 |


■後藤弘茂のWeekly海外ニュース■R680でデュアルダイGPUへと向かうAMD |
●CPUのデュアル化と似て非なるGPUのデュアル化
AMDによって、ディスクリートGPUのアーキテクチャの転換点が見えてきた。同社が投入する、次のハイエンド向け製品「Radeon HD 3870 X2(R680)」と、その先の「R700」は、GPUの今後の技術トレンドを示している。それは、GPUのデュアルダイ化だ。
今後、AMDのハイエンドGPUは、複数の中程度のサイズのダイ(半導体本体)で構成されるように変わって行くだろう。その先駆けが、デュアルのRadeon HD 3800(RV670)チップを1ボードに搭載したR680で、本格的なデュアルダイGPUが実現されるのがR700世代になると予想される。AMDは、FUSIONによってCPUとGPUを統合するが、その一方で、ディスクリートGPUにもアグレッシブな改革をもたらそうとしている。
GPUの“デュアル化”は、CPUの“デュアル化”と似通った部分がある。どちらも、電力消費の増大という問題に直面したことが一因となりデュアル化へと舵を切った。しかし、CPUとGPU、それぞれのアプローチには大きな違いがある。CPUはパフォーマンスを上げるために1ダイの上でCPUコア数を増やす“マルチコア”へと向かった。それに対して、GPUはパフォーマンスカーブを維持しつつコストを激減させるために、複数のダイでGPUを構成する“マルチダイ”へと向かう。GPUのマルチダイ化は、パフォーマンスと電力、コストのバランスを取るためのアプローチだ。
2個のRV670をオンボードでCrossFire構成にしたR680は、AMDにとってスタート地点に過ぎない。おそらく、この先の世代では、ハイエンドGPUは1個のチップパッケージの上に、2個のGPUのダイがMCM(Multi-Chip Module)で搭載された姿へと変わるだろう。IntelのMCM版クアッドコアCPUのように、2つのダイが密に接続され、最終的には両GPUダイに接続されたメモリを共有アクセスできるようになるだろう。単にGPUをデュアルにするデュアルGPUではなく、1個のGPUが2個のダイで構成されたデュアルダイGPUへと進化を遂げる。
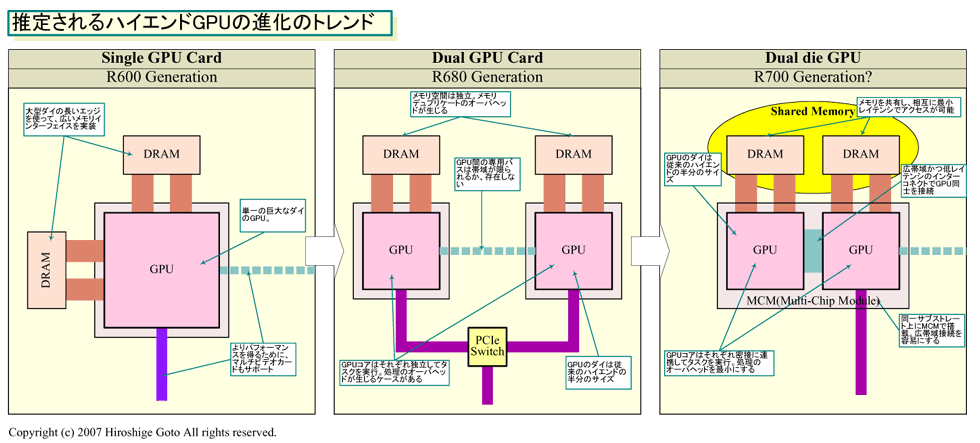 |
| 推定されるハイエンドGPUの進化のトレンド ※別ウィンドウで開きます PDF版はこちら |
●GPUのマルチコンテキスト化と連携するマルチダイ化
また、GPUのマルチダイ化は、GPUを取り巻くソフトウェア環境の大きな変化とも連動する。それは、GPUのマルチコンテキスト化だ。3Dグラフィックスが一部アプリケーションのものではなく、OSのUIの基本部分となり、GPUリソースが仮想化されることで、GPUではより小さな粒度でコンテクストを切り替える必要が増しつつある。また、GPUを非グラフィックス処理で使うGPUコンピューティングの動きも、GPUで走るコンテキストの数を増やす。
こうしたソフトウェア側の変化に対応するため、GPUはコンテキストの切り替えをハードウェアで高速に行なうことができるように進化しつつある。当然、その先に見えるステップは、GPUのサイマルテニアスコンテキスト化だ。そして、GPUのマルチダイ化は、そのための手段としても有効だ。CPUのマルチプロセッサのように、複数のGPUダイが、それぞれ別コンテクストを同時に走らせることができるからだ。
こうして見ると、AMDが向かっているGPUのマルチダイ化は、技術的には自然な流れに見える。しかし、複数のGPUダイでのメモリ共有など、アーキテクチャ的に解決しなければならない問題も多い。そのため、いつが適切なタイミングで、何が適切な技術なのか、判断するのが難しい。
いずれにせよ、流れとしては、GPUはモノリシックなシングルタスクシステムではなく、パーティション化されたマルチタスクシステムへと変わりつつある。そして、その流れの中で、パフォーマンスと電力、コストを最適化するために、少なくともAMDのハイエンドGPUはマルチダイ化の方向へと向かっていると思われる。
●マルチダイへと向かう圧力となるGPUの省電力化
AMDは、今春のCOMPUTEX時に、すでにハイエンドGPUでは2ダイ化することによって、消費電力を抑える方向へ向かうと説明していた。その当時、AMDのGPU製品部門を率いていたDavid(Dave) E. Orton(デイブ・オートン)氏(当時Executive Vice President, Visual and Media Businesses, AMD)は次のように語った。
「この市場(ハイエンドGPUを指しながら)に対しては、この製品(ミッドレンジGPU)を2個で提供するかもしれない。なぜなら、ハイエンドGPUでは消費電力面で大きくなりすぎるからだ。
消費電力は、基本的にキャパシタンス×電圧の2乗×周波数で導かれる。電圧は2乗で効果が大きく、我々はこれを下げ続けることで消費電力を抑えてきた。ところが、今では電圧は1Vちょっとで、低下が止まってしまっている。一方、周波数の方は継続して上がり続ける。だから、電力を抑えることは、ダイをシュリンクすることでしか達成できない。キャパシタンスを減らすわけだ。
そのため、ダイをシュリンクせずに、20mm角(400平方mm)の65nmプロセスと45nmプロセスのチップを作るというアイデアは、電力の面で歓迎されないだろう」
プロセッサの消費電力のうちアクティブ成分は「キャパシタンス(Cdynamic)×電圧(Vdd)の2乗×動作周波数(F)」に比例する。GPUでは、周波数はパフォーマンスを維持するために下げることが難しい。そして、駆動電圧は、現在、プロセスが微細化してもほとんど下がらなくなってしまっている。そのため、アクティブ電力を左右する3つの要素のうち、微細化によって下げることができるのは、Orton氏が指摘したようにキャパシタンスだけとなっている。そして、それでは十分ではない。
●プロセス世代毎に増えるGPUの消費電力
プロセスが1世代微細化すると、各トランジスタ毎のキャパシタンスは0.7倍に減る。しかし、1世代の微細化によって、トランジスタのサイズは0.7倍の2乗の0.5倍に縮小する。そのため、微細化すると同じダイ面積に約2倍のトランジスタが搭載できるようになる。つまり、同じサイズのチップでは、1世代の微細化でトランジスタ数は2倍になるのに、トランジスタ当たりのキャパシタンスは0.7倍にしか減らない。
そのため、同じサイズのチップのキャパシタンスは、約1.4倍に増えてしまう。つまり、電圧と周波数が同じなら、1世代微細化すると、同じダイサイズのチップの消費電力は1.4倍に増える。簡単に言えば、今までと同じサイズのチップを作り続けるなら、プロセス世代毎に消費電力は1.4倍ずつ増え続ける。90nmから65nm、45nmへと移行すると、電力は1.4倍、2倍へと増えてしまう。Orton氏が指摘していたのは、この問題だ。
これにさらに電力のうちのスタティック成分であるリーク電流(Leakage)の増大の問題が加わる。その時々でGPUメーカーが選択するプロセス技術によって、リーク電流量には違いがある。しかし、現状ではリークは膨大な比率に上がっており、特にパフォーマンスを上げようとするとリーク電流が多い。そのため、パフォーマンスオリエンテッドなハイエンドGPUは、アクティブ成分にプラスしたリークによる電力増大に苦しめられている。
GPUの電力消費の増大は、このように半導体プロセスの根本的な壁に根ざしているため、容易には解決がつかない。そこで、GPUアーキテクチャの抜本的な改革が必要になる。それが、AMDが向かっているマルチダイ化だ。
●ダイ単位のON/OFFにより負荷に最適化した電力制御
もっとも、ダイを小さくすることで1個のGPUダイの消費電力を抑えても、複数のダイでハイエンドビデオカードを構成するなら、カード全体の消費電力は高くなってしまう。マルチダイ化によって、どうやって消費電力を抑えるのか。今春の時点でAMD執行副社長だったOrton氏は、次のように説明していた。
「コンピュータの電源を入れると、(2つのGPUチップが)協調して動くようにする。しかし、通常に稼働している時は、使われていないGPUがただアイドル状態になるのではない。電力管理の面から、マルチコアCPUのように、ローパワーモードでは(アイドル状態の)コアは走らせないでおく。そして、よりパフォーマンスが必要な時だけ、コアをターンオンする。コンセプト的には、これと似たような方法が考えられる」
現在のマルチコアCPUは、負荷が低い時は、アイドル状態のCPUコアを、スリープ状態にすることで消費電力を押さえている。GPUも、マルチチップ化することで、そうした個別の省電力制御が容易になる。例えば、Windows VistaのUIだけを走らせている時は1個のGPUダイだけを走らせ、3Dアプリによって負荷が高まった時にだけ2個のGPUダイの両方をオンにするといった制御が予想できる。パフォーマンスが不要な時は、電力消費を1個のダイだけに抑えることで、電力の消費を最適化するというアイデアだ。
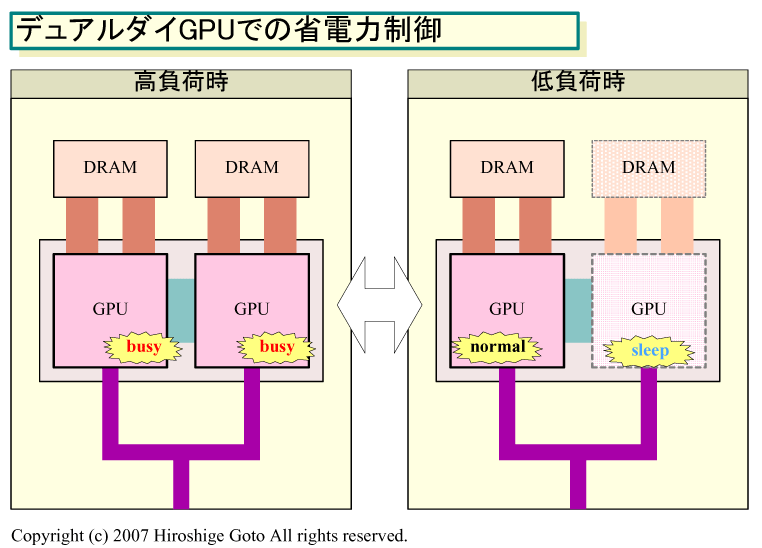 |
| デュアルダイGPUでの省電力制御 ※別ウィンドウで開きます PDF版はこちら |
●コストの増大もGPUのマルチダイ化への圧力に
もちろん、GPUでもCPUのように、オンダイでコアの半分をスリープさせる制御を行なう選択肢もある。しかし、GPUの場合、ダイを分割した方が有利な点がある。それは、製造コストの低減だ。
GPUは、DirectX 9世代から、本格的なプログラム性を備えたプログラマブルシェーダプロセッサを搭載し始めた。DirectX7までのGPUは、プログラム性を持たない固定機能ユニットで構成されていた。固定機能ユニットは、柔軟性を持たない代わりに効率が高いため、トランジスタ当たりの処理能力は高かった。しかし、プログラム性の高いシェーダは、柔軟な代わりに効率が悪い。そのため、同じトランジスタ数のGPUを、固定機能ユニットからシェーダ中心の構成に変えると、トランジスタ当たりのパフォーマンスが落ちてしまう。
そこで、GPUベンダーは、DirectX 9世代以降は、GPUをより大きくし、トランジスタ数を増やすことでパフォーマンスを強化した。DirectX 8世代のハイエンドGPUのダイサイズ(半導体本体の面積)は大きくても150平方mm程度だったのが、DirectX 9 Shader Model 2.0世代では200平方mm前後に増えた。ダイはDirectX 9 Shader Model 3.0世代で300平方mmに達し、DirectX 10世代ではついに400平方mmを超えてしまった。これは、CPUで言えばMPサーバー向けハイエンドCPUのサイズだ。
ダイが巨大化すると消費電力が増大するだけでなく、製造コストが激増する。大型ダイでは、1枚のウェハから採れるダイの数が減る。さらに、半導体チップは、製造過程でのウェハ上の欠陥のために不良ダイが発生してしまう。ダイが大きくなると、1個のダイエリアに欠陥が含まれる可能性が増えるため、良品の率(歩留まり)も悪くなる。つまり、ダイの面積が2倍になると、製造できるチップ個数は1/2ではなく、1/3あるいはそれ以下に減ってしまう。その結果、GPUコストが増大する。
●GPUの収益の足を引っ張るGPUダイの肥大化
ハイエンドGPUでは、パフォーマンス競争によってダイの肥大化を続けた結果、コストの激増を招いた。その結果、ハイエンドGPUは、GPUベンダーにとって稼ぎ頭ではなく、利益を圧迫する高コスト商品になってしまった。GPUベンダーは、この問題を解決しようと、ハイエンドGPUを、より高く売れるワークステーショングラフィックスやGPUコンピューティング用途に売り込み続けているが、見合うだけの利益を上げているかどうかはわからない。そのため、GPUベンダーは、ハイエンドGPUのコスト効率の見直しを行ない始めていた。
実際、旧ATI TechnologiesがAMDと合併した直後、AMDが行なった2006年12月のアナリスト向けカンファレンス「Analyst Day」では、GPU事業の収益性が焦点の1つとして取り上げられた。これを見ると、CPUの利益は15%であるのに、GPUは-3%と極めて悪いことがわかる。つまり、合併AMDの足を引っ張るのは旧ATIのGPU部分というわけだ。そして、AMDはGPUの収益性の改善のために、ダイサイズの縮小などを行なってゆくと説明した。その答えが、ハイエンドGPUのマルチダイ化ということになる。
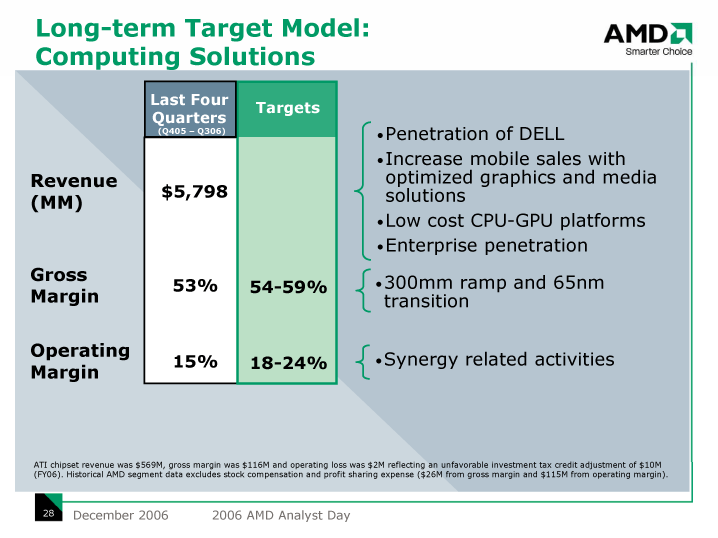 |
| コンピューティングソリューションにおける長期ターゲットモデル ※別ウィンドウで開きます PDF版はこちら |
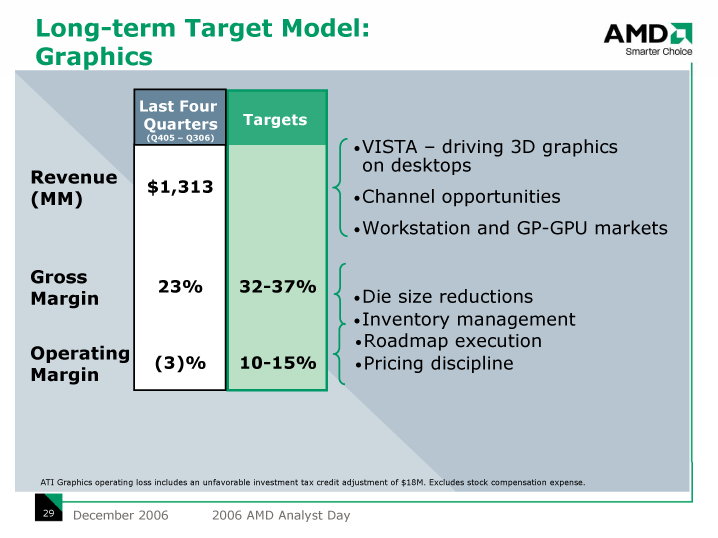 |
| ビデオ機能における長期ターゲットモデル ※別ウィンドウで開きます PDF版はこちら |
もっとも、ATIはAMDと合併する前から、すでにデュアルダイ化の方針を固めていた。実際、Orton氏はATIの社長兼CEOだった2006年6月のCOMPUTEX時に、すでにその方針について語っていた。
「これまで、GPUは、14mm角(約200平方mm)、17mm角(約300平方mm)、20mm角(400平方mm)と大きくなってきた。しかし、25mm角(約600平方mm)は現実的ではないと思う。20mm角(400平方mm)が業界的には限界で、ダイサイズの大型化は、水平になるだろう。我々は、これ以上大きなチップを作ろうとは思わない。
CPUの世界では、すでにそうした方針転換を行なっている。単なるパフォーマンスではなく、パフォーマンス/電力へと転換した。GPUもこれからは、パフォーマンス/電力に非常にフォーカスして行かなければならない。そのため、ダイサイズは右肩上がりにはできない。
グラフィックスの利点は、グラフィックスタスクがパーティション化が容易なので、GPUもよりコストエフェクティブにできることだ。1チップで処理する代わりに、2チップで処理することで、もっと低コストにできる可能性がある。業界として見ると、価格パフォーマンスカーブを上げなければならないことは確かだ」
つまり、AMDの現在のマルチダイGPUへの方向性は、AMDとATIの合併の結果突然出てきたものではなく、ATI時代からすでに既定の路線として敷かれていたと思われる。そして、合併後に財政が逼迫したAMDにとって、GPU部門の収益改善が急務となり、その動きが加速されたと推測される。
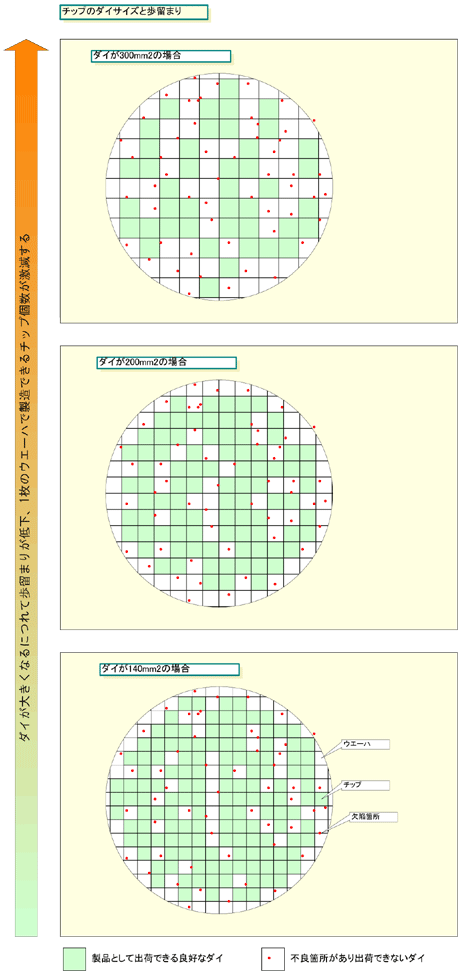 |
| チップのダイサイズと歩留まり ※別ウィンドウで開きます PDF版はこちら |
●ダイサイズを大幅に縮小したRV670コア
巨大なダイのハイエンドGPUを作る代わりに、中程度のダイサイズのGPU 2個でハイエンドGPUを構成する。Radeon HD 3800(RV670)コアは、この手法によるコスト削減の点では理想的なチップだ。AMDはRV670で、ほぼ同じシェーダプロセッサ構成だった前世代のハイエンドGPU「Radeon HD 2900(R600)」から、大幅なダイサイズの縮小を果たしているからだ。TSMC 55nmプロセスのRV670は192平方mmで、TSMC 80nmプロセスのRadeon HD 2900(R600)の408平方mmの約50%のサイズとなっている。ダイサイズはコストに大きく影響するため、RV670の相対的に小さなダイは大きな意味を持つ。ちなみに、RV670はR600に対して、メモリインターフェイス幅は半分(512bits→256bits)になったが、倍精度浮動小数点演算のサポート(ストリームプロセッサ版でイネーブル)などが加わっており、差し引きでトランジスタ数は大きく変わっていない。R600の700M(7億)に対して、RV670は666M(6億6,600万)だ。
RV670のダイ縮小比率は、かなり高い。現在のプロセス技術では、プロセスノードが約70%に縮小しても、ダイサイズはなかなか理論値の50%にまで縮小しないからだ。実際、NVIDIA GPUでは、プロセスが1世代進んでもダイサイズは50%にまで縮小しないケースが多い。しかし、AMDは今回のRV670ではきっちりとダイを理想値まで縮小し、コストエフェクティブにした。「Radeon HD 3800(RV670)のダイ(半導体本体)は、競争相手(GeForce 8800GT = G92)の約70%に過ぎない。ダイサイズで差をつけている」とAMDのDavid Cummings(デビッド・カミングス)氏(Director of Marketing, Desktop GPU, Graphics Products Group, AMD)は言う。
 |
| GPUダイサイズと採用プロセス技術 ※別ウィンドウで開きます PDF版はこちら |
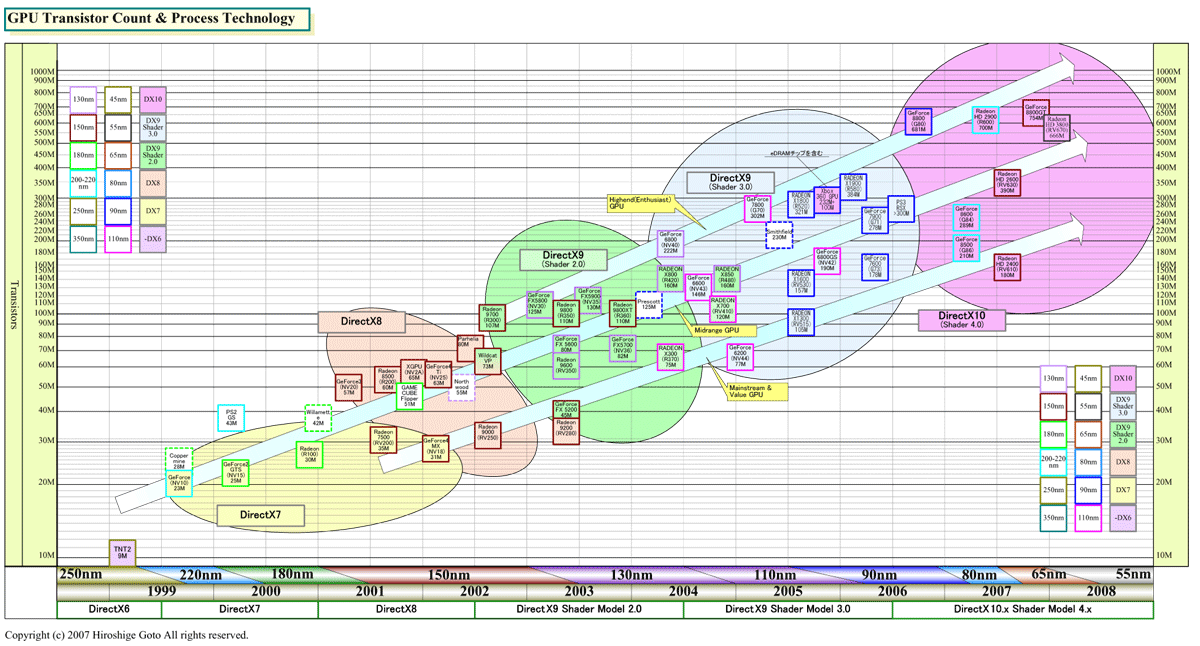 |
| GPUトランジスタ数と採用プロセス技術 ※別ウィンドウで開きます PDF版はこちら |
旧ATIは、もともとNVIDIAに比べてGPUのダイサイズを小さくすることが得意だった。同じプロセス世代なら、ATIの方がNVIDIAよりGPUダイが小さいのが通例だった。今回もAMDは、当初からダイを縮小しやすい設計を採ったと見られる。例えば、AMDのリングバスは、従来のクロスバースイッチのような配線の集中が起こらない。そのため、込み入った配線がスイッチブロックの縮小の邪魔をするといった現象を避け、より効率的に縮小することができると推測される。
 |
| Radeon HD 3800(RV670) Overview ※別ウィンドウで開きます PDF版はこちら |
□関連記事
【11月15日】AMD、世界初DirectX 10.1対応の「Radeon HD 3800」シリーズ
http://pc.watch.impress.co.jp/docs/2007/1115/amd.htm
【11月15日】【多和田】DirectX 10.1に対応するAMDの新GPU「Radeon HD 3800シリーズ」
http://pc.watch.impress.co.jp/docs/2007/1115/tawada116.htm
【7月9日】【海外】AMDが次期GPU「R700」を巨大にできない理由
http://pc.watch.impress.co.jp/docs/2007/0709/kaigai371.htm
【7月5日】【海外】AMDの次世代GPUは55nmプロセスがターゲット
http://pc.watch.impress.co.jp/docs/2007/0705/kaigai370.htm
(2007年12月4日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.