 |


■後藤弘茂のWeekly海外ニュース■Radeon HD 4800の高パフォーマンスの秘密 |
●DirectX10世代で初のメジャーアップデートアーキテクチャ
DirectX10世代GPU戦争の第2フェイズが幕を開けた。AMDの旧ATI Technologies部門であるGraphics Products Groupは、ハイエンドクラスのプロセッサパフォーマンスを、ミッドレンジGPUクラスの価格で提供する「ATI Radeon HD 4800(RV770)」ファミリをリリース。また、RV770コアを2個使ったハイエンドGPU「R700」の発売も予告した。AMDは、GPGPU(GPUの汎用コンピューティング利用)向けの製品ブランド「FireStream」にもRV770コアを投入する見込みで、NVIDIAのGeForce GTX 200(GT200)系列と真っ向からぶつかり合う。
AMDとNVIDIAの両社とも昨年(2007年)の年末商戦向けGPUラインナップは、従来アーキテクチャの微細化版であり、性能と機能の両面で飛躍は小さかった。また、昨年末は、最高性能かつ最高メモリ帯域の、単体GPU製品はリリースされなかった。両社とも、前回の製品はマイナーチェンジで、今回の製品がメジャーチェンジとなる。
足並みを合わせるかのような両社は、製品メッセージの面でも共通点が多い。両社とも、「1TFLOPS(テラフロップス)」前後の演算パフォーマンスを前面に押し出した。そして、クアッドコアCPUの10倍のピーク浮動小数点演算性能を活かした、汎用アプリケーションへの展開を強く謳った。ビデオエンコーディングや画像フィルタリングといった、一般アプリケーションへの展開を示すことで、「GPUの非グラフィックスへの利用」を強く打ち出したのが今世代の2社のGPUだ。
CPUメーカーでもあるAMDには、GPU専業メーカーであるNVIDIAのように、GPUを汎用コンピューティングで成り立たせなければならないという、焦りはない。しかし、CPU製品では、このところ製品の遅延などのために不振が続いており、ロードマップ上でもIntelをひっくり返すだけの勢いはない。
そのため、AMDは短期的には、GPU製品に頼る比重を高くすると見られる。そのために、GPUをグラフィックス用途だけでなく、より高付加価値の汎用コンピューティング用途でも盛り上げたいというのが、AMDの思惑だろう。おそらく、RV770コアのFireStreamは、これまでより強く押し出すものと推測される。
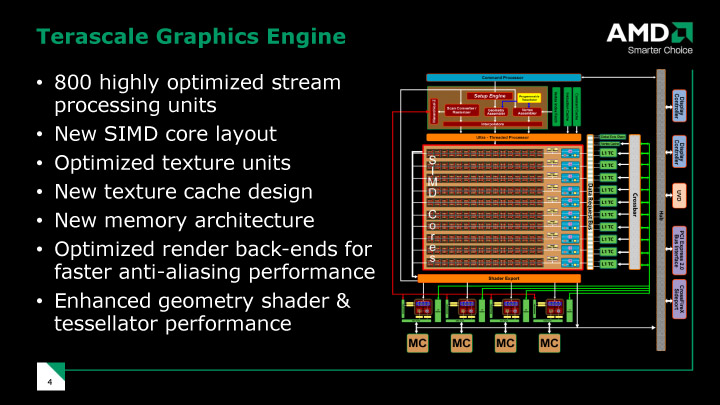 |
| RV770の演算アーキテクチャ |
●R600をベースに拡張したRV770のマイクロアーキテクチャ
RV770は、ATI Radeon HD 2900(R600)アーキテクチャをベースにしている。下のチャートは、AMDが公開したRV770のダイアグラムに、アーキテクト達からの情報を加えて作成したブロック図だ。その隣は、R600のダイアグラムをRV770のフォーマットに合わせて描き直したブロック図だ。どちらも、一部に推定が入っている。
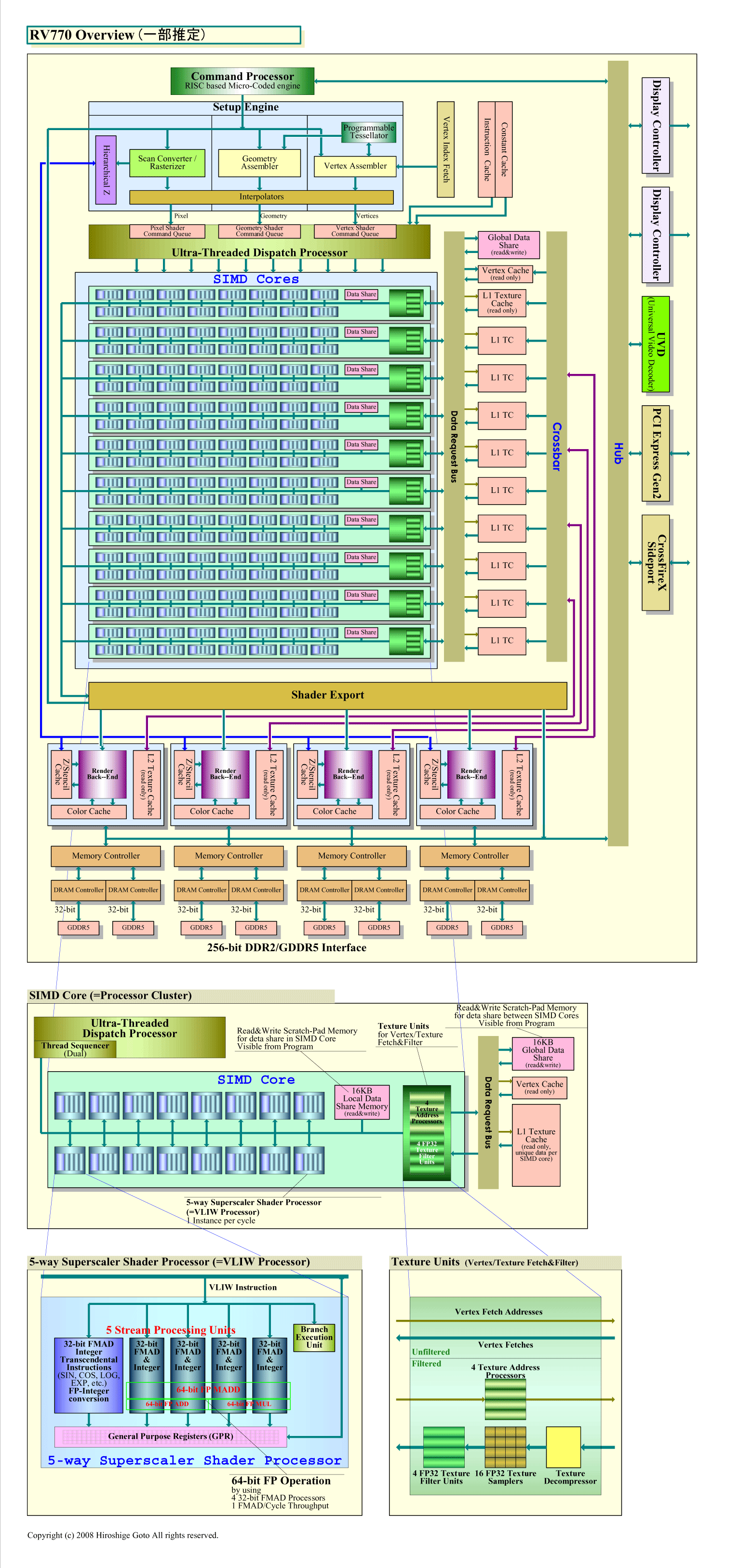 |
| RV770のオーバービュー (PDF版はこちら) |
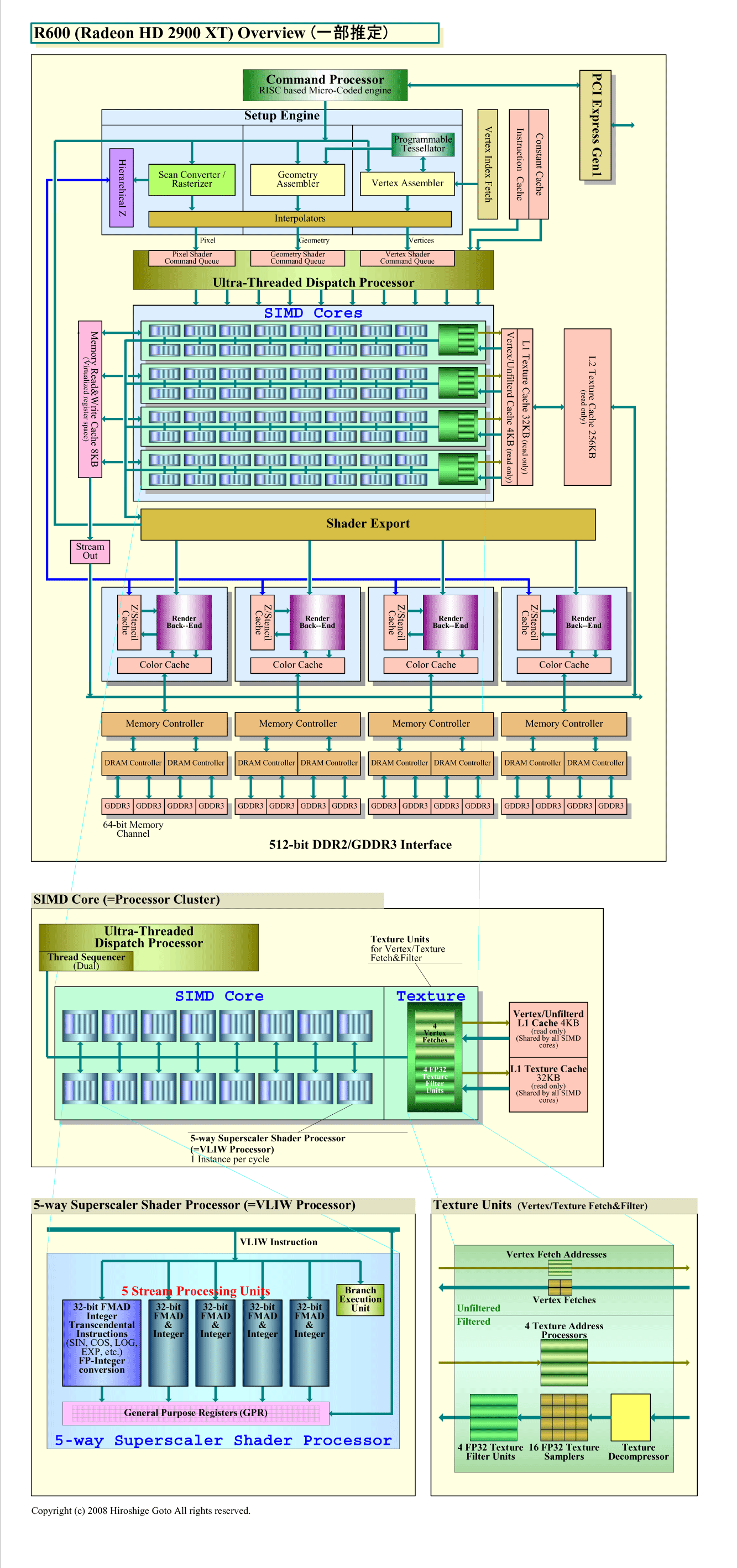 |
| R600のオーバービュー (PDF版はこちら) |
R600とRV770の関係は、NVIDIAのGeForce GTX 200とGeForce 8800の関係とよく似ている。R600のベースアーキテクチャを改良し、グラフィックス性能を倍増させ、さらに、汎用アプリケーション向けの機能拡張を追加したのがRV770だ。そのため、RV770とR600では、プロセッサ自体の基本構造は驚くほどよく似ている。しかし、R600とRV770には、大きな飛躍もある。グラフィックスに特化した機能拡張以外の、プロセッサとしてのRV770の飛躍ポイントを挙げると次のようになる。
- SIMD実行によるパフォーマンス効率の追求
- 汎用コンピューティング向けの機能の拡充
- GPU内部バス構造の一新によるデータフローの改善
- GDDR5採用とメモリ回りの一新によるデータ帯域拡大
AMDの期待を担うRV770で、今回強調されたのは、極めて高い性能効率だった。RV770は、160個のVLIWプロセッサを搭載、合計で800個の単精度積和算(FMAD)ユニットを搭載する。Radeon HD 3800(RV670)までは320個だったので2倍以上に増えたことになる。NVIDIA同様に、ピークパフォーマンスは、「ATI Radeon HD 4870」で1.2TFLOPSをマークする。
それに対して、同時期のNVIDIAのGT200系は240個のプロセッサを搭載し、240個の単精度FMADユニットと60個のスーパーファンクションユニット(乗算FMULを4並列実行可能)を搭載する。物理的な演算ユニット数ではAMDが大きく上回る。ただし、ピーク性能は、グラフィックス向け製品GeForce GTX 280で933GFLOPS、GPUコンピューティング向けの「Tesla(テスラ) T10P」で1.08TFLOPSと、RV770と大きくは差がつかない。
RV770は多くのプロセッサを低速(750MHz)で走らせ、NVIDIAはより少ないプロセッサを高速(1.3~1.5GHz)に走らせる。そのため、ピーク演算パフォーマンスではそれほど差がないが、GPUのダイサイズ(半導体本体の面積)とトランジスタ数は大きく異なる。GT200が1.4B(14億)トランジスタで570平方mmの巨大ダイであるのに対して、RV770は956M(9億5,600万)トランジスタで260平方mm。ダイサイズでは、ほぼ半分となる。
GT200がTSMC 65nmプロセスであるのに対して、RV770はTSMC 55nmプロセスという差はあるが、65nm相当で計算してもRV770のダイは約350平方mm程度にしかならない。そのため、RV770はGT200に対して、ダイ面積と消費電力当たりのピークパフォーマンスが極端に高い。つまり、AMDは、NVIDIAよりずっと効率のいいGPUを作り上げたことになる。
ちなみに、RV770のダイサイズは、AMDのBarcelona(バルセロナ)やIntelのNehalem(ネハーレン)など、クアッドコアCPUとほぼ同レベルだ。つまり、AMDは、CPUと同じダイサイズで10倍の浮動小数点演算パフォーマンスのプロセッサを作り上げたことになる。
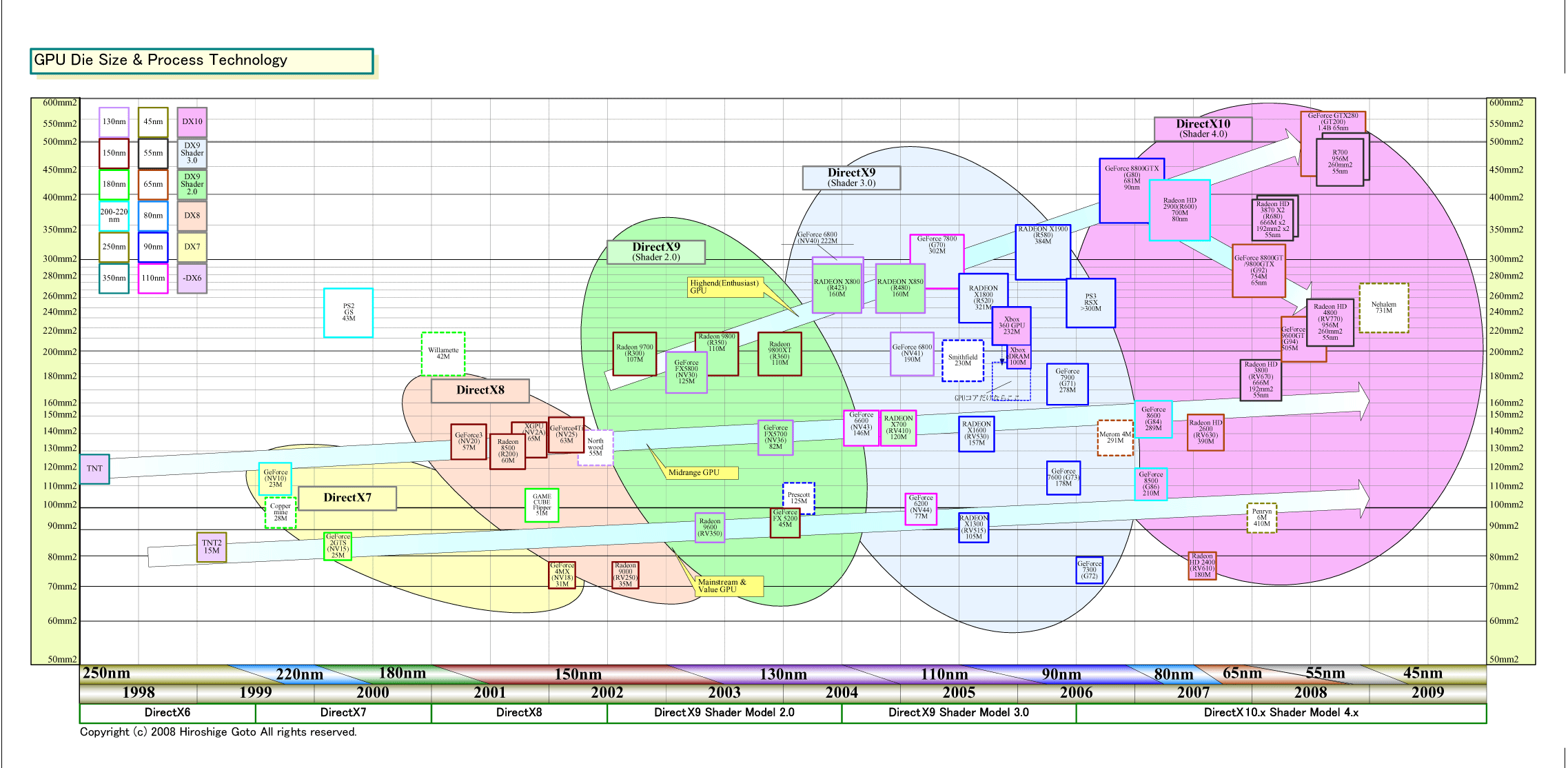 |
| GPUのダイサイズ推移 (PDF版はこちら) |
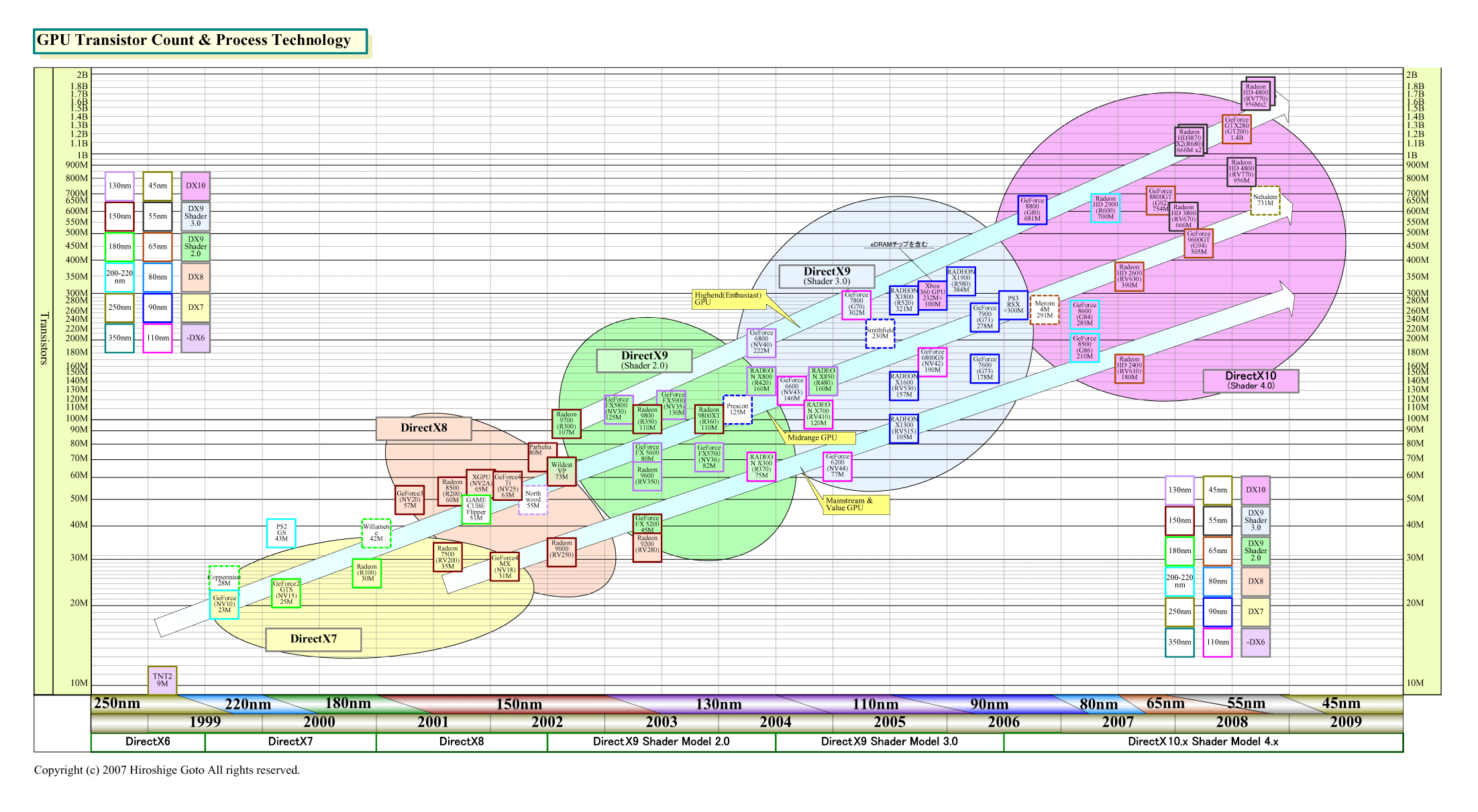 |
| GPUのトランジスタ数推移 (PDF版はこちら) |
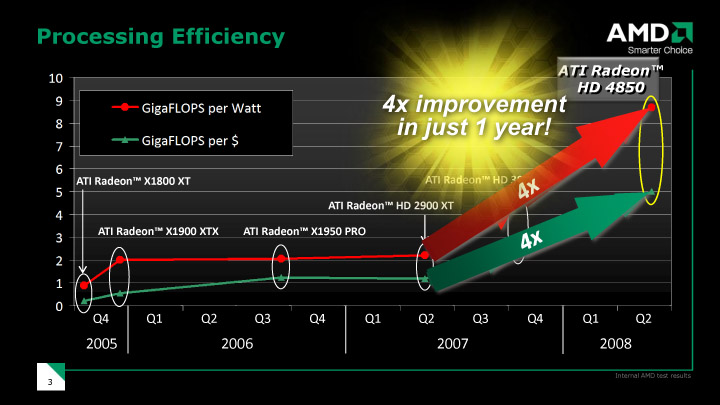 |
| 消費電力あたりの性能、価格あたりの性能比推移 |
●トランジスタ効率のいいRV770アーキテクチャ
演算ユニット数が多いRV770の方が、GT200よりダイもトランジスタ数も小さいのは不思議に見える。もちろん、プロセッサの世界にマジックはない。これには明快な理由がある。一言で言えば、RV770はデータ並列プロセッサとしての効率を追求している。つまり、多くの演算ユニットを、SIMD(Single Instruction, Multiple Data)型の命令実行で並列に動作させ、高効率を得ている。RV770のダイの大半はプロセッサアレイで占められ、余計な制御系ユニットの比率は極端に少ない。そのため、ダイ面積当たりのピーク演算パフォーマンスは極めて高い。
 |
| RV770は演算系に多くトランジスタを割いている |
プロセッサ設計では、フレキシビリティとパフォーマンス効率はトレードオフの関係にある。その2つの間で、効率性にぐっと振ったのがATIアーキテクチャだ。この点は、汎用コンピューティング向けGPUとしてのフレキシビリティにもある程度振っているNVIDIAとの大きな違いとなっている。ただし、AMDはRV770において、汎用コンピューティング向けの拡張もいくつか行なった。プログラムが明示的にアクセス可能なスクラッチパッド型共有メモリの搭載だ。GPGPU向けの最適化は、RV770の大きな特徴となっている。
簡単に言えば、NVIDIAはGPUコンピューティング向けのアーキテクチャを取ったことで、効率性はある程度犠牲にした。それに対して、AMDはデータ並列プロセッサとしての高効率を追求したその結果の高パフォーマンスを武器に、汎用コンピューティングへの浸透を狙う。どちらのアプローチが成功するかは、まだわからない。ただし、プログラミングフレームワークの整備では、今のところNVIDIAが先行している。
汎用コンピューティング向けの機能を取り入れたRV770。だが、RV770で最も大きく手を入れられたのは、じつは演算コアではなく、内部バスとメモリコントローラ回りだ。R600世代では、この部分の効率の悪さが、性能のボトルネックとなり、チップの大型化や電力消費の増大を招いていたという。そこで、RV770ではR600世代のリングバスからクロスバスイッチへと変更した。それに合わせて、キャッシュ階層を大きく変更した。この変更の結果、巨大なプロセッサアレイに、充分データを供給できる内部バスができあがった。
また、サポートメモリをJEDEC(米国の電子工業会EIAの下部組織で、半導体の標準化団体)で標準化した次世代グラフィックスメモリGDDR5にした。その結果、RV770では3.6Gt/secと極めて高い転送レートで、115.2GB/secのメモリ帯域を実現する。AMDは、高パフォーマンスプロセッサの最大の課題である、データ帯域の問題を解決することで、コンパクトながら1 TFLOPSのGPUを実現した。
●VLIWアーキテクチャを取るRV770のプロセッサ
RV770のプロセッサの構造は、R600世代をほぼ踏襲している。演算ユニットは、VLIW(Very Long Instruction Word)型のプロセッサにまとめられている。R600世代では、このプロセッサは「5-way Superscaler Shader Processor」と呼ばれていた。内部には、5個の単精度浮動小数点FMADユニット「Stream Processing Unit」が搭載されている。
ちなみに、AMDは、5個の浮動小数点演算ユニットそれぞれを、スカラプロセッサと呼ぶことも多い。これは、NVIDIAアーキテクチャでは、個々の演算ユニットが独立したスカラプロセッサになっているため、対抗上名称を合わせたものだ。つまり、NVIDIAとプロセッサ数を比較される場合に、5-wayプロセッサではなく、各演算ユニット単位で比較されたいというマーケティング上の狙いがある。しかし、実態は、5個の演算ユニットで、1データエレメント(ピクセル/頂点など)に対する処理を行なう、5-wayのプロセッサだ。
4ユニットは同じ構成で、32-bit単精度浮動小数点の積和算(FMAD)と整数演算用のシンプルな演算ユニット。1サイクルスループットで、毎サイクル毎に命令を実行できる。それに対して、5番目のユニットは、浮動小数点FMADと整数演算の他に、複雑なオペレーション(sin/cos/log/expなど)や浮動小数点と整数のデータ変換なども実行する。GPU用語では、5番目のユニットは一般的に「Super Function Unit」と呼ばれる。5ユニットともFMADなどの演算は1サイクルスループットで実行できる。
5-wayプロセッサに対する命令語は6つの命令スロットを備えたVLIW(Very Long Instruction Word)命令となっている。VLIWでは、長い命令語の中に複数の命令を格納することができる。命令をコンパイルする際に、並列に実行できる複数の命令を抽出して、1個のVLIW語の中に納める。プロセッサ側では、VLIW命令の中から個々の命令を取りだして、複数の演算ユニットで並列に実行する。コンパイル時に命令スケジューリングを行なうため、プロセッサをシンプルに保つことができる。AMDがVLIWを採用したのは、GPUが実行するプログラムが、SIMD(Single Instruction, Multiple Data)型からスカラ型へと比重が移り始めたからだ。NVIDIAも同じ理由から、スカラプロセッサのアレイアーキテクチャを採用した。
 |
| RV770のVLIW命令 (PDF版はこちら) |
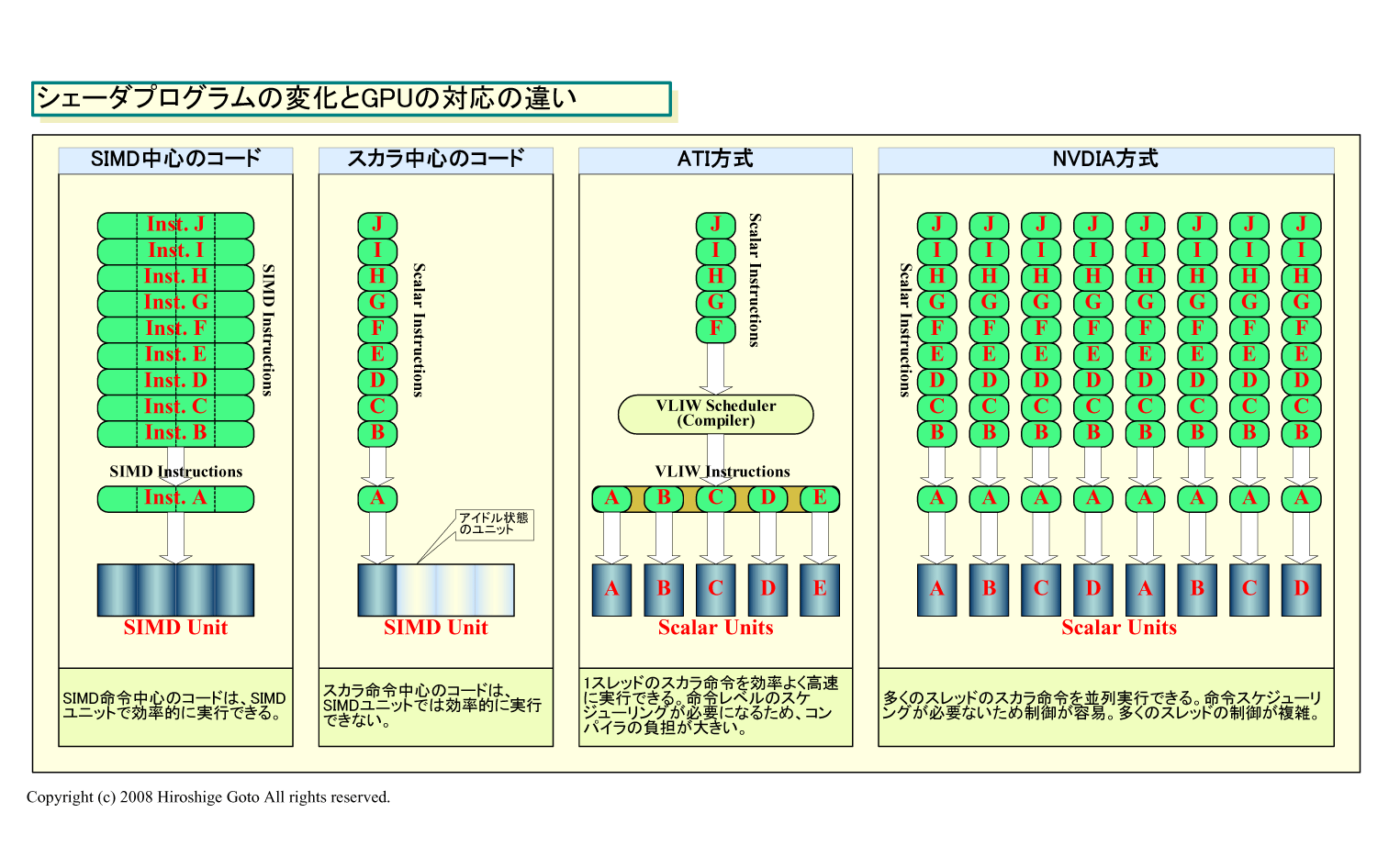 |
| シェーダプログラムの変化とGPUの対応の違い (PDF版はこちら) |
●トレードオフがあるスカラ構成とVLIW構成
NVIDIAは、GPUの演算プロセッサをフルにスカラプロセッサとして構成し、命令レベルの並列性はほとんど考慮していない。それに対して、旧ATI系のアーキテクチャはVLIWによる命令レベルの並列性を追求する。そのため、RV770では、NVIDIAより1個のプロセッサに多くの演算ユニットを搭載している。
5個の演算ユニットによる並列実行は、依然としてSIMD型の並列演算が多く含まれるグラフィックス処理では、性能を上げやすい。一方、スカラ演算が中心で、かつ命令同士に依存性が存在するケースが多いと並列実行ができず、無駄が生じる可能性がある。また、ドライバでのリアルタイムコンパイルにより時間がかかるため、処理の単位が大きくないとオーバーヘッドが生じる。ただし、グラフィックスでは単位が非常に大きいため、この問題は目立たない。こうした基本アーキテクチャは、NVIDIAよりグラフィックス寄りだ。
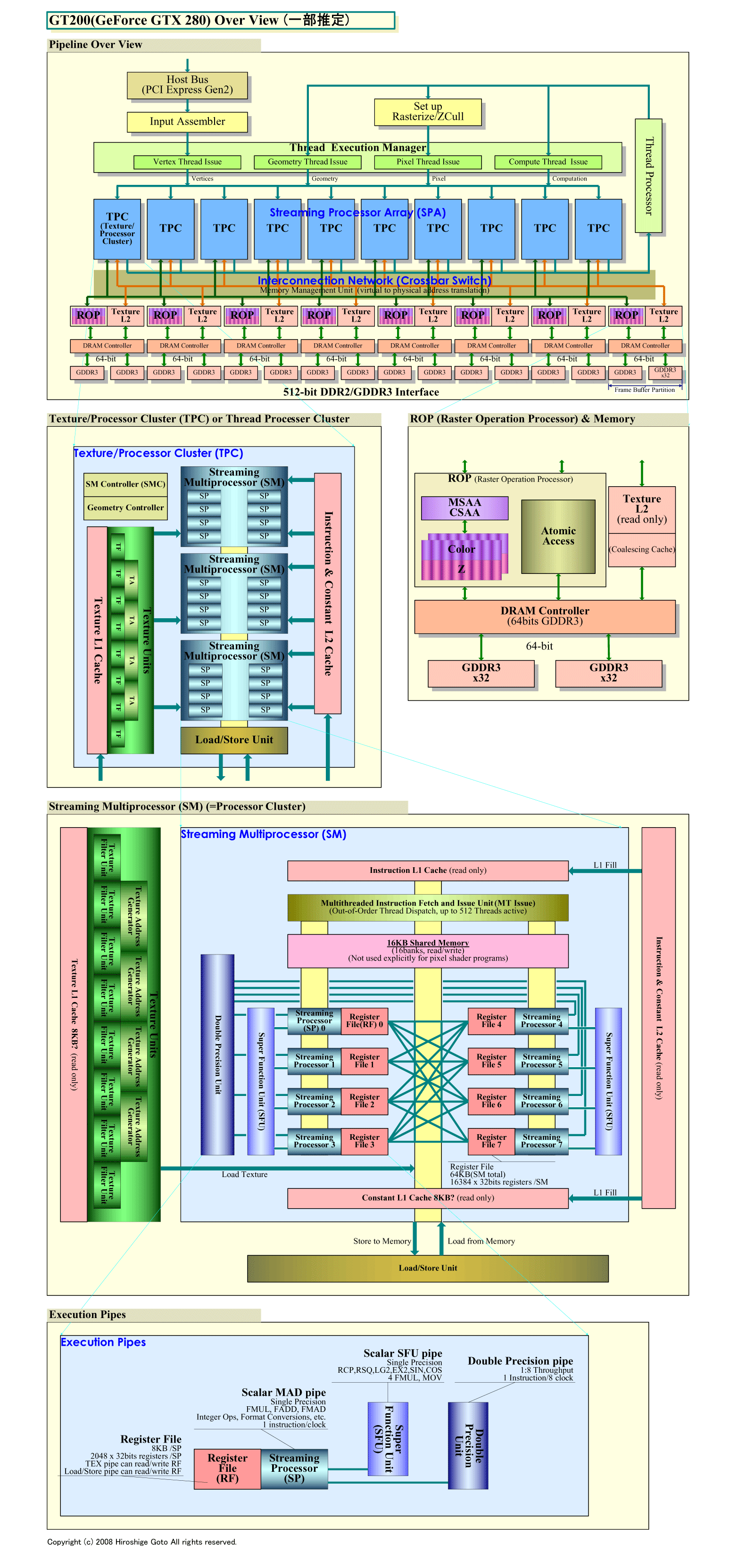 |
| GT200のオーバービュー (PDF版はこちら) |
NVIDIAはGT200で倍精度(64bits)浮動小数点演算をサポートしたが、AMDも前世代RV670コアから倍精度演算をサポートしている。しかし、実装方式はNVIDIAとは大きく異なる。GT200では、倍精度専用ユニットをクラスタに加えているが、AMDは、既存の単精度ユニットを使って倍精度演算を実現する方法を選んだ。
5-wayプロセッサの中のスーパーファンクションユニット以外の4個の単精度FMADユニットを使って、1個の倍精度FMAD演算を1サイクルスループットで実行する。2個の単精度FMADユニットが1個の倍精度の乗算(FMUL)を、別な2個のFMADユニットが1個の倍精度の加算(FADD)を実行し、コンバインして倍精度FMADを実現する。
AMDの方式では、倍精度演算は単精度演算の1/5のパフォーマンスとなる。1.2TFLOPSのRV770で240GFLOPSで、Teslaの90GFLOPSの2倍以上だ。しかし、GT200アーキテクチャと異なり、単精度演算と倍精度演算を並列に行なうことはできない。実装の違いが、トレードオフを産んでいる。
AMDはグラフィックス製品では倍精度は有効にせず、GPGPU向けの「FireStream」系列でのみ倍精度をサポートする見込みだ。これは、グラフィックス製品で倍精度をサポートするNVIDIAとの大きな戦略の違いだ。
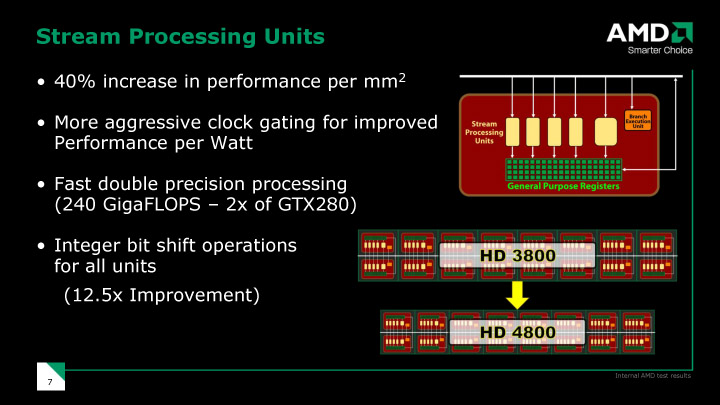 |
| RV770のプロセッシングユニット |
●プロセッサクラスタの構成や分岐粒度はR600と同じ
RV770では、16個の5-wayプロセッサを1個のクラスタ「SIMD Core」として制御している。つまり、1個の命令ユニットが16個のプロセッサの80の演算ユニットを制御する。11個の演算ユニットを1個の命令ユニットが制御するGT200と較べると、格段に粒度が大きい。1個の命令ユニットで制御する演算ユニットの数がNVIDIAより多いため、制御ユニットの比率を減らして、より多くのプロセッサを搭載することが容易となっている。
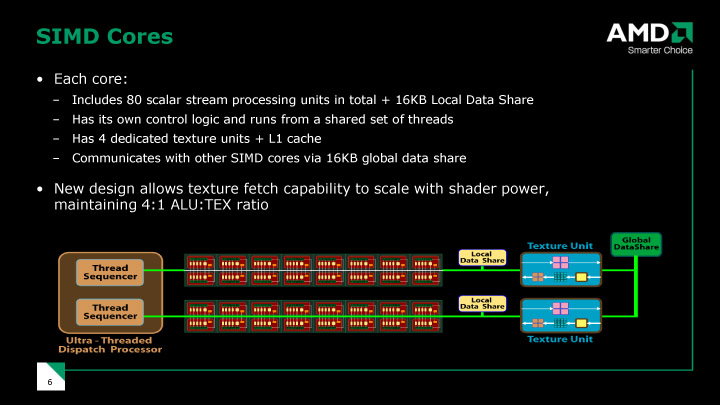 |
| RV770のSIMDコア |
RV770では、R600世代のGPUと同様、各プロセッサが4サイクル同じ命令を実行する。そのため、64インスタンス(NVIDIA用語ではスレッド)が分岐粒度(Branch Granularity)となる。分岐粒度が小さいほど、分岐命令の多いプログラムを効率的に走らせることができる。G80/GT200系は分岐粒度が32インスタンスで、RV770より小さい。AMDによると、グラフィックスでは64インスタンスの粒度が最適だと判断したという。NVIDIAは粒度を小さくしたことで、制御機構が複雑化している。これはトレードオフだ。
AMDは、RV770では明瞭にGPGPUに力を入れ始めた。NVIDIA GPUは、各プロセッサクラスタの中に16KBの共有メモリを搭載。汎用アプリが、インスタンス間のデータ交換などに使えるようにしている。RV770も、これと同じ機能を持つ16KBの共有メモリ「Local Data Share Memory」を搭載した。GPUの一般的なキャッシュは、プロセッサコアからの書き込みができないリードオンリーのバッファだ。それに対して、この共有メモリは、プロセッサコアからのリード&ライトが可能となっている。アドレス空間が割り当てられ、明示的にアクセスが可能となっている。これも、NVIDIAの共有メモリと同じだ。
R600アーキテクチャでは、SIMD Core間で共有する8KBのライタブルなキャッシュメモリ「Memory Read&Write Cache」が搭載されていた。それに対してRV770ではSIMD Core間で共有する16KBの「Global Data Share」を搭載する。これは、SIMD内のLocal Data Share Memoryと同様にアドレッシング可能なスクラッチパッドメモリとなっている。
●内部バスアーキテクチャを完全に一新
NVIDIAは、GT200でプロセッサクラスタの中を大きく変更した。それに対して、AMDは、プロセッサクラスタの構成や構造は、ほとんど変更しなかった。目立つのは共有メモリの搭載や倍精度サポートで、構成自体には大きな変更はない。しかし、GPUの中でのクラスタの数は大きく増やされた。
R600ではSIMD Coreを4個搭載していた。RV770では、SIMD Coreの数は10個に増やされた。それぞれのSIMD Coreが16個の5-wayプロセッサを搭載しているため、合計で160個の5-wayプロセッサ、800個の浮動小数点演算ユニットとなる。つまり、クラスタであるSIMD Core自体は大きく構成を変えず、SIMD Coreを増やすことでGPUの規模を大きくしている。
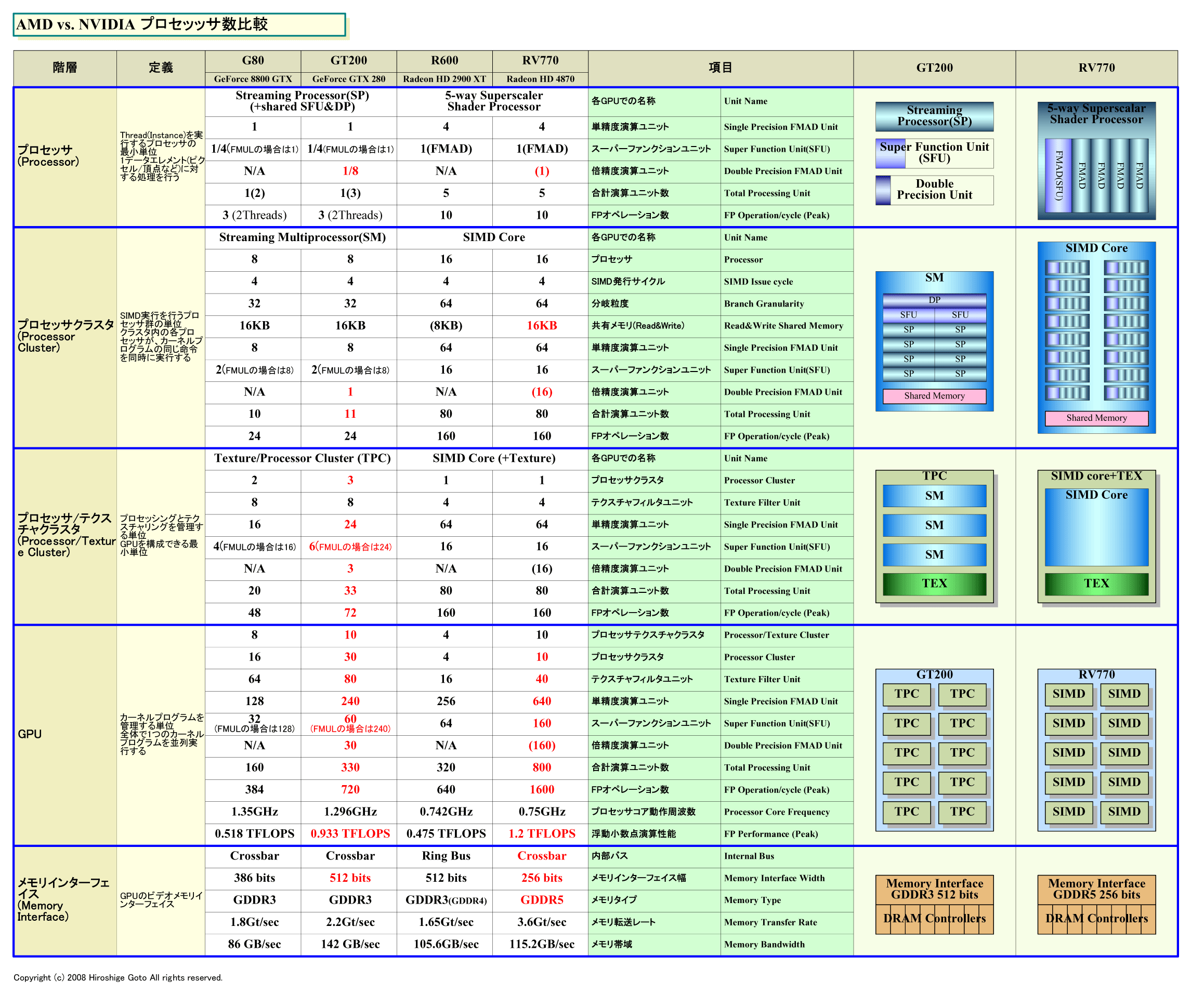 |
| GT200とRV770のプロセッサ数比較 (PDF版はこちら) |
RV770で最も大きく変更されたのは、チップの内部バスアーキテクチャだ。AMDはR600系では、チップ内部での各ユニットの接続にリングバスを使っていた。しかし、RV770ファミリでは、GPUで一般的なクロスバスイッチへと戻した。これは、電力消費などを考慮した上での設計変更で、メモリコントローラを分散化することで、クロスバ設計を容易にしたという。
また、テクスチャキャッシュを変更。従来は、SIMD Core間で共有する単一のL1テクスチャキャッシュ(32KB)と単一のL2テクスチャキャッシュ(256KB)の2階層だった。下の白いスライドがR600のテクスチャキャッシュとテクスチャユニットの解説だ。
RV770では、これを、各SIMD Coreに専属のL1テクスチャキャッシュ群(10個)と、4個のメモリコントローラに直結するL2テクスチャキャッシュ群(4個)へと切り替えた。そして、L1とL2の間を専用のクロスバで結んだ。下の黒いスライドがRV770のテクスチャキャッシュとテクスチャユニットの解説だ。この改良によって、劇的にキャッシュフェッチ効率が上がったという。
 |
| RV770のテクスチャユニット |
 |
| クロスバ型のメモリコントローラ |
 |
| Radeon HD 2900のテクスチャユニット |
実は、このキャッシュアーキテクチャはNVIDIAのG80/GT200と非常によく似ている。皮肉な見方をすれば、ライバルのアーキテクチャをうまく取り入れたと言える。しかし、データの局所性をうまく活かすアーキテクチャを考えると、結局は同じ結論に行き着くのかもしれない。結果として、RV770とGT200のメモリ回りとキャッシュの構造は、非常に似たものになった。
テクスチャキャッシュの再編成の結果、バストラフィックの90%がメインのバスから削減されたため、リングバスは意味を失い、RV770では取り去られた。テクスチャキャッシュの改良とリングバスの廃止は、密接に結びついている。
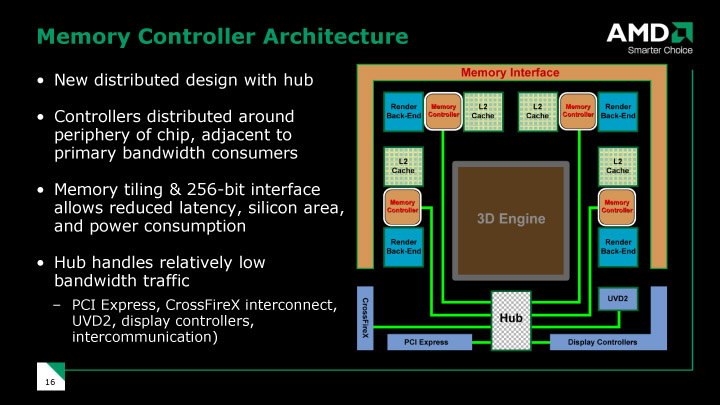 |
| メモリバスはリングバスからクロスバに変更 |
●メモリコントローラ回りを改良してGDDR5をサポート
ダイの小さなRV770では、DRAMインターフェイスのパッド面積が少ないため、メモリインターフェイスの幅が限定される。AMDは256bitsインターフェイスを採用した。これは、従来ならミッドレンジ向けGPUのインターフェイス幅で、充分なメモリ帯域を確保できない。そこで、AMDは、JEDECで規格化が行なわれたGDDR5を採用した。
ATI Radeon HD 4870(RV770)では、転送レート3.6Gtps(メモリクロック0.9GHz)のGDDR5によって115GB/secのメモリ帯域を実現している。ただし、GDDR5ではメモリプリフェッチ幅が広いため、従来のメモリチャネル幅でアクセスすると、メモリのアクセス粒度がGDDR3世代の2倍になってしまう。すると、必要なデータ粒度以上のメモリを一度に読み書きすることになり、メモリ帯域が無駄になってしまう。NVIDIAのGT200がGDDR3までしかサポートしないのはこのためだ。
R600は64bitsメモリチャネルのDRAMコントローラだった。64bits幅の場合は、GDDR4ではメモリのアクセス粒度が大きくなってしまうため、R600ではGDDR3が最適だった。AMDはRV770ではGDDR5でのメモリアクセス粒度を従来と同じに保つために、DRAMコントローラを32bits幅にしているという。
 |
| GDDR5の採用で転送レートが向上 |
RV770アーキテクチャを概観すると見えてくるのは、現在のプロセッサアーキテクチャが直面するトレードオフだ。効率性か柔軟性か。AMDのアプローチは、その中で、効率性に最も振った最左翼のアーキテクチャだ。極めて高いパフォーマンス/消費電力&ダイ面積は、その証明だ。しかし、その一方で、AMDは汎用コンピューティングへの最適化も進めつつある。AMDがプログラミングのフレームワークをきちんと構築できれば、RV770の高効率は、汎用コンピューティングにとっても魅力的なポイントになりうる。
□AMDのホームページ(英文)
http://www.amd.com/
□製品情報(英文)
http://ati.amd.com/products/radeonhd4800/
□関連記事
【6月25日】AMD、1.2TFLOPSの演算能力を持つRadeon HD 4870
http://pc.watch.impress.co.jp/docs/2008/0625/amd.htm
【6月20日】AMD、800SP搭載/1TFLOPSのGPU「ATI Radeon HD 4850」
http://pc.watch.impress.co.jp/docs/2008/0620/amd.htm
【6月17日】【海外】AMD、1TFLOPS GPU「Radeon HD 4800」ファミリをプレビュー
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai447.htm
【6月17日】AMD、200ドルで1TFLOPS越を実現するRadeon HD 4850を6月25日出荷
http://pc.watch.impress.co.jp/docs/2008/0617/amd.htm
(2008年6月26日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.