 |


■後藤弘茂のWeekly海外ニュース■R600のパフォーマンスを低価格帯にもたらす
|
●Radeon HD 2900(R600)の演算性能をメインストリームにも
AMD(ATI)はメインストリーム向けのGPU「Radeon HD 4600(RV730)」ファミリを発表した。RV730は、Radeon HD 4800(RV770)ファミリのマイクロアーキテクチャをそのまま継承した、よりローコストなGPUだ。ボード価格では69~79ドルが予想価格帯となっている。
マイクロアーキテクチャ的にはRV770相当で、RV770に実装されたシェーダプロセッサの機能は、基本的にはRV730にもそのまま実装されているという。例えば、RV770では、シェーダプロセッサのクラスタである「SIMDコア」の中に、各シェーダプロセッサ間でデータを交換することができる16KBの「Local Data Share Memory」が実装されている。これは、そのままRV730にも引き継がれている。つまり、RV730もRV770と同じプログラミングモデルでプログラムできる。
AMDのRV730のプロセッサ個数は320で、これは、前世代のミッドレンジGPUである「Radeon HD 3800(RV670)」や前々世代のハイエンドGPU「Radeon HD 2900(R600)」と同じだ。1グラフィックスインスタンスを実行する単位であるシェーダプロセッサ「VLIW型の5-way Superscalar Shader Processor」の数はいずれも64プロセッサ。それぞれが5個のスカラ演算ユニットを備えるため、合計320演算ユニットとなる。同クロック時の演算パフォーマンスは、1年半前のR600と同レベルを達成できる計算だ。
つまり、AMD(旧ATI)は、80nmプロセスでハイエンドだったGPUを、1年半をかけて55nmプロセスでメインストリームまで持ってきた。そのダイサイズはR600の420平方mmから146平方mmと、約1/3となっている。低価格化を図ることができる理由は、ダイサイズを大幅に削減することができたためだ。
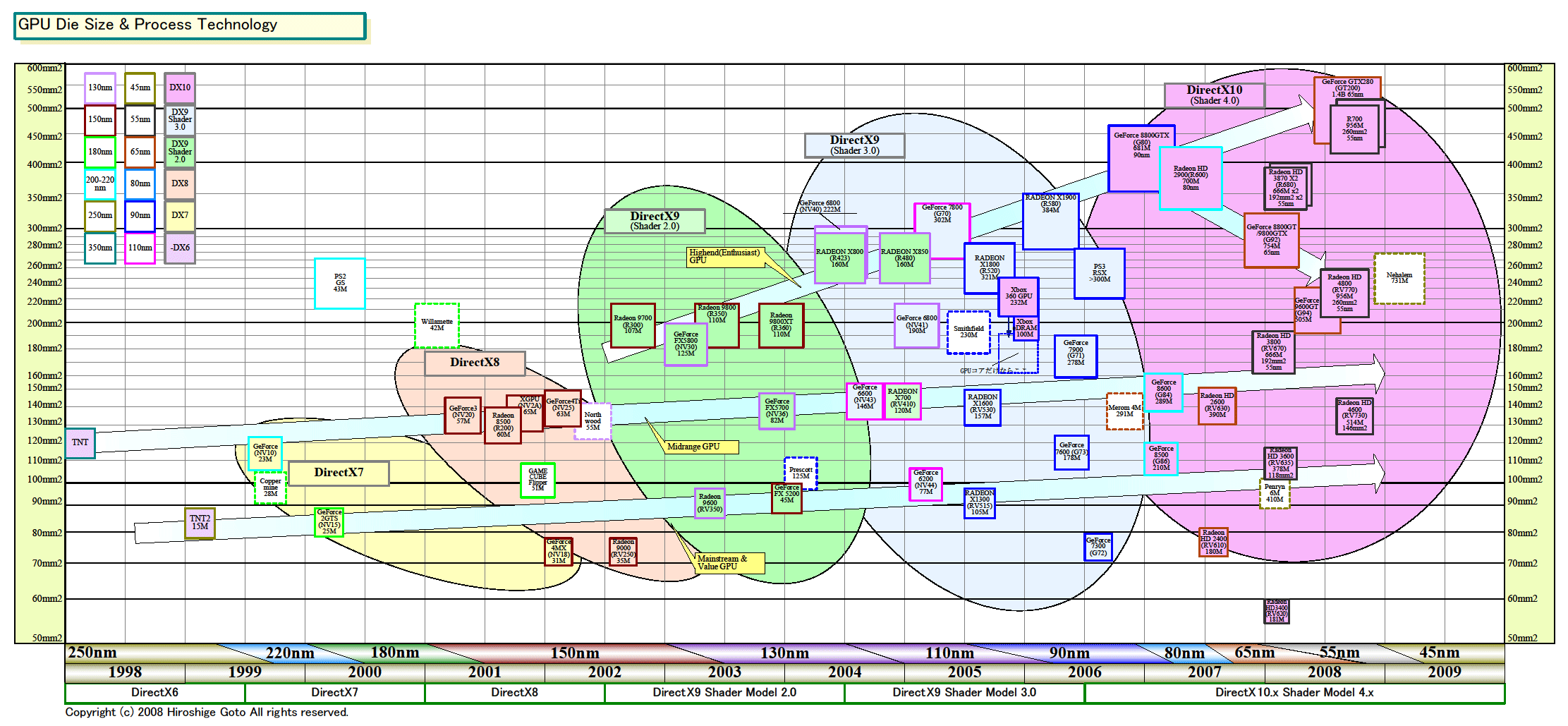 |
| GPUダイサイズとプロセス技術
PDF版はこちら |
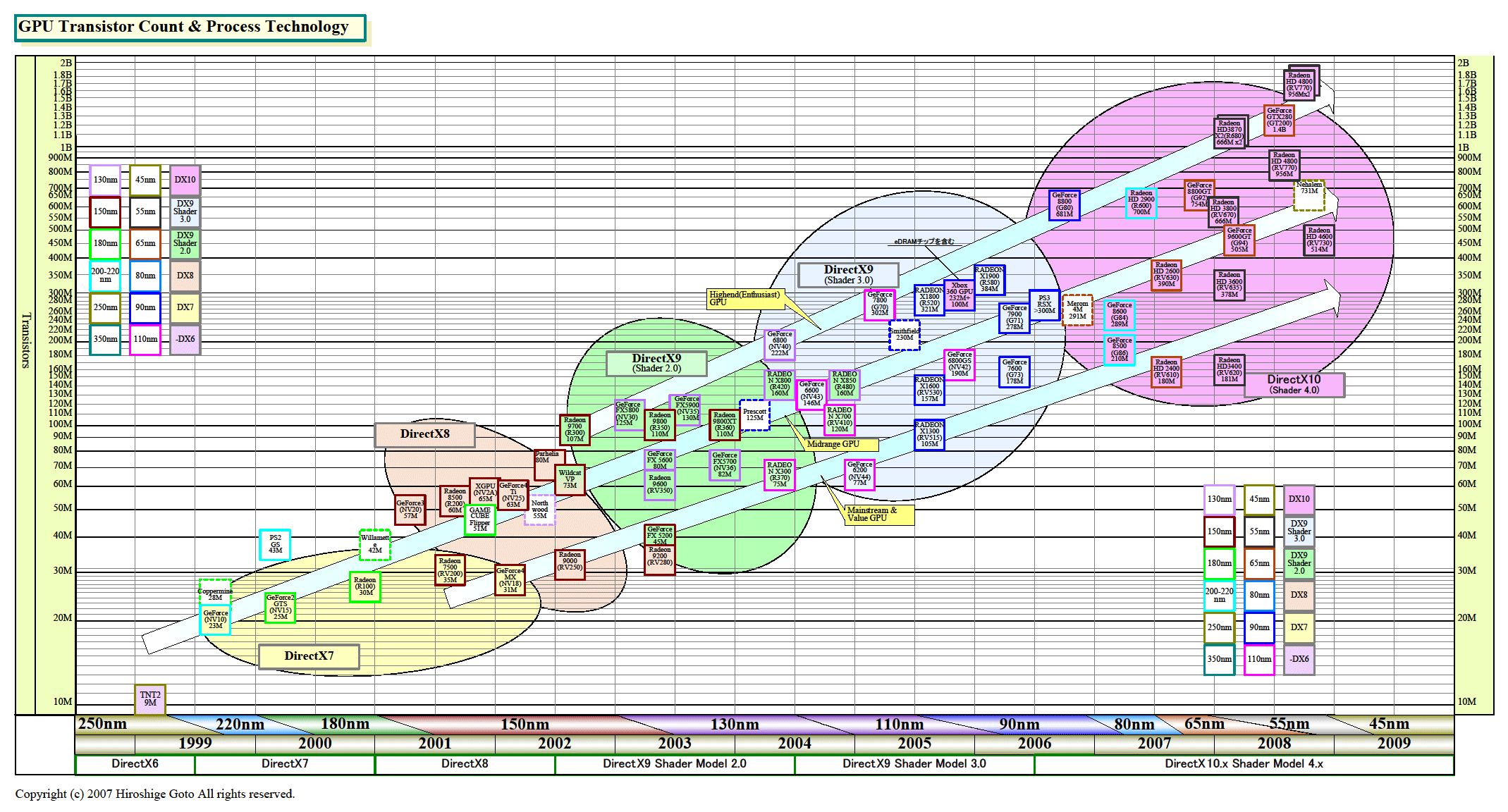 |
| GPUトランジスタ数とプロセス技術
PDF版はこちら |
 |
| メモリーテクノロジーのリーダーシップ |
 |
| Radeon HD 4600シリーズの特徴 |
 |
| HD 3600との比較 |
 |
| GeForce 9500 GTとの比較 |
 |
| HD 4600シリーズの位置づけ |
●DRAMコントローラを32bitにしてメモリ粒度を抑える
ダイを小さくした場合の問題は、パッドエリアが小さくなりメモリインターフェイスの幅を狭くしなければならないことだ。ローコストのメインストリームグラフィックスカードでは、高価なハイエンドメモリは使いにくいため、メモリ帯域がボトルネックになりかねない。
この問題を解決するため、RV730はDDR3/GDDR3をサポートする。DDR2に代わってDDR3をサポートすることで、低価格帯のメインストリームボードでも1.8Gtps(Transfer per sec)の高転送レート、28.8GB/secのそこそこのメモリ帯域を確保する。
DDR3のサポートには、実は難しいチャレンジがある。それは、DDR2よりメモリプリフェッチ幅が2倍になるからだ。DRAMのメモリセルの速度は、インターフェイスの転送レートほど向上しない。そのため、DRAMチップでは、メモリセルから読み出すデータの単位を大きくする「プリフェッチ(Prefetch)」で高速化を図っている。「プリフェッチ4」のDDR2では、メモリセルから4n個のデータを1クロック毎に読み出し、4倍のスピードのインターフェイスでチップ外部に出力している。これがDDR3では、プリフェッチ8で、メモリセルから8n個のデータを1クロック毎に読み出す。
プリフェッチ技術のおかげで、DRAMはメモリセル速度の制約にもかかわらず倍速化を続けることができた。しかし、その一方で、メモリアクセスの粒度(グラニュラリティ)は世代毎に倍増している。64-bit幅のDRAMインターフェイス当たりのアクセス粒度は、DDR2が32bytes、プリフェッチ8のDDR3では64bytesとなる。メモリアクセス粒度が大きくなると、メモリにアクセスする際の無駄が発生する可能性が高くなる。そのため、GPUのマイクロアーキテクチャを変更しないのなら、メモリアクセスの粒度は一定に保った方が効率的だ。そのため、RV730はDRAMコントローラを、従来の一般的な64-bit幅から32-bit幅にすることで、メモリ粒度を保っている。
シェーダプロセッサのクラスタであるSIMDコアの中のVLIWプロセッサの数は、アーキテクチャ図を見る限り、上位のRV770の16個の半分の8個となっている。つまり、1個のSIMDコアの中に8個のVLIWプロセッサがあり、40個の演算ユニットを備える。そのため、分岐粒度はRV770の半分の32となる。
●ATIがリングバスを諦めた理由
RV730は、シェーダプロセッサの規模的には前世代のRV670とほぼ同等であるのにも関わらず、同じプロセス技術でトランジスタ数を減らしてダイを76%にまで縮小することができた。RV670が6億6,600万(666M)トランジスタで192平方mmであるのに対して、RV730は5億1,200万(514M)トランジスタで146平方mmとなっている。
AMD(旧ATI)は、RV7xx世代でダイを縮小するために、いくつかの工夫を行なっている。中でも大きな改良は、内部バスの変更だ。
AMD(ATI)は、R6xx系で採用したチップ内部のリングバス(R5xxでも部分的に採用)を、RV770ではクロスバスイッチに戻した。その最大の狙いは、RV730のようなシュリンク版のチップのためだったという。AMD(ATI)で、R6xx/R7xx系のメモリコントローラと内部バスを設計したアーキテクトのFritz Kruger氏は次のように語る。
「R600アーキテクチャでチップを縮小しようとした時に、リングバスが一番の問題となった。リングバスがチップ上で大きな面積を取ってしまい、電力も食うためだ。そこで、リングバスのトラフィックを分析したところ、90%がテクスチャの転送だと判明した。R600では、テクスチャキャッシュ間の転送をリングバスを通していたためだ。
そうした分析の結果、次の製品では、テクスチャキャッシュの構成を変えることにした。RV770では、テクスチャL2キャッシュをメモリコントローラに、L1キャッシュをSIMDコア(シェーダクラスタ)に密接に接続した。2階層のキャッシュの間は、クロスバスイッチで結んでいる。R600世代から、すでにスヌープトラフィック用にキャッシュ間のクロスバスイッチがあったので、それを拡張した。
テクスチャ転送をクロスバへと切り替えたことで、リングバスから90%のトラフィックがなくなった。テクスチャを除けば、トラフィックはたいしたことがなかった。そのため、最終的にリングバス自体が不要となってしまった(笑)。これが、リングバスからクロスバへと戻した真相だ。
もっとも、RV770のクロスバは、以前の製品(R4xx系など)のクロスバスイッチとは、かなり構造が異なっている。以前は、中央にメモリコントローラとクロスバスイッチを搭載していた。R600ではメモリコントローラ自体を分散させてリングバスで結んだ。
今回のRV770でも、メモリコントローラは集中させず、4つに分散させている。ただし、各メモリコントローラを接続しているのは、リングバスではなく、比較的簡単なハブだ。単純な5スポークで、4個のメモリコントローラとPCI Expressとを結ぶ構造となっている。インテリジェンスは、全て分散したメモリコントローラ側に移して、ハブの機能を簡素化した」。
●上り方向だけのテクスチャトラフィックを分離
R4xx世代までのAMD(旧ATI)のメモリコントローラは、クロスバスイッチを内蔵し、プロセッサクラスタ群とDRAMコントローラ群を接続していた。そのため、メモリコントローラが非常に複雑になり、設計上のボトルネックとなってしまった。R600世代でリングバスに移行した最大の理由は、メモリクライアントとDRAMコントローラ数が多くなりすぎて、クロスバスイッチでは設計できなくなったためだった。AMDは、R500世代で部分的に移行し、R600で完全に移行した。
AMDのリングバスは片方向512bitsで双方向1,024bitsの広帯域バスだ。リング上に5つのリングストップ(1個はPCI Expressインターフェイス)を持ち、4個のメモリコントローラとシェーダプロセッサクラスタ接続する構成となっていた。AMD(旧ATI)は、接続するノード数をスケーラブルに増やしやすいという、リングバスの利点を期待して、このアーキテクチャを取ったと見られる。しかし、そのために、R600世代ではダイ(半導体本体)が大型化し、消費電力とコストが大きくなってしまった。
リングバスはフレキシブルでスケーラリビティが高い。しかし、GPU内のデータの流れは、じつは非対称である程度決まった流れがある。大量のデータを参照するが、モディファイしたデータを書き込む必要がないテクスチャ(プロシージャルテクスチャは除く)などのデータが大半を占めるためだ。GPUでは、メモリからプロセッサコアへの上りデータ量は膨大となるのに対して、プロセッサコアからメモリへの下りデータ量は相対的に少ない。
そこで、Kruger氏は、上りのテクスチャデータを、双方向でフレキシブルなリングバスではなく、片方向の専用クロスバに通してしまった方がコスト面で有利と考えたわけだ。テクスチャを分離すれば、残りのトラフィックは比較的少ない。各ノードをリングではなくハブで接続することで対応できる。RV770のアーキテクチャでは、10個のプロセッサクラスタも接続しなければならないはずだが、Kruger氏は5スポークのハブと説明している。おそらく、プロセッサクラスタは、4個のメモリコントローラノードにそれぞれ直結されていると推測される。
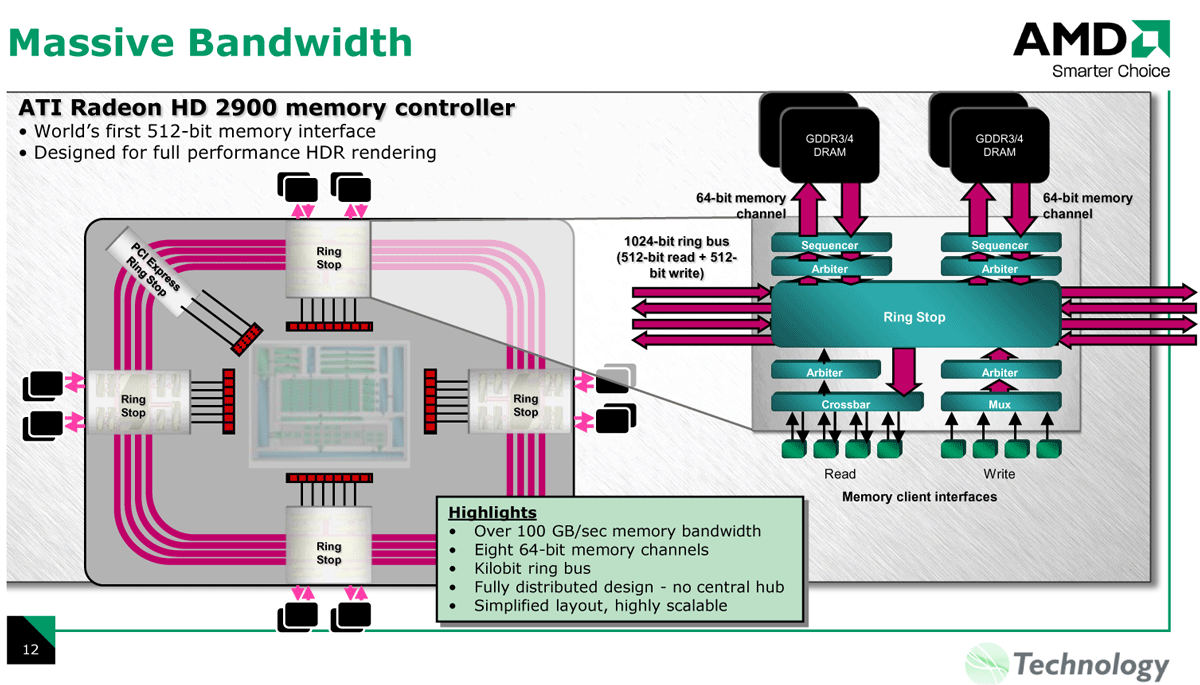 |
| ATI Radeon HD 2900のメモリコントローラ |
 |
| メモリコントローラの変遷 |
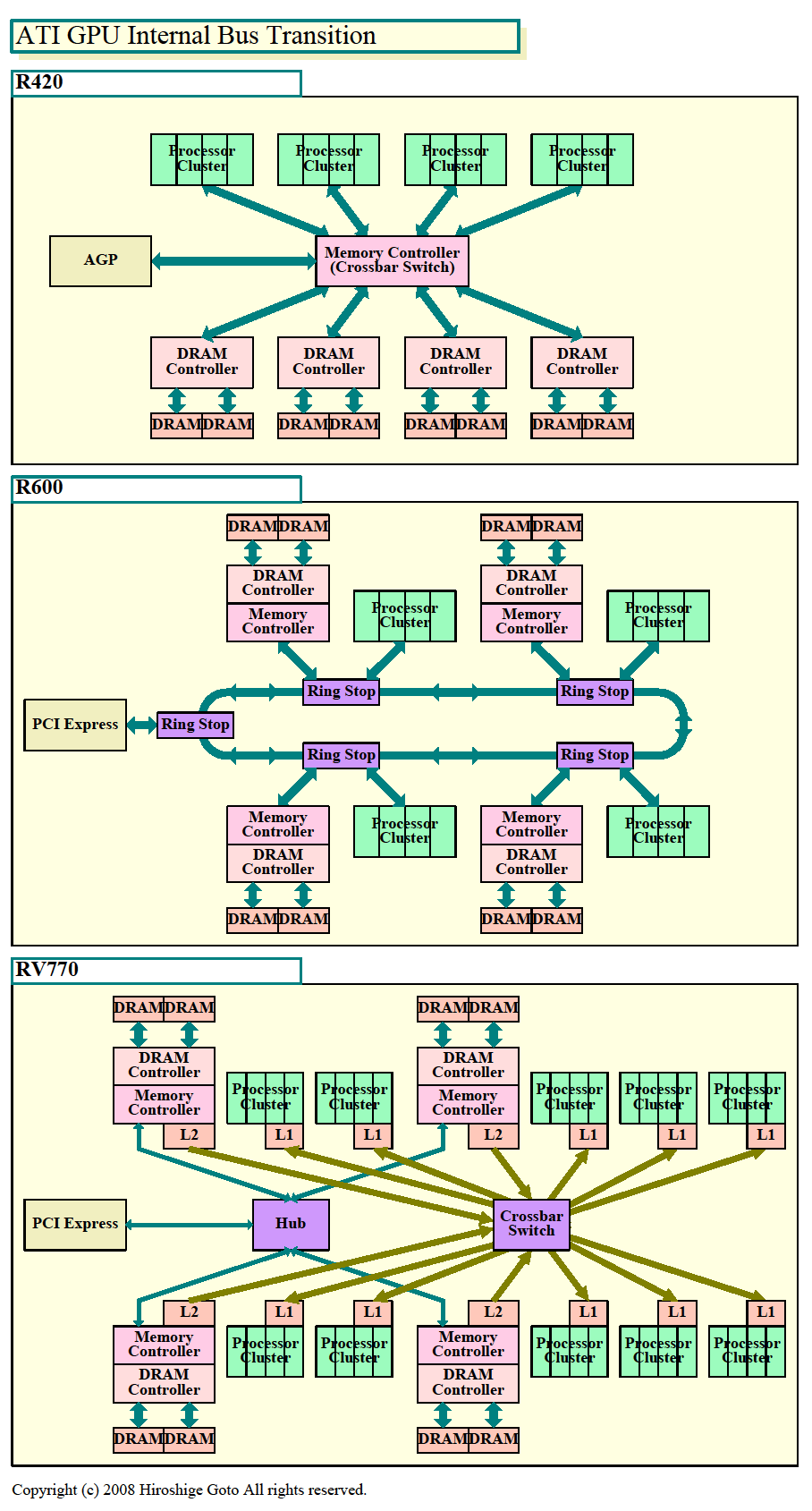 |
| ATI GPUの内部バスの変遷
PDF版はこちら |
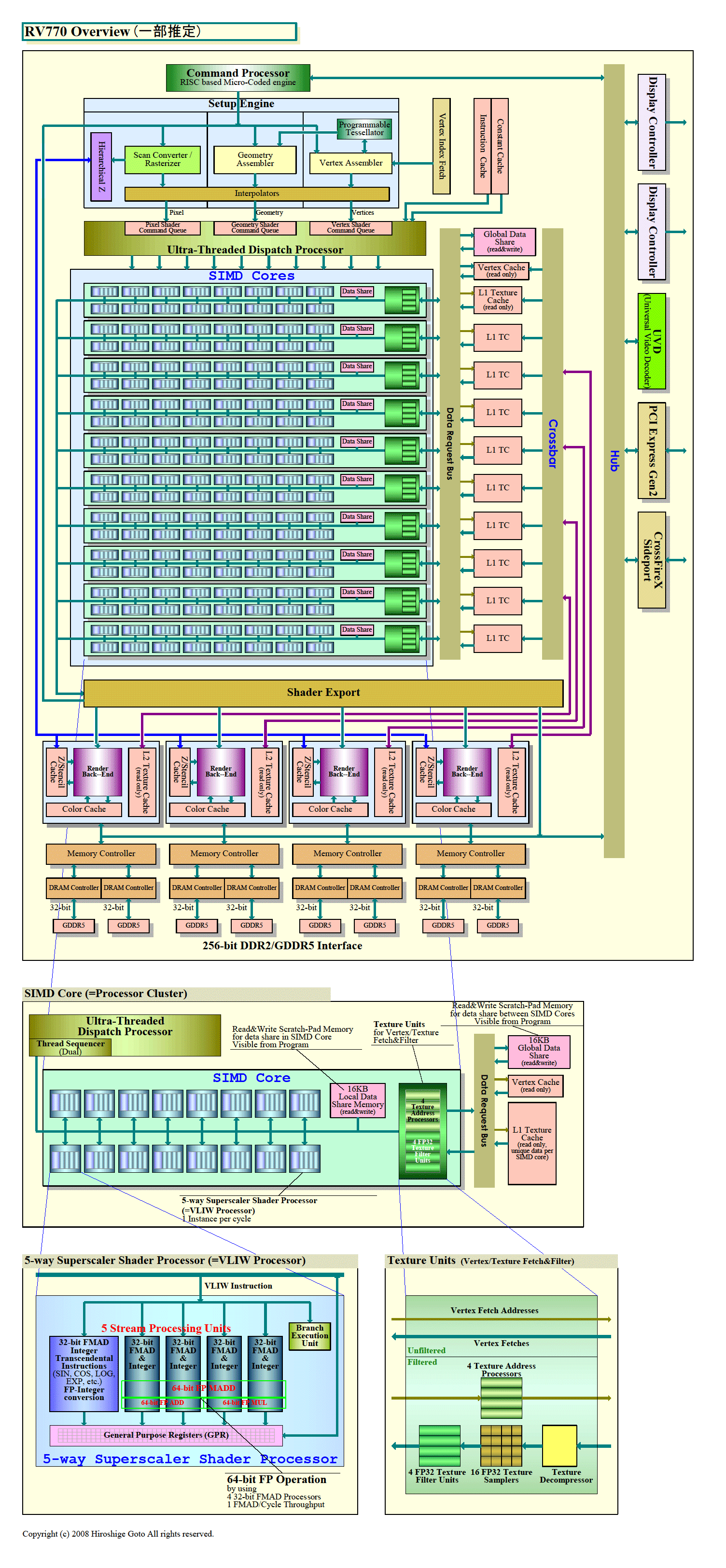 |
| RV770のオーバービュー(一部推定)
PDF版はこちら |
□関連記事
【7月2日】【海外】NVIDIAのGT200とAMDのRV770のどちらが優れているのか
http://pc.watch.impress.co.jp/docs/2008/0702/kaigai451.htm
【9月10日】【多和田】Radeon HD 4000世代初のミッドレンジ「Radeon HD 4670」
http://pc.watch.impress.co.jp/docs/2008/0910/tawada151.htm
(2008年9月12日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.