 |
さまざまな低消費電力技術 |
 |
会期:6月16~19日(現地時間)
ARMの記事でもちょっと触れたが、今年のEPFは4部構成になっている。
1:Embedded Architectures(初日午前、高性能Embedded ProcessorとDSP)
2:Low-Power Embedded Processors(初日午後、低消費電力Processor)
3:Special Purpose Processors(2日目午前、特定用途向けProcessor)
4:Network Processor(2日目午後、Network Processor)
一応きちんとテーマ分けされているともいえるが、MPF/EPFの「暗黙のルール」(初日午前はまともなもの。2日目午前もまぁまともなもの。初日午後はやや変なもの。2日目午後はすごく変なもの)をほぼ守ったものになっていたとも言える。「すごく変なもの」については項を改めるとして、初日午後に登場したLow-Power Embedded Processorsで発表されたものをいくつかご紹介したい。
●Adaptive Voltage Scaling(AVS):ダイナミックな電圧制御
 |
| 【写真01】発表を行なったNSのSystem Application Engeneer、Juah Pennanen氏 |
P= CVdd^2fc + VddIoff
C:係数。回路内部のキャパシタンス合計などで静的に決まる。
Vdd:プロセッサのコア電圧
fc:動作クロック
Ioff:リーク電流
という式で計算することができる。つまり消費電力にはVdd、つまりコア電圧が2乗で利いてくるから、とにかく電圧を下げればドラスティックに消費電力を減らしやすい。ここまではPC向けプロセッサなどにも共通の話なので、お分かりいただけよう。
さて話はここからだ。従来の(コア電圧変更可能な)プロセッサは、どこかに動作クロック-コア電圧の関係を記したテーブルを持っておき、このテーブルをみながら周波数を変更するときには同時に電圧を変更するという仕組みを使っている。これをCPU内部に持つか【写真02上側】、外に出すか【写真02下側】というのは色々あるわけで、概してPC向けプロセッサはテーブルだけ外(BIOS)に出すなんてアプローチが一般的だったりする。
さて、NSはここでPowerWiseと呼ばれる新しいAPCを提案している。PowerWiseはOpen-loop(電圧制御を行なった結果のフィードバックを受け取らない)とClosed-loop(電圧制御結果のフィードバックを受け取って反映する)の2つの構成が可能だが、注目したいのはClose-loopの場合で、この場合は動作クロック-コア電圧テーブルが不要になるとしている【写真03】。何でテーブルが不要になるかというと、ダイナミックに回路をモニターし、このモニター結果に応じて電圧の制御を行なうからだ【写真04】。
 |
 |
 |
| 【写真02】これは概念図なので、実際はAPCにこの機能すべてが含まれていないとか、APC自体が分割され、他の機能モジュールに集約されている場合も多い | 【写真03】NSの主張によれば、Closed-loopを使うことで(Open-loopと比較して)20~40%の省電力化(&低発熱化)が可能だという | 【写真04】CPUの一部に、測定用の回路を用意する。で、この回路は当然電圧に応じてディレイが変わってくる訳だが、それをリアルタイムで測定し、ディレイが長すぎるようなら電圧を上げ、ディレイが短すぎれば電圧を落とす、という形で常時電圧の微調整を行なっている。これにより、常に最適な電圧を供給できるという仕組みだ |
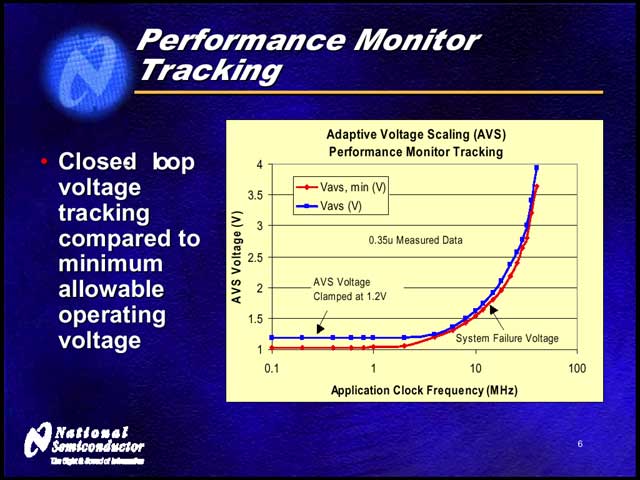
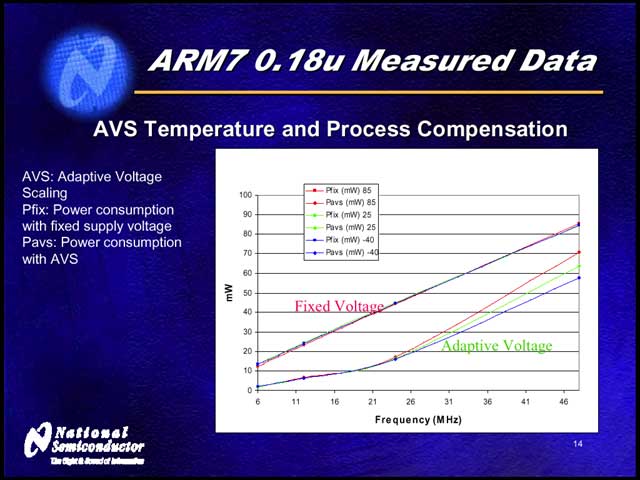
実際、いくつかのデータが今回示されている。【写真05】は0.35μmプロセスの例で、AVSを使うとCMOSの動作限界まで電圧を下げられる事が示されている。実際の構成回路は【写真06】のようになっており、例えば0.18μmプロセスのARM7では【写真07】のような、0.13μmプロセスのARM9では【写真08】のような結果が得られたとしている。
ARMの記事で「NSと共同で云々」とあったのは、このAVSの事である。ただ、別にAVSはARM専用という訳ではない。原理的にはどんなプロセッサにも適用可能だし、実際そうした方策を色々考慮していると思われる。この仕組みを見ると、PC向けの各種省電力機構が前時代なものに思われてしまうほど、理屈はすばらしい。問題は、十分なレスポンスタイムをどう確保するかというあたりで、これは単にAVS側だけでなくCPU側の対処も必要かもしれない。
 |
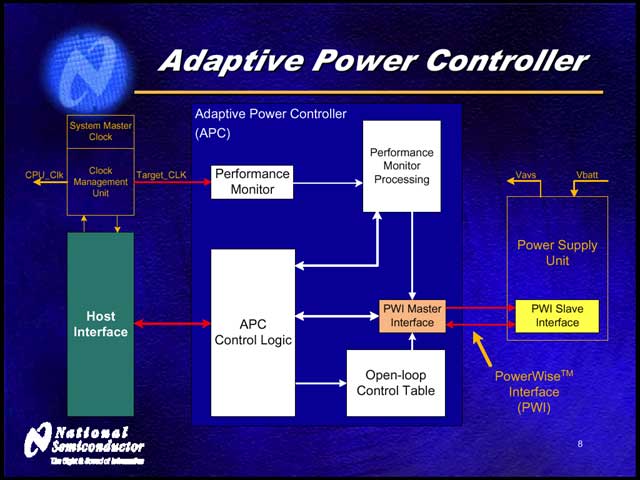 |
| 【写真05】動作周波数があまりに低い部分では、AVSがコア電圧を多少引き上げて安定させているが、それ以上の部分ではほぼCMOSの動作限界に近い電圧を保っていることが判る | 【写真06】AVSを適用したAPCのブロック図。電源回路向けに、PWI(PowerWise Interface)と呼ばれるインターフェースを用意している。PowerWiseが普及するためには、このPWIに対応した電圧コントローラが増えることが必須になるだろう |
 |
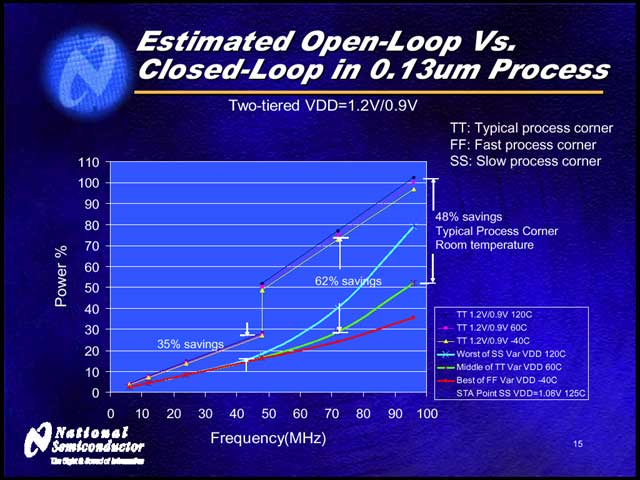 |
| 【写真07】CMOSの電圧特性は温度にも影響を受ける関係で、AVSを使うと温度によって多少消費電力が変わってくる。とはいえ、一定電圧で動作するオリジナルのARM7に比べると、いずれも省電力化がなされていることが判る | 【写真08】AMR9の場合、コア電圧を0.9Vと1.2Vに変化させることができるが、それでもAVSを使ったほうが効果的に省電力を実現できる |
●SMTで省電力?
 |
| 【写真09】Infinion TechnologyのSenior ArchitectであるErik Norden氏が講演した |
さて、TriCore2に関して省電力を考える際に、問題になるのはキャッシュミスによるプロセッサの空白の時間が多すぎる、ということだそうだ【写真10】。実際、333MHz動作のプロセッサコアに333MHz DDRメモリを搭載した場合と66MHzのフラッシュメモリを接続した場合を考えた場合、キャッシュミスの頻度が上がるほど、実効クロックが落ちる傾向が顕著だという【写真11】。
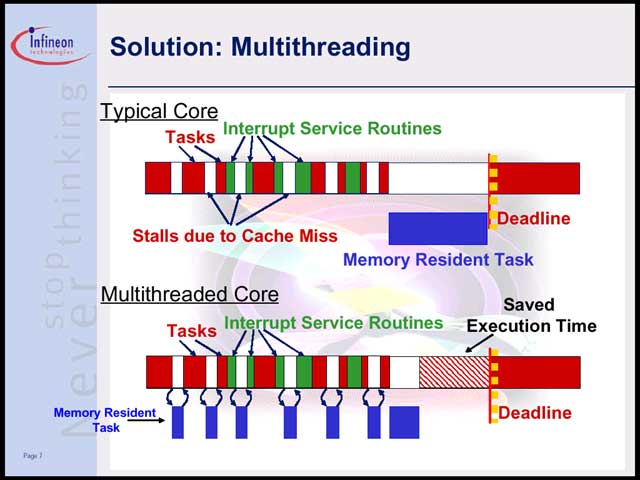
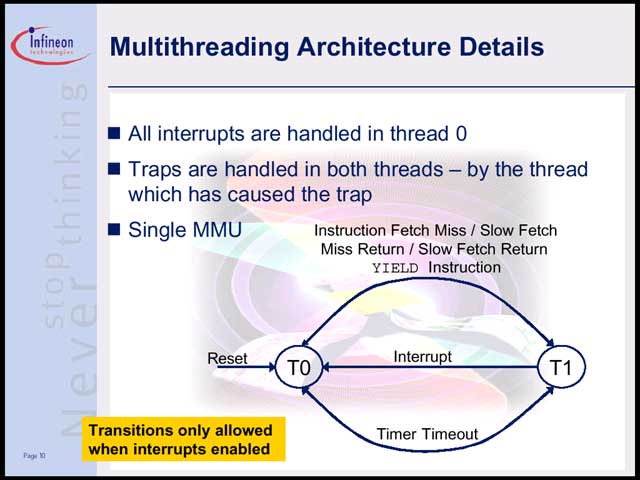
これを解決するためにはどうしたらよいか、という問題に対して同社が出した解は「じゃSMT(Simultaneous Multithread)にしよう」というものだった【写真12】。要するに機器の構成やコストを考えた場合、大量のメモリを搭載するとか、フラッシュを高速化するとか、キャッシュの容量を増やすといった解決策は取りにくい。したがってキャッシュミスは必ず発生し、避けることはできない。避けられないなら、こうした理由でパイプラインが止まっている間は、他のタスクを実行すればよいという話である。幸いTriCore2の場合、CPUローカルにプログラム/データ用のScratch RAMを持っているので【写真13】、緊急性の高くない小さなプログラム(携帯電話での画面表示とか)をここに常駐させておき、合間合間に行なえばよい、という発想だ。
 |
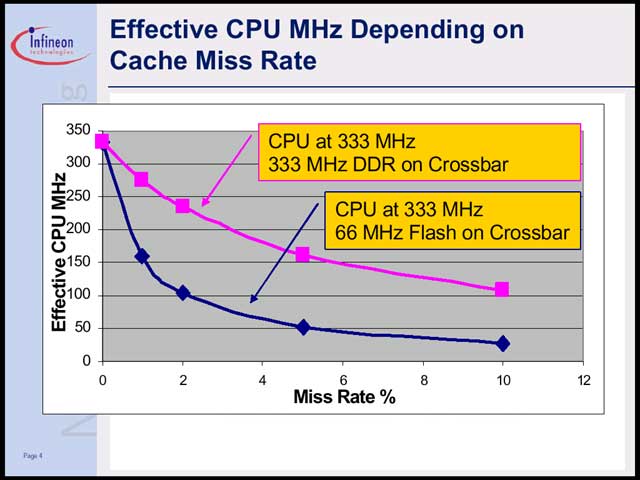 |
| 【写真10】キャッシュミスが発生する要因は、外部のフラッシュメモリから読み出しているため。携帯機器だと大容量のメモリは搭載できず、専らフラッシュメモリにプログラムやワークエリアを設けるのが普通だ | 【写真11】DDR333メモリは、普通は使わない。あくまでも対比のために示したと思われる。それにしても、実効速度の低いことよ |
 |
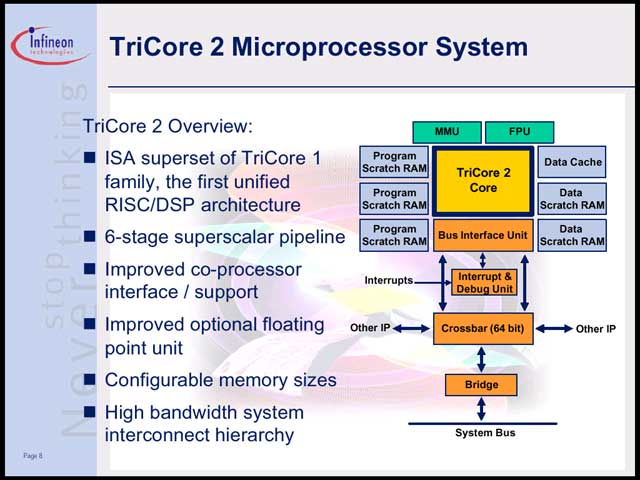 |
| 【写真12】TriCore2におけるSMTの考え方。通常のTaskとMemory Regident Taskを分けることで、効果的にCPUを利用し、その結果あまったCPU時間をクロック低下に振り分けるというアプローチだ | 【写真13】TriCore2の内部構造。外部インターフェースがクロスバースイッチなあたりが、ちょっと特徴的 |
 |
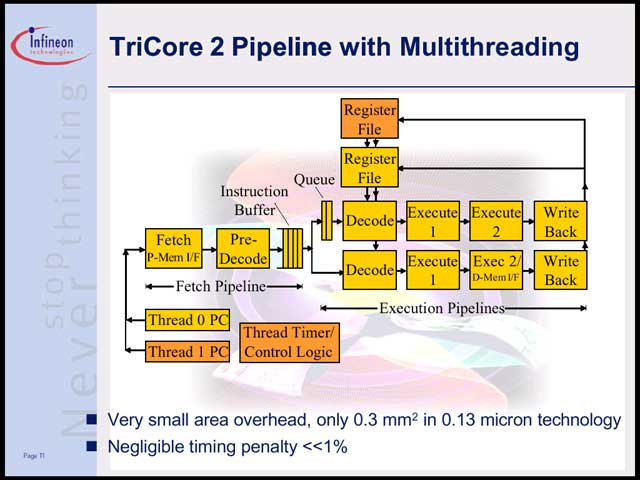 |
| 【写真14】スレッドの切り替えは、他にタイマーイベント(一定時間以上特定のスレッドがCPUを占有させない仕組み)とYield命令(明示的にスレッドの切り替えをソフトウェアから行なえる)、及び割り込み処理(すべての割り込みはThread0で処理される)でも発生する | 【写真15】TriCore2の内部構造。基本的には2命令のスーパースケーラといえなくも無いが、実体はMIPS32 24Kに似ていて、ALUとMemory Accessが別パイプラインになっていると考えた方が良い。色の濃い部分が、SMTのために追加されたユニット。0.13μmプロセスで0.3平方mm程度でしかないそうだ |
・MultiThreadを使わない
・MultiThreadを使うが、どちらもフラッシュメモリ上のプログラムを実行する
・MultiThreadを使い、片方はスクラッチメモリに常駐させる
の3パターンを比較した場合、最後のケースでは驚くべき高さの効率を見せている事が判る【写真17】。
PC用プロセッサだとここで「というわけでMultiThreadingは素晴らしい」で話が終わるのだが、TriCoreの場合はさらに話が続く。これだけ効率を上げられるということは、逆にいえば動作クロックを下げても間に合うということである。例えばこれまで80%が処理待ちで、これを0%に近くできるということは、クロック速度を最大80%下げてもぎりぎり間に合うという計算になる。もちろんこれは極端な例だが、400MHz/1.5Vで駆動していたTriCore2を250MHz/1.1Vにするだけで、消費電力は55%節約することが可能である。また、電圧を下げるということはリーク電流に起因する静的な消費電力も下げられるわけだ。
加えて、SMTを使うことでキャッシュミスが遮蔽しやすいということは、キャッシュの容量自体を下げたり(これはダイサイズの削減になる)、外部メモリの速度を落としたり(これは直接コストの削減になるほか、消費電力も下げられる)といい事ずくめになる。
これがPentium 4とかだと、SMTをサポートした結果、内部の処理ユニットの実行効率が上がってしまい、TDPが増加するといった議論になっているわけで、同じSMTがここまで異なるアプローチに繋がるあたりが、PC用プロセッサとEmbedded Processorの違いを示しているとも言える。
 |
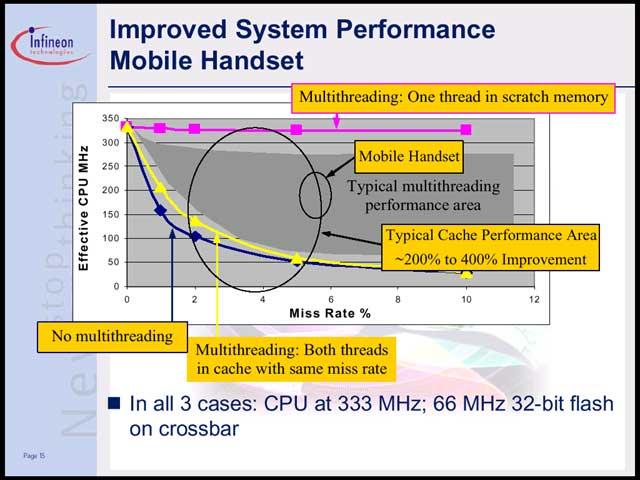 |
| 【写真16】SmartPhoneの場合、さすがにフラッシュメモリだけではワークエリアが足りないようで、ローカルメモリを別に搭載している。ただしコストが最重要視されるので、速度や容量は押さえ気味である | 【写真17】Memory Regident Taskを設けることで、劇的に効率が改善されていることが判る。ま、これはBest Caseの話で、実際は桃色と黄色の線に挟まれたグレーのエリアのどこかで落ち着くことになるのだが。どの辺で落ち着かせるか、は消費電力/コスト/性能をにらみながらのトレードオフなわけで、設計者を悩ませる事になるだろう |
●Array Processorで省電力?
 |
| 【写真18】NeoMagicのVice President of Corporate Engeneering担当Sanjay Adkar氏 |
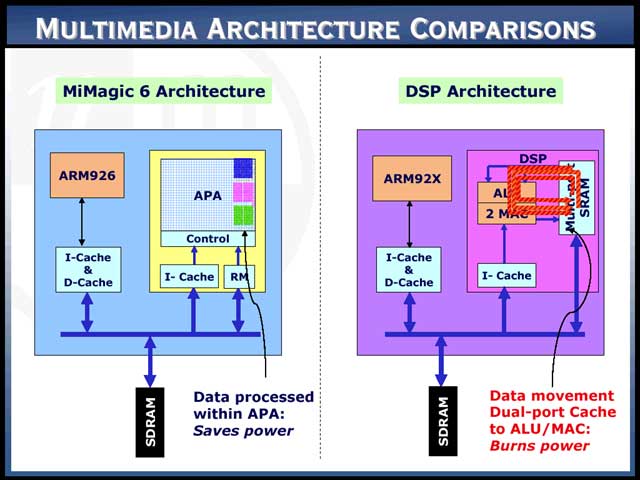
さてそのNeoMagicだが、現在PDAなどの携帯機器のマーケットに関して、急激に高い性能が求められつつある、と分析している【写真19】。こうしたマーケットに向けて今回発表されたのが、同社のMiMagic6である【写真20】。MiMagic“6”というからには、当然MiMagic1~MiMagic5まで存在する(が、なぜかMiMagic4は無い)ただ、MiMagic1~MiMagic5までは、基本的にARMコア(MiMagic3まではARM7、MiMagic5はARM9)に周辺回路を集積したというレベルで、他のARMベースのSoCと大きく違う部分は無かった。強いて言えば2Dグラフィックスの経験が長いだけに、ビデオ出力が充実している程度だろうか。ところがMiMagic6では、ちょっと別世界に踏み出してしまった。
 |
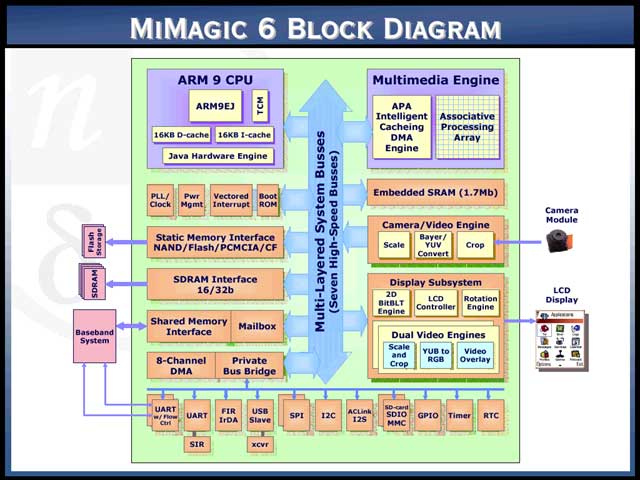 |
| 【写真19】Mobile 3Dとは、要するに携帯機器上で動く3Dゲームなどの事。もっともこの計算、ポリゴン類を全部ソフトウェアでまじめに計算した場合の数字な気がする | 【写真20】CPU自体はARM926EJで、つまりJava Hardware EngineというのはJazzelleの事である。ちなみに1.7MbのEmbedded SRAMで、320×320×16ディスプレイを外部フレームバッファなしに実現できる、としている |
Display Subsystem自体も、2Dに関してはBitBLTに加えてなぜか回転(Rotate)のアクセラレーションが入っており、また図には含まれていないが、1MPolygon/secの生成能力を持つ3Dアクセラレーションが搭載されるという力の入ったもので、これらをAHBでなく、マルチレイヤの高速インターコネクトで接続するという仕組みになっている。しかし、これらはAPAに比べると余禄のようなものである。
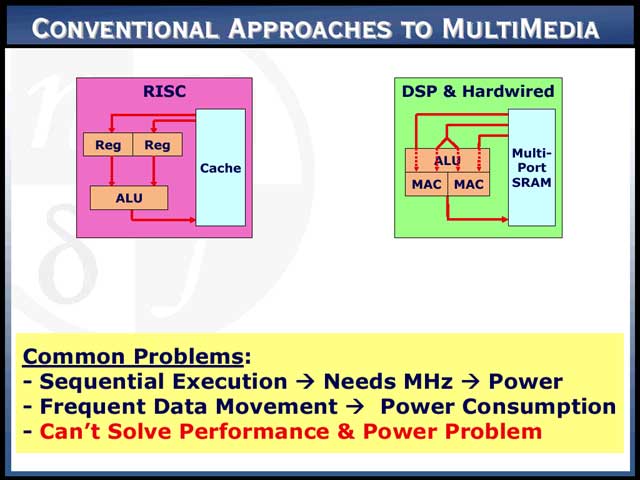
ではAPAとは何か? これを説明するためには、まず消費電力に関する同社の考え方を説明しなければならない。例えばRISCプロセッサの場合、キャッシュからデータをRegister Fileに読み込み、そのあと演算した結果を再びキャッシュに書き戻す。DSPあるいはハードワイヤードロジックならば、マルチポートSRAMからデータを読み込み、再びSRAMにデータを書き戻すという作業が出る。同社の主張は、「こうやってデータを移動するから消費電力が増えるのだ」という、斬新なものである【写真21】。同社のAPAの場合、記憶領域がそのまま演算領域となる。つまり、計算をするのに必要な元データはすでにAPAに格納され、演算結果も自動的にAPAに格納されるから、それ以上データを動かす必要がない。したがって、多くの演算をすればするほど、消費電力が大きく節約できるという仕組みである【写真22】。加えて言えば、シーケンシャル処理で性能を上げるためには、動作クロックをどんどん上げなければならず、それよりは並行処理を考えた方が効率的だ、という主張もここには含まれている。
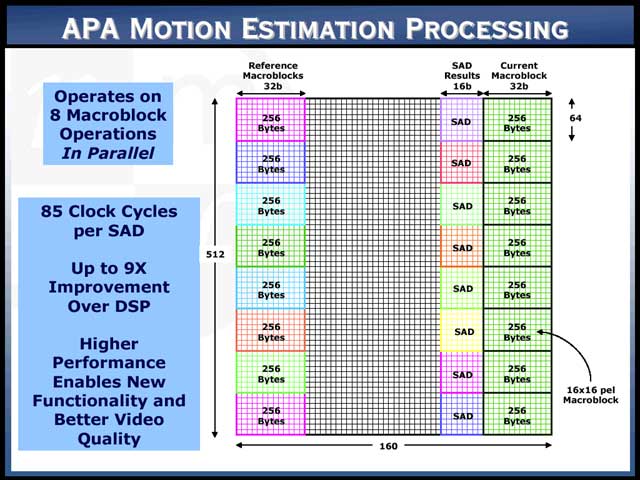
さて、APAの各々のエレメントは、1bitの記憶と、比較/書き込み/データ移動/シフトという処理が基本的には行なえる。このエレメントが512×160個並ぶ形だ。例えばV1にV2の値を加算する(V1,V2はベクタデータ)なんて場合、まずAPAに512個づつデータをロードし、ついでV2の内容をV1に一気に加算する。この際のレイテンシは48clockになるので決して高速とはいえないが、ポイントは512のデータを一気に処理できることで、この結果見かけ上のスループットは10.7add/clockほどになるという仕組みだ【写真23】。実際、MEを行なわせた例も示されたが、この場合1マクロブロックあたり85クロックで処理する事ができるとしており、その高速性を誇っている【写真24】。
実際、さまざまな条件での動画エンコードを行なう場合、必要なAPAの動作クロックとその際の消費電力が【写真25】に示されているが、確かに画期的に小さい事は事実。同社は「Embedded Processorの場合、性能指標はMOPS/mW(単位消費電力あたりの処理性能)にすべきだ」と主張しており、たしかにこの指標を使うとAPAは他を圧倒するほどの性能を発揮することになる。
実はこのMiMagic6のAPA、Conference前日のセミナーでもちょっと取り上げられており、「確かに性能はいいのだけれど、プログラミングが非常に難しい」という評判だった。これは簡単に頷ける。例えば【写真24】に戻ると、1回のSADの計算は確かにこんな具合で済むが、実際にはReferenceエリアはもっと広い(でないと検索にならない)訳で、データの移動を最小にしながらReferenceを入れ替えるためには、かなり頭を捻る必要があるだろう。また、単純にMEを全画面に掛け、ついでMCを全画面に掛け、差分をDCTに掛け、量子化し、……とやったら、激しくデータの入れ替えが起きることになるので、この8ブロックでME→MC→差分→DCT→量子化まで済ませてから、次の8ブロックをロードするといったテクニックも必要になる。まぁEmbeddedの場合、頭を捻るのも仕事のうちと言えなくも無いが、かなりチューニングしないと消費電力を下げるどころか性能が追いつかない可能性もありそうで、そういう意味ではピーキーなプロセッサと言えそうだ。
余談ながらこのプロセッサ、「どっかで見たことあったなぁ」と考えて気が付いたのが、昨年のMPF 2002でMicronが発表したYukonである。こっちは省電力というよりもむしろ高速化が主眼だったが、メモリエレメントがそのままプロセッサエレメントになるというのは、案外今後トレンドになってゆくのかもしれない。
 |  |
 |
| 【写真21】処理性能を上げるためには動作周波数を上げなければならないし、動作周波数を上げたらデータの移動速度も上げる必要がある。従ってこのままでは消費電力は減らない、という主張だ | 【写真22】APAはアレイ状の記憶領域で、同時に演算もこの中で行なわれる。従って、無駄なデータの移動がないから消費電力を低く抑えられる、という仕組み | 【写真23】NeoMagicはAPA用に四則演算/ビット処理/比較/端数処理/絶対値/シフト/参照/ブロック演算といったライブラリを既に用意しており、これらを組み合わせればMPEGのME(動き参照)やMC(動き補償)などは実現できるとしている。当然DCT/IDCTや量子化/逆量子化も可能だから、要するにMPEGエンコード処理のほとんどがAPAで済ませられる事になる |
 |
 |
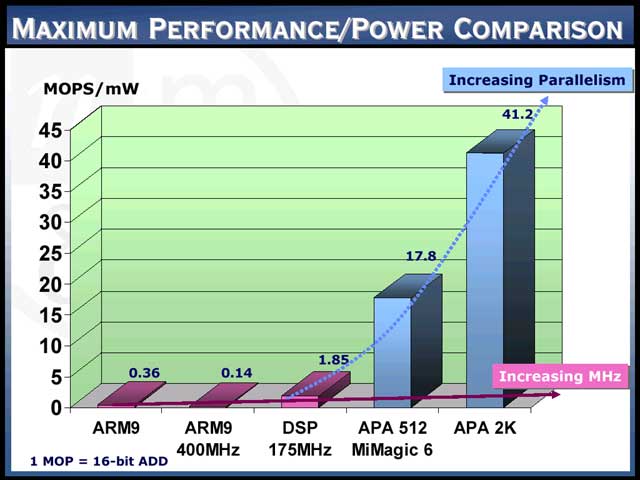 |
| 【写真24】これはちょっと納得できない部分がある。例えば32bitのDSPが4ピクセルのSAD計算を行なえるSIMD命令(8bitデータの絶対差を加算する)を持っているとしよう。そうなると、1個のブロックが64ピクセルだから、SADの計算には16回のSADの演算と、16回のSAD自身の加算が必要になる。SADの値は8bitを超える可能性があるので、16bit演算が必要だ。2個の16bit加算を行なえるSIMD命令もあるとすれば、合計の演算は16+8+4+2+1=31回になる。マクロブロック=4つのブロックだから(本当にはYUV411とかYUV420だと6つなのだが、今回は色成分は無視して輝度成分だけでMEをすると仮定しよう)となると、単純に4倍で124回の計算が必要である。各SIMD演算のスループットが1クロックなら、85clock対124clockだから、9倍もの差は出ない気がする。まぁ実際はSADの計算が5~6クロック、16bit加算が2クロック程度のものが多いので、これを加味すると440~500クロック程度になり、かなり差は開くが9倍にはちょっと遠い。数字の基準を知りたいものである | 【写真25】一番下、QCIF(176×144ピクセル)@15fpsのデータは、ありとあらゆるフィルタを突っ込んだといわんばかりの条件だが、それでも45MHz程度で済んでいるのが面白い。面白いといえば、動作周波数と消費電力が、相似の関係にはあっても、明確な比例関係にないのもちょっと興味深い。これはAPAのアーキテクチャに関係するのかもしれない | 【写真26】一番右の“APA2K”は、まだ登場していない、2,048行のエレメントを持つAPAの推定データらしい。図に被さるように書かれている2本の線は、「動作クロックを上げるよりも並列性を上げるほうが効率的!」という同社の主張である |
http://www.mdronline.com/epf/
□関連記事
【6月20日】【EPF2003】MIPSが、新32bitコアMIPS32 24Kを発表
http://pc.watch.impress.co.jp/docs/2003/0620/epf02.htm
【6月19日】【EPF2003】ARMが3つの機能拡張を発表
http://pc.watch.impress.co.jp/docs/2003/0619/epf01.htm
(2003年6月23日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.