 |


■後藤弘茂のWeekly海外ニュース■GT200コアでHPCの世界を狙う「Tesla」 |
●1TFLOPSと倍精度が2つめのステップ
NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、1年半前のGeForce 8800(G80)発表当時、「翌年の後継GPUは、ワンチップで1TFLOPSのパフォーマンスになる」と語っていた。また、1年前のGPUコンピューティング向け製品「Tesla(テスラ)」発表の際は、「我々は、年末(2007年末)までに倍精度浮動小数点演算を実現することを明らかにした。これは、単精度の複合(によるソフトウェアソリューション)ではなく、実際に倍精度のハードウェアになるだろう」と語っていた。
計画は大きくずれ込んだが、NVIDIAは「GeForce GTX 280(GT200)」と「Tesla T10P」で、倍精度(64bits)サポートと、900GFLOPS台~1TFLOPS超のパフォーマンスのGPUを送り出すことができた。同じく1TFLOPSと倍精度を謳うAMDとの競合は熾烈だが、NVIDIAはようやくGPUを進化させるプロジェクトを第2ステップに進めることができる。NVIDIAの汎用コンピューティングプログラミングモデル「CUDA(クーダ:compute unified device architecture)」も、それに合わせてCUDA 2.0へとステップアップする。
倍精度と1TFLOPSは、NVIDIAにとって重要なマイルストーンだ。1TFLOPSは、純粋にパフォーマンスとCPUに対しての10倍のパフォーマンス優位という象徴的な意味のため、倍精度は非グラフィックスアプリケーションの一部が必要とするためだ。
●CPUの変化で狭まる伝統的グラフィックス市場
CPUがGPU統合とデータ並列型演算の強化(AVXやSSE5やLarrabee)へと向かいつつある今、GPUベンダーであるNVIDIAにとっての活路はGPUを汎用的なコンピューティングに利用する「GPUコンピューティング」を花開かせることにある。それに成功しなければ、近い将来にGPUという市場自体が縮小し、NVIDIAが生き残る場所がほとんどなくなってしまう。
NVIDIAにとっては、GPUがCPUより重要なプロセッサとなる必要がある。それも、PCだけでなくサーバーや携帯機器においても、グラフィックス用途だけでなく汎用的なアプリケーションにおいても。同社のビジョンとしては、広汎なアプリケーションでGPUが使われるように持って行きたい。
エンドユーザーが使う一般的なアプリケーションの中で、処理は重いが並列化が可能な部分はGeForceで走らせる。サーバールームには、CPUサーバーと同数のTesla GPUサーバーが入り、並列処理が可能なタスクはTesla上で走らせる。最終的にはTegraのような携帯機器向け製品でもCUDAによる汎用アプリケーションがGPUコア上で走るように持って行く。そして、アプリケーション性能が、CPUではなくGPUで決まるようになれば、GPUがコンピューティングの主役として躍り出るというシナリオだ。
パっと考えただけでも、非常に多難な道だが、NVIDIAはその方向へ進むしかない。でなければ、メインストリーム&バリューという広大なGPU&グラフィックス統合チップセット市場を失い、GPUはニッチのゲーマー向けだけの製品に縮小してしまうだろう。NVIDIAにとって、これはのるかそるかの大きな賭けだ。
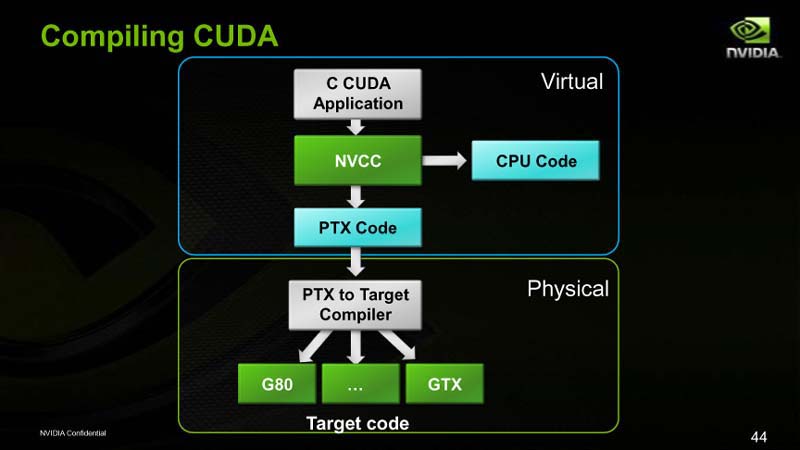 |
| CUDAのコンパイル |
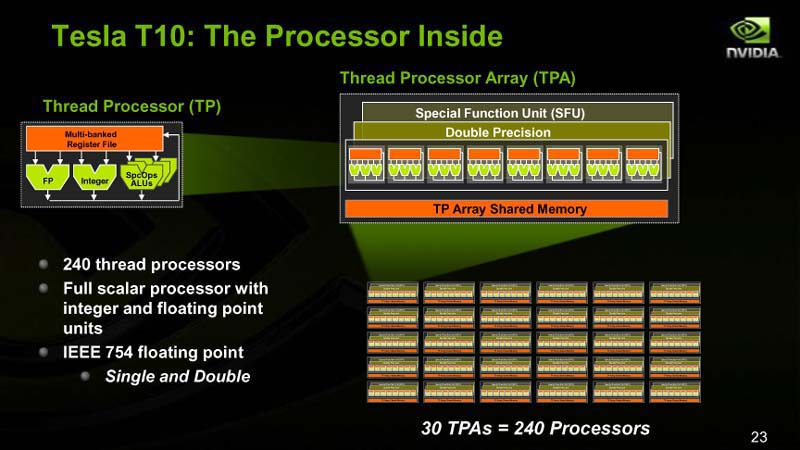 |
| Tesla T10の構造 |
 |
| CUDAの環境 |
●意外な領域で伸び始めたCUDA利用
NVIDIAがG80とCUDAをリリースして以降、同社のGPUコンピューティング戦略は、一般ユーザーからは見えにくい分野で成功を収めつつある。それは、科学技術演算系のハイパフォーマンスコンピューティング(HPC)やエンジニアリング、財務などの分野で、その反響はNVIDIA自身の予想すら上回っているという。「昨年、我々は(CUDAで登場する)アプリケーションの数を、本当に低く見積もっていた」とNVIDIAは説明する。NVIDIA側もこの市場にアプローチしているが、それ以上に、デベロッパがCUDAに自主的にトライし、成果を出しつつある状況となっている。
これらの市場では、大規模なサーバークラスタを使っても、何時間あるいは何日もかかる処理を抱えているデベロッパが多い。彼らは、処理時間をある程度短縮してくれる方法があるなら、新しいプログラミングモデルへの挑戦は厭わない。CUDAを試そうとする好奇心旺盛なデベロッパも少なくない。NVIDIAのSumit Gupta氏(Sr. Product Manager, Tesla GPU Computing, NVIDIA)は次のような例を挙げる。
「SPICEシミュレータをCUDAに移植したエンジニアに、どうしてCUDAに行き着いたのか聞いた。彼は『顧客がシミュレーション時間の短縮を求めているため、常にSPICEを高速化できる方法を探している。そうしたところ、自宅に、ローエンドのNVIDIAのGPUカードがあったので試すことにした。CUDAのサンプルコードの中に、SPICEアルゴリズムのカーネルに似ているものを見つけたので、移植できるか家でやり始めたら、うまく行った』と言っていた」
チップベンダであるNVIDIAにとっても、シミュレーション時間は常に問題だという。例えば、新しいTeslaの4GBメモリ搭載カードのSPICEシミュレーションには3日間かかったという。こうした分野のソフトウェア開発者は、CUDAに可能性を見いだしつつある。
 |
| 250以上のカスタマー |
 |
| ライフサイエンスでの採用事例 |
 |
| 大気科学での採用事例 |
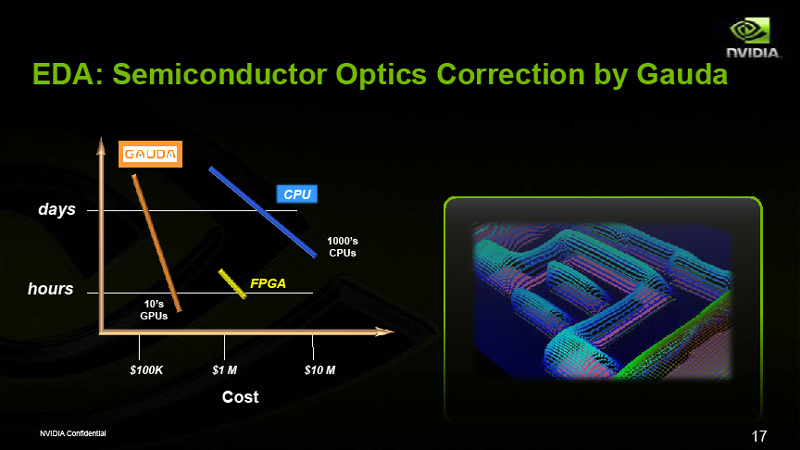 |
| GaudaのEDAにおける採用事例 |
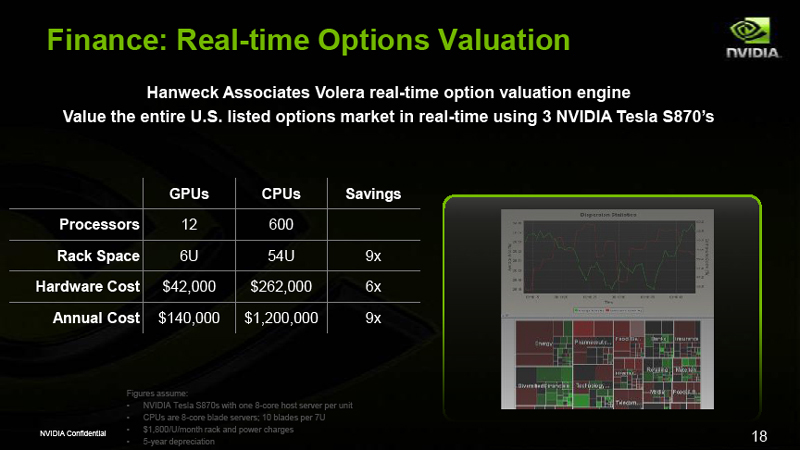 |
| 金融での採用事例 |
 |
| 物理挙動に基づいた服飾のCADデザイン |
 |
| 幅広いディベロッパに採用されている |
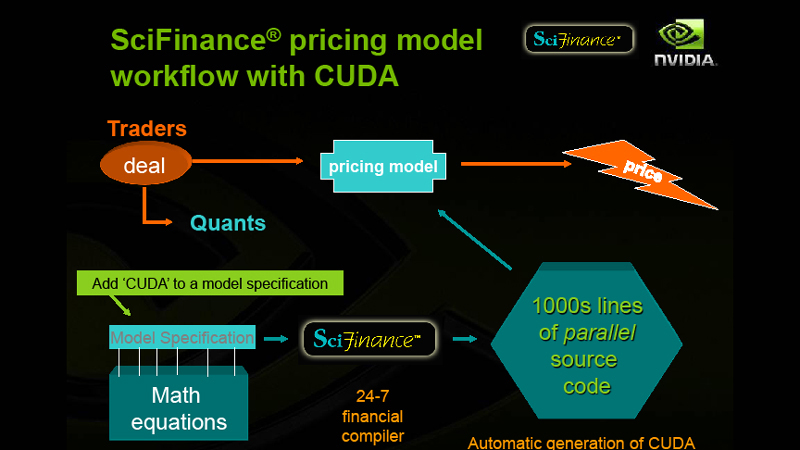 |
| SciFinance分野のプライシングモデルのワークフロー |
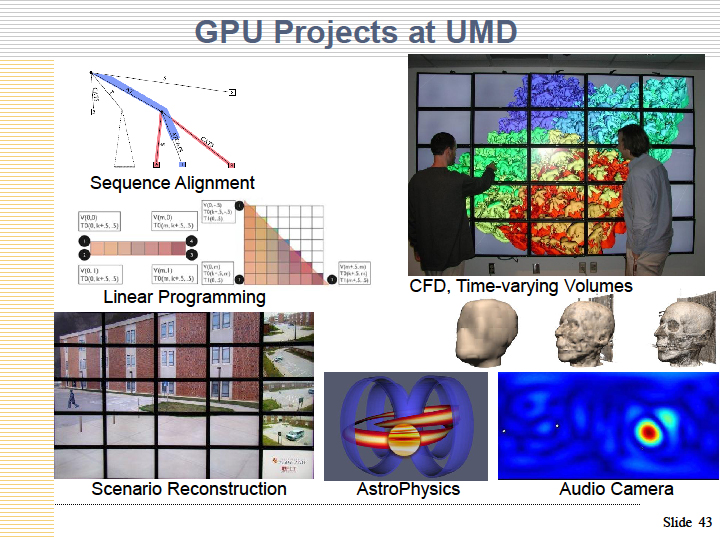 |
| UMDでのGPUプロジェクト |
●未来のGPUにとってのキラーアプリケーション
NVIDIAとしては、恐る恐る始めたCUDAが、期待以上のレスポンスを得て、自信をつけつつあるようだ。
もちろん、規模的には、まだCUDAとGPUコンピューティング戦略が本当に成功したと言えるレベルには達していない。しかし、この勢いを持続できれば、プログラミングコミュニティが育ち、ポジティブスパイラルが回り始める可能性もある。ただし、HPC以外の広汎なプログラミングコミュニティに浸透させるには、CUDAとCUDAを巡る環境をもっと進化させる必要があり、壁は厚い。
NVIDIAは、CUDAをリリースした当初は、HPCなどの市場は小さいと見ていた。本命は一般向けのメディアアプリケーションで、そちらを強調していた。しかし、昨年Teslaをリリースして以降はHPC分野も、NVIDIAがフォーカスすべき重要目標の1つと定めているように見える。その市場では、GPUの浮動小数点演算パフォーマンスが大きな威力を発揮し、進んでプログラミングしてくれるプログラマが揃っているからだ。
進展も速い。一般エンドユーザー向けのアプリケーションは、未だにビデオエンコーディングや画像処理のアクセラレーションといったものがメインだ。こうしたアプリケーションは、PCユーザーの目先の利用モデルとしては確かに魅力だ。しかし、この手のアプリは、実際にはDirectX 9のリリース頃から予想されていたものあり、むしろ実現までにずいぶんと時間がかかったことの方が目立つ。
ところが、HPC分野では、NVIDIA自身が予想もしていなかったようなアプリケーションが次々に出つつあるという。それも、急な展開でだ。プログラミングコミュニティ側の勢いが、一般エンドユーザーアプリケーションとは違う。この分野では、ハードウェアのインストールドベースやプログラミングの難度などがそれほど問題とされないからだ。
一般エンドユーザーにとって、GPUなどデータ並列性の高いコンピューティングモデルの最終的なキラーアプリケーションは、いわゆる「RMS」と総称される「Recognition(認識)」「Mining(分析&抽出)」「Synthesis(合成)」と、その結果実現されるマンマシンインターフェイスにあるだろうと言われている。SF的な自然対話型インターフェイスの世界だ。キーボードとマウスをなくし、人間からの自然な入力を認識し、意味を分析、自然な応答と合成する。
従来の汎用CPUより1桁大きなGPUの演算パフォーマンスは、計算上は6~10年先の汎用CPUのコンピューティングを実現できる。数値だけで言えば、未来を先取りできることになる。そして、未来のソフトウェアが、現在はラボの中でリサーチ段階にあるのなら、HPCの世界を狙うというNVIDIAの現在の戦略は、あながち回り道ではないかもしれない。
分散コンピューティングのFolding@homeもNVIDIAアーキテクチャで加速される。CUDAが走るNVIDIA GPUは、すでに70M(7,000万)ユニットが出荷され、累計のコンピューティングパフォーマンスは7 Exa(エクサ)FLOPSに登っているという。Peta(ペタ)FLOPSスパコン7,000台分のプロセッシング能力が、すでに存在する。分散コンピューティングなら、これを利用しない手はないというわけだ。ゲノム解析が進むにつれて、Folding@homeが解析しなければならないタンパク質の数もどんどん増えているはずで、演算パフォーマンスはいくらあっても充分ではないはずだ。
 |
| GPUでの動画エンコーディング |
 |
| Folding@homeとNVIDIA |
●NVIDIA Teslaも第2世代へと移行
GeForce GTX 280(GT200)のリリースに合わせて、NVIDIAはGPUコンピューティング向け製品Teslaラインナップもアップデイトした。今回投入するのは、4wayの1Uラックマウントサーバー「Tesla S1070 1U System」と、1wayのPCI Express Gen2カード「Tesla C1060 Computing Processor」。どちらもグラフィックス出力を持たない、GPUコンピューティングに特化した製品だ。
NVIDIAは、GeForce製品は933GFLOPSに設定したのに対して、1UのTesla S1070は1GPU当たり1.08TFLOPSに設定。1TFLOPSの栄冠はグラフィックス製品ではなく、GPUコンピューティング製品にゆずった。このあたりからも、NVIDIAのGPUコンピューティングに対する注力振りがわかる。
Teslaの基本的な特徴は、以前のシリーズから変わっていない。タスクの中の並列化できないシリアル成分が並列化のパフォーマンスを制約するアムダールの法則が活きているため、Teslaは必ず汎用CPUとセットになる。1UのTesla S1070では、CPU 1UサーバーとPCI Expressケーブルで接続する。
 |
| Teslaの1UシステムS1070 |
 |
| カードタイプのTesla C1060 |
 |
| Teslaの1UタイプはPCI Express Gen2ケーブルで接続 |
●NVIDIAのCUDA戦略のこれから
NVIDIAの次のフェイズは、CUDAとGPUコンピューティングをどうやって、より広いプログラミングコミュニティに広めるかという点にある。現状のCUDAのプログラミングモデルはかなりプリミティブで、最適化にはハードウェアに対する知識もかなり必要となる。そのため、広汎なソフトウェア開発者に受け容れられるレベルには至っていないという意見もある。
しかし、そもそもの問題として、現状ではCUDAだけでなく、さまざまなC言語の並列コンピューティング拡張や新言語が乱立し、それぞれコンパイルできるターゲットが制約されているという混乱状況にある。CUDAが本命と見極められないと、動けないのが現状だ。
しかも、混乱は増しつつある。例えば、MicrosoftのDirectX 11では、GPGPUステージが設けられ、汎用コンピューティングがプログラムしやすくなる。OpenGLを策定するKhronos Groupも、C言語の並列コンピューティング拡張に名乗りを上げた。Intelも自社のデータ並列&タスク並列プロセッサ「Larrabee(ララビー)」にCt言語を組み合わせる。並列コンピューティングのプログラミング環境は、加速度的に選択肢が増えて複雑になりつつある。
CUDA 2.0ではマルチコアCPU向けにコンパイルできるようにしてターゲットを増やすが、本当の理想環境にはまだ遠い。あるGPU関係の開発者は「現在は、CUDA、Ct(Intel)、Brook(Stanford)とさまざまな言語がばらばらに存在している。しかし、健全なのは、1つの言語に集約されること。そこからコンパイルすればどのハードウェアにも対応できるようにならなければ、真の並列コンピューティングの発展はないだろう」と語る。
もちろん、NVIDIAのCUDA開発陣もそれはわかっている。わかっているからこそ、先に走って、実績を積み上げようとしている。最悪、CUDAのC言語拡張が、最終的に生き残らなくても、スタンダードとなった言語が、CUDAランタイムのコンパイラインターフェイスである中間言語「PTX」にコンパイルしてくれれば、NVIDIAとしては戦い続けることができる。
□関連記事
【6月17日】【海外】NVIDIAの1TFLOPS GPU「GeForce GTX 280」がついに登場
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai446.htm
【6月17日】AMD、200ドルで1TFLOPS越を実現するRadeon HD 4850を6月25日出荷
http://pc.watch.impress.co.jp/docs/2008/0617/amd.htm
(2008年6月19日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.