1カ月集中講座
骨まで理解するPCアーキテクチャ(GPU編) 第3回
~ビッグGPUから効率重視へ、そしてGCNへと繋がるAMD GPUの歴史
(2014/4/18 06:00)
今週はATI/AMDのアーキテクチャの変遷を、またもや後藤氏の記事をフルに引用させていただきつつ、ご紹介したいと思う。
前回紹介した通り、シェーダの実装が始まったのはDirectX 8の世代である。もっとも後藤氏の記事をひっくり返して見たところ、ATIへの言及が本格的に始まるのはDirectX 9の世代からになる。ということでDirectX 7~8の世代をまず簡単にまとめておく。
DirectX 7世代に向けたATIの最初の製品が、初代「Radeon」あるいは「Radeon DDR」、「Radeon 7000」など色々なバージョンがあるが、「R100」コアと呼ばれているものである。このRadeonシリーズの基になるのはDirectX 6世代に向けた「ATI Rage 128」シリーズである。さらに、このRage 128の基になったのはTseng Labsの「ET6300」という、開発完了直前まで行なった製品であるが、Tseng LabsはET6300完成直前にグラフィック部門を丸ごと売却、これをATI Technologiesが買収した上でRage 128としてリリースした形になる。このRage 128は2本のピクセルパイプラインを持つ製品であったが、これをベースにT&L(Transformation & Lighting)ユニットを追加したのがR100コアとなる。もっとも単純にT&Lを追加したわけではなく、例えばテクスチャユニットはピクセルラインあたり1つだったものを3つに強化するなどの変更も加わっている。
もう1つの特徴は、すでにRage 128(より正確にはET6300)の時点で、同社の演算ユニットは24bit幅になっていたことだ。この結果、競合するNVIDIAの「RIVA 128」や「GeForce 128」などと比較した場合、16bitカラーでは性能が大幅に劣るのに、24bitカラーになると同等の描画性能を実現できた。ここでNVIDIA風に16bit演算器×2で32bit、とせずに愚直に24bit幅で実装するあたりは社風というか、考え方の違いであろう。このR100コアの機能削減版が「RV200」で、ピクセルパイプラインが1本になっている。
これに続き、R100をDirextX 8.1に対応させたのが次の「R200」コアで、これはRadeon 8500/9000/9200/9250といった製品としてリリースされた。もっともこの時期、ATIとしては続く「R300」世代の早期投入に注力していたことや、チップセットビジネスに参入すべくIGPモデルの開発を行なったりしていたことがあり、R200では大きな変革はない。ピクセルパイプラインという言い方はもう適当ではないのでシェーダ類の数を並べてみると
| ピクセルシェーダ | 頂点シェーダ | テクスチャユニット | ROP | |
|---|---|---|---|---|
| R100 | 4 | 0 | 6 | 2 |
| R200 | 8 | 2 | 8 | 4 |
といった具合で、大雑把に言えばR100の2倍の規模のシェーダを搭載するとともに、DirectX 8.1のShader Model 1.4に準拠させたのが主要な違いである。ただ前回も触れたが、Shader Model 1.4はDirectX 9のShader Model 2.0への先行拡張といった趣があり、その意味でもR200は次のR300までの過渡的なモデルとして差し支えないと思う。
続いて、DirectX 9世代の「R300」について言及していきたい。このR300世代はATIが2000年に買収したArtXの開発チームによる最初の製品という言い方もできる。そしてこのArtXのCEO兼社長だったDave Orton氏がATIのCOO(後にCEO)となり、AMD買収までの間同社を率いていたことからも、このR300世代が同社にとって重要な製品だったことを物語る。
そのDirectX 9世代のGPUの一般的な構造として想定されていたものはどんなものだったか、というのは下記の記事が分かりやすい。
実はここに出てくる図「DirectX 9世代GPUの推定図」は、R300の構造のダイジェストと言っても差し支えない。この時点では、まだNV30が突拍子もない構造(前回記事参照)になるとは予想されておらず、逆に言えばR300の構造は「普通に考えればこういう構造になる」というものを、素直に実装したと言っても良いだろう。
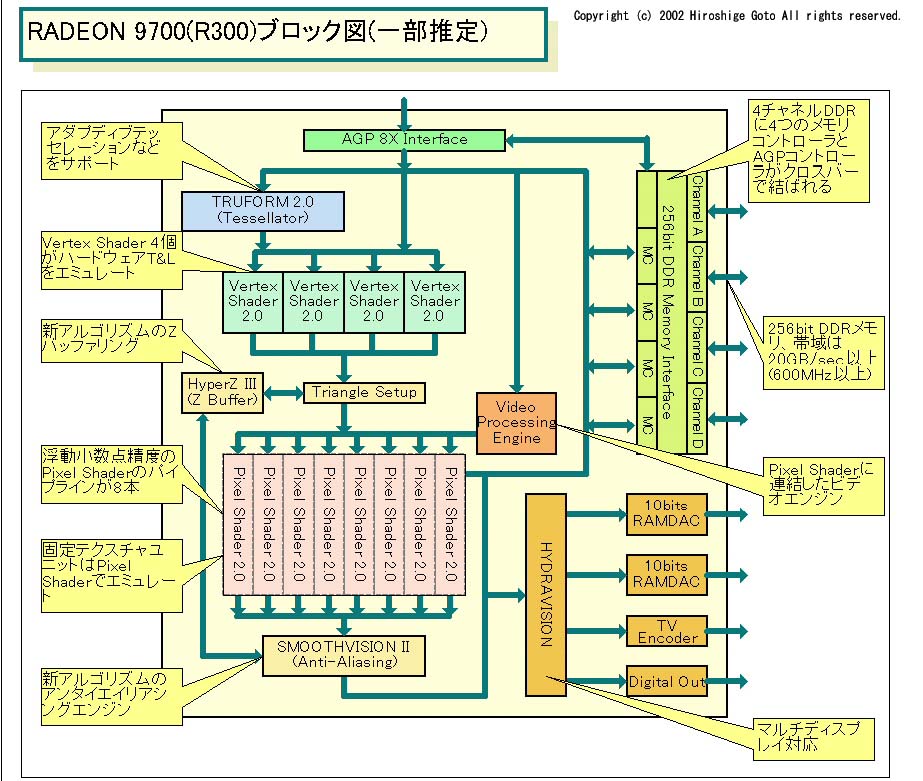{kind=link}
もっとも「素直」といっても、それは大きな視点で見た場合の話であって、内部的には色々な仕掛けが施されている。例えば、機能的には最大256チップまでパラレル接続できる。あるいはこちらの記事で言及されるように、ピクセルシェーダの機能をハードウェアではなくマイクロコードで実装するといった工夫がそれに当たる。とは言え、この時期はどの程度までGPUの用途がGPGPU的に広まってゆくか、あるいはGPUにオフライン・レンダリングのような要素が求められるか、まだ見極めがつかなかった時期でもあり、「とりあえずありそうな要素で、それほど実装が困難ではないものを入れておいて動向を見極める」というスタンスだったように思える。
ただR300そのものは、最新のプロセス(0.15μm)と256bit幅メモリという、2002年における最大限の構成になっており、トランジスタ数は1.1億個に達している。またシェーダ内部はNVIDIAと異なり、128bitのSIMD構成となっており、一応マルチスレッド化はなされていると見られたものの、効率は高くないと評されていた。
これが何を意味するかというと、「普通に考えた構成をそのまま実装する限り、どうしても効率は低めに推移するので、これで性能を上げるにはとにかく規模を大きくするしかない」ということになる。
現実問題として、0.15μmプロセスのままシェーダ数を増やす(=トランジスタ数を増やす)のは歩留まりの観点から無理なので、0.13μmへの移行は不可避と見られていた。だが、実際にはマイナーチェンジしたR350世代も引き続き0.15μmプロセスに留まった。アーキテクチャ的にもF-Bufferの搭載といった拡張はあるものの、オフライン・レンダリングはともかくリアルタイム・レンダリングに関してはR350とR300ではほとんど差がない。F-Bufferは、言ってみれば「オフライン・レンダリングも可能」というレベルの実装で、リアルタイム・レンダリングに関しては、あくまでもDirectX 9が要求する範囲に留めているからだ。

さて、ATIはこれに続き、「R400」というコアを開発していた。こちらの記事にもある通り、少なくとも2003年5月の時点では、このR400や後継のR500というコアはまだロードマップに載っていた。だが、このR400と初代R500は2003年9月ごろにキャンセルされ、2004年春に「R420」として投入されることになった。
理由は多数あったようだが、そのうちの少なからぬ部分がPCI Expressへの対応である。2004年というのはAGPからPCI Expressへの転換期であり、市場には両方のプラットフォームが流通していた。その上、PCI Expressを実装するには、当時のプロセスでは負担が大きすぎるダイサイズが必要になった。余談ながら、同時期にS3は「PCI Expressへの対応を行なうためには、ピクセルパイプラインを半減(4→2)させないと難しい」とまで言っていた。低価格向け製品では利用できるダイサイズはさらに小さくなるため、ピクセルパイプラインを減らさないと辻褄が合わなくなるほど大きかったということだ。
これもあってNVIDA/ATIともに、Bridgeソリューション(AGP/PCI Express Bridgeチップを別途搭載する形。GPUそのものはAGP対応のまま)を提供したが、NVIDIAがハイエンドまでこれを貫いたのに対し、ATIはR420でPCI ExpressとAGPの両方にネイティブ対応した製品をリリースする。ただし、この結果として、R420は性能こそR360の2倍となったものの、内部のアーキテクチャそのものはR360と余り変わらない(下記記事参照)。要するに引き続き力技のままであるが、これはプロセスを(やっと安定したTSMCの)0.13μmと、後に0.11μmに移行させたことで可能になった。

もっともこの頃から、ATIもシェーダを汎用的に使う、GPGPU的な要素を加味する必要性を感じていたようだ。後藤氏によるDavid Orton氏へのインタビューを読むと、次世代以降のGPUに仕込む要素を色々と検討していることが伺える。ただ、これに続いて発表される予定だった「R450」はキャンセルされ、「R480」となった後継製品は「Radeon X850」として2004年12月に発表されたものの、プロセスや内部構造は殆ど変わらないままで、若干コア/メモリの周波数が引き上げられた程度のマイナーアップデートに終わる。
プロセスルールが変わらないこともあってか、当然消費電力も増え、リファレンスカードも、ついに2スロット厚に進化(?)している。要するに、色々思い通りに進まなかったということだろう。これはNVIDIAも同じで、ATIは「Xbox 360」向けにR500ベースのカスタムGPUコアを提供している一方、NVIDIAは「PlayStation 3」(PS3)に「G70」の派生型とも言うべき「RSX」を提供しており、両社ともこちらの作業に忙殺された結果として、2005年後半まで業界に動きはなかった。これが動き出すのは、Xbox 360やPS3向けの作業が一段落してからとなる。
そして、2005年10月にATIは「R520」をリリースする。R520はShader Model 3.0に準拠で、Unified Shaderへの対応はDirectX 10が普及するまで先送りとされた。

そのR520は統合型シェーダではないものの、GPGPU的な使い方を意識したのか、統合型シェーダ世代を先取りしたかのような構成になった。ピクセルシェーダはこの世代では16基に過ぎず、これだけ見るとR400世代とあまり変わらないのだが、内部接続をリングバス構造にするとともにメモリを32bit単位の管理に切り替えたり、512-wayものマルチスレッディング(ATI曰くUltra-Threading)を実装したりと、内部は劇的に変化している。R520の性能を考えると贅沢な構成であるが、これは次の「R580」世代でピクセルシェーダを3倍(16→48)に増加させたことで、辻褄があった。この記事にもあるように、R580はR520と比べて20%ほどのトランジスタ数増加で100%の性能アップを実現しているが、これが可能だったのはR520の時点でR580の規模に耐えられるだけのベースを作っていたからである。
加えて言えば、R520の世代でATIはDirectX 10の統合型シェーダに必要となる要素技術をほぼ実装している(その当たりはこちらの記事に詳しい)。元々、Xbox 360に実装されたR500ベースのカスタムGPUコアは統合型シェーダ構成になっていたから、ここである程度見極めをした上で、必要となる技術を拡張させてR520/R580に実装、そこで動作を確認して、次の「R600」世代で統合シェーダ化、というシナリオを立てていたのだろうし、ここまではそのシナリオはうまく実行されていたと考えて良い。
AMDによる買収で方向性を転換
シナリオが違う方向に動き始めたのは、AMDによるATIの買収である。元々この直前から、AMDはコプロセッサを構想して、Torrenzaイニシアチブを立ち上げたりする動きを見せていたが、ATIの買収によってコプロセッサの大きな部分がAMDの手に入ったことになる。このコプロセッサの話そのものは次回紹介するので、今回はこのことがGPUに及ぼした影響を説明したい。
元々ATIはハイエンド品に関し、NVIDIAを上回る勢いで巨大なダイを製造して提供していた。これはR500世代も同じで、結果R520は90nmプロセスを利用して3億2,100万トランジスタで280平方mm、R580は80nmプロセスを利用して3億8,400万トランジスタで352平方mmものダイサイズとなっている。次のR600は、単に統合型シェーダを搭載するのみならず、シェーダの数も圧倒的に増えるため、65nmプロセスでないと製造できないと見られていた。
ところが、「Radeon HD 2900」として2007年5月に登場した「R600」コアは、80nmプロセスのままで統合型シェーダを320基搭載する“お化け”となった。トランジスタ数は7億に達し、ダイサイズは408平方mmである。これは、そもそもこのR600コアの設計はAMDによる買収前に完了しており、しかもその時点ではまだ65nmプロセスを使っての設計が間に合わなかったからであり、R600の低価格向けであるRV610/RV630コアに関しては65nmプロセスに移行している。


そのR600は、R500から比べると非常に多くの新機能を搭載した、意欲的な製品となっているが、後々まで影響を与えたこととしては、シェーダを従来の128bit SIMDから5-way-VLIW(VLIW5)に切り替えたことだ。この当時としては、これは並列性を高める上で効果的と判断されたのだろう。ATIもまたGPGPU的な使い方を模索する上で、当然さまざまな命令をシェーダに行なわせる必要があると考え、それを最小のコスト(=トランジスタ数)で実装するにはVLIWが効果的と判断したと思われる。このあたりが、32bitのALUをWarpを使って束ねる、という選択をしたNVIDIAとのアーキテクチャ上の差の1つである。後藤氏の記事にもあるように、このR600世代は320シェーダと表記されるが、これは1つのVLIW5を5シェーダと数えての話なので、VLIWのセットで言えば64個分でしかなく、R580から大きく増えているわけではない。
さて、転換点は次の「RV670」からやってきた。RVという型番は先ほどもちょっと触れたが、本来はハイエンドではなく、メインストリーム~バリュー向けの機能限定の派生型に付けられるものだ。ところがRadeon HD 3000番台の製品は「RV670」、「RV635」、「RV620」、「RV610」といったRVシリーズで占められ、唯一、「Radeon HD 3870 X2」にのみ「R680」という型番が割り当てられている。もっともご存知の通りRadeon HD 3870 X2は実際にはRV670が2つ搭載された製品であり、これはコアの型番というよりもボードの型番に近い。Radeon HD 3870そのものは、基本的にはRadeon HD 2000番台のプロセスシュリンク版であり、DirectX 10.1への対応のみで内部構造はほとんど変化がない(アクセラレータ類には多少改良が施されている)。トランジスタ数は若干減って6億6,600万個だが、ダイサイズは半減して190平方mmまで下がっている。加えてメモリバス幅も256bitに減らした結果、チップ原価とボードコストの両方を大幅に下げることに成功した。この目的はこちらの記事に詳しいが、要するに巨大なダイを猛烈な動作周波数で動かすのは、歩留まりの点でも消費電力の点でもそろそろ転換点であると認識されており、加えてAMDが「スイートスポット戦略」を打ち出したことでこれが加速された形だ。
AMDはこの当時CPUビジネスが決して好調とは言いがたかった上に、ATIの買収費用の償却も重くのしかかっていた。他方ATIが持っていたグラフィックビジネスは好調であり、利益もきちんと出ていた。となると、なるべくATIの売り上げと利益率を高めてAMD本体の財務状況を改善するため、開発費や生産コストが高くなる大きなダイのGPUから撤退し、手頃な大きさのダイ(2007年当時で言えば200平方mm程度、こちらの記事が参考になる)に商品を絞るのが、ビジネス上のリスクを減らし、利益を最大化する賢明な方法だったことも事実である。

この戦略はその後も引き続き採用される。続いて2008年には「Radeon HD 4000」シリーズが発表されたが、こちらもコアのコード名は「RV770」で、引き続きRVシリーズである。
プロセスは引き続き55nmを使い、トランジスタ数は9億5,600万個まで増えたがダイサイズは256平方mmとまだ手頃なサイズに収まっている。内部構造は下記の記事に詳しいが、シェーダの構造そのものは引き続きVLIW5を使いつつ、これを160個(AMDの数え方で言えば800シェーダ)に増強した。
その一方でリングバスを一般的なクロスバー・スイッチに置き換え、さらにNVIDIAに先んじてGDDR5メモリを採用したことで、メモリバス幅を増やさずにメモリ帯域を引き上げ、トータルとしての性能と効率を高めた方向だ。ちなみにリングバスを廃した理由はこちらの記事の最後に説明されているが、テクスチャキャッシュの構成を変えた結果、リングバスそのものが不要になったというわけだ。
もともとリングバスは、スケーラビリティを確保するには非常に良い解であり、IntelはSandy Bridge世代以降は内部バスをリングバスとしている。R520でリングバスを採用したのは将来の拡張性を考慮してのことと思われるが、スイートスポット戦略の実施により、そうした巨大ダイを作るプランが消えた結果として、一般的なクロスバー・スイッチで十分、と判断されたのだろう。

続いて登場の、DirectX 11世代一番乗りとなった「Cypress」も、やはりこの戦略の延長で設計されることになった。シェーダの基本的な構造としては引き続きVLIW5ベースであり、DirectX 11に対応した以外に大きな違いはない。全体としてみると、RV770のデュアルコアとでも言うべき構造になっており、どうしてもトランジスタ数は増えてしまい21億5,000万個に達した。幸いにも40nmプロセスを使ったことで、ダイサイズは334平方mmと、「それほど大きくならない」ように収まっている。処理性能の2.72TFLOPSは、登場した時点では間違いなくトップの性能だった。
むしろAMDにとっての懸念は、その演算性能を有効に使えるAPIが普及していないことで、CUDAの普及が着々と進んでいたNVIDIAと好対照を成していた。2007年頃からAMDは「Brook+」と呼ばれるGPGPU向けのライブラリの提供を開始していたものの、さっぱり普及しない状況で、こうなると如何に演算性能が高くてもただの宝の持ち腐れである。
ところが2008年にOpenCL 1.0がリリースされ(これはAppleのMac OS Xがプライマリだった)、これに続きもっと汎用的なプラットフォームとなることを目指してOpenCL 1.1の策定が始まる。またMicrosoftもGPGPUのAPIとしてDirectComputeを策定する。こうしたAPIによりCUDAに対抗できると踏んだAMDはまずOpenCLに注力することになり、CypressではこうしたOpenCLをフルにサポートするハードウェア構成になったことで、GPGPUのマーケットでNVIDIAを追撃できる準備が整った事になる。このあたりのアーキテクチャについては、下記記事が詳しい。

さて、AMDの目算としてはこの次に32nmプロセスに微細化という話であったが、TSMCの32nmプロセスは難航し、最終的にキャンセルされてしまったことで、次の28nmプロセスの熟成まで1年ほど間が空くことになってしまった。そこで、この間を使ってシェーダの再設計を行なったのが次の「Cayman」である。もっともこの時期、同時にGCNの設計も行なっていたと思われるが、こちらを先行できなかったのは、単に劇的な変更だからという以上に、40nm世代でGCNを実装しても十分な性能が確保できなかったからだと思われる。
そのCaymanは、シェーダの構成を4wayのVLIW(VLIW4)に切り替えた。最大の理由は後藤氏の記事にもあるように、命令並列度を下げることでコアの稼働率を高めることにある。なにしろプロセスが同じ40nmのままだし、ダイサイズを広げるのはスイートスポット戦略に反する。となると効率を上げるしかない。ただこれはある種、使い方を見極めた上で最適化するもので、柔軟性は失われる事になる。ただこのCayman世代は中継ぎだと割り切れば、むしろ手頃な製品とも言える。もっとも中継ぎと言いつつ、VLIW4は「Trinity」、「Richland」世代まで使われたので、開発コストに見合うだけの効果はあったとも言えるだろう。
翌2011年、AMDはGCN(Graphics Core Next)アーキテクチャを発表する。分散処理モデルに切り替わって、命令発行がCU(Computation Unit)に移される、VLIWを捨ててSIMDに切り替えるなど、内部構造が大きく変わっている。最大の狙いは、HSA(Heterogeneous System Architecture)との親和性が高く、GPGPU的に使いやすい構成にすることだ(この当時はまだHSAという組織がなかったため、FSA:Fusion System Architectureとなっている)。

このGCNを最初に搭載したのがTahitiこと「Radeon HD 7900」シリーズである。その内部構造は上記の記事でも解説されている。NVIDIAのSM(Streaming Multiprocessor)とCUは似ている点もあるが、GCNはもう少しHSAに向けて踏み込んだ構成になっている。そのキーワードはhQである。
Kaveriで初めて実装された、CPUコアとGPUコアを同列に扱えるキューの仕組みにより、CPU/GPUのタスク・オフローディングや連携が非常に容易になるが、このためにはGPU側がCPUと同じように命令を解釈して実行できないといけない。また、GPU全体で1個とか2個しかプロセッサ・エレメントが見えないと、粒度が大きすぎて効率が悪い。CUという仕組みは、HSAのあるべき姿を睨んだ上で、そこにぴったりはまるような演算性能と粒度を勘案して決められたスペックということになる。
結果、Tahiti以降の全てのAMDのGPUと、ほとんどのAPUにGCNが採用されることになったが、マイナーチェンジや演算以外の部分(例えばTrueAudioのサポート)に違いはあっても、CUそのものは同じものが継承されている。結果、要求性能に合わせてCUの数や周波数だけが増減する形で製品が構成されているのが現在のAMDのラインナップである。
ということでAMDの動向をやはり駆け足で紹介した。次回はこの短期連載の最後として、CPUとの連携という観点で説明してみたい。