 |


■後藤弘茂のWeekly海外ニュース■GeForce GTX 280の倍精度浮動小数点演算 |
●倍精度浮動小数点演算の4つのポイント
NVIDIAは、CUDAとG80アーキテクチャによって、ハイパフォーマンスコンピューティング(HPC)である程度の成功の足がかりを掴んだ。そうしたNVIDIAにとって、倍精度浮動小数点演算のサポートは、欠かせない要素だ。HPCのアプリケーションでは、倍精度が必要となる局面があるからだ。GPUコンピューティング向けのTesla製品では、倍精度演算はカギとなると言ってもいい。「これまでも、倍精度の壁によって移植できなかったアプリケーションがかなりあった」とNVIDIAは必要性を強調する。
問題は、現状のリアルタイムグラフィックスでは、単精度(32-bit)までの浮動小数点演算しか必要とされないこと。そのため、これまでのGPUは単精度演算ユニットしか実装しておらず、GPUでの倍精度演算のサポートには、いくつかのポイントと疑問点がある。
(1)IEEE 754準拠。これは、汎用アプリケーションで実用になる機能かどうかの重要な分岐点となる。
(2)倍精度の実装方式と性能。GPUにとっては追加的な実装となる倍精度演算ユニットが実用的な性能に達しているかどうか。
(3)単精度と倍精度の性能比率。これは、実際のアプリケーションがどの程度のバランスを必要としているかという問題と絡む。
(4)実装コスト。倍精度の実装によってNVIDIAのGPUコアの他の機能が犠牲にされているかどうかも問題だ。
●IEEE 754準拠のフィーチャーリストを公開
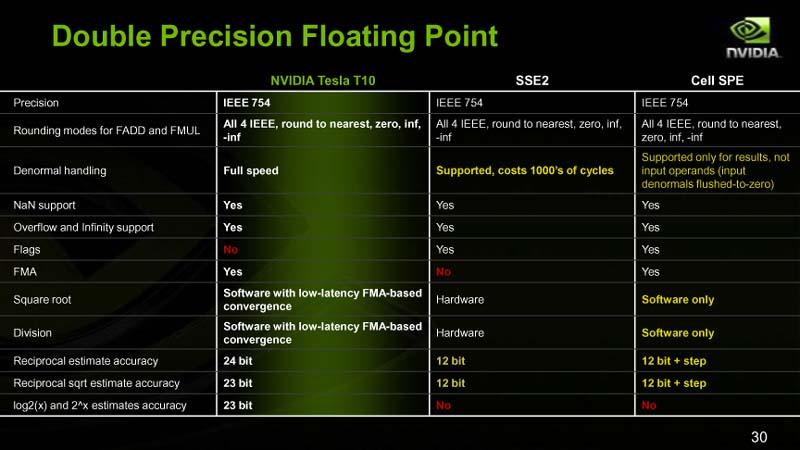
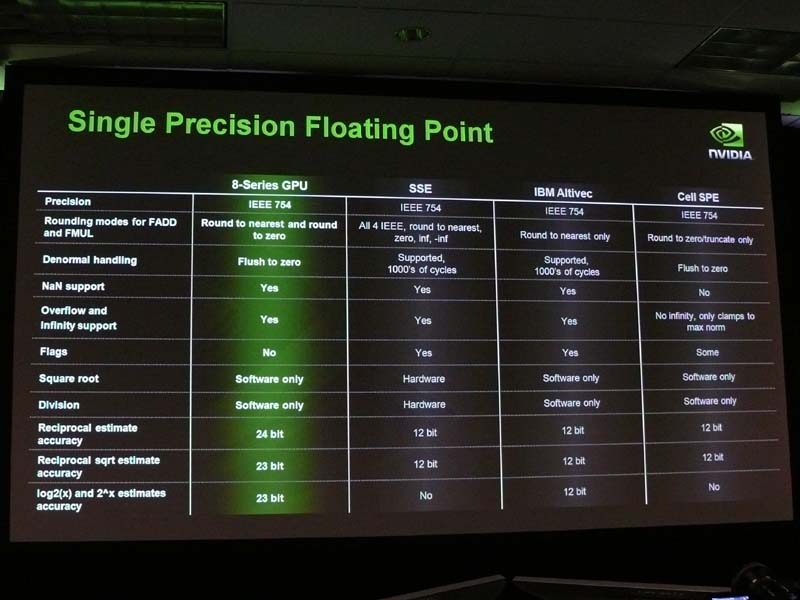
(1)IEEE 754準拠についてはNVIDIAは、下のような倍精度演算と単精度演算のフィーチャーリストも提示。IEEE 754にほぼ準拠していることを強調した。特に、Intel SSEやCell Broadband Engine(Cell B.E.)といった、他のSIMD浮動小数点演算アーキテクチャと比較して、IEEE 754サポートで同等レベルにあることを強調した。
NVIDIAがリストを示してIEEE 754を謳うのは、GPUの倍精度演算はIEEE 754に準拠しておらず、実用にならないという憶測を打ち消すためだ。フィーチャリストのうち白はハードウェアサポート、イエローがソフトウェアサポート、レッドが非サポートを示す。GT200ではほとんどがホワイトだが、Flagがレッドの非サポートとなっている。
「我々は、(必須項目ではないものも含めて)最も広いサポートを行なっている。例外は『Flag』だ。なぜなら、Flagは、浮動小数点演算プロセッサが、整数演算のCPUとは分離されたコプロセッサだった時代の遺物だからだ。浮動小数点コプロセッサでは、CPUがファイナルワークのflagを読む必要があった。しかし、(整数演算と浮動小数点演算がワンチップになった)モダンアーキテクチャでは、もはや不要のものだと判断した」とNVIDIAのSumit Gupta氏(Sr. Product Manager, Tesla GPU Computing, NVIDIA)はその理由を説明する。
Flagをサポートしない一方で、CPUでも低速な「Denormal handling」をGT200はフルスピードで実行できる。SSEに欠けている積和演算(FMAD)も1サイクルスループットでサポートする。ただし、1ユニットを8スレッド/サイクルで共有するため、命令発行後は8サイクル次の命令発行ができず、個々のスレッドから見ると8サイクルスループットに見える。
NVIDIAの倍精度演算ユニットのフィーチャが実用的なスペックかどうかは、アプリケーションデベロッパが判断を下すことになるが、すでに試用しているデベロッパはフィーチャに問題がないと語っていた。
 |
| 倍精度演算のフィーチャリスト |
 |
| 単精度演算のフィーチャリスト |
 |
| 倍精度演算の概要 |
●8個の単精度ユニットに対して1個の倍精度ユニット
(2)倍精度の実装では、NVIDIAは、倍精度浮動小数点演算の専用ユニットを1個、演算ユニットのバンドルであるStreaming Multiprocessor(SM)に実装した。つまり、GPUに新たに新しいユニットを加えている。
NVIDIAは、単精度浮動小数点演算ユニットを複数個並列または2パスで使い、倍精度浮動小数点演算を実行する実装方法は取らなかった。「SP(単精度プロセッサ)を使って2パスで実現する方法では、充分な性能を得られないと判断した」とNVIDIAのTony Tamasi(トニー・タマシ)氏(Vice President, Technical Marketing)は説明する。
これは、既存の単精度演算ユニットを利用する方法で、先に倍精度サポート製品を出荷したAMDを牽制した発言だ。次回に詳しく説明するが、NVIDIAアーキテクチャでは、複数個のSPを組み合わせて倍精度演算を実行させる方法は、AMDアーキテクチャに較べると難しい。1個のSPで2パスで実行させる方法は、NVIDIAアーキテクチャでも可能だが、その場合はレイテンシが長くなり、単精度演算の性能が削がれてしまう。
GT200では、この実装方法の結果、倍精度浮動小数点演算のピーク性能は、プロセッサコアクロックが最高1.5GHzの「Tesla(テスラ) T10P」で、90GFLOPSとなった。これは、T10Pの単精度ピーク性能の1.08TFLOPS(SP+SFUの性能)の12分の1。GT200コアのメインのプロセッサであるStreaming Processor(SP)の単精度演算能力との比率では1:8だ。90GFLOPSは、Intelクアッドコアと較べると約40%増し。CPUより上と言えば上だが、ダイサイズ(半導体本体の面積)や電力消費を考えると、決していい数字ではない。つまり、倍精度演算だけをやらせるプロセッサとしては、GT200は向いていない。そこで重要となるのは、アプリケーション側が単精度と倍精度をミックスさせることだ。
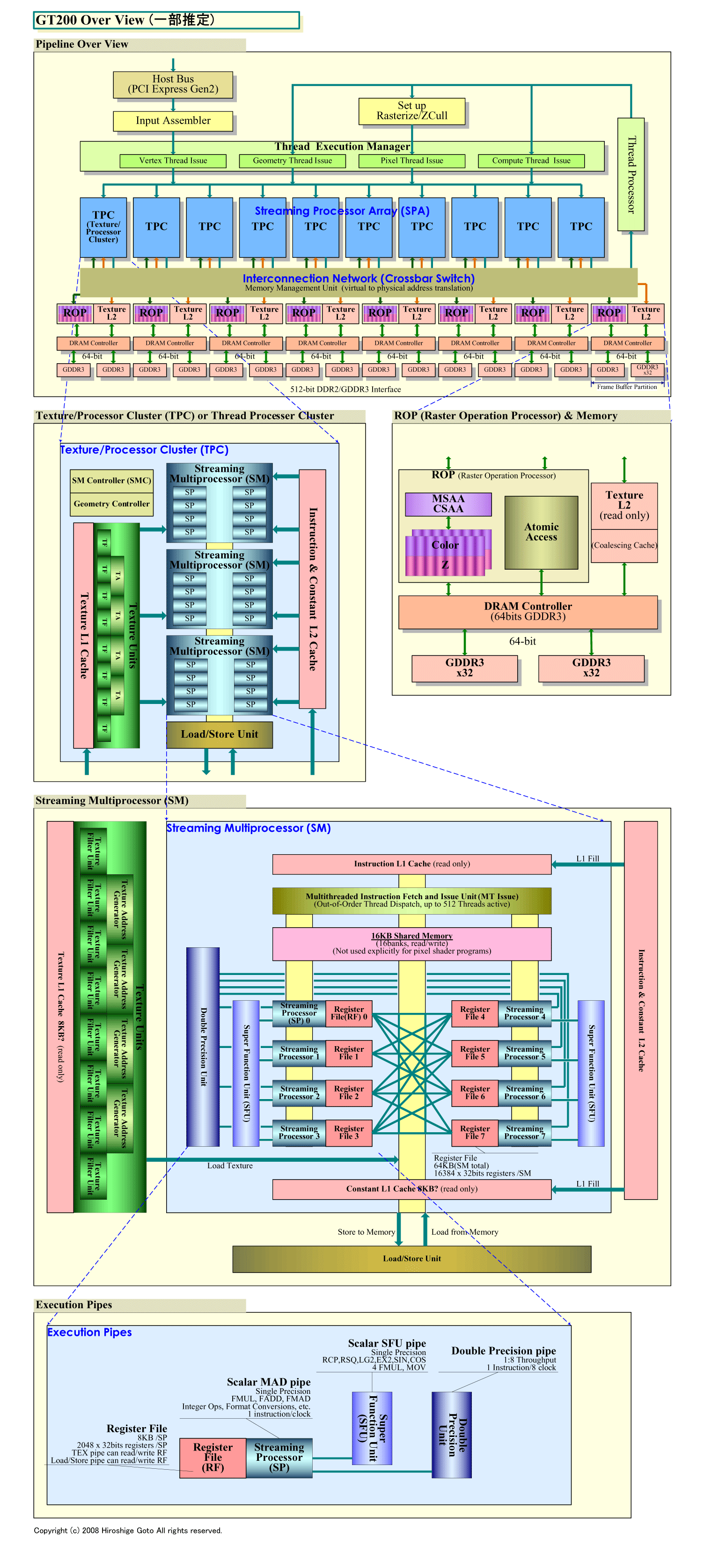 |
| GT200のオーバービュー (PDF版はこちら) |
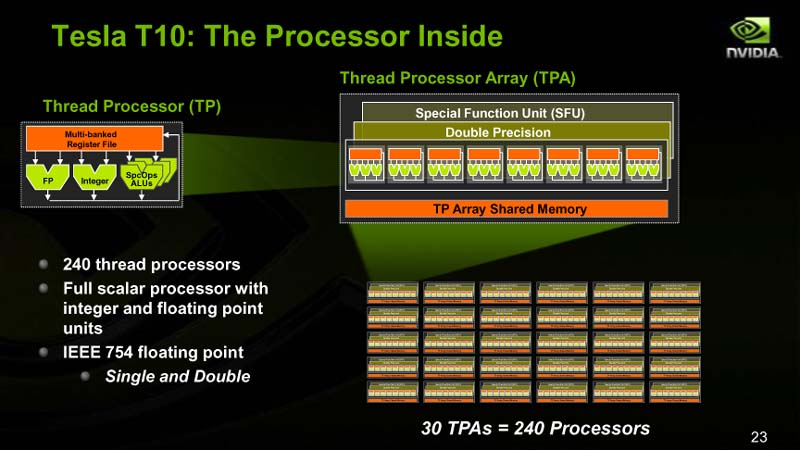 |
| Telsa T10のプロセッサ構成 |
●単精度と倍精度をミックスするアプリケーションへ
(3)単精度と倍精度の性能比率は、これから先のクエスチョンとして浮かび上がって来た。
NVIDIAは、最高パフォーマンスは単精度で稼ぐが、一定レベルのパフォーマンス倍精度もサポートすることで、混合精度のアプリケーションを促そうとしている。CPUでも、SIMD化によって単精度浮動小数点演算の方が、倍精度よりピークパフォーマンスが2倍も高い。そのため、精度の混合というアイデア自体は現実的だとNVIDIAは見ている。
この発想はAMDも同じだが、NVIDIAの場合は倍精度と単精度のピークパフォーマンスの比率は1:12と、より大きく開いている(AMD GPUは1:5)。GT200のメインのプロセッサであるStreaming Processor(SP)の単精度演算能力との比率では1:8だ。SPと倍精度プロセッサは並列に走るので、GT200の倍精度と単精度を同時に走らせた時の性能比は1:8となる。
では、混合精度のアプリケーションで、1:2~1:12までのうち、どの程度の倍精度:単精度のパフォーマンス比が適切なのか。この答えは、まだ出ていない。
そもそも、倍精度演算を必要とするようなアプリケーションは、これまで全てを倍精度で演算するように書かれていることが多かった。しかし、単精度パフォーマンスが突出したGPUというプラットフォームが登場したことで、状況が変わり始めた。
「性能を考えると、(GT200に倍精度ユニットがあっても)全てを倍精度で演算するのはいい考えではない。現実的には単精度と倍精度の混合となるだろう。いくつかのアルゴリズムは単精度で、いくつの倍精度がどうしても必要な部分は倍精度と分担する。主に単精度で演算し、倍精度で助けるといった発想だ」とAndy Keane(アンディ・キーン)氏(General Manager, GPU Computing Business Units)は語る。
実際、現在CUDAで走っているアプリケーションには、元々倍精度で組まれていたものもあるという。そうしたデベロッパは、倍精度から単精度へとアルゴリズムを組み替えるほど、プログラマブルGPUハードウェアのパフォーマンスに魅力を感じていると見える。
「SPICEシミュレータを作ったエンジニアは、倍精度を全てに使う必要があるかどうかを見直した。その結果、最終的にほとんどの部分を倍精度から単精度に移すことができたという。倍精度でなければならない部分も残っているが、それに対しては、今は倍精度のボードを提供できる」とGupta氏は語る。
GPUコンピューティングの話が持ち上がった時、HPCなどの分野では倍精度の性能が必要とされるため、GPUはきわめて限られたエリアでしか受け容れられないと言われた。しかし、NVIDIAは、現在、ミクスド精度化によって、その壁を乗り越えられると見ているようだ。
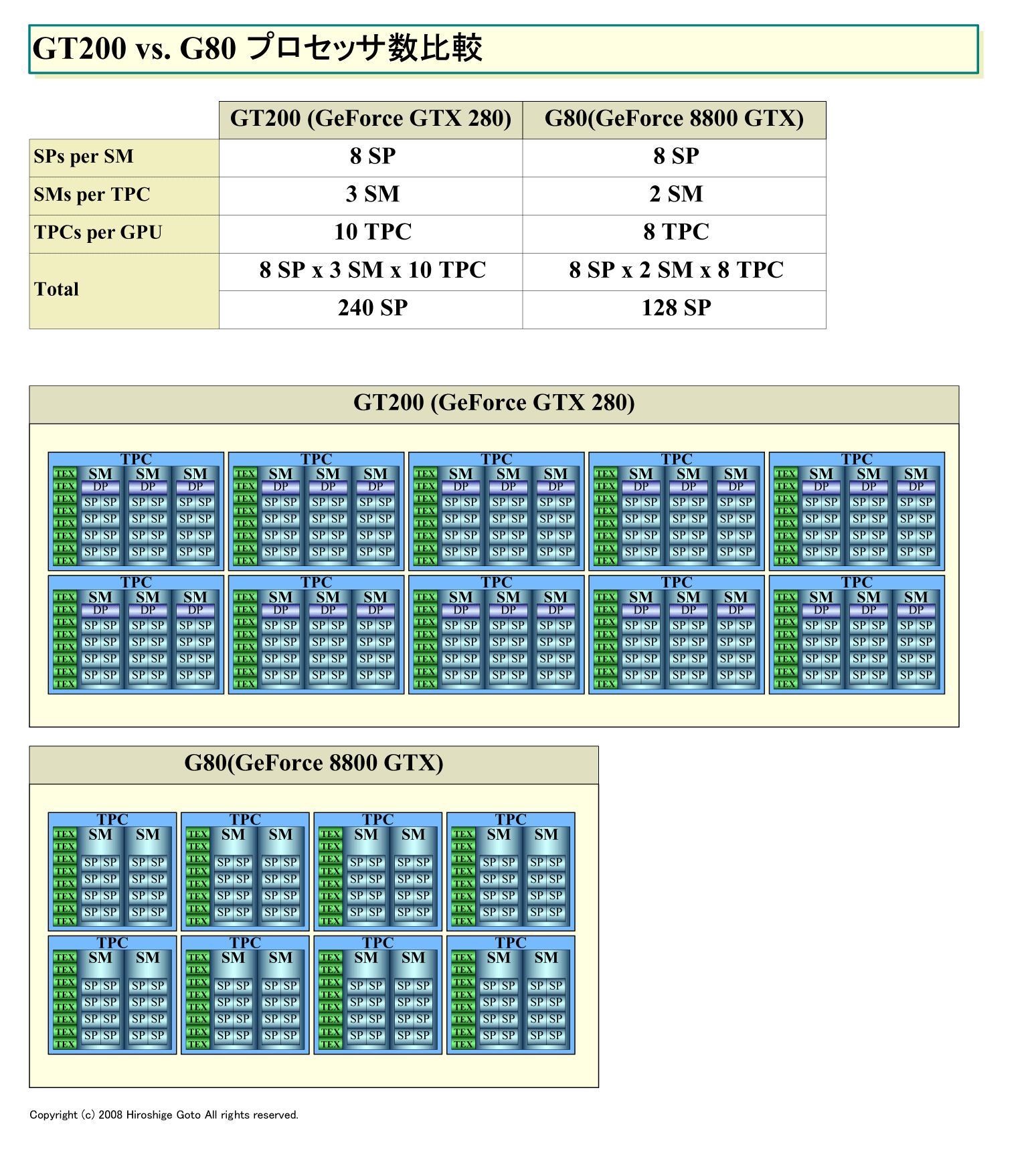 |
| GT200のプロセッサ数 (PDF版はこちら) |
●倍精度演算ユニットのコスト
(4)倍精度演算ユニットは、グラフィックスでは不要な部分であるため、GPUとしては実装コストが重要となる。NVIDIAは、これに対してどれだけのコストを払ったのか。つまり、倍精度ユニットの実装によって、グラフィックス向けの機能ユニットの数がどの程度削られたのか。
チップ上でのコストは、ダイ(半導体本体)上に占める面積で測られる。NVIDIAでGPUのチーフアーキテクトを務めるJohn Montrym氏は、次のように説明する。
「倍精度演算ユニットのサイズは、単精度のStreaming Processor(SP)よりある程度大きい。しかし、さほどではない。Streaming Multiprocessor(SM)の中で占める割合は10%以下に過ぎない」
下は、GeForce GTX 280(GT200)のダイレイアウトだ。この中でStreaming Multiprocessor(SM)はピンク色に見える部分で、ダイ上で四角く区切ったTexture/Processor Cluster (TPC)の片側半分に3段になっている。TPCを引き出し拡大したのが真ん中の図で、TPC 1個はAtomプロセッサを一回り大きくした程度のサイズ(ただしAtomは45nmプロセスで、65nmならTPC 2個弱のサイズとなる)だ。TPCの中のSMを拡大したのが一番下の図だ。倍精度ユニットは、この小さなSMの中で10%以下を占めているという。GPU全体で見れば、非常に小さな比率だ。しかし、エクストラのコストであることも間違いがない。
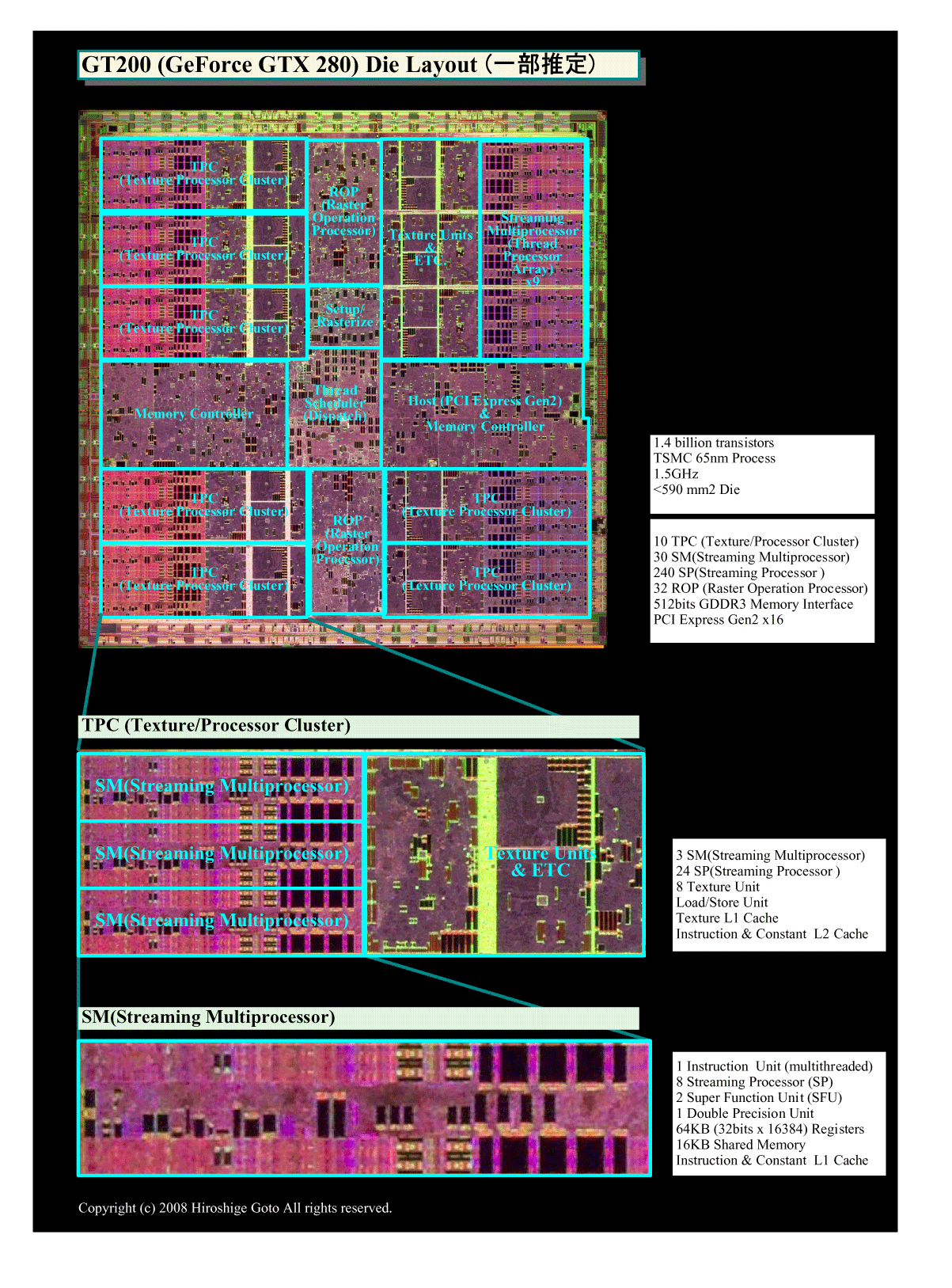 |
| GT200のダイ (PDF版はこちら) |
こうしてGT200アーキテクチャでの倍精度演算の実装を概観すると、それなりのコストは払っているが、実用になりそうな実装であることがわかる。1:12という単精度との性能比も、アプリケーションによっては受け容れられるだろう。NVIDIAとしては、これでGPUコンピューティングの最後のチェックマークを埋めたことになる。
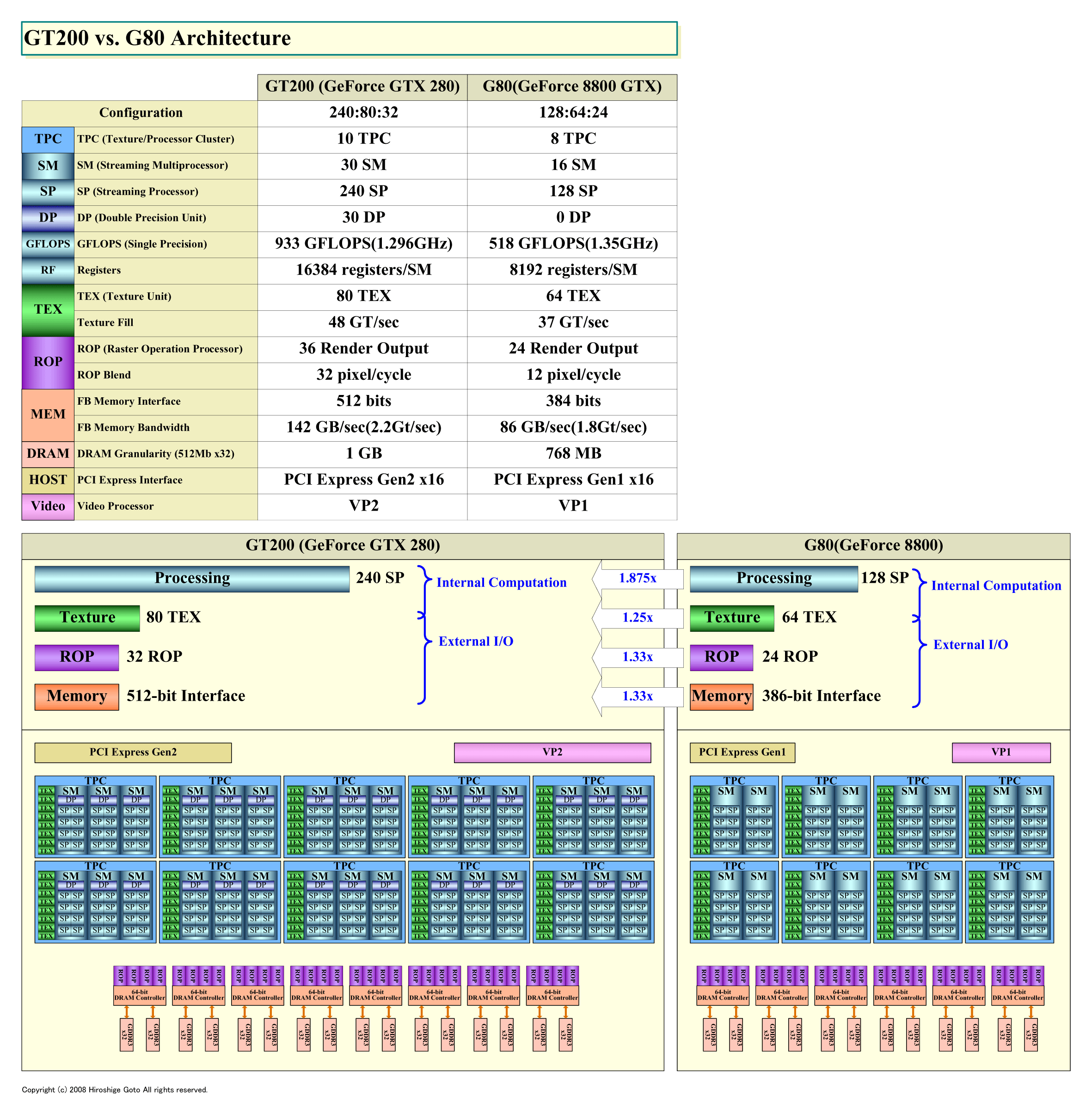 |
| GT200とG80の比較 (PDF版はこちら) |
□関連記事
【6月19日】【海外】GT200コアでHPCの世界を狙う「Tesla」
http://pc.watch.impress.co.jp/docs/2008/0619/kaigai448.htm
【6月17日】【海外】NVIDIAの1TFLOPS GPU「GeForce GTX 280」がついに登場
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai446.htm
【6月17日】AMD、200ドルで1TFLOPS越を実現するRadeon HD 4850を6月25日出荷
http://pc.watch.impress.co.jp/docs/2008/0617/amd.htm
(2008年6月20日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.