 |


■後藤弘茂のWeekly海外ニュース■NVIDIAの1TFLOPS GPU
|
●GPUコンピューティング用Tesla T10Pでは1TFLOPS
NVIDIAが、新たなハイエンドGPU「GeForce GTX 200(GT200)」シリーズを発表した。GT200アーキテクチャの最大の特徴は、1TFLOPSの浮動小数点演算(単精度)パフォーマンスを達成すること。グラフィクス製品「GeForce GTX 280」は1TFLOPSを切るが、同じチップを使うGPUコンピューティング向け製品「Tesla(テスラ) T10P」プロセッサは1.5GHz動作で1TFLOPSを超える。1Uラックに4TFLOPSが収まる。スーパーコンピュータの世界だったTFLOPSレベルパフォーマンスに、フルプログラマブルGPUがついに到達した。
 |
| GT200の概要 |
 |
| 新旧製品の比較 |
 |
| GeForce GTX 260の概要 |
GT200は、アーキテクチャ的にはG8x/9x(GeForce 8/9)を継承発展させている。G80のパフォーマンスと機能拡張版がGT200だ。G8x/G9xは、高いスループットと柔軟性によって、グラフィックス市場で成功しただけでなく、汎用コンピューティングでも波に乗りつつある。NVIDIAは、パフォーマンスを倍増させ、機能を強化したGT200で、その流れを加速しようとしている。NVIDIAの、「グラフィックスを足がかりに、汎用コンピューティングの世界に伸ばす」戦略の第2段階を担うのがGT200だ。
NVIDIAは、G8x/G9xでの汎用コンピューティングのために、新しいプログラミングモデル「CUDA(クーダ:compute unified device architecture)」を導入した。今回のGT200に合わせて、NVIDIAはCUDAも2.0に発展させる。CUDA 2.0では、マルチコアCPUへCUDAモデルの適用(コンパイルでCPUコードを生成)といった、戦略発展が行なわれる。現在のNVIDIAでは、GPUハードとCUDAの進化が両輪で進展している。
 |
| CUDA 2.0までのロードマップ |
G8xアーキテクチャ自体のコードネームは「Tesla(テスラ)」で、そのコードネームはそのままGPUコンピューティング製品ブランド名に転用された。今回のコードネームGT200は「GeForce/Tesla 2nd Generation」を意味する。G8x/9x系をGT1xx世代と見なした命名だ。
G80アーキテクチャの名称がTeslaであることは、NVIDIA自身が、雑誌「IEEE Micro」掲載の論文「NVIDIA Tesla: A Unified Graphics and Computing Architecture」(IEEE Micro March April 2008(Vol. 28, No. 2))の中で明かしている。また、4月16~18日に横浜で開催されたプロセッサカンファレンス「CoolChips XI」で、GPUコンピューティングの講演を行なったKevin Skadron氏(University of Virginia Dept. of Computer Science LAVA Lab/NVIDIA Research)も、G8xアーキテクチャをTeslaアーキテクチャと呼んでいた。
●プロセッサ数を従来の128個から240個へと増強
GT200では、500GFLOPSクラスだったG80/92(GeForce 8800/9800)世代から、演算性能を2倍近くに上げるため、内部ストラクチャを一新。スカラプロセッサ「SP(Streaming Processor)」の数を、従来の128個から240個へと1.875倍に増やした。全体のコンフィギュレーションは、一般的な表現に従うと「240:80:32」となる。「シェーダプロセッサ数/テクスチャユニット数/レンダーアウトプットユニット数」の構成だ。前世代のトップエンドだったGeForce 8800(G80)は「128:64:24」だった。
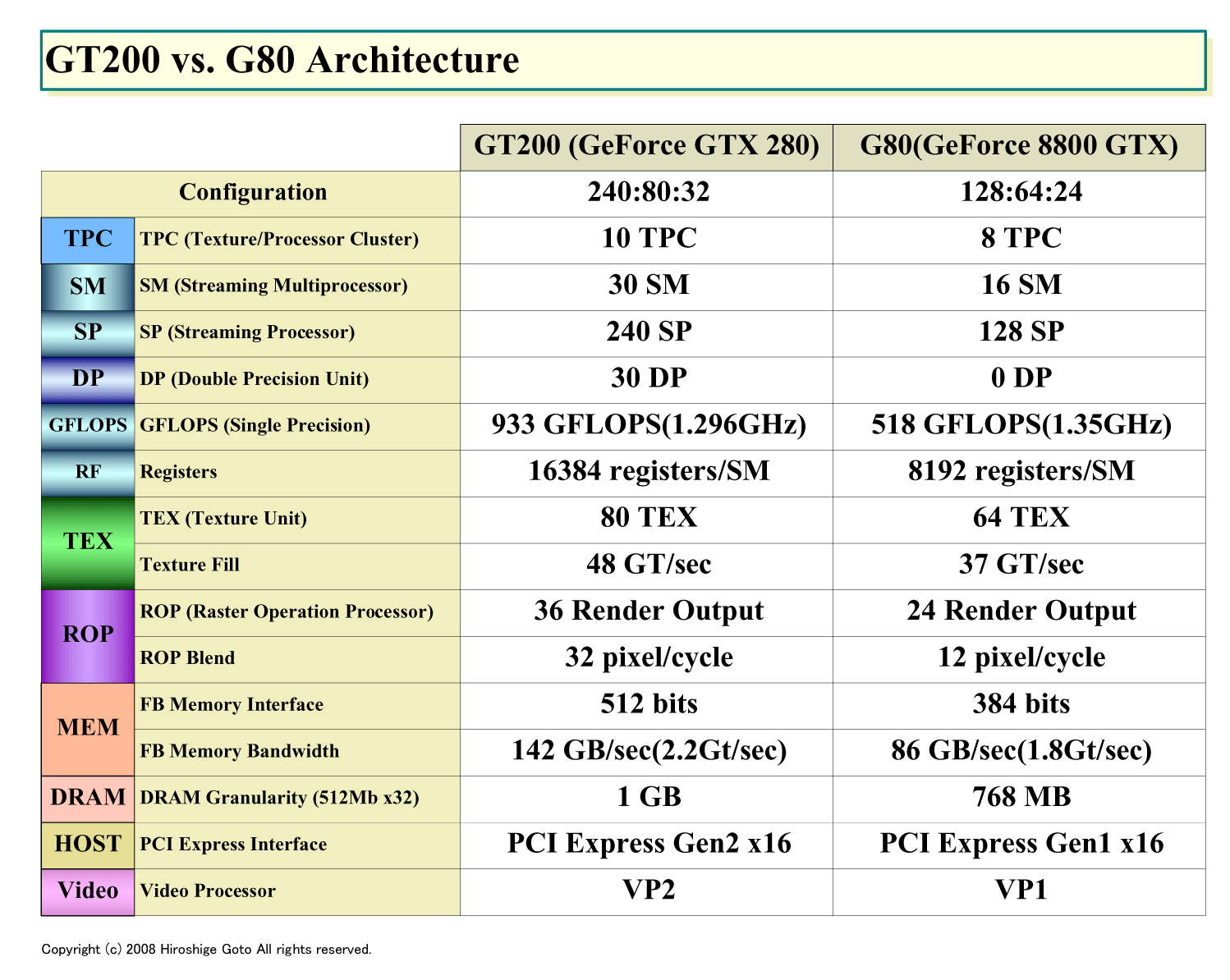 |
| GT200とG80の比較 (PDF版はこちら) |
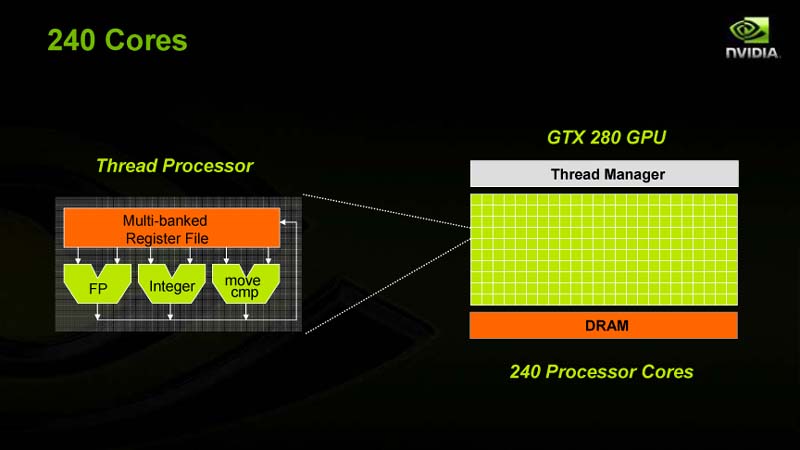 |
| 240個のSPを搭載 |
シェーダコアクロックはトップエンドグラフィックスのGeForce GTX 280で1.297GHz、1UラックマウントサーバーのTesla S1070で1.5GHzと、従来世代と変わらないレベル。ただし、今世代ではプロセッサコアは、パフォーマンスの高いカスタムロジック回路設計(従来はASICロジック)を行なったため、まだ周波数向上の余裕があるという。
NVIDIAは、GT200ではプロセッサ内のレジスタ数の倍増や、不揃いなデータアクセスの高速化など、GPUコンピューティングのための機能も充実させた。そのため、GPUコンピューティングの性能は2倍以上(NVIDIAによる)になり、シェーダプロセッシングがヘビーになった最新の3Dグラフィックスの性能も大幅に伸びた。
また、NVIDIAはGT200から、これまで対応して来なかった倍精度(64-bit)浮動小数点演算もサポートした。グラフィックス処理では単精度(32-bit)までの浮動小数点演算しか必要とされないため、伝統的なGPUは倍精度をサポートして来なかった。GT200は、倍精度FPUを合計30個搭載することで、倍精度の必要から、これまでGPUがカバーできていなかったアプリケーションにも対応できるようになった。「倍精度は、GPUコンピューティングの顧客からの要請されていた重要リクエストの最後の1つ。これで、ようやくチェックマークが揃った」とあるNVIDIA関係者は言う。
NVIDIAは、高いスループットのG80/92系アーキテクチャとプログラミングモデルCUDAによって、ハイパフォーマンスコンピューティング(HPC)分野に足がかりを作った。GPUを、汎用的な並列処理に使うGPUコンピューティングを成功させるためには、倍精度のサポートは欠かせない要素だった。実際に、Teslaユーザーからは、倍精度サポートでこれまで移植できなかったアプリケーションがポートできたことが報告された。
ただし、Tesla T10Pでも倍精度浮動小数点演算パフォーマンスは90GFLOPSと、単精度の12分の1の性能。GPUが依然として単精度にフォーカスしたプロセッサである点に変更はない。最大に性能を発揮できるのは、倍精度も使うが、単精度がどちらかと言えば比重が高い、精度混合のアプリケーションだ。
●Geometry Shaderのスループットを強化
グラフィックス処理では、AMDに対して弱かったGeometry Shaderのパフォーマンスを大幅に改善。実用レベルに向上させた。また、「ROP (Raster Operation Processor)」でのブレンディング処理の向上などが果たされた。全体で見ると、グラフィックスに特化した改良点は小さく、プロセッシング面の拡張が目立つ。DirectX 10世代では、シェーダプロセッシングに偏重するため、プロセッシングの改良によってコンピューティング性能だけでなく、グラフィックス性能も押し上げるという判断だ。
プロセッシング面の拡張に対して、比較的穏やかなのはメモリ回りの拡張だ。DRAMインターフェイス幅はG80世代の384 bitsから512 bitsへと拡張された。サポートメモリタイプはGDDR3/DDR2で同じ。GDDR3 DRAM自体が2214Mt/secへと高速化したため、メモリ帯域はGeForce GTX 280で141.7GB/secと、GeForce 8800 GTXの86.4GB/sec(1,800Mt/sec)より大きく伸びた。しかし、純粋にアーキテクチャ面だけを見ると、拡張は1.33倍となる。おそらく、内部バスもこれに比例した拡張に留まると推定される。ROP数もメモリインターフェイス幅に比例して1.33倍に、テクスチャユニット数はG80の64レンダアウトプットから80になった。
G80の「128:64:24」から、GT200の「240:80:32」への発展が示しているのは、メモリインターフェイスとそれに依存するROP/テクスチャの拡張は1.25~1.33倍と抑え、プロセッシングは1.88倍と大きく拡張したことだ。バランス的にプロセッシングに偏重している。メモリ帯域の拡張は難しく、プロセッシングの拡張は相対的に容易であるという、現在のプロセッサ設計の事情を象徴している。
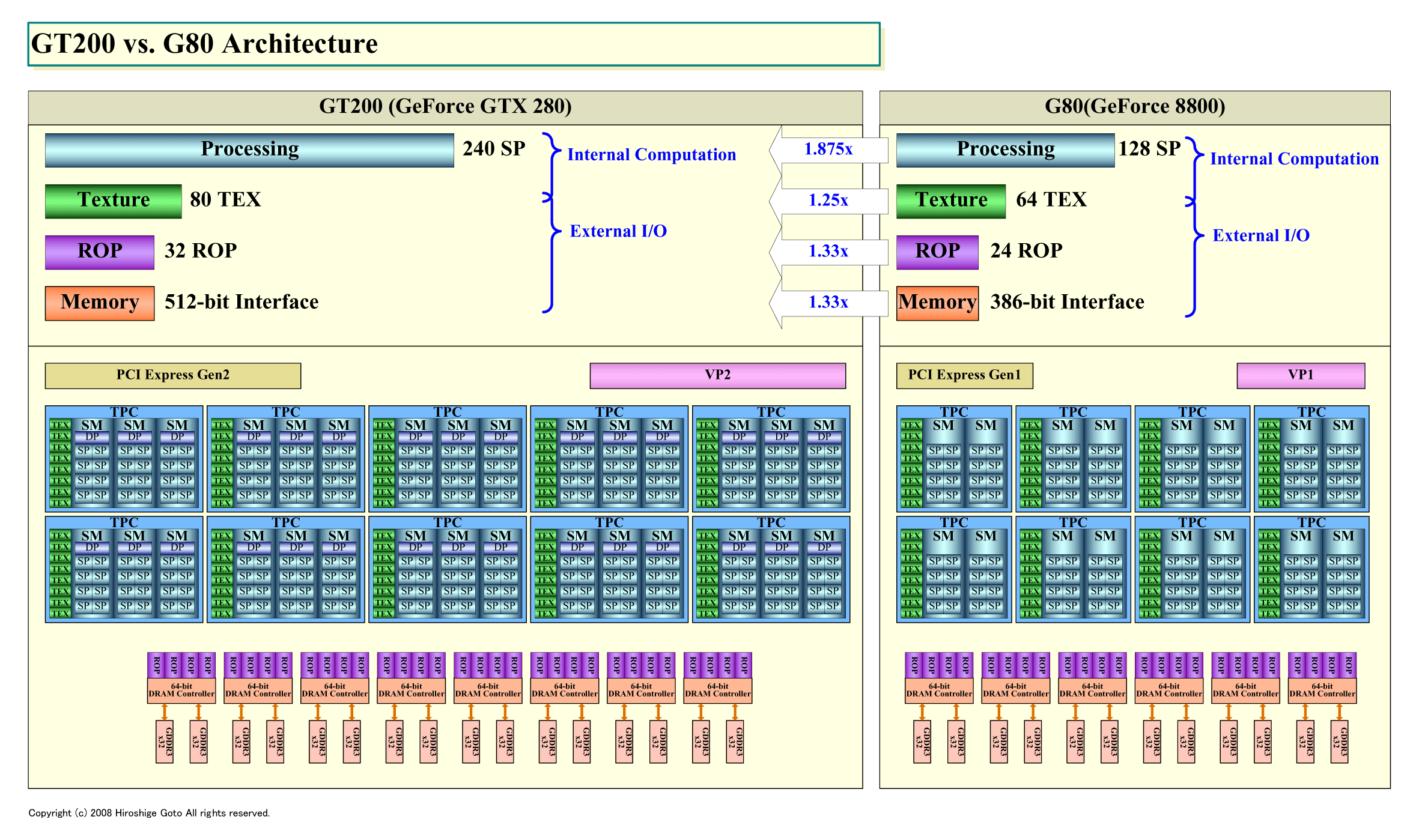 |
| GT200とG80プロセッサ構成比較 (PDF版はこちら) |
このほか、ホストバスであるPCI ExpressはGen2に、ビデオ処理プロセッサは第2世代の「VP2」となった。これはG92世代と同等だ。
G80/92に対して大幅に性能と機能を強化した結果、GT200は巨大チップとなった。TSMC 65nm CMOS技術でトランジスタ数は1.4 Billion(14億)、ダイサイズ(半導体本体の面積)は600平方mmに近づいた。90nmのG80の681 Million(6億8,100万)トランジスタ、470平方mmダイからさらに大型化し、露光の1ショットの限界(半導体製造の露光工程でのチップサイズの制約の目安)にひたひたと迫りつつある。NVIDIAのTony Tamasi(トニー・タマシ)氏(Vice President, Technical Marketing)は、「TSMCが過去製造した中で最大のサイズのチップ」と語る。巨大シングルダイから、デュアルダイ路線へと転換したAMD(旧ATI)とは対照的に、NVIDIAはハイエンドGPUの巨大化を続けている。
 |
| GT200のウエハ |
 |
| GT200のダイ写真 |
●GPUのストラクチャを変更
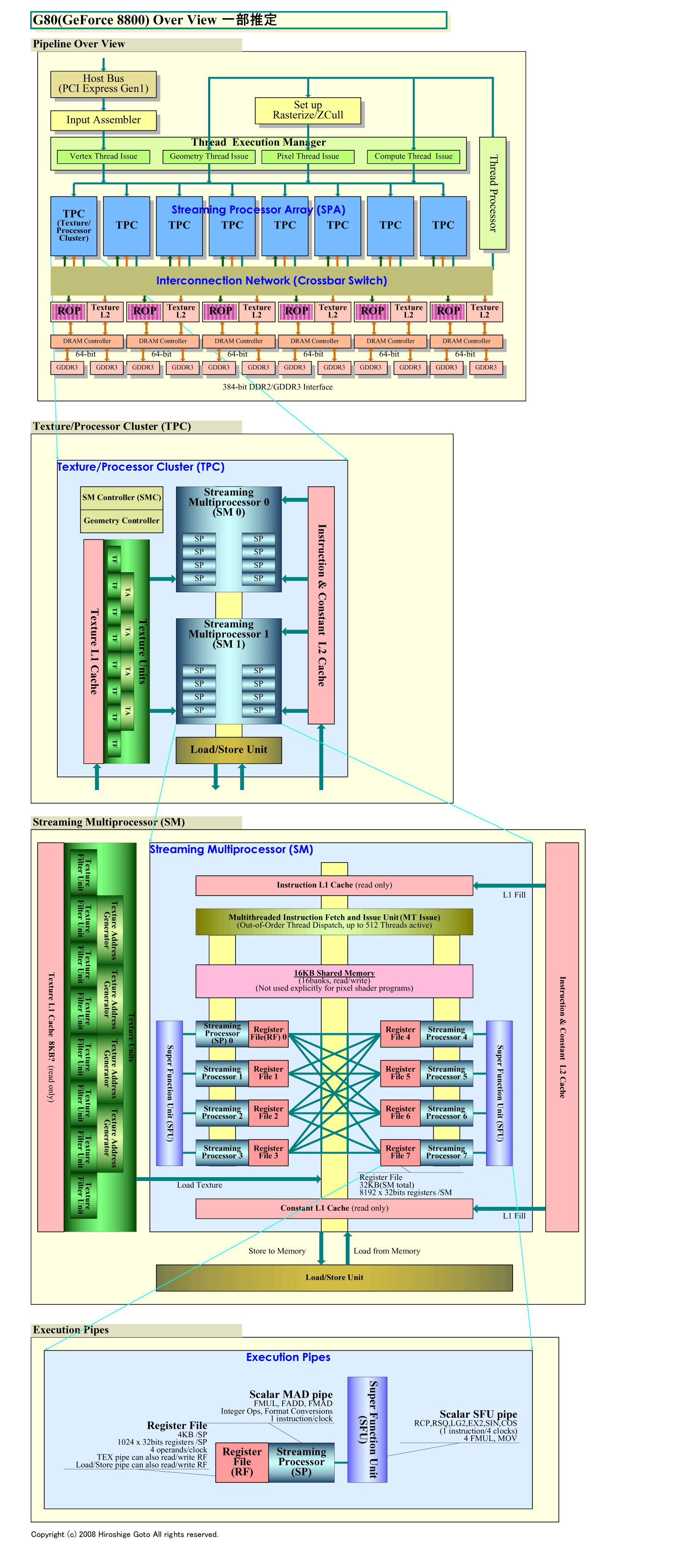
下の図がGT200(GeForce GTX 280)のブロックダイアグラム図と、比較用のG80のダイアグラム図だ。GT200のチャートは、NVIDIAの公開したG80アーキテクチャの図をベースに、今回のGT200発表の拡張部分や、最新のNVIDIAの論文やプレゼンテーションにあった内容を加えた。そのため、一部は推定となっている。
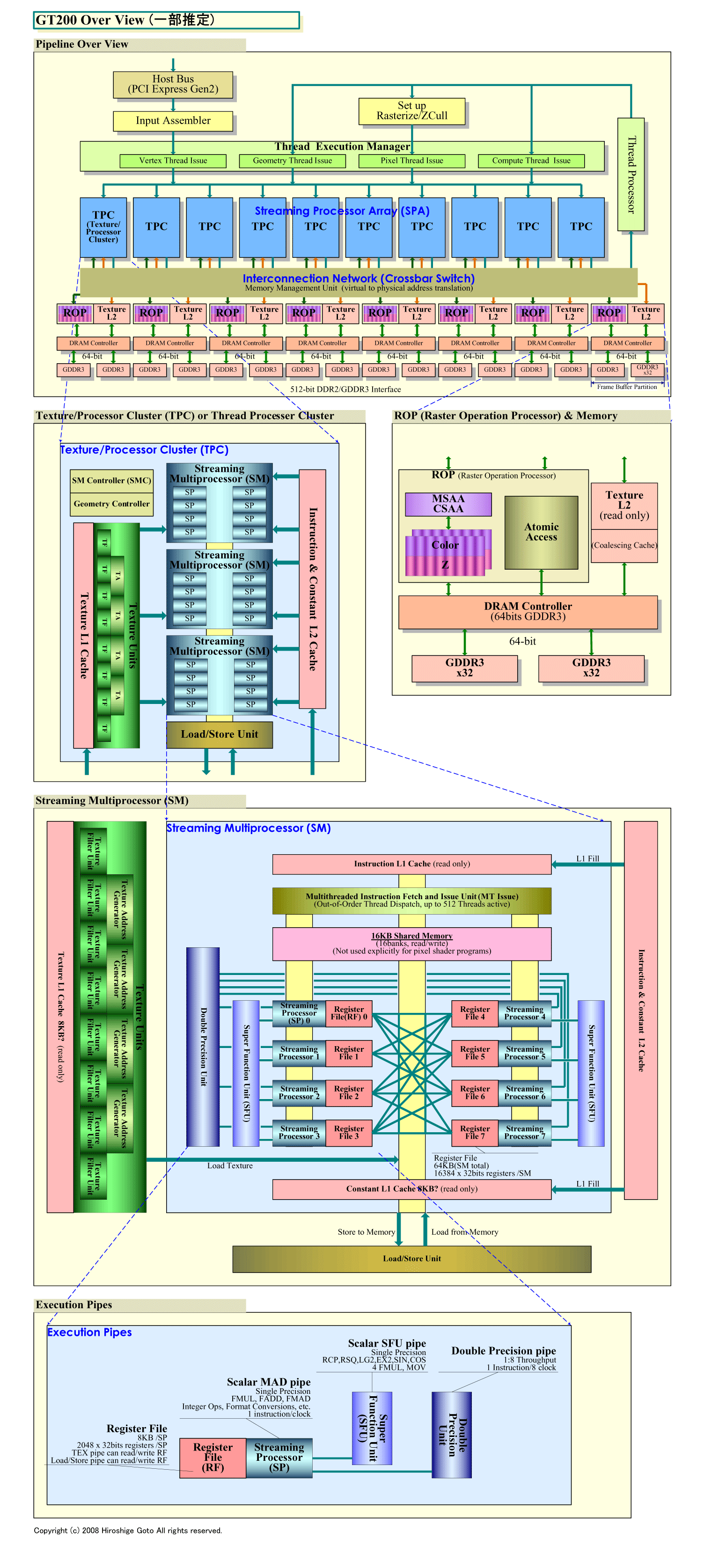 |
| GT200のオーバービュー (PDF版はこちら) |
 |
| G80のオーバービュー (PDF版はこちら) |
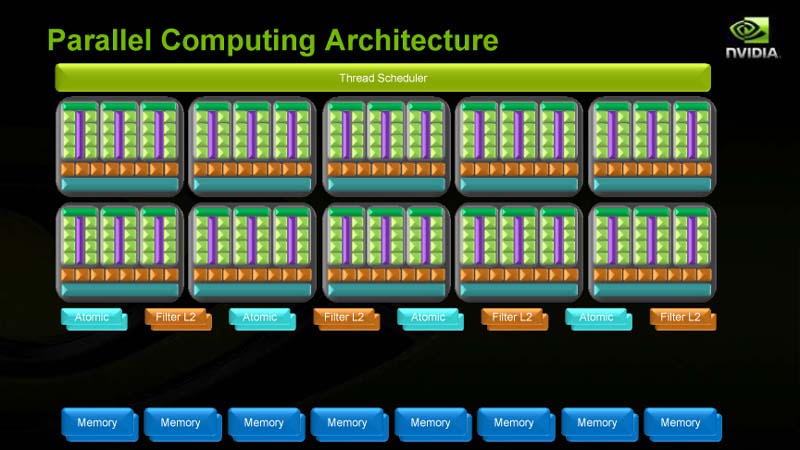
NVIDIAは今回、非常に簡略な下のスライドのような構成図しか示していない。左がGPUコンピューティングモード時の機能構成、右がグラフィックスモード時の機能構成だ。微妙にユニットの使い方が異なっている。
 |
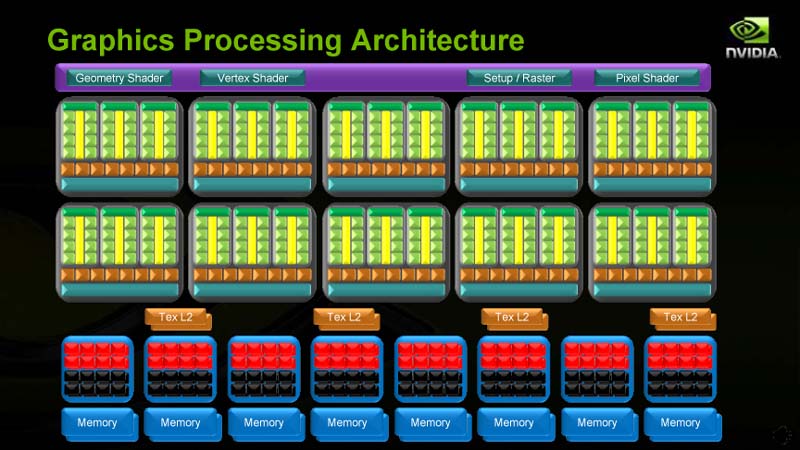 |
| GPUコンピューティングモード時の機能構 | グラフィックスモード時の機能構成 |
ブロックダイアグラム図を見てわかる通り、NVIDIAは、GT200で、GPUのシェーダプロセッサアレイである「Streaming Processor Array (SPA)」フレームワークの内部構成を変更した。
NVIDIAのG8x以降のGPUは、単精度浮動小数点演算/整数演算のスカラプロセッサ「SP(Streaming Processor)」を単位としている(SPをThread Processorと呼ぶ場合もある)。8個のSPと周辺ユニット群を1個のバンドル「SM(Streaming Multiprocessor)」にまとめて管理する仕組みだ。従来のG8x/9xアーキテクチャでは、2個のSMと1個のテクスチャユニット(Texture Unit)でクラスタ「TPC(Texture/Processor Cluster)」(Thread Processor Clusterと呼ぶ場合もあり)を構成している。各TPC当たり、16個のSPと8個のテクスチャフィルタリングプロセッサ(Texture Filtering Processor)を内包する。G80では、8個のTPCを搭載し、合計128個のSPを搭載していた。
それに対して、GT200では、8個のSPで1個のSMを構成する点は同じだが、TPCの中のSMの数は2個から3個へと増やされている。また、全体のTPCの数も8個から10個へと増やされた。そのため、合計のSP数は240へと増えた。
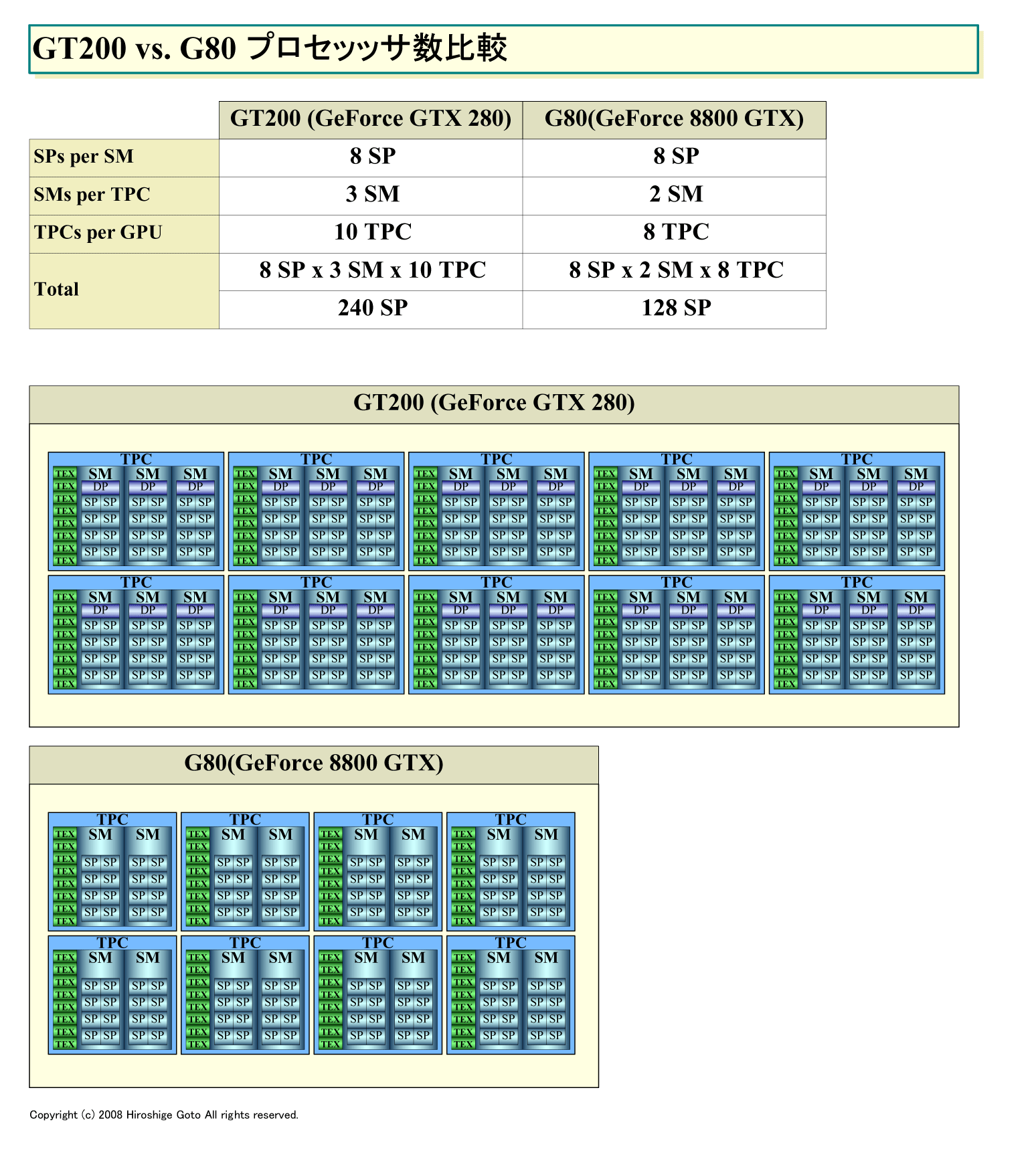 |
| プロセッッサ数比較 (PDF版はこちら) |
●ノードの増加を抑えたGPUの設計変更
NVIDIAがTPCの数の増加を抑え、TPC内のSMの数を増やした理由の1つは、テクスチャとコンピュテーションの比率を変え、よりコンピュテーションインテンシブに編成し直すためだ。従来は、SMの中はSPが16個に対してテクスチャプロセッサは8個で、2対1の比率だった。GT200ではそれが24個に対して8個と、プロセッシング3対テクスチャ1に変わる。それだけ、メモリアクセスが減り、プロセッサ内部での演算の比率が高まると見ている。
TPCの構成を変えたもう1つの理由は、内部バスの複雑度の増加を抑えるためだと推測される。NVIDIAアーキテクチャでは、各TPCと各メモリパーティションがクロスバー接続されている。そのため、内部配線は極めて密集して複雑な状況になっていると推定される。あるGPUベンダーの技術者は、GPU設計で最も難しいのはクロスバーだと語っていた。AMDはそのために、内部にリングバスを採用している。しかし、リングバスのオーバーヘッドを嫌ったNVIDIAは、クロスバーを継続して使っている。
リングバスでは、内部バスに接続するノード数を増やすことは比較的容易だ。しかし、クロスバーでは複雑度を抑えなければならないため、ノード数を増やすことが難しい。NVIDIAはそのためにTPCを15個にするのではなく、10個にする設計を選んだと推定される。
今回、NVIDIAはGT200のダイ(半導体本体)写真と、大まかなダイレイアウトも公開した。レイアウト図を参考に、ダイ写真上に各機能ユニットの区分を示したのが下の図だ。NVIDIAが示したレイアウトは非常に大まかなものなので、一部は、ダイ写真上のパーティションを参考に推定を加えている。そのため、NVIDIA提供のものと較べるとブロックの形などが異なる部分もある。
また、NVIDIAは、IEEE Microのアーティクルの中でG80の大まかなダイレイアウトを公開している。それを参考にダイ写真上に各機能ユニットの区分を示したのが下のG80の図だ。こちらも、一部に推定を加えている。
次回は、GT200の各プロセッサエレメントの内部構造をレポートしたい。
 |
| GT200のダイレイアウト |
 |
| GT200のダイレイアウト (PDF版はこちら) |
 |
| G80ダイレイアウト (PDF版はこちら) |
□NVIDIAのホームページ(英文)
http://www.nvidia.com/
(2008年6月17日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.