 |


■後藤弘茂のWeekly海外ニュース■CPUをはるかに追い抜くGPUのトランジスタ数
|
●GPUの進歩と半導体技術の関係
GPUの発展は半導体技術の発達と深く結びついている。今後のGPUの発展も、プロセス技術からある程度までは予想ができる。
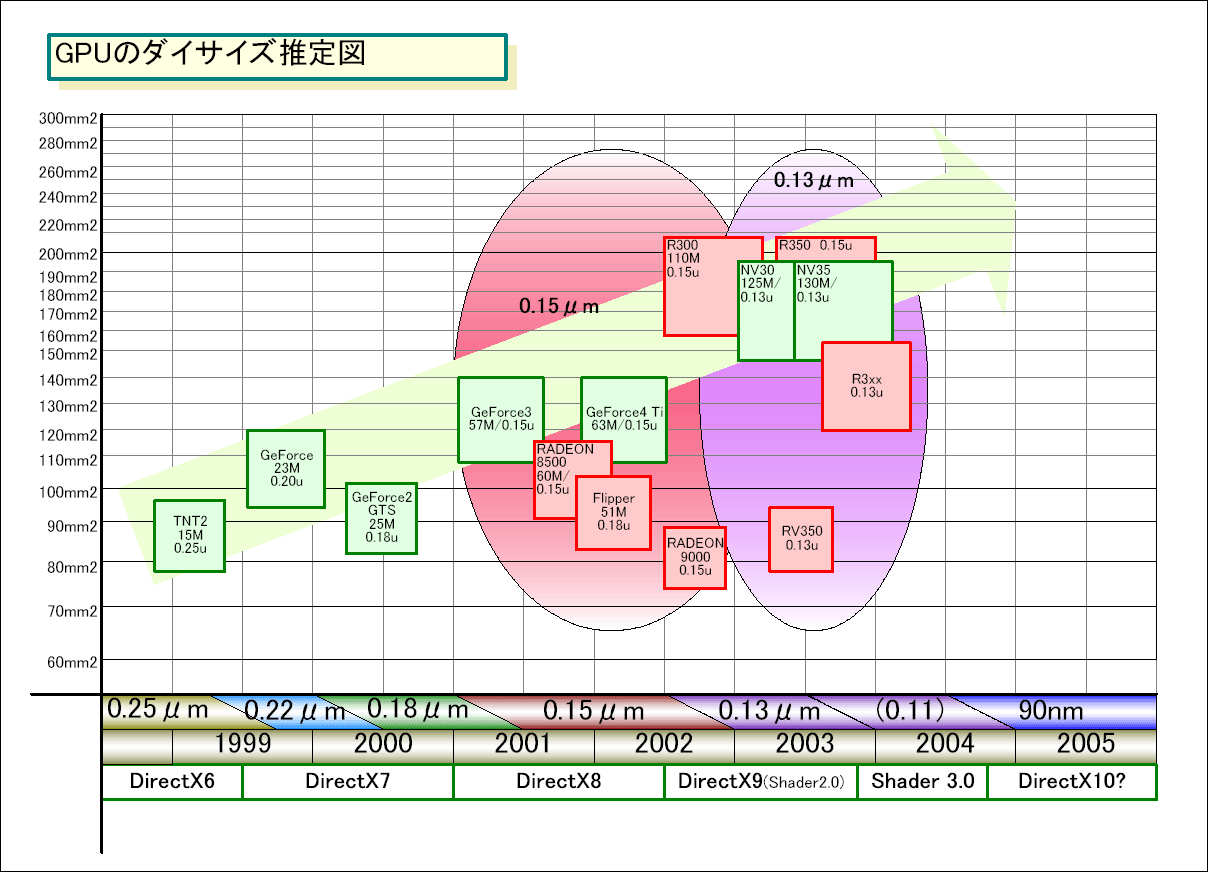
現在のDirectX 9世代のプログラマブルGPUは、0.13μmプロセスで花開いた。RADEON 9700/9800(R300/R350)とGeForce FX 5200(NV34)は、0.15μmで製造されている例外だが、少なくともハイエンドGPUに関しては、今年後半には完全に0.13μmへと移行するだろう。また、0.13μmプロセスで製造されているRADEON 9600(RV350)やGeForce FX 5900(NV35)なども、低誘電(Low-K)層間絶縁膜を使うことで、より高クロック化したバージョンが出てくる可能性がある。
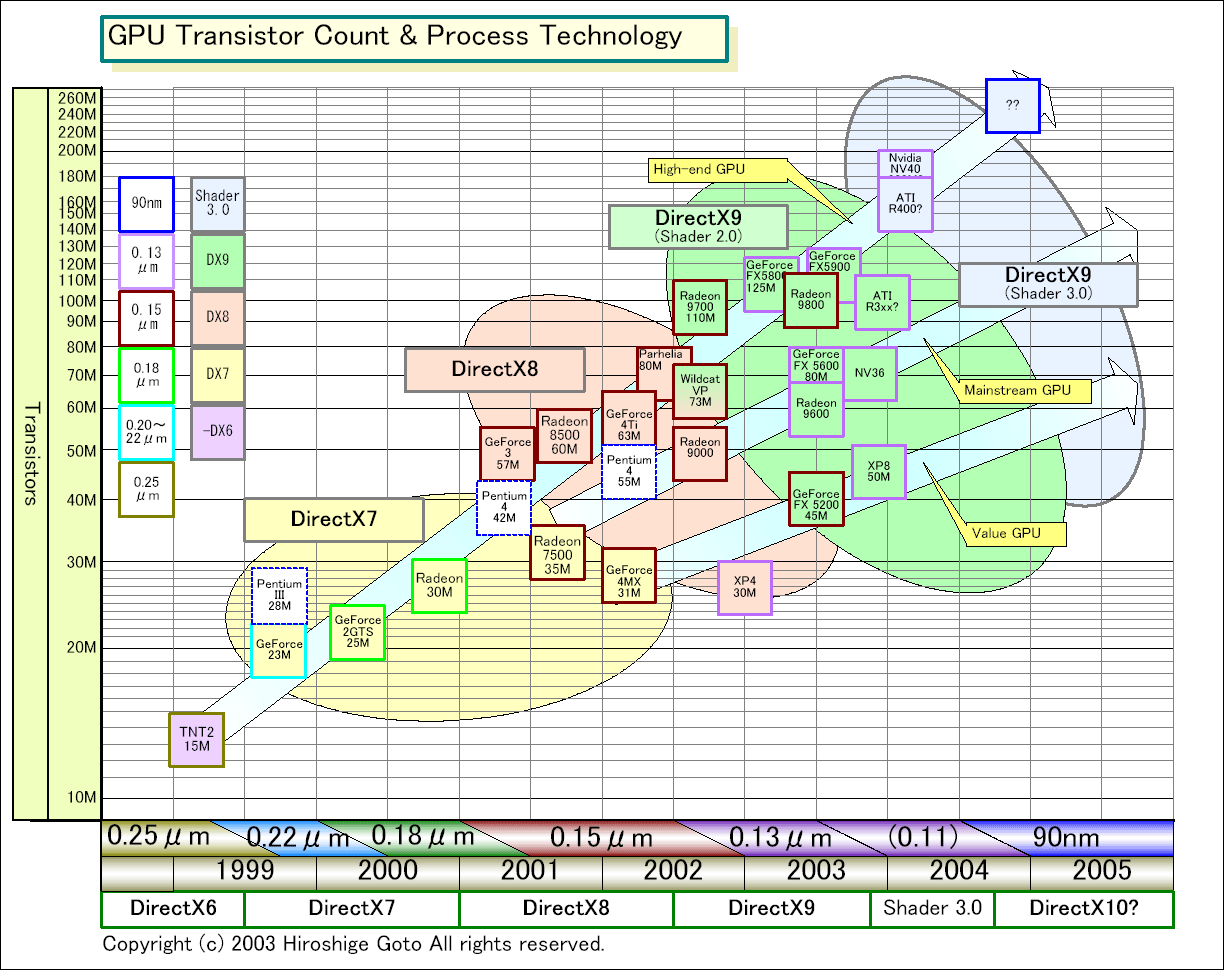
さらに、今年末には拡張0.13μm(0.11μmとも言われる)プロセスでGPUを製造できるようになる。おそらく、NVIDIAのNV40やATI TechnologiesのR400は、このプロセスで製造されるだろう。そうすると、ハイエンドGPUには最大2億トランジスタを搭載できるようになり、機能は大きく拡張される。現時点では、DirectX 9の全てのフィーチャを完全な形で揃えたGPUは存在しないが、0.11μmでは、そうしたGPUが登場し始めると思われる。アーキテクチャ的には、DirectX 9の拡張規格Programable Shader 3.0のサポートがこの世代になるだろう。
これが来年後半の90nmプロセスになると、さらに飛躍的に搭載トランジスタ数が伸びる。ハイエンドGPUクラスは、3億トランジスタを搭載するようになるだろう。NV50やR500世代がこれに当たる。90nm GPUは、アーキテクチャ的にはDirectX 10になると推測される。この段階では、NVIDIAだけでなく全GPUベンダーが、パイプライン構造を分解してShaderとピクセル出力を分離して来ると思われる。
●Low-k素材の採用で高クロック化を
ATIは、第2世代のハイエンドDirectX 9 GPUであるRADEON 9800(R350)を0.15μmでリリースした。しかし、同社が今年いっぱいを0.15μmのR350で乗り切るつもりだとは思えない。それは、今年後半になると0.13μmプロセスが成熟して来るため、歩留まりや動作速度で0.15μmを引き離すようになるからだ。そのため、ATIはR350系コアの0.13μm版も平行して設計していると考えるのが自然だ。
そもそも、GPUベンダーは、まだ大手ファウンダリの0.13μmプロセスのフィーチャをフルに使うことができていない。
「0.13μmもまだまだ改良の余地がある。現在は、(層間絶縁膜に)まだ0.15μmプロセスと同じSiOFを使っている。低誘電率(Low-k)材料は、誰も使っていない。銅配線の問題だけで手一杯だったからだ。だから、0.13μmプロセスも、今後数年に渡って性能を向上させることができるだろう。我々も、しばらくは、ほとんどのチップで0.13μmを使い続けるだろう」とATIのAndrew B. Thompson氏(Director, Advanced Technology Marketing, ATI Research)は説明する。
低誘電(Low-K)層間絶縁膜は、銅配線と組み合わせることで、配線での遅延を減らすことができる。配線間やレイヤー間の配線間容量(キャパシタンス)を減らすからだ。現在のロジックプロセスでは、配線遅延の方がトランジスタ遅延よりも問題になりつつある。そのため、Low-Kの採用はGPUの高クロック化につながる。また、配線をより最適化してGPUのダイサイズ(半導体本体の面積)を小さくして、製造コストを下げることもできる。
現在NVIDIAとATIのハイエンドGPUを製造している台湾ファウンダリTSMCの0.13μmプロセスは、Low-K膜の採用をうたっている。しかし、Thompson氏が指摘する通り、ATIのRV350やNVIDIAのGeForce FX 5800/5900(NV30/NV35)、GeForce FX 5600(NV31)などは、いずれもLow-kを使っていないようだ。また、TSMCを使っているCPUやチップセットのベンダーに聞いても、やはり現状ではLow-kを使っていないという。
その理由は、現在のCPUやハイエンドGPUのように、フリップチップ実装タイプのパッケージだと、パッケージングのプロセスでLow-K層が壊れやすいからだという。だが、この問題もようやく解決、そろそろLow-kが利用できるようになる。
「(Low-Kは)わりとすぐに使えるようになる。多分、あと6カ月くらいのうちだろう。正確にはわからないが、そう遠い時期ではない」(ATI、Thompson氏)
つまり、ATIは半年以内にはLow-K版0.13μmのGPUも投入する(可能性が非常に高い)というわけだ。
ちなみに、この0.13μm世代でNVIDIAはATIとは異なる選択をした。ATIもNVIDIAも、これまではTSMCでメインのチップを製造していた。だが、NVIDIAはIBMともファウンダリ契約を結び、今年後半からは製造の一部をIBMに移し始める。
これは、専業ファウンダリだけに頼るのはリスキーだとNVIDIAが判断したことを示している。プロセス技術では定評があるIBMに製造を委託した方がいいと判断したわけだ。最初の製品は、IBMの0.13μmプロセス「CMOS 8SF」を使うと見られる。
この判断は、明暗を分けることになるかもしれない。もし、TSMCがすんなり微細化を続けることができるなら、ファウンダリとして優れた能力を持つTSMCを使い続けた方がトク。しかし、TSMCがつまづくなら、IBMへ移行した方が正解かもしれない。まだ、結論は出ていない。
 |
| PDF版はこちら |
●今年末には0.11μmの2億トランジスタGPUが
プロセス世代としては、0.13μmの次は90nmになる。しかし、90nmの前にまだ拡張版0.13μmと呼ばれるプロセスがある。これは、実際には0.13μmのゲート長などをさらに小さくし、より高速化を可能にしたプロセスだ。「90nmが次のプロセスだが、エンハンス0.13プロセスも利用できるようになる。これは0.11μmに相当する」(ATI、David E. Orton デビッド・E・オートン社長兼COO)。0.11μmというプロセスノードはファウンダリのロードマップにはないが、0.11μmと呼ばれることが多い。
ではリニアにシュリンクするとして、この世代のGPUにはどれだけのトランジスタが搭載できるのか。半導体業界のロードマップの「International Technology Roadmap for Semiconductors (ITRS)」の最新版2002updateを見ると実際には0.11μmは0.107μm(MPU 1/2 pitch)で0.13μmからは面積で68%シュリンクとなる。
ダイサイズやトランジスタ数がわかっているR300(1億1,000万トランジスタ強/0.15μm/約216平方mm)やNV30(1億2,500万トランジスタ/0.13μm/200平方mm弱)を基準にすると、同じ200平方mmクラスのダイに0.11μmなら約1億8,000万~2億トランジスタを搭載できる計算になる。つまり、最新のR350(1億2,000万)やNV35(1億3,000万)よりも、5,000~8,000万多いトランジスタ数を見込むことができる。実際に、NVIDIAのDavid B. Kirk氏(Chief Scientist)は「2003年中には、多分2億(トランジスタ)になるだろう」と予告している。
このトランジスタ数だと、32bit精度の浮動小数点Pixel Shaderを8基搭載してもおつりが来る計算になる。そのため、現在の24bit対32bitという、Pixel Shaderの内部精度論争も、今年末から来年頭にはなくなると思われる。また、DirectX 9のスペックにある「アダプティブテッセレータ(適用型平面分割ユニット)」も、搭載したDirectX 9世代GPUが登場する(今は、Parhelia以外は搭載していない)と思われる。
つまり、現在はDirectX 9のフィーチャを完全に揃えたGPUは存在しないが、0.11μm世代ではようやくフルフィーチャのGPUになる可能性が高い。また、さらにプラスしてDirectX 9のShaderの拡張である、Programable Shader 3.0や、PCI Express x16もサポートし始めるだろう。Shader 3.0は、このプロセス世代を睨んだ拡張だと思われる。
動作周波数も向上する。この世代になると安定して500MHz品が採れると思われる。
 |
| PDF版はこちら |
●90nmプロセスでは最大3億トランジスタのGPUが
GPUの90nmへの移行は2004年中盤以降だというのが一般的な見方だ。0.13μmから2年後とすれば2004年末が穏当なラインだ。
「ファウンダリは2003年中から90nmの生産を始めている。しかし、最大の疑問はキャパシティだ。いつ大量生産に移れるのか私にはわからない。これはちょっと“ニワトリとタマゴ問題”に似ている。我々はファウンダリに『いつからハイボリューム生産ができる』と聞く。すると、ファウンダリ側は『いつからハイボリューム生産が必要になる』と聞き返す(笑)といった具合だ」「実際には、我々はファウンダリとロードマップを共有している。彼らと我々のタイミングを合わせている」(ATI、Thompson氏)
では、90nmではどれだけのトランジスタをGPUに搭載できるのか。これもR300とNV30を基準にすると200平方mm前後のダイに2億6,000万~3億トランジスタとなる。Shaderの数を現在の2倍にしてもおつりが来る。しかし、この世代でも、GPU側のピクセル出力は8ピクセル/クロック以上にはならないだろうとGPU業界関係者は言う。そのため、ハイエンドGPUはピクセル出力以上のShaderユニットを抱えることになるだろう。
また、この世代ではアーキテクチャもDirectX 10へと移り、Vertex ShaderとPixel Shaderも融合する可能性が高い。そうすると、GPUは、例えば汎用Shaderを24個搭載するといった形態になるかもしれない。増えたトランジスタで、GPUのアーキテクチャを根底から変えるというわけだ。
また、微細化により動作周波数も上がる。GPUはプログラマブル化によって、動作周波数は上げやすくなって行く。計算上では、90nm世代では600MHzクラス、ハイエンドは700MHz程度になるはずだ。
次の大きなジャンプとなる90nmに対する、GPUメーカーの期待は高い。90nmの立ち上げについて、ATIのThompson氏は次のように語る。
「多くのチャレンジが0.15μmから0.13μmへの移行ではあった。それは、銅配線への移行が大変だったからだ。しかし、90nmではそうした問題はないだろう。0.13μmで銅配線の問題を解決してしまったからだ」
90nmは2004年なら量産できるだろいうという声はよくきく。しかし、楽観はできないという意見も多い。というのは、プロセスの微細化はどんどん難しくなるという見方が強いからだ。90nmでも不安材料がないわけではないし、その先を見れば高誘電率(High-k)ゲート絶縁膜やSOI(完全空乏型を含む)など、多くの技術ハードルが横たわっている。そのため、専業ファウンダリはプロセス微細化で追いつけなくなり、Intelのような半導体ベンダーがに水をあけられるという見方がある。
NVIDIAがIBMを選択したのは、そうした背景があるからだ。しかし、GPUについては、ファウンダリとしてのIBMの現在の能力は未知数だ。
「非常に興味深い。なぜなら、誰もIBMで何を作れるのかわかっていないからだ。(回路が)高速なのか低速なのかすらわからない。だから、興味深く彼らの動きを見守っている」とATIのThompson氏は言う。
□関連記事
【5月12日】【海外】まだまだ疑問が残るGeForce FX 5900のアーキテクチャ
http://pc.watch.impress.co.jp/docs/2003/0522/kaigai01.htm
(2003年5月27日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp 個別にご回答することはいたしかねます。
Copyright (c) 2003 Impress Corporation All rights reserved.