
|
|


●McKinleyで立ち上がるIA-64
 |
| McKinleyのパッケージ |
Intelの第2世代IA-64プロセッサ「McKinley(マッキンリ)」と、次世代のハイエンドサーバー&ワークステーション向けチップセット「Intel 870」の姿が明らかになり始めた。また、McKinleyの0.13μm版「Madison(マディソン)」の概要や、今後、マルチスレッディング(スレッドレベルで並列処理をする)技術などを採用することも明らかにした。今後、Intelは、2004年まで1年に1世代つづIA-64プロセッサを世代交代させる。そのため、IA-64プロセッサの性能は、一気に駆け上がると見られる。
McKinleyを1センテンスで説明してみよう。最初のIA-64プロセッサ「Itanium(Merced:マーセド)」の2倍の性能でありながら、パッケージはより簡略になり、消費電力も減って扱いやすくなったIA-64 CPUの真打ち...といったところだろうか。つまり、ハードウェアだけを取ってみれば、いいことづくめだ。
 |
 |
 |
| MercedとMcKinleyの比較 | Intel 870チップセットのダイアグラム | |
IA-64は、2002年前半に登場するこのMcKinleyで、ついに本格ラウンチの時を迎える。つまり、Merced=ラウンチさせるための助走、McKinley=商用システムへの本当のスタートとなる。McKinleyが登場したら、Mercedはその役目を終えて消えてゆくだろう。
もっとも、McKinleyの時代もそう長くは続かない。それは、McKinleyを0.13μmにシュリンクした「Madison(マディソン)」と「Deerfield(ディアフィールド)」が2003年に控えているからだ。もっとも、McKinleyからMadisonへの移行はスムーズに行きそうだ。それは、McKinleyとMadisonのシステムバスが共通で、同じチップセット(870など)を使えるからだ。熱設計も含めて、同じフォームファクタを使うことができるようだ。
Madisonは、オンダイのL3キャッシュをMcKinleyの3MBから6MB(!)に増やす。Deerfieldは、おそらくアーキテクチャは共通でキャッシュサイズなどを減らした廉価版となる。
●1年置きに新CPUが登場するIA-64
 |
| IA-64ロードマップ |
左の図がIntelが発表したIA-64プロセッサのロードマップだ。8way以上のバックエンドサーバと2wayハイエンドワークステーションへは、来年にMcKinleyの3MB版、2003年にMadisonの6MBが来る。2~4Wayのミッドタイヤサーバーと2wayパフォーマンスワークステーションの領域へは、来年McKinleyの1.5MB版と3MB、2003年にMadisonの3~6MB版が来る。キャッシュが半分のバージョンは、実際にはキャッシュの半分を使えないようにしただけと見られる。そして、その下の2Wayサーバーやデンシティ(高密度)サーバーやミッドレンジワークステーション、つまりIA-32系CPUが今占めているポジションに、Deerfieldが来る。
そして、さらに2004年には、次のIA-64 CPUが控えている。IntelのLisa Hambrick氏(Director, Enterprise Processor Marketing)は、昨年春、このCPUについて「5つ目のIA-64 CPUをすでに計画している。Madisonよりさらにパフォーマンスをのばした新しいマイクロアーキテクチャのCPUになる」と説明していた。Intelは、今回、IA-64にマルチスレッディングやマルチコアオンダイ(1つのダイに複数のCPUコアを載せる)などの技術を採用することも明らかにしている。おそらく、こうした技術が次々世代IA-64に投入されると見られる。
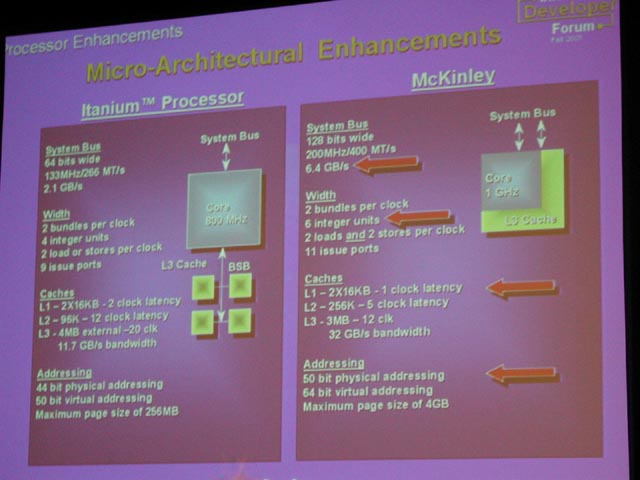
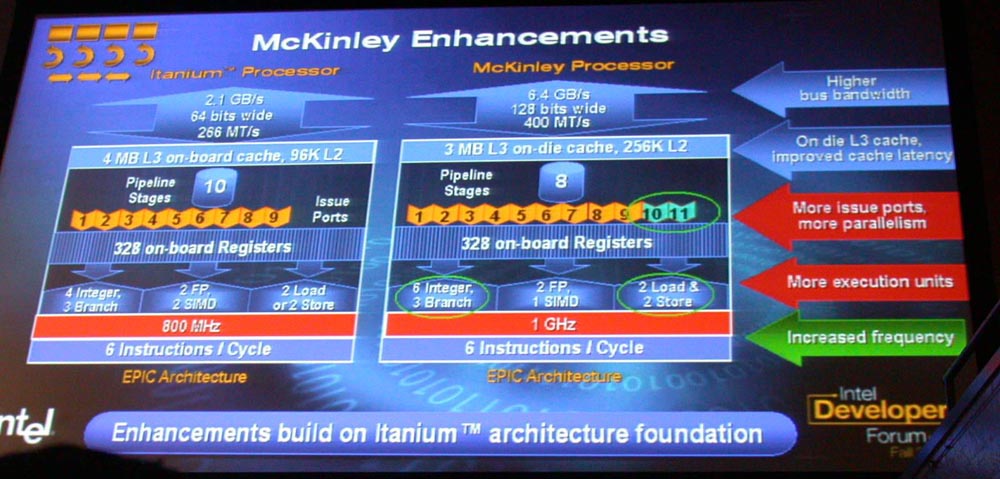
●クロック向上はそれほどでないMcKinley
Intelによると、McKinleyは、最初のIA-64プロセッサである「Itanium(Merced:マーセド)」の1.5~2倍の性能を達成するという。MercedとMcKinleyは、同じ0.18μmプロセッサ。製造プロセスが同じで、どうやって2倍の性能を達成できるのかというと、それは次のような改良による。
・クロックの向上
・キャッシュの性能向上(レイテンシの短縮、帯域向上、容量とアソシエイティブの増加)
・システムバスの改良
・実行ユニットの増加
まず、クロックはMercedの800MHzに対して、McKinleyではターゲットが1GHzに上がった。ただし、同じ0.18μm世代ではPentium IIIが1.13GHzでPentium 4が2GHzまで行く。それと比較すると、クロック向上に対しては、相変わらずそれほどアグレッシブではない。それは設計を見てもわかる。
 |
 |
 |
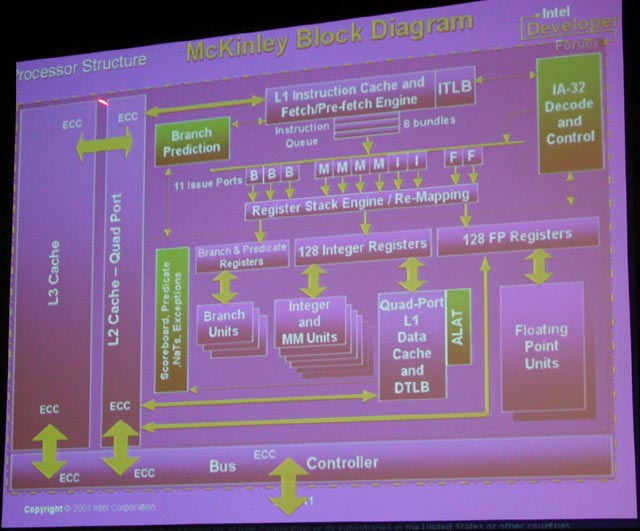
| McKinleyのブロックダイアグラム | McKinleyのパイプライン | McKinleyの命令発行 |
例えば、パイプライン段数は8ステージで、20ステージ以上になるPentium 4と比べるとずっと少ない。一般的には、パイプラインを細分化するほど、クロックを上げやすくなる。もっとも、Pentium 4には、IA-64には不要な複雑なスケジューリングがパイプラインに含まれているので、単純には比較できない。だが、例えば、ネックになりやすいキャッシュアクセスにMcKinleyは1ステージしか割いていない。これがPentium 4だとネクストIPの生成だけでも2ステージに分解されている。つまり、McKinleyはクロック向上に力点を置いた設計をしてないのだ。
●性能/クロックに注力した設計
キャッシュに関しては大きく改良された。まず、これまで外付けSRAMチップだったL3キャッシュをオンダイにした。これにより、L3キャッシュのレイテンシは20クロックから12クロックへと激減、帯域は11.7GB/secから30GB/secへと大幅に増大した。同様にL1が1クロックレイテンシ、L2が5クロックレイテンシと、それぞれMercedより小さい。L1の1クロックというのは、2クロックレイテンシが普通の最近のプロセッサでは非常に珍しい。
こうしてみると、McKinleyはクロック向上ではなく、パイプラインの短縮とメモリレイテンシの短縮に注力した設計であることがわかる。パイプラインやメモリレイテンシの短縮は、クロック向上とトレードオフの関係にある。McKinleyは、クロックを犠牲にして、パイプラインが止まる時間をできるだけ短くしようとしているように見える。
また、McKinleyではシステムバス(フロントサイドバス)も大きく改良された。これは、Mercedの2.1GB/secからMcKinleyの6.4GB/secへと、じつに3倍に跳ね上がっている。もっとも、これはMercedのバスがそもそも貧弱過ぎたと言えるかもしれない。Mercedの64bitバスからMcKinleyの128bitバスになって、初めてバンドル(IA-64命令の1パック)の幅(128bit)とつりあった。IA-64では、性能/クロックが高いために、原理的にIA-32と比べてより広いバスが必要となる。
こうした改良により、McKinleyは最大でMercedの2倍の性能になるという。Intelによると、実際、Merced用にコンパイルしたコードで、Specint2000は1.7倍の性能に達しているという。McKinley用のコードなら、性能はさらに引き上げられるだろう。というのは、IA-64アーキテクチャの場合、演算ユニットの構成やメモリのレイテンシなどをすべて織り込んでコードを生成しないと、そのCPUの性能を引き出せないからだ。
つまり、Merced用のバイナリではMcKinleyの真価は発揮できない。これは、スケジューリングの多くをコンパイラが静的に行なっているからだ。Merced用のコードでも1.7倍の性能になったのは、クロックの向上やペナルティやレイテンシの減少などで達成されたと見られる。2倍の性能は、うたい文句だけではないだろう。McKinleyの内部アーキテクチャや、870チップセットについては、またあとでレポートしたい。
(2001年8月31日)
[Reported by 後藤 弘茂]