でデータを一旦待避させるなどに使うのだと思われる(CPU-コプロセッサ間のデータ転送には時間がかかるため、コプロセッサ内部で転送させたほうが速い)。
 |
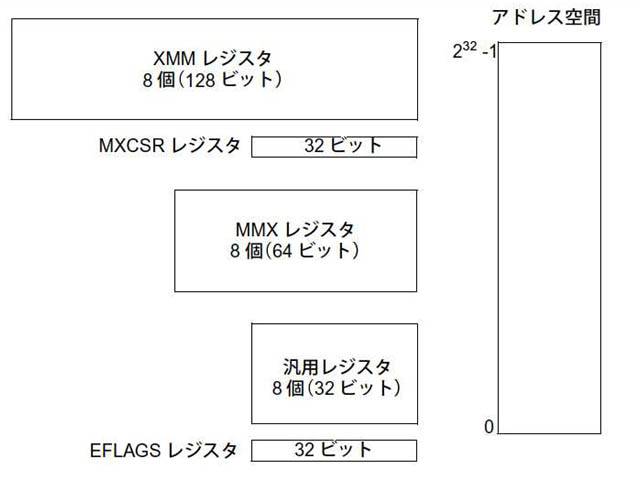 |
| ワイヤレスMMXで追加されるレジスタ。右側がMMX/XMMレジスタに相当し64bitレジスタが16本ある。左側が汎用32bitレジスタ(wCGR0~4)と制御用レジスタ | IA-32のSSEで使われるレジスタ。MMX用の64bitレジスタが8つ。128bitのXMMレジスタが8つある |
なおワイヤレスMMX命令では、整数のみを扱い、SSE/SSE2で導入された浮動小数点データは扱わない。浮動小数点演算は回路規模も大きくなり、消費電力的に不利だからである。入れることで性能は向上するものの、消費電力が大きくなる、ダイサイズが大きくなるなどの理由で、XScaleが狙う分野には不向きなプロセッサとなってしまう。
これらのレジスタに対するアクセスは、ARM命令セットにあるコプロセッサデータ転送命令を使う。ARMでは、コプロセッサとメインプロセッサのレジスタ間のデータの転送と、コプロセッサレジスタとメモリ間のデータ転送をサポートしている。
ワイヤレスMMX命令は、実際にはARMのコプロセッサデータ処理命令(CDP)にマッピングされる。このCDP命令の一部にあるビットパターンがコプロセッサに渡されることで、コプロセッサは処理を行なう。しかし、ARMのメインプロセッサ(この場合には、XScale)から見れば、あくまでもCDP命令であり、他の命令と違いはない。このため見かけ上、CPU命令が増えたように見えるわけである。
これで追加される命令には、MMX/SSEの整数演算命令29個と、新たにワイヤレスMMX用に作られた8個、XScale Media Instructionの上位互換命令3つがある(オペランドサイズによるバリエーションを除く)。
ワイヤレスMMXでは、64bitのSIMD演算、つまり、8bit×8、16bit×4、32bit×2を実行できる。一部、64bit×1に対する演算も可能。
これにより、従来のMMX/SSEと同じく、MP3やMPEGといったマルチメディアデータの処理が高速化される。ただし、このワイヤレスMMX命令を使わないプログラムは、クロックの差ぐらいしか高速化されない。
MMX/SSEの普及には少し時間がかかった。特に最初のMMXについては、対応アプリケーションが普通になったのはごく最近のこと。こうした背景もあって、Intelは、早期にBulverdeの情報を公開、開発用ボードを提供しているのだと思われる。
●Mobile Scalable Link
Mobile Scalable Link(MSL)は、最大192Mbpsでの転送が可能なXScale用のデバイス接続技術。これは、デバイス内部での接続と、パッケージ間(つまりボード上)での接続の両方に使われる。XScaleは組み込み用であり、さまざまなコントローラーとして使われる場合に、大量のデータを出し入れする必要がある。また、PDAやスマートフォンでは、ネットワークやその他のデバイスとの接続が必要な場合がある。例えば、携帯電話用のベースバンドプロセッサとの接続などである。
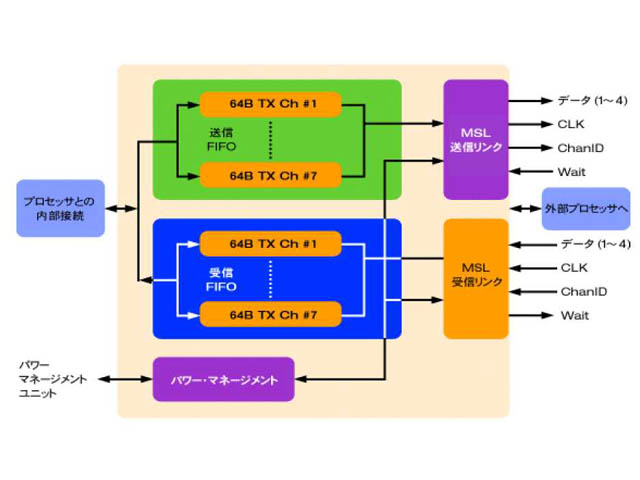 |
| MSLは、片方向192Mbpsのリンクを2つ組み合わせて双方向とする。1つのリンクは、論理的な16チャンネルから構成されており、それぞれがFIFOを持っている。また、この16チャンネルのうち7つをデータ転送に利用できる(残りは通信制御用か) |
MSLは、4bitパラレルの片方向リンク(信号ラインとしては7本)を2つ組み合わせて双方向としたもの。ただし、個々のリンクは、片方向16の論理的なチャンネル(双方向で32チャンネル)からなっている。つまり、16本の論理的な双方向接続をこの1組の物理的なリンクで実現できるわけである。
この16チャンネルのうち、最大7つまでをデータ転送に利用でき、チャンネルごとに優先度をつけることも可能。このため、音声や映像といったリアルタイム性の強いデータの転送に利用できる。
また、転送プロトコルがちゃんと定義されており、エラー検出や回復ができ、上位プロトコルからは、パケットを受け取るだけでフロー制御などはMSL内部で行なう。
このMSLは、Bulverdeでは、外部接続として実装されることになると思われる。用途としては、無線LANやEthernet、あるいはカメラなどがあるだろう。携帯電話用途であれば、W-CDMAなどのベースバンド接続だろう(こちらは、スマートフォン向けプロセッサであるManitobaの後継チップがW-CDMA対応するといわれているので、おそらく内部接続として使われるだろうが)。
前回のインタビューで、シーカ副社長は、PXA255などにさらにデバイスを集積することは考えていないと言っており、無線LANデバイスも入れる予定がないとしていたが、おそらく、PDAや携帯電話などに使われる少し特殊なデバイスは、このMSLで接続することを想定しているのであろう。
日本ではデジタルカメラ付き携帯電話があたりまえになったが、世界的にみればまだごく一部。今後、解像度なども変わる可能性があり、プロセッサと統合することは難しい。このため、MSLのような高速インターフェイスを用意し、必要なら、好きなデバイスをこれで接続してくれということなのだろう。
また、こうした接続技術を出すからには、Intelとしてもここにつながるデバイスを用意していることは十分考えられる。前述のW-CDMAなどのベースバンドプロセッサ、あるいはIEEE 802.11bの無線LANデバイスなどがあり得るだろう。
●省電力はどうなる?
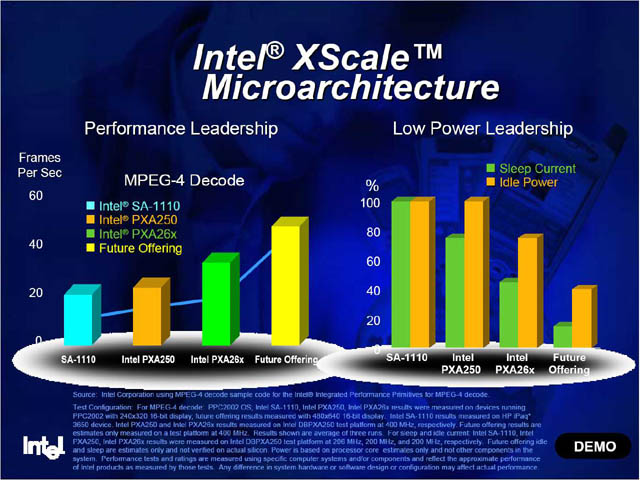 |
| 同じくGadi Singer副社長の基調講演では、次世代のプロセッサの性能や消費電力が示された。性能的には500~600MHz程度、Sleep/Idle時の消費電力は、現在の半分ぐらい |
最近では、ARM系プロセッサも省電力機能を搭載する動きがある。ソニーがHandheld Engineで取り入れたし、ARMも省電力機構をアナウンスしているほか、National Semiconductorが省電力技術であるAVSを発表している(このあたりは、大原氏のEmbedded Processor Forum 2003レポートを参照していただきたい)。
ARMプロセッサは、もともと消費電力あたりの実行速度(MIPS/W)が高く、これがバッテリ駆動の組み込み機器に向いていたためにヒットしたわけだが、それがために、他社プロセッサに比べると省電力に対する取り組みが遅くなってしまった。
最近では、PDAやゲーム機など用途が広がるにつれて内部構造も複雑化し、トランジスタ数が増え、消費電力も大きくなってきた。そこに登場したのが、省電力機能を備え、パフォーマンスの高いXScaleだったわけである。つまりXScaleは、ARMプロセッサの空白地帯を狙った製品だったわけである。
というわけで、現在ではARMをふくめさまざまな企業が、ARMプロセッサの省電力に取り組み始めている。XScaleに他社が追従しはじめたわけだ。
XScaleの省電力機能とは、簡単にいえば、クロックに応じて電源電圧を変動させることで、最低限必要な電力で動作させるというもの。PXA255では、Sleep、Idle、Run(最も効率の良いクロック/電圧で動作)、Turbo(最高クロックで動作)という4つのモードを持ち、これをソフトウェアで切り替えられる。
SleepやIdleからは割り込みで抜けだせるようになっており、言うならば「やるべき処理が終わったら、すぐに寝て、必要になったら起こしてもらう」という制御になる。もっとも、これでは複数のプロセスが同時に動くような場合にはなかなか休めないので、負荷やプロセス状態などに応じてクロックを上げ下げする処理などが行なわれることもある。
これに対してソニーのHandheld Engineでは、CPU負荷や内部バスのアクセスの頻度などを測定して、自動的にクロック、電圧を制御するDVFM(dynamic voltage and frequency management)を搭載した。自動的にクロック/電圧が変わるため、XScaleよりはソフトウェア側の負担が少ない。
組み込み機器ではリアルタイム性も要求されるので、あまりソフトウェアに頼れないという面もあるわけだ。例えばPDAなどでは、ペン入力時には追従性が問題になるので、できる限り高速に動作しなければならない。
さて、このあたりIntelとしてもなんとかしたいところ。今年2月のIDFでは、次世代プロセッサでは、Sleep時、Idle時の電力消費を現在のPXA26xの半分ぐらいにするというプレゼンテーションがあった。IdleではCPUコアのクロックは止まるが、電源はONのまま、Sleepでは、統合された周辺デバイスへのクロックも止まり、CPU電源もOFFになる。
このことから考えると、リーク電流などを減らしたり回路を工夫して消費電力を減らす、Sleep/Idle状態での電源電圧を小さくするといった対策が行なわれるようだ。もっとも、IA-32用プロセッサと同じで、電源電圧が同じでもより高いクロック動くデバイスを作れば、より電源電圧を下げられるわけだ。
現在のXScaleプロセッサは、0.18μmプロセスで作られているが、これが90nmプロセスに切り替わるのは、少し先と思われる。一応年内にIA-32では、Prescott、Dothanといった90nmプロセスの大物が控えているので、XScaleも同時ということはないだろう。プロセスが移行するとしたら来年ということになる。
●発表時期は?
Bulverdeではそのほかに、統合された周辺デバイスなどが改良される可能性もある。たとえば、現在のPXA255に実装されているSDカードインターフェイスは、MMC互換の1bitでデータを転送するもの。このため、PXA255マシンでCPUのSDカードインターフェイスを使っているものはそれほど読み書きの速度が速くない。
このせいかどうか分からないが、以前紹介したシャープのLinuxザウルスC700は、SDメモリーカードの読み書きはそんなに速くない。高速版のSDカードを使っても、ファイルシステムをEXT2にしてもFATにしても、ほとんど速度が変わらなかった。このあたりは改良が望まれる部分だ。
さて、気になるBulverdeの発表時期だが、可能性としては9月に行なわれる秋のIDFあたりがもっとも可能性が高い。
SamsungがPXA255よりも高速なPDA用プロセッサ「S3C2440」を発表しているため、Bulverdeの出荷時期が来年で年末商戦用の製品には間に合わないにしても、なんらかのクギをさしておく必要があるからだ。
すでにHPは、下位製品の一部にSamsungのプロセッサを採用したし、ソニーも自社開発のプロセッサを投入した。ある意味PDAのXScale離れが起こりつつあり、早めに手を打っておく必要があるからだ。もっとも、Intelのことなので、何か隠し球がある可能性も否定できない。少なくとも、9月のIDFではXScaleに関してPDA業界向けに何らかのアナウンスがあるだろう。
□関連記事
【7月23日】Samsung、世界最高速のモバイルプロセッサ
http://pc.watch.impress.co.jp/docs/2003/0723/samsung.htm
【7月23日】【塩田】IntelでXScaleを担当するアンソニー・シーカ副社長インタビュー
http://pc.watch.impress.co.jp/docs/2003/0723/pda22.htm
【7月17日】ソニー、自社製CPUを搭載したクリエPEG-UX50
http://pc.watch.impress.co.jp/docs/2003/0717/sony2.htm
【6月18日】【EPF】さまざまな低消費電力技術
http://pc.watch.impress.co.jp/docs/2003/0623/epf03.htm
(2003年8月5日)
[Text by 塩田紳二]
【PC Watchホームページ】
PC Watch編集部 [email protected] 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.