 |


■後藤弘茂のWeekly海外ニュース■GeForce GTX 200(GT200)のパフォーマンスの秘密 |
●G80のために並列コンピュータアーキテクトを雇う
 |
| John Nickolls氏(Director of Architecture) |
Nickolls氏は、超並列のSIMD(Single Instruction, Multiple Data)型スーパーコンピュータ「MasPar Computer」のアーキテクトとして知られていた。MasParは、当時としては“低価格”の並列スーパーコンピュータとして知られたマシンで、膨大な並列性を備えていた。例えば、「MasPar MP-2」は、ワンチップに32個のプロセッサエレメント(PE)を搭載、32チップをワンボードに搭載(1,024PE/ボード)し、16ボードを搭載することで1万6千個のプロセッサエレメントをシステムに載せていた。
NVIDIAは2003年に顧客に対して行なったプレゼンテーションの中で、MasParからキーパースンを迎えたと報告している。それが、NVIDIAのGPUコンピューティング面のアーキテクチャを担当することになるNickolls氏だった。Nickolls氏によると、NVIDIAに参加して、すぐにG80のアーキテクチャを担当することになったという。G80の設計がスタートしたのは2002年だと推測されるため、Nickolls氏も初期の段階から加わったと推測される。
Nickolls氏が、NVIDIAアーキテクチャにどのような影響を与えたかは、MasParアーキテクチャを見れば一目瞭然だ。
MasPar MP-2では、それぞれのチップに1個の命令制御ユニットを搭載し、オンチップの32個のプロセッサエレメントをSIMDとして制御している。個々のプロセッサエレメントはスカラデータバリューを演算する。SIMDによって制御系を極力簡略化することで、チップのほぼ90%の面積がプロセッサエレメントで占められるようになった。つまり、チップのほとんどは演算に使われている。MasParは単体で動作させるのではなく、DECマシンをフロントエンドに使い、プログラムの中の並列化可能な部分だけをMasParにダウンロードする仕組みだ。
こうして見ると、MasParはNVIDIAのG80/GT200アーキテクチャにかなり似ていることがわかる。MasParの1チップがG80/GT200の1クラスタ(Streaming Multiprocessor:SM)」に当たり、MasParの1ボードがG80/GT200の1チップに当たる。ホストマシンがDECからPCまたはPCサーバーに替わり、MasParのプログラミング環境「MPPE (MasPar Programming Environment)」がCUDAになった。厳密には、さまざまな違いがあるが、それでも類似性は明らかだ。そう考えると、SIMDスーパーコンピュータを、ワンチップにしたものがG80/GT200とも言えそうだ。
もっとも、Nickolls氏は依然としてGPUとCPUにはかなりの違いがあると強調する。「私自身もNVIDIAに入るまでGPUがこれほど複雑なストラクチャを持っているとは知らなかった。CPUとは全く異なる複雑性で、それがためにCPUとの融合は簡単ではない」(Nickolls氏)。GPUベンダーであるNVIDIAは、GPUの複雑性はそのまま残しながら、GPUコンピューティング向けのフィーチャを加えて行くアプローチを取った。
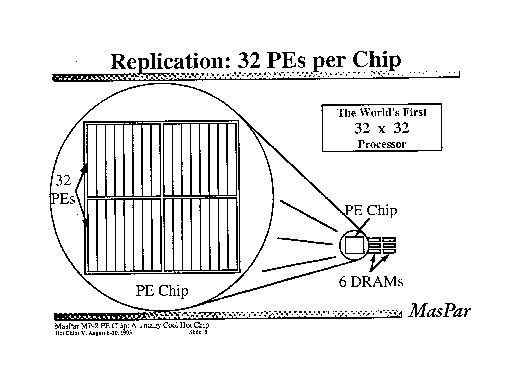 |
| ワンチップに32個のプロセッサエレメント(PE)を搭載 |
●スカラプロセッシングを暗喩するコードネームTesla
並列コンピューティングのアーキテクトNickolls氏を迎えて開発された、NVIDIAのG80以降のアーキテクチャには、従来型のGPUとは異なるさまざまな特徴がある。中でも大きなポイントは前回の記事で説明したように、演算アレイがスカラプロセッサで構成されていることだ。G80/GT200では、テクスチャを除く各プロセッサが、シングルイシューでスカラデータ(スカラレジスタ)に対して演算を行なうスカラプロセッサとなっている。これは、演算ユニットを4-wayのSIMD(ベクタ)演算ユニットとして構成する伝統的なGPUとの大きな違いとなっている。
MasParライクなプロセッサのスカラ化は、G80アーキテクチャの中で最重要のポイントだったと推測される。それがわかるのは、G80のコードネームが「Tesla(テスラ)」だったからだ。
Teslaというコードネームは、アメリカを代表する発明家で電気科学者のニコラ・テスラ(Nikola Tesla)氏に由来している。テスラ氏はさまざまな発明発見を行なったが、“スカラ”電磁波を唱えたことでも知られている。これは通常の“ベクタ”電磁波とは異なるふるまいをする電磁波の仮説だ。つまり、“ベクタ”に対して“スカラ”を唱えたのがテスラ氏だった。
これは、偶然の一致にしてはできすぎている。G80のコードネームにTeslaを選んだ理由は、スカラ波から来ていると考えるのが自然だ。だとすれば、スカラプロセッサ構成は、G80/GT200アーキテクチャの、最も重要な基本コンセプトだと考えられる。
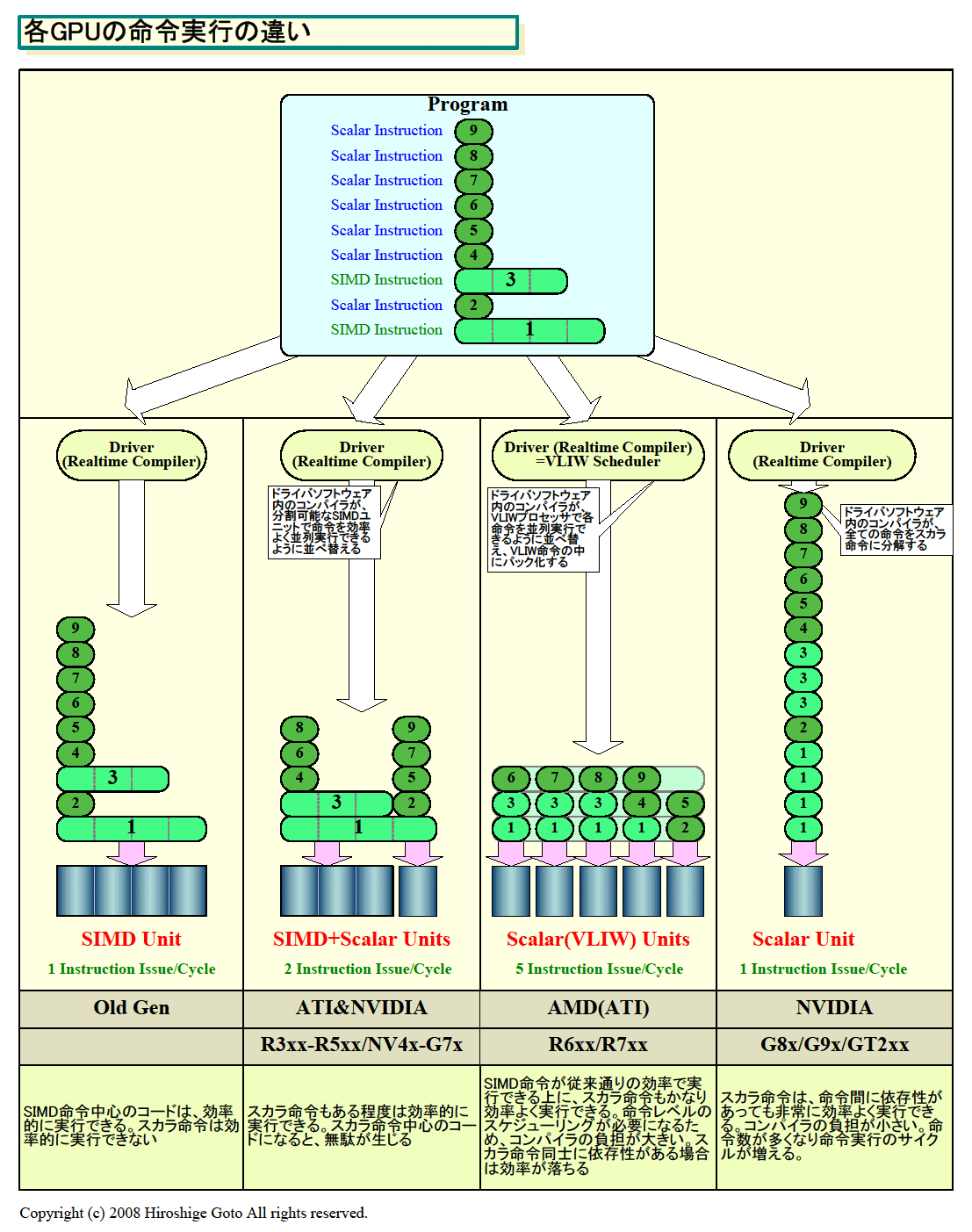 |
| 各GPUの命令実行の違い
PDF版はこちら |
●スカラプロセッサで構成するG80/GT200
Teslaと名付けられたG80アーキテクチャでは、演算ユニットは、いずれもスカラプロセッサとなっている。後継であるGT(GeForce/Tesla) 2xx世代でもそれは同じだ。従来のGPUとは異なり、NVIDIAはプロセッサの中ではデータレベルの並列性(DLP:Data-Level Parallelism)を使わないアプローチで、後述するが、おそらく、命令レベルの並列性(ILP:Instruction-Level Parallelism)も利用しない。例外はテクスチャフィルタリングプロセッサで、これはSIMD演算専用ユニットで、SIMDバリューのテクスチャデータをフィルタリングするようになっている。
G80/GT200型GPUでは、プロセッサクラスタであるStreaming Multiprocessor(SM)に、Streaming Processor(SP)が8個、Super Function Unit(SFU)が2個、搭載されており、GT200では、これに倍精度の浮動小数点演算ユニット「Double Precision Unit」が1個加わった。SMクラスタの構成は以下の通りだ。
- Streaming Processor(SP) 8個
- Super Function Unit(SFU) 2個
- Double Precision Unit 1個
- 命令ユニット(Instruction Fetch and Issue) 1個
- 32-bitスカラレジスタファイル(Register File) 16,384本
- 共有メモリ(Shared Memory) 16KB
- 命令L1キャッシュ(Instruction L1 Cache)
- コンスタントL1キャッシュ(Constant L1 Cache)
基本の演算プロセッサであるStreaming Processor(SP)は、スカラの積和算(MAD)演算ユニット(ALU)で、FMUL/FADD/FMADの浮動小数点演算、整数オペレーション/フォーマットコンバージョンなどを実行できる。1命令/クロックの実行スループットで、1クロック当たり1命令実行だ。
NVIDIAが示したGT200の図には、各Streaming Processor(SP)に対して、複数命令を発行できるように見える図がある。下のスライドがそれだ。しかし、アーキテクトのJohn Nickolls氏(Director of Architecture)によると、このプレゼンテーションの図は正確ではなく、SPは1命令/サイクルのプロセッサのままだという。
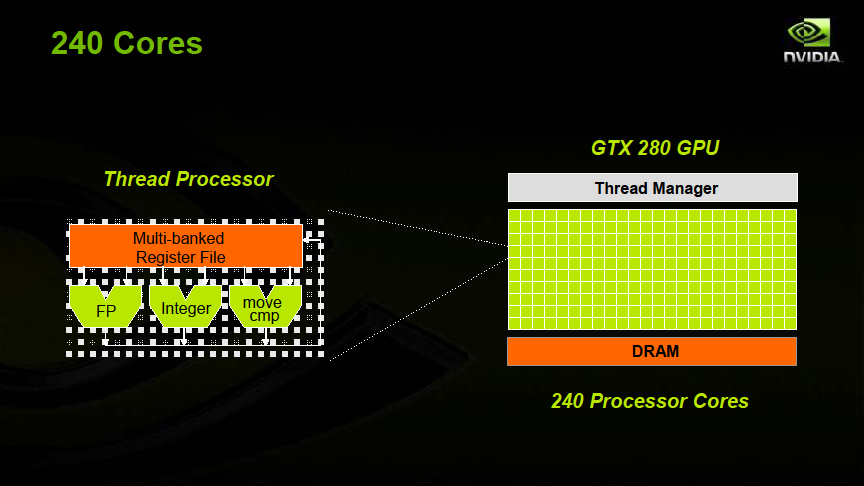 |
| GTX 280は240のプロセッサコアを搭載 |
スカラプロセッサである点は、Super Function Unit(SFU)も同じだ。2個のSuper Function Unit(SFU)は、RCP/RSQ/LG2/EX2/SIN/COSといった複雑な演算を行なうユニットだ。それぞれ、4個のStreaming Processor(SP)の間で、共有されるリソースとなっている。正確には、各SFUがそれぞれ4個のSPに結びつけられているレジスタファイルをSPと共有する。
SFUに対しては、4サイクルスループットで4つのスレッドが4クロック毎に各1命令を発行できる。実際にはSFUは1サイクルスループットでパイプラインで演算しているが、4スレッドで共有するため、各スレッドからは4サイクルスループットに見える。4スレッドの命令はプールされ、各サイクルに1スレッドずつ発行されるという。
また、SFUは4個のFMUL(浮動小数点乗算)ユニットとしても機能するとNVIDIAは説明する。つまり、4スレッドが1サイクルスループットで、4個のFMULを並列に実行できるという。その場合は、4個のFMULユニットが1個のSFUの中にあるように見える。個々のスレッドが、それぞれ仮想的に1個ずつのFMULユニットで実行することになる。ちなみに、AMD(旧ATI)アーキテクチャでのSFUは、1個のFMADユニットとしても機能する。
一方、GT200の倍精度演算ユニットは、8 SPで共有される。そのため、SPの単精度演算と較べると1/8のパフォーマンス比となっている。8スレッドが8サイクル毎に各1命令を発行できる。逆を言えば、8スレッドがいったん命令を発行したら、8サイクルは次の命令を発行できないという。
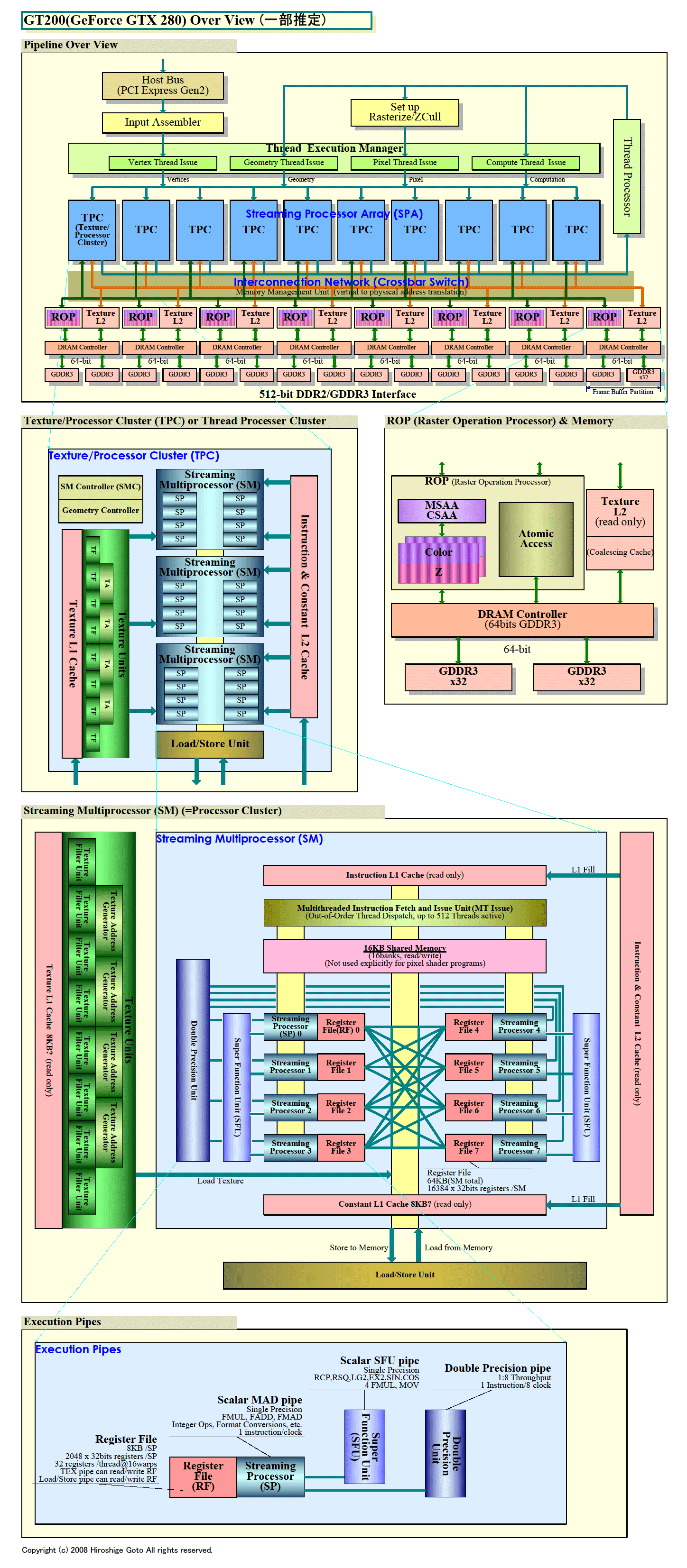 |
| GT 200のオーバービュー(一部推定)
PDF版はこちら |
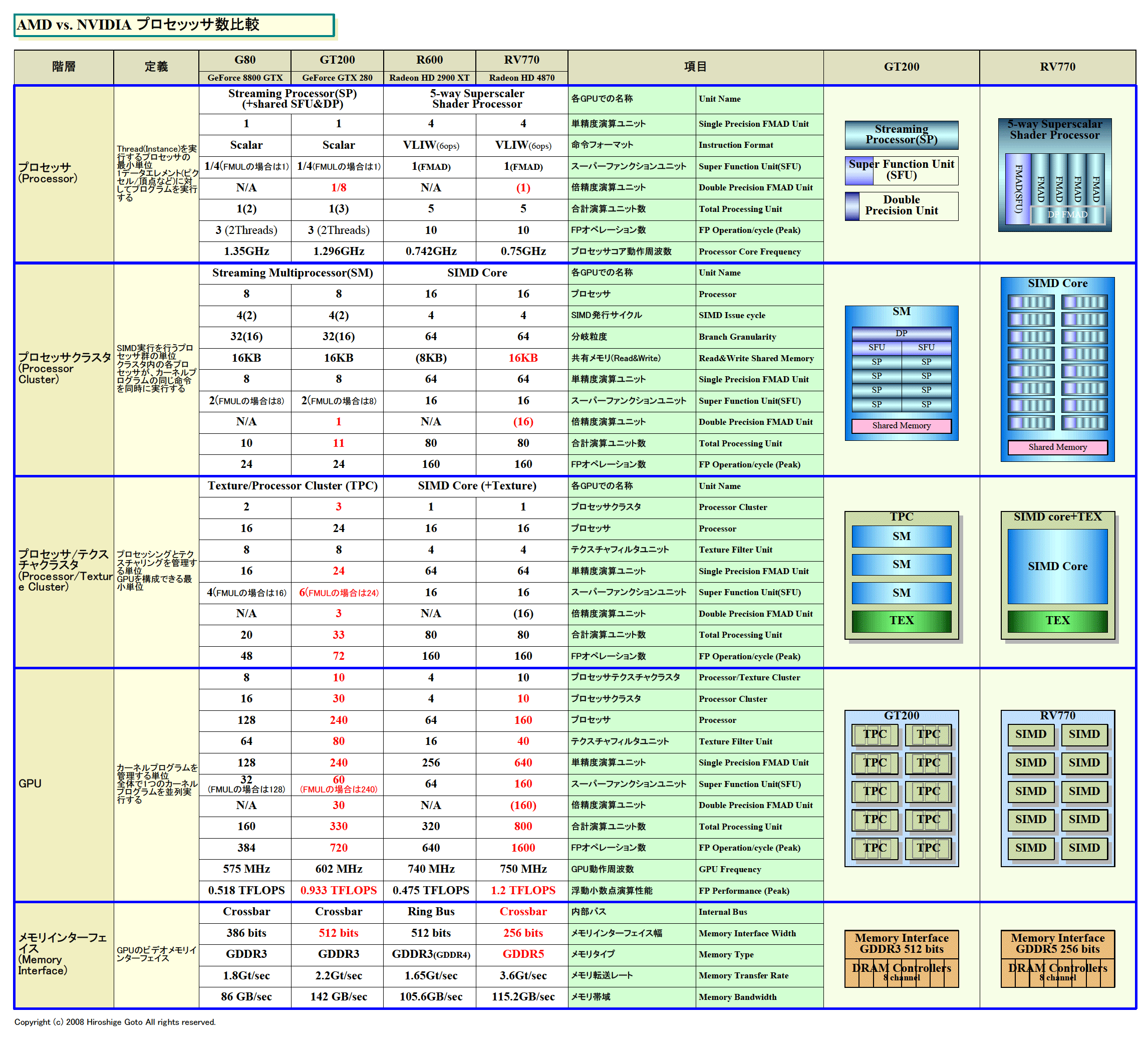 |
| AMDとNVIDIAのプロセッサ数比較
PDF版はこちら |
●疑問符がついているG80での2命令発行
GT200は、このように、SPとSFU、DP(倍精度)と複数の実行パイプラインを備える。G80/GT200アーキテクチャでは、これらの実行パイプに対して、2命令同時発行(Dual Issue)の機能を実装している。つまり、複数ユニットに命令を同時発行して並列に稼働させることができる。
じつは、GT200の公称ピークパフォーマンスは、SPとSFUのFMULユニットでそれぞれの演算を同時に行なった場合の数字となっている。つまり、SPで積和算の2オペレーション、SFUで乗算の1オペレーションの合計3オペレーションが1サイクルで実行できることを前提に計算している。Streaming Multiprocessor(SM)全体では1サイクルに24オペレーション(24 FLOPs)で、1.29GHzでコアを駆動し30個のSMを搭載するため933GFLOPSとなる。
しかし、実際には、NVIDIAアーキテクチャでの並列実行とピークパフォーマンスには疑問があった。G80が製品として登場すると、現実のパフォーマンスはSPとSFUの理論値にならないというクエスチョンがつけられた。そのため、NVIDIAはG9x世代ではSPだけのピークパフォーマンスを掲げ、SPとSFUの合計値については大きく謳わなくなった。だが、GT200では、NVIDIAはG80/G90世代より2命令発行が強化され、より多くの命令が発行できるようになったとして、再びSPとSFUの合計ピーク性能を謳うようになった。
じつは、NVIDIAはG80世代の2命令発行の仕組みについて、詳しくは明らかにしていない。そのため、2命令発行が難しい理由が、命令スケジューリングのためなのか、他の制約があるのか、そこがわからなかった。しかし、NVIDIAのさまざまなドキュメントを参考にすると、G80の命令発行の仕組みが見えてくる。
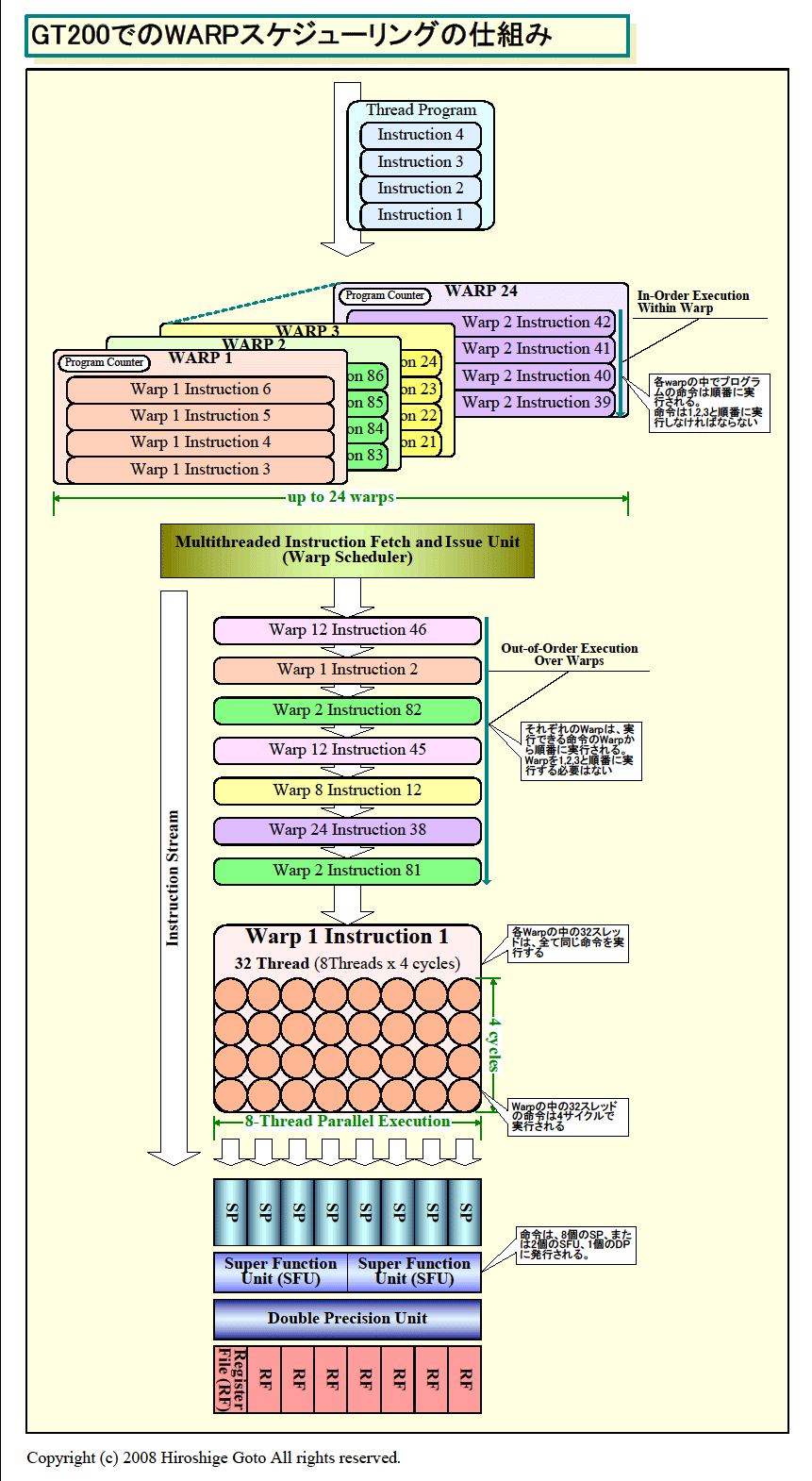 |
| GT 200におけるWARPスケジューリングの仕組み
PDF版はこちら |
●推測できるG80の2命令発行の仕組み
まず、SPとSFUはどちらも1命令/サイクルのスカラプロセッサで、どちらのプロセッサも2命令を同時に実行することができない(SFUのFMULを除く)。一方、命令ユニットは、各サイクル毎に異なるwarpの命令を1プロセッサに対して発行できる。そして、雑誌「IEEE Micro」掲載の論文「NVIDIA Tesla: A Unified Graphics and Computing Architecture」(IEEE Micro March April 2008(Vol. 28, No. 2))によると、SPとSFUに渡る命令発行は交互の(命令発行)サイクル(on alternate cycles)に行なわれ、両パイプをビジーに保つとなっている。
普通に考えると、1サイクルに1命令発行の命令ユニットは、2命令を同時発行できないため、2パイプをビジーに保つという説明は矛盾しているように見える。しかし、G80では1つのwarpに含まれる32スレッドに対して、4サイクルに渡って同じ命令を実行する。そのため、命令ユニットは、実際にはプロセッサコアサイクルで4サイクル置きに命令を発行すればいいことになる。
そして、命令ユニット自体は、1.5GHzのプロセッサコアの半分のクロックで動作している。つまり、プロセッサコアサイクルで2サイクル置きに命令を発行できる。だとしたら、G80アーキテクチャでは、SPとSFUのそれぞれに対して、2サイクル置きに、交互に異なる命令を発行できることになる。
つまり、G80の命令ユニットは、特定のサイクルにSPに1命令を発行して、2サイクル後に、今度はSuper Function Unit(SFU)に別な命令を発行できることになる。SPは2サイクル前に発行された命令を実行中だが、Super Function Unit(SFU)は4サイクル前の命令の実行が終わっているので、別な命令の4サイクル実行を開始できる。この推測が正しければ、下の図のように、SPとSFUは2サイクルのずれで、フルに回転し続けることができる。
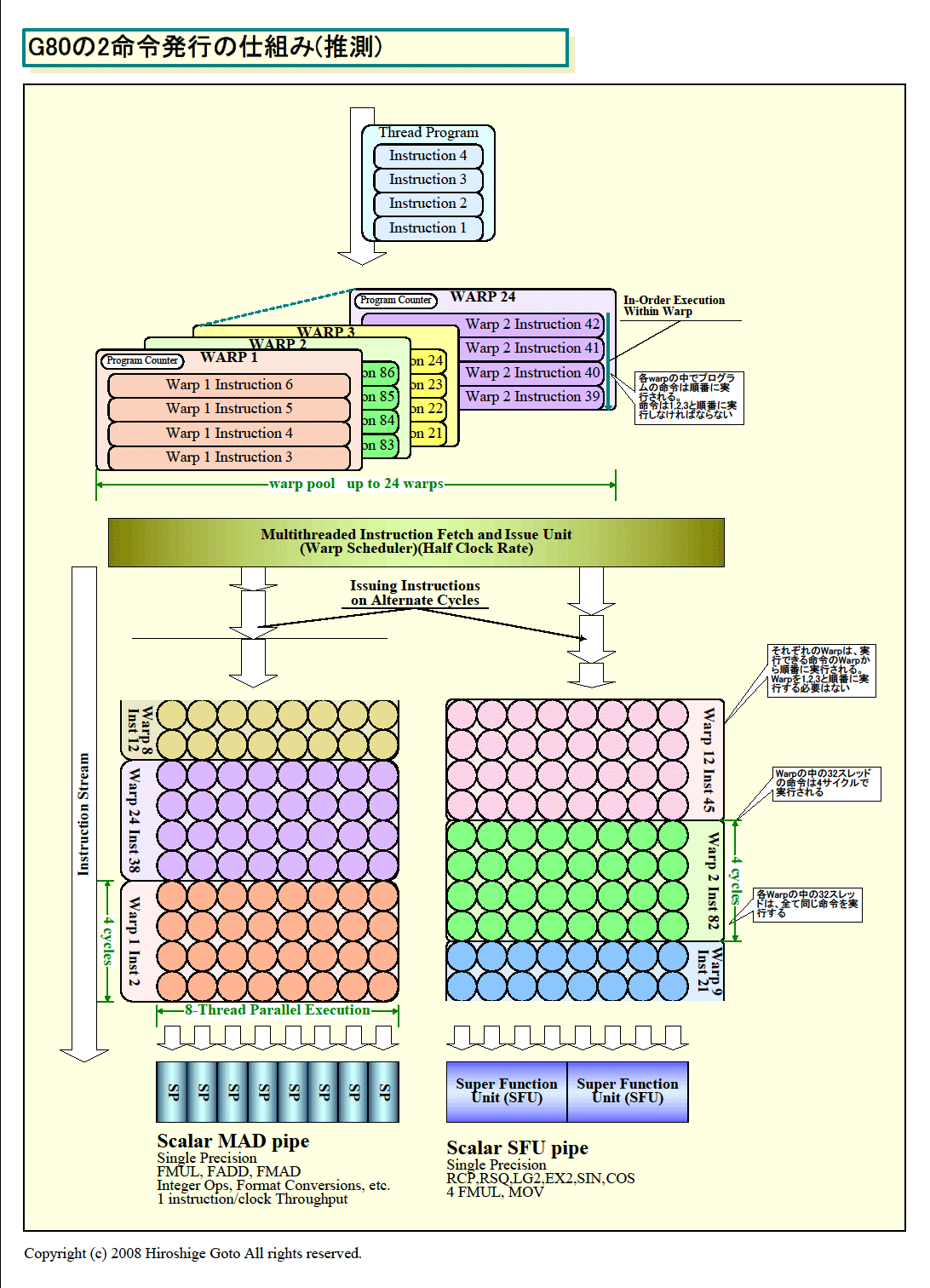 |
| G80の2命令発行の仕組み(推測)
PDF版はこちら |
命令ユニット自体はwarpにまたがりOut-of-Order命令発行であるため、この場合に発行する命令は同じwarpに属している必要はないと見られる。だとすれば、1スレッド内での命令レベルの並列性は一切ないことになる。
G80の命令発行がこうした仕組みだとすると、初期のG80の説明でwarpに16スレッドの仕様があったことも納得できる。命令ユニットが2サイクル毎に命令を発行できるからだ。しかし、16スレッドwarpの場合には、SPまたはSFUどちらか片方にしか命令を発行することができないことになる。16スレッドwarpが実際には使われていない理由もこれでわかる。
●改善されたGT200での2命令発行
では、GT200では2命令発行の何が改善されたのか。NVIDIAのTony Tamasi(トニー・タマシ)氏(Vice President, Technical Marketing)は、追加の命令ユニットが加わったと説明した。額面通りに受け取ると、命令ユニットが2個になり、同一サイクルで命令を発行できるようになったと考えられる。しかし、NVIDIAの説明にはマーケティング的な誇張が含まれている場合も多く、現実の実装にはクエスチョンが残る。G80の2命令発行が推測通りだとすると、2命令を同一サイクルで発行する意味がないからだ。
 |
| 2命令発行の第2世代 |
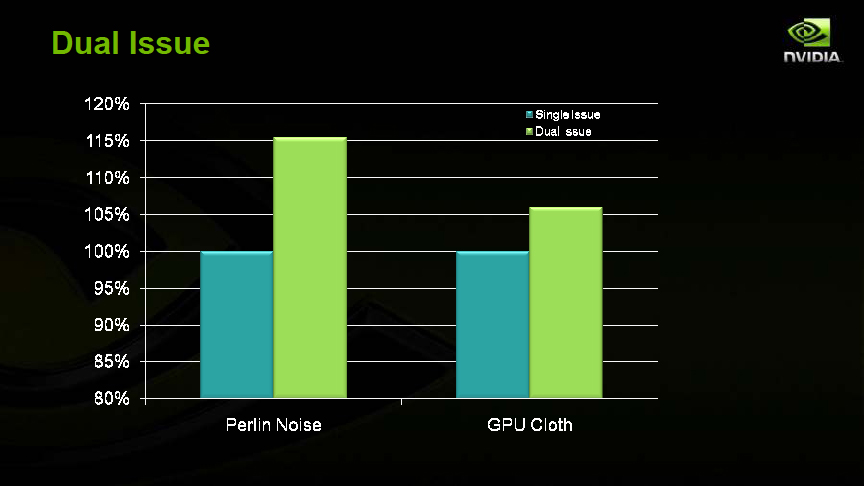 |
| 2命令発行のパフォーマンス |
しかし、NVIDIAは、GT200では2命令発行の最適化によって、93~94%の効率で2命令発行が可能になったと説明している。GT200以前は、2命令発行が非常に限られていたことは確かであるため、GT200で何らかの改善が行なわれたのは確かだ。考えられる要素はいくつかある。
例えば、レジスタファイルのアクセス帯域が、SPのFMADと、SFUのFMULをフルに回すと足りなかった可能性がある。G80のレジスタは1パーティション毎に4オペランド/サイクルなので、この問題は大きい。だとすれば、GT200でレジスタ帯域を改善すれば、SPのFMADとSFUのFMULの並列実行が改善されることになる。
NVIDIAのアーキテクトはいずれも、プロセッサのマイクロアーキテクチャで大きな変更は行なわなかったと言っている。そのため、GT200での2命令発行の変更は、命令発行アーキテクチャの改革といった大規模なものではなく、こうした小幅な改良である可能性が高い。
ちなみに、NVIDIAはSPと倍精度演算ユニット(DP)の間の2命令発行についても、「条件が合えば」という微妙な言い方をしている。DPは32bitレジスタを2個組み合わせて使うため、レジスタ帯域は2倍必要になる。ただし、8サイクルスループットで、8個のレジスタファイルに交互にアクセスすると推測される。NVIDIAがレジスタ帯域を拡張したとしたら、それは倍精度サポートのためでもある可能性が高い。
●スレッドレベルの並列性にフォーカスしたアーキテクチャ
NVIDIAの2命令発行が、推測したような仕組みを取っているとすると、並列に実行する2命令の組み合わせには、論理的には制約がないことになる。warpスケジューラによって、異なるスレッドの異なる命令を発行するため、命令間の依存性による制約が原則としてはない。データレベルの並列性(DLP:Data-Level Parallelism)も命令レベルの並列性(ILP:Instruction-Level Parallelism)も一切活用しない、純粋にスレッドレベルの並列性(TLP:Thread-Level Parallelism)にフォーカスしたアーキテクチャだと言える。原理的には、オールラウンドに高いスループットを実現できるアーキテクチャだ。
また、この命令発行のメカニズムは、倍精度と単精度の混合精度(Mixed Precision)モデルにも向いている。倍精度が独立した専用ユニットで、論理的には同時命令発行が可能であるため、単精度演算と平行して倍精度演算を行なうことができるためだ。現実には命令発行メカニズム自体ではなく、他の制約のために並列発行できないケースがあるようだ。しかし、G80アーキテクチャの2命令発行の原理が推測通りなら、NVIDIAが将来に渡って改良を続ければ、制約なく倍精度と単精度の並列演算も行なえるようになる可能性もある。
G80/GT200のプロセッサコアを概観すると、こうした細部の仕組みが、GPUという制約の中で汎用コンピューティング向けに作られていることがよくわかる。
□関連記事
【7月2日】【海外】NVIDIAのGT200とAMDのRV770のどちらが優れているのか
http://pc.watch.impress.co.jp/docs/2008/0702/kaigai451.htm
【6月26日】【海外】Radeon HD 4800の高パフォーマンスの秘密
http://pc.watch.impress.co.jp/docs/2008/0626/kaigai450.htm
【6月20日】【海外】GeForce GTX 280の倍精度浮動小数点演算
http://pc.watch.impress.co.jp/docs/2008/0620/kaigai449.htm
【6月19日】【海外】GT200コアでHPCの世界を狙う「Tesla」
http://pc.watch.impress.co.jp/docs/2008/0619/kaigai448.htm
【6月17日】【海外】AMDが1TFLOPS GPU「Radeon HD 4800」ファミリをプレビュー
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai447.htm
【6月17日】【海外】NVIDIAの1TFLOPS GPU「GeForce GTX 280」がついに登場
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai446.htm
(2008年7月7日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.