 |


■後藤弘茂のWeekly海外ニュース■Larrabeeに追われるNVIDIAがGT200に施したGPGPU向け拡張 |
●迫るIntelのLarrabeeに対抗して急ぐNVIDIAのCUDA戦略
Intelは、データ並列+タスク並列型プロセッサである「Larrabee(ララビー)」の準備を進めている。今夏にアーキテクチャの概要を明らかにし、来年(2009年)には製品投入の予定だ。Intelは、当初Larrabeeをハイパフォーマンスコンピューティング(HPC)向けと説明していたが、実際にはグラフィックス製品として投入する。これは、NVIDIAがグラフィックスカードとしてボリュームを出荷することで、汎用コンピューティングにも使うことができるプロセッサを普及させている戦略を踏襲するものだ。
Intelは、じつはLarrabee戦略の当初から、グラフィックス製品として普及させる計画だった。つまり、グラフィックス製品へと戦略を切り替えたのではなく、当初からグラフィックスとして売る計画だった。しかし、GPUベンダーを警戒させないために、当初は、煙幕を張り、LarrabeeはHPC向けと謳っていたという。このコーナーでも、IntelがLarrabeeの戦略を切り替えたように書いてきたが、それは、実際にはIntelの宣伝戦略に乗せられていたわけだ。
Intelは、最初のバージョンのLarrabeeを投入したら、すぐにシュリンク版のLarrabee 2を投入。この世代では、ノートPCにもGPUとして載せようと計画しているという。つまり、Larrabeeを完全にGeForce対抗として投入するつもりだ。
こうしたIntelの猛迫のため、NVIDIAは尻に火がついた状態となっている。NVIDIAがGPUの汎用的な利用形態であるGPUコンピューティングへと邁進するのは、Intelが追いつく前に、GPUコンピューティングの地歩を固めたいからだ。そのため、GPUコンピューティングのフレームワークである「CUDA (クーダ:compute unified device architecture)」の普及にフォーカスしている。しかし、NVIDIAにとって、これは困難な道のりだ。
NVIDIAはCUDAがさまざまな分野に浸透しつつあると謳う。実際に、CUDAはHPCなどの分野の一部で歓迎され、一定の成果を上げつつある。しかし、実態は、CUDAが広く広まるというフェイズにはまだ遠い。
●パフォーマンス最適化が難しいGPUコンピューティング
CUDAにトライしたプログラマ達の一部は、CUDAでGPUのパフォーマンスを引き出せるプログラムを組めるのは、一部の人だけだろうと指摘する。CPUとは異なるさまざまなパフォーマンスボトルネックが待ち受けているからだ。そのため、ただCUDAにコードを移植しただけでは、GPUのスペックに見合うだけのパフォーマンスを出すことは難しいと言われる。
CUDAが登場してからまだそれほど時間が経っていない昨年(2007年)8月のCPUカンファレンス「HotChips 19」では、NVIDIAの協力を得てCUDAプログラミングコースを開設したイリノイ大学が、学生によるプログラミングの結果を発表した。それを見ると、パフォーマンスが大きく上がるものもあれば、そうでないものもあり、かなりのばらつきがあった。NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、その結果について「並列コンピューティングのアルゴリズムにまだプログラムを書く側が慣れていないからだ」と説明していた。GPUコンピューティングに最適なアルゴリズムに、まだ親しんでいないから、性能を引き出せないケースが出てくるというわけだ。
あれから1年、CUDAプログラミングコミュニティは一定の広がりを見せ、アプリケーションも登場し、非常に高いパフォーマンスを達成しているものもある。たが、それでもNVIDIA CUDAには、最適化が難しいという批判がつきまとっている。NVIDIAのGT200世代である「GeForce GTX 200」と「Tesla T10P」は、そうした問題に対して、NVIDIAがある程度の解答を出したものだ。
●汎用コンピューティングのボトルネックをハードで解決
NVIDIAのCUDAが最適化が難しいのは、GPU独特のアーキテクチャ上のボトルネックがあるためだ。ハードウェアを隠蔽するプログラミングモデルのために、問題が見えにくいということもある。しかし、ハードウェア自体が、まだまだ、汎用的なコンピューティングに充分に最適化されているとは言い難いのも確かだ。
HotChips 19で指摘されたボトルネックは、レジスタやビデオメモリのアクセスレイテンシ、共有メモリ(Shared Memory)容量、命令発行レートなど。単体GPUの宿命であるCPUとGPU間のデータ転送のボトルネックもあるが、ほとんどのケースは、GPU側でのアーキテクチャ上のボトルネックで占められていることがわかる。
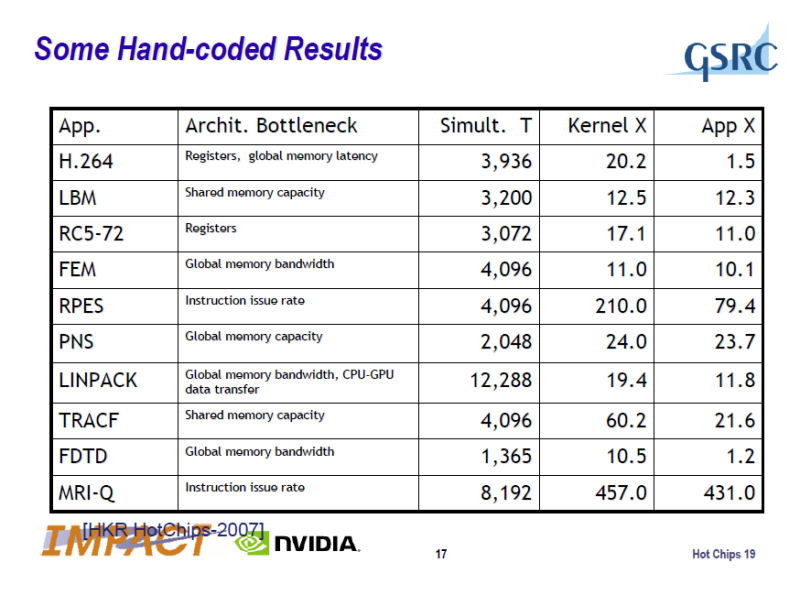 |
| HotChipsで示されたGPUによる各アプリケーションでの性能向上の度合 |
 |
| HotChipsで示されたGPGPUアプリケーション作成の際の注意点 |
NVIDIAは、昨年11月に米プリンストンで開催された、天文学と天体物理学でのGPUの応用カンファレンス「AstroGPU 2007」で、CUDAにおける最適化のポイントを説明した。そこでNVIDIAが挙げたのは、レジスタの不足によるマルチスレッディングの制約など「レジスタプレッシャ(Register Pressure)」、メモリアクセスの非効率化を招く「非結合メモリアクセス(Non-Coalesced Memory Access)」、それにGPU内部に備えるスクラッチバッドメモリでの「共有メモリのバンクコンフリクト(Shared Memory bank conflicts)」などだ。
 |
| AstroGPUで示されたレジスタプレッシャの問題 |
 |
| AstroGPUで示された非結合メモリアクセスの問題 |
 |
| AstroGPUで示されたバンクコンフリクトの問題 |
AstroGPUでは、NVIDIAはアーキテクチャ上のこうした問題を挙げた上で、それを避けて最適化する方法を示しただけだった。つまり、その時点では、ハードウェアの改良ではなく、プログラマ側の努力で問題を避けて欲しいというアプローチだった。この時のプレゼンテーションだけを見ると、NVIDIAは、ハードウェアをより汎用コンピューティングに向けて改良することを避け、プログラム側に負担を押しつけようとしているように見えた。
しかし、先月明らかになったGT200では、NVIDIAはAstroGPUで指摘した、いくつかの問題をハードウェアで解決した。このことは、NVIDIAが、今後も汎用コンピューティングの上でボトルネックになる部分は、徐々にハードウェアを改良することで解決して行こうとしていることを示している。
●レジスタ数とマルチスレッドのトレードオフ
GPUの性能を引き出そうとすると、GPUの演算リソースをできるだけフル稼働させなければならない。実行パイプラインが、メモリからのデータ待ちやリソースの競合で止まることをできる限り減らす必要がある。ここで問題になるのは、伝統的なグラフィックスタスクと、非グラフィックスの汎用的なタスクでは、プログラムの挙動が違うこと。そのため、伝統的なGPUとは異なるアーキテクチャ上の工夫が必要になる。
ただし、ここにはトレードオフがある。汎用コンピューティングに向けてリソースを割くと、その一方で、相対的にグラフィックスに有用なリソースを抑えなければならなくなる。両者を立てようとすると、GPU自体が巨大になってしまう。
もっとも、この問題には若干あいまいな部分がある。グラフィックスもシェーダプログラム中心になり、シェーダプログラムが複雑になるに従って、伝統的グラフィックスから離れ、部分的に汎用コンピューティングと似たような特徴を持つようになりつつある。そのため、一概に、グラフィックス機能対汎用コンピューティング機能といった対比はできない。
GT200のプロセッサコアの中で、NVIDIAが改革した大きなポイントの1つは、汎用レジスタの倍増だ。この拡張は、GPUコンピューティングの性能を引き上げ、メモリレイテンシを隠蔽するのに、大きな効果がある。
GPUでは、一般に物理レジスタと、プログラム側(または中間言語)から見える論理レジスタが分離されている。現在のCPUの多くが行なっている、論理レジスタをCPU内部の物理レジスタにマップする「レジスタリネーミング」と多少似ている。
GPUでは、まず、スレッド当たりのレジスタ数の割り当ては固定されていない。GPUでは、プログラムがドライバソフトウェアのランタイムコンパイラで、GPUのネイティブ命令に変換する際に割り当てるレジスタ数を決定する(実際の物理レジスタへのマッピングはGPU側で行なう場合が多い)。しかし、GPUが備える物理的なレジスタ数は決まっている。そのため、スレッド当たりのレジスタ数と、立ち上げることができるスレッド数にはトレードオフが生じる。
「各スレッド毎に専用のレジスタスペースを持つが、固定されてはいない。そのため、立ち上げるスレッド数が増えれば、1スレッドが使えるレジスタ数が減る。この2つはトレードオフの関係にある」とDavid B. Kirk氏は説明する。1スレッド当たりのレジスタ数が増えると、スレッド数が減ってしまうことになる。
この構造は、現在のマルチスレッディングGPUで共通した特徴となっている。そのため、コンパイラによるスレッドに対するレジスタ割り当てが性能を大きく左右する。例えば、Xbox 360の初期の段階ではMicrosoftのコンパイラのはき出すGPUネイティブコードが大量に物理レジスタを使ってしまっていた。そのため、スレッドが最大数まで立ち上がらず、GPUパイプラインがアイドルになるという状態が発生したという。その後、Xbox 360では、コンパイラ側の改良によってマルチスレッディングが向上し、シェーダ性能が上がるという現象になった。
伝統的なグラフィックスでは、それほど汎用レジスタを必要としないため、以前のNVIDIA GPUはレジスタが極端に少なかった。しかし、汎用コンピューティングとなると話が違ってくる。G80/GT200のGPUコンピューティングアーキテクトのJohn Nickolls氏(Director of Architecture)は、「GPUコンピューティングでは、スレッド当たり32の汎用レジスタが適切だと考えている」と語る。一般的なRISC(Reduced Instruction Set Computer)プロセッサと同レベル(ただしGPUの場合は整数と浮動小数点でレジスタの区別はない)の汎用レジスタが必要だと考えているわけだ。
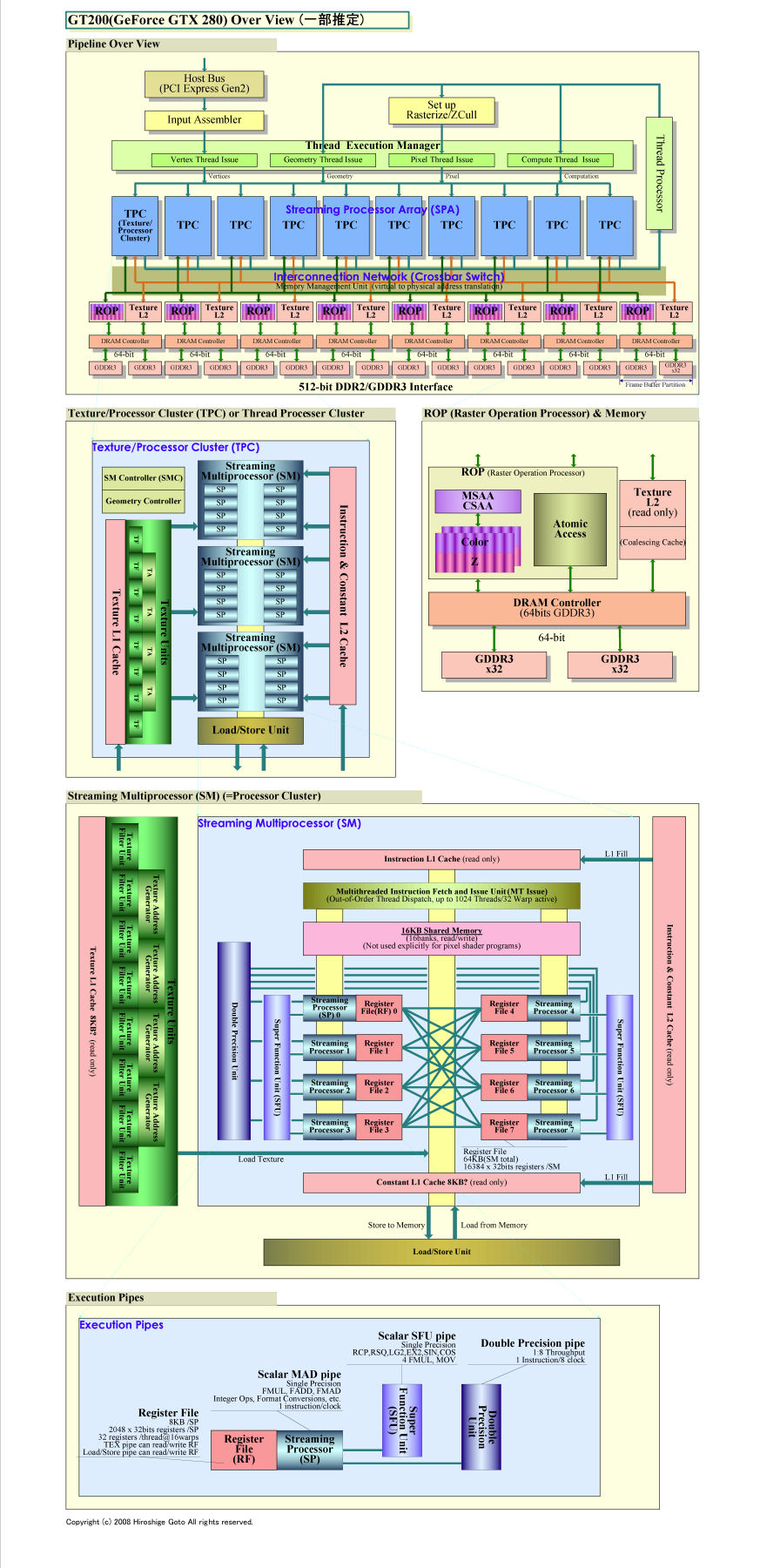 |
| GT200の概要(一部推定) PDF版はこちら |
●400~600サイクルのメモリレイテンシを隠蔽する
問題はここにあった。1スレッド当たりのレジスタ数を増やすと、立ち上げることができるスレッド数が減る。すると、マルチスレッディングで隠蔽しているメモリアクセスレイテンシがカバーできなくなる。GPUに外付けされたビデオメモリへのアクセスには、時間がかかる。G80/GT200系では、最低で200サイクル、プログラミングガイドでは400~600サイクルとされている。
G80/GT200は、32スレッドで構成されるスレッドバッチ「warp」を、各プロセッサクラスタ「Streaming Multiprocessor(SM)」の中で、4サイクルに渡って実行する。SMにはプロセッサ「Streaming Processor(SP)」が8個搭載されており、8並列で処理するため、4サイクルで32スレッドを処理できる。
G80では、Streaming Multiprocessor(SM)当たりのレジスタ数は8,192本だった。そのため、32レジスタを各スレッドに割り当てると、立ち上げることができるスレッド数は256スレッドとなる。スレッドバッチであるwarp数ではたった8個だ。
ここで、プログラム中のメモリロード命令の後に、ロードに依存しない命令が平均で3命令続くとする。8 warpが、それぞれ4サイクルでメモリアクセスして4命令間隔で依存命令が来るため、平均で128サイクルのメモリレイテンシしか隠蔽できない。
そのため、メモリ待ちで無駄が生じる可能性が大きくなってしまう。もちろん、プログラムによって、さまざまな条件が異なるため、一概には言えない。実際には、ロード命令から依存命令まで、もっと間隔が開くケースも多いだろう。しかし、warp数が少なくなればなるほど、ストールやパイプラインバブルが生じる可能性は高まる。また、ロード命令の後に、依存しない命令をより多くスケジュールしようとすると、命令スケジューリングがより複雑になる。
G80の場合は立ち上げることができる最大のアクティブwarp数は24 warp。24 warpを確保すると、4命令間隔のメモリアクセスの場合で、平均で384サイクルも隠蔽できるようになる。しかし、その場合、G80ではスレッド当たりのレジスタ数は10本になってしまう。x86並の窮屈なレジスタになる。ネイティブ命令が、レジスタ間演算命令中心であることを考えるとこれは苦しいだろう。
 |
| AstroGPUで示されたメモリアクセスレイテンシに関する説明 |
●レジスタを2倍に増やしてメモリレイテンシを隠蔽
G80では、限られたレジスタ数のために、アプリケーションによっては、このレジスタプレッシャの問題に気を使わなければならなかった。それに対して、GT200ではレジスタ本数が16,384本と2倍になり、最大アクティブwarp数も32 warpに増えた。
GT200では、メモリロード命令の後にロードに依存する命令が4命令間隔で現れるとして、1スレッド32レジスタを割り当てた場合は、16 warpで256サイクルを隠蔽できる。そのため、スレッド当たり32レジスタが、より現実的になった。また、マックスの32 warpの場合には、16レジスタ/スレッドで、512サイクルを隠蔽可能だ。
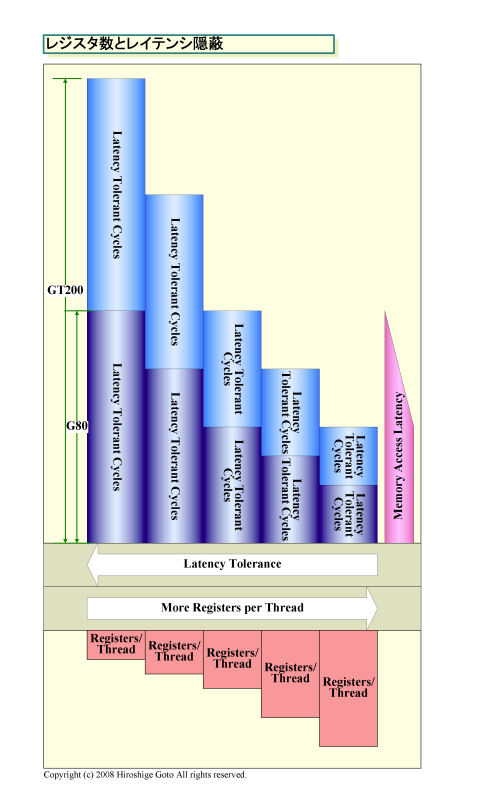 |
| レジスタ数とレイテンシ隠蔽 PDF版はこちら |
GT200では、Streaming Multiprocessor(SM)当たりのレジスタ数の倍増によって、G80と較べてレジスタ総量が3倍以上に増えた。G80では512KBのレジスタだったのが、GT200では1.875MBに増えている。CPUのキャッシュと、ある程度似通った増え方をしている。
CPUはシリアルタスクでのレイテンシを隠蔽するため膨大なキャッシュを必要とする。それに対して、GPUはパラレルタスクでレイテンシを隠蔽するために、マルチスレッディングのリソースとして膨大なレジスタを必要とする。両プロセッサはこのように分化している。
ちなみに、汎用レジスタはAMD(旧ATI)も同様に膨大な数を積んでいる。元々は、ATIアーキテクチャの方がNVIDIAより、スレッド当たりのレジスタ数が多かった。ATIはR6xxファミリの時に、すでに「DirectX 9ではスレッド当たり16からおそらく32のGPRにアクセスした。今後はそれ以上になる」と指摘していた。RV770は演算ユニット数がR620より多く、VLIW(Very Long Instruction Word)による命令レベルの並列性を活かすため、よりスレッド当たりのレジスタを必要とする。
そして、メモリアクセスレイテンシを隠蔽しなければならない事情は、ATI側も同じだ。ただし、プロセッサコアの動作サイクル自体はRV770の方がGT200より遅いため、相対的に隠蔽しなければならないメモリレイテンシサイクルはGT200より少なくなる。しかし、演算ユニット数が多いことでそれは相殺されるだろう。ATI Radeon HD 4800(RV770)はMB単位のレジスタを搭載しているとAMDは説明する。
●メモリアクセスをGPUコンピューティング向けに改良
GT200で改良されたもうひとつのポイントは、メモリアクセスだ。伝統的なグラフィックスタスクでは、メモリアクセスは結合(Coalescing)されることを前提としている。まず、各プロセッサがSIMD(Single Instruction, Multiple Data)として実行されるため、各プロセッサのメモリアクセス命令は揃う。そして、多くの場合、隣接するピクセルのような、メモリ上の番地が連続するメモリアクセスとなる。そのため、各スレッドのメモリアクセスを結合して、粒度の大きなメモリアクセスにまとめることが可能だ。
実際、G80/GT200系ではwarpの半分である16スレッドでメモリアクセスを結合させる。しかし、G80の場合は、各スレッドのアクセスするメモリアドレスが入れ替わった「Permuted Access」や、アクセスするアドレスの頭が整列していない「ミスアラインアクセス(Misaligned Access)」の場合は、ペナルティが極めて大きかった。これは、分割された多数のメモリアクセストランザクションを発生させてしまったからだ。
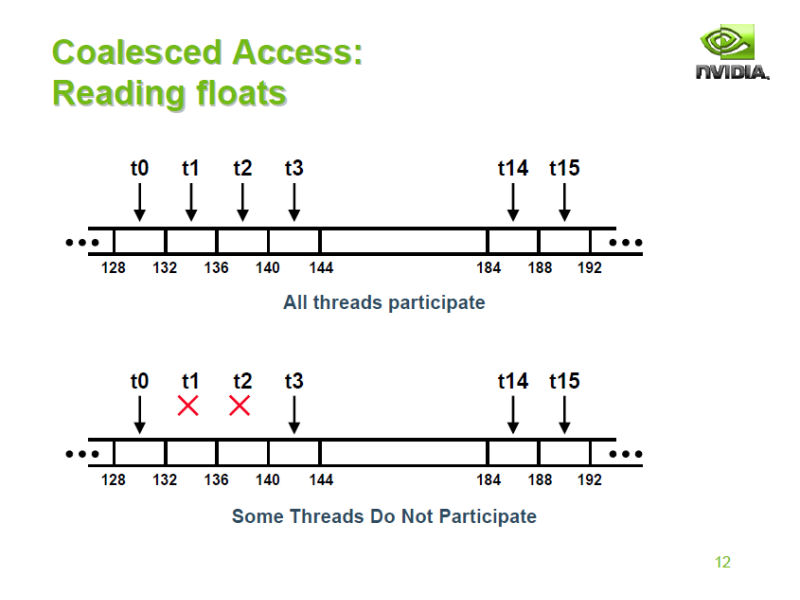 |
| AstroGPUで示された結合アクセスでの流れ |
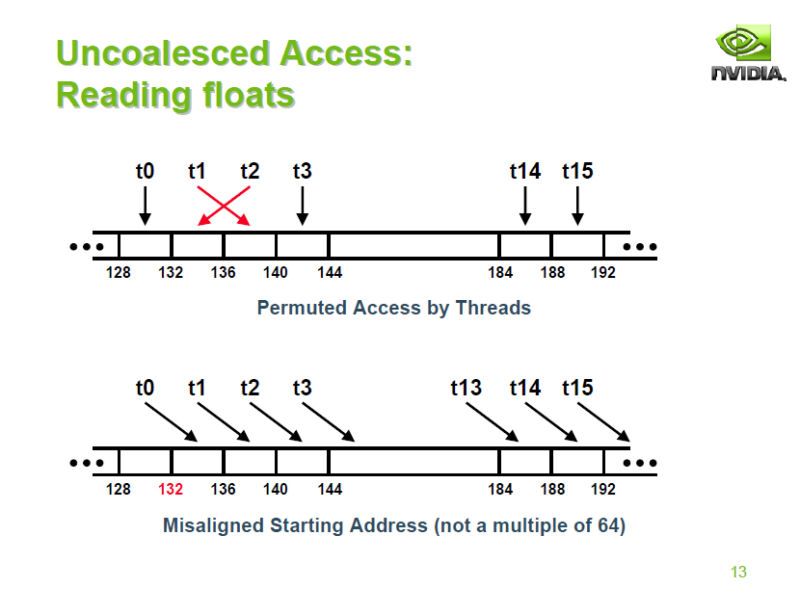 |
| AstroGPUで示された非結合アクセスでの流れ |
そして、悪いことに、汎用コンピューティングでは、こうしたアクセスパターンが生じる可能性が高い場合がある。つまり、伝統的グラフィックスタスクのように、効率的なアクセスに都合のいい振る舞いをしてくれない場合が多いアプリケーションがある。
GPUの場合、高パフォーマンスであるが故にメモリ帯域は非常にタイトだ。メモリアクセスには一定の粒度(32~64 bytes)があるため、アクセスの粒度が小さいと、無駄が生じてしまう。つまり、メモリのピーク帯域が広くても、実際に転送できるデータ量が減るというメモリ帯域の問題が生じてしまう。G80では、この問題がかなりクリティカルだった。
GT200では、ここが改善された。一定のメモリセグメントの中でのランダムアクセスやミスアラインアクセスは、GPUハードウェアによって、単一のアクセストランザクションに自動的にまとめられる。NVIDIAは、この機能のために、メモリコントローラに直結している読み出しオンリのL2テクスチャキャッシュを使っていると説明する。
実際には、この非結合(Non-Coalesced)メモリアクセスのハードウェア支援のために、メモリアクセスレイテンシは若干は延びているはずだ。しかし、トランザクションが結合されるため、結果としてレイテンシが短縮され、帯域も有効に使われるというわけだ。このあたりは、CPUのアンアラインアクセスの機能と似通ったものがある。
●据え置かれた共有メモリの強化
GT200では、強化されなかった部分もある。その代表は、共有メモリ(Shared Memory)だ。NVIDIA GPUでは、各Streaming Multiprocessor(SM)の中に16KBの共有メモリがある。これは、読み出し&書き込み可能なスクラッチパッドメモリで、スレッド間で共有できる。つまり、スレッド間のデータ交換に利用できるメモリだ。昨年のHotChips 19では、この共有メモリの量が限られており、また、バンクコンフリクトが発生しやすいことも問題だと指摘された。
NVIDIAが共有メモリを強化しなかった理由のひとつは、このメモリがプログラムからビジブルであるためだと思われる。そのため、共有メモリの量を変えると、プログラミングモデルに与えるインパクトが大きく、ソフトウェア互換性を取りにくくなってしまう。
GT200では、共有メモリをグラフィックスタスク時にも使っているという。ジオメトリシェーダでは、共有メモリをプログラム側からは見えない形で利用しているとNVIDIAは説明する。GT200ではジオメトリシェーダのスループットが大幅に改善された(G80は非常に悪かった)が、そのためにはアウトプットレジスタなどのリソースが必要で、共有メモリがそうした用途に利用されている可能性は高い。
NVIDIAは、今回、グラフィックスパイプのテクスチャキャッシュをGPUコンピューティングに転用し、GPUコンピューティングのための共有メモリをグラフィックスタスクに転用した。NVIDIA GPUの持つ2つの側面は、融合して行くように見える。実際には、これは業界全体のトレンドだ。例えば、MicrosoftはDirectX 11から、GPUコンピューティング向けのフィーチャをグラフィックスパイプで活用したり、逆にDirectX 11自体にGPGPU(汎用GPU)ステージを組み入れたりする。GPUの2つの機能は、将来的には融け込んで行くだろう。
ただし、NVIDIAの実装にはトレードオフがある。それは、グラフィックスモードとGPUコンピューティングのモードが共存できないことだ。現在のNVIDIA GPUでは、両タスクで、プロセッサのモード切り替えを行なう必要がある。グラフィックスモードでは、頂点/ジオメトリ/ピクセルの3種のタスクを混在させることができるが、GPUコンピューティングへはモード切替を行なう必要がある。今後は、このオーバーヘッドを減らすことも重要になって行くだろう。
NVIDIAは、GPUコンピューティングでの問題点のいくつかを、GT200世代で解決または軽減した。NVIDIAは、GPUを汎用的なアプリケーションで使いやすいように、さらに改良を加えて行く気があることを示した。問題は、そのペースが充分速いのかどうか、改良がプログラマの支持を取り付けるのに充分なのかどうかという点にある。
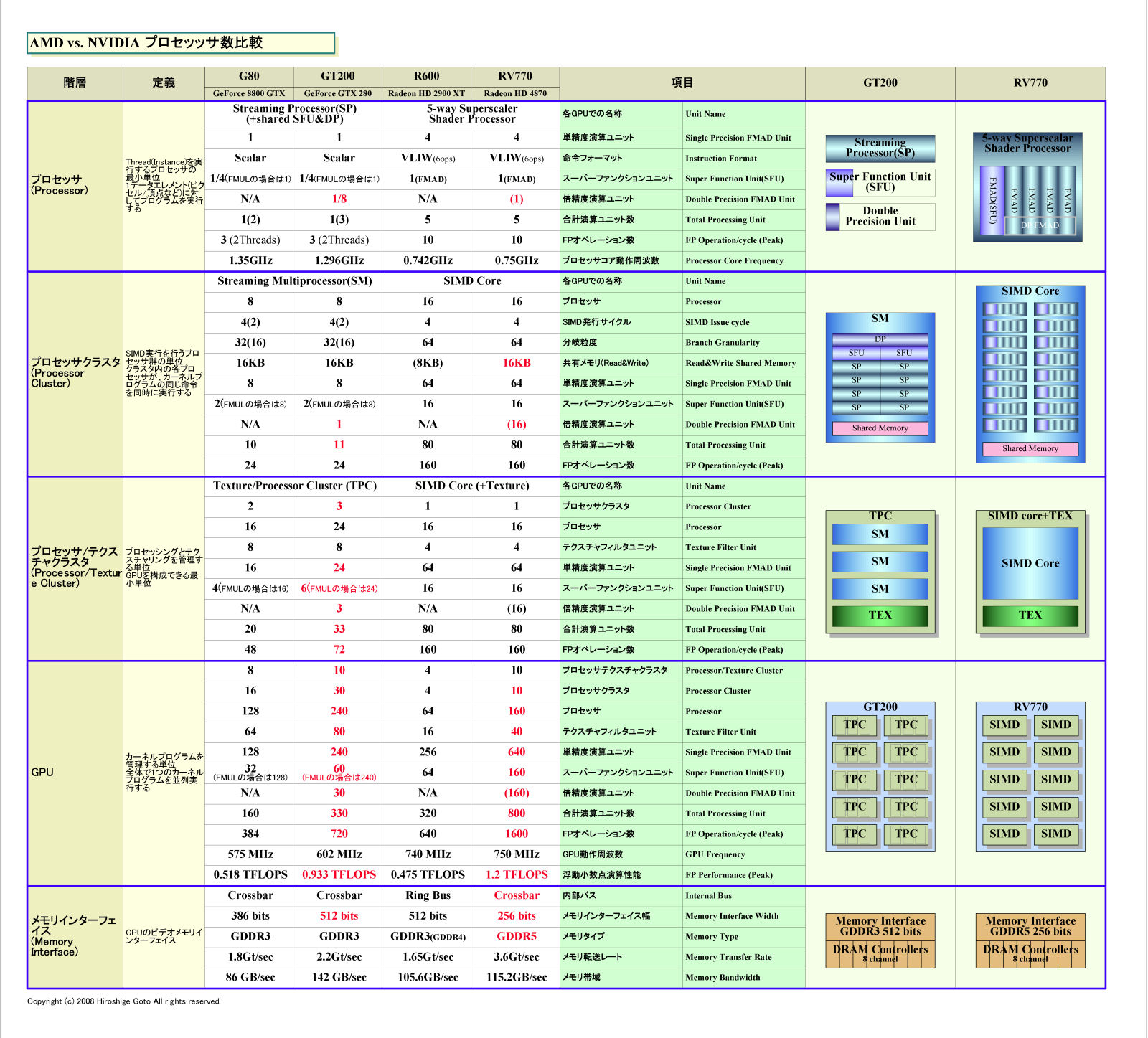 |
| AMDとNVIDIA GPUのプロセッサ数の比較 PDF版はこちら |
□関連記事
【7月2日】【海外】NVIDIAのGT200とAMDのRV770のどちらが優れているのか
http://pc.watch.impress.co.jp/docs/2008/0702/kaigai451.htm
【6月20日】【海外】GeForce GTX 280の倍精度浮動小数点演算
http://pc.watch.impress.co.jp/docs/2008/0620/kaigai449.htm
【6月19日】【海外】GT200コアでHPCの世界を狙う「Tesla」
http://pc.watch.impress.co.jp/docs/2008/0619/kaigai448.htm
【6月17日】【海外】NVIDIAの1TFLOPS GPU「GeForce GTX 280」がついに登場
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai446.htm
(2008年7月16日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.