
|
|


●マルチスレッド技術をデスクトップ&モバイルにも
「Hyper-Threadingテクノロジは、最初はXeon MPにインプリメントされる。この製品は、サーバー&ワークステーションがターゲットで、来年の早い時期に登場する。だが、我々は、Hyper-ThreadingテクノロジをデスクトップCPUにもたらすことも計画している。また、モバイルCPUにもだ。我々は、Hyper-Threadingを(デスクトップ/モバイルCPUに)入れる能力は持っている。MicrosoftやほかのISVと密接に協力しながら、(Hyper-Threading技術を)投入する適切なタイミングを図る」
Intelのアナンド・チャンドラシーカ(Anand Chandrasekher)氏(Vice president, Intel Architecture Group, director, Intel Architecture Marketing Group)は、IDFのグループインタビューでこのように答えた。そう、Intelのマルチスレッドプロセッサ技術「Hyper-Threading」は、デスクトップ/モバイルの領域にも入ってくるのだ。それも、それほど遠くないうちに。Pentium IIにSSE命令が加わってPentium IIIになったように、Pentium 4にHyper-Threadingがプラスされた拡張版Pentium 4が、Northwood(0.13μm版Pentium 4)の先に登場する可能性が高い。
では、この拡張版Pentium 4ではどうなるのか。Intelによると、OSは、CPUIDを見てHyper-ThreadingをインプリメントしたCPUかどうかを判断するという。これは、Hyper-Threading対応のモディフィケーションをしたコードが必要だからだ。Hyper-Threading対応CPUだった場合には、従来のデュアルプロセッサシステムの場合と同じように、OSがスレッドを各ロジカルCPUに割り当てる。
Intelによると、マルチスレッドアプリケーションやマルチタスクのワークロードで20%以上の性能向上をもたらすという。ひとつのCPUで、デュアルプロセッサ構成に近い性能になるのだから、これはおいしい話だ。普通のPCユーザーにとっても、バックグラウンドタスクが走っている時も性能が落ちないという利点がある。
ただし、これはまだ第1世代のHyper-Threadingで、Intelの目指す「スレッドレベルの並列化(TLP:Thread-Level Parallelism)」の真価が発揮されるのは、その先、Pentium 5や6でのことになりそうだ。というのは、今のHyper-Threadingでは、シングルスレッドアプリケーションのパフォーマンス自体は向上しないため、PCではエンドユーザーの体感性能がそれほど改善されないからだ。だが、将来のIntel CPUでは、シングルスレッドアプリケーションも、TLPで高速化できるようにすると見られる。実際に、Intelは、昨年あたりからそのための研究の結果を発表し始めている。
●スペキュレイティブなスレッド実行
では、シングルスレッドのアプリケーションをどうやってマルチスレッディングで高速化するのか。IntelはIDFで、そのための手法の一例についての説明も行なった。IntelのJustin Rattner氏(Intel Fellow, Director of Microprocessor Research Labs)によると、スペキュレイティブ(投機的:Speculative)にスレッドを実行することで、シングルスレッドのアプリケーションの性能が画期的に向上するという。
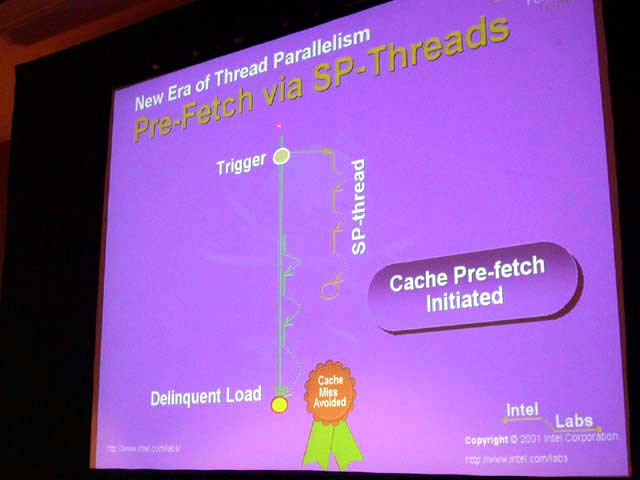
Intelは、この研究をしばらく前から行なっており、「疑似マルチスレッディング(Pseudo Multithreading)」と呼ぶ手法の論文をいくつか発表しているという。これは、シングルスレッドのアプリケーションを、スレッドに分けて並列実行するものだ。IDFでは、その中の「Speculative Pre-computation(スペキュレイティブプリコンピュテイション)」という手法についての説明が行なわれた。
Speculative Pre-computationでは、スペキュレイティブスレッドを使うことで、メモリのレイテンシを隠蔽する。どういうことかというと、プログラムがデータのロード待ちでストールした場合や、ストールしそうなロードの手前に来たところで、プライマリスレッドとは別なスレッドを生成してしまう。そして、そのスレッドで、プライマリスレッドがストールしている間に、先のコードをどんどん実行してしまうという。
今回説明された手法の場合、別スレッドの方は破棄してしまうが、それでも、本筋のプライマリスレッドがロード命令を実行する時には、L1キャッシュにすでにデータが入っていることになる。つまり、必ずL1データキャッシュにヒットすることになり、L1キャッシュミスがなくなるわけだ。
今のCPUの場合、性能を落とす最大の原因はメモリからのロードのレイテンシだ。それは、CPUコアクロックが速くなって、メモリとのギャップが開いてしまったためだ。メインメモリはもちろん、L2キャッシュにしても、今ではレイテンシが長い。そのため、ロードの時間を隠蔽するだけで、性能がぐっと上がるという。
この場合、スペキュレイティブスレッディングは、プリフェッチングとして使われていることになる。では、このSpeculative Pre-computationは、どこがハードウェアプリフェッチよりいいのか。それは、ハードウェアプリフェッチだと、メモリへのアクセスパターンが予測できる場合にしか有効でなかったからだ。この手法なら、従来のプリフェッチで拾えなかったロードも含めた完璧なプリフェッチができるという。Rattner氏によると、99%のキャッシュミスがなくなる。ほとんど理想的なメモリマシーンになるという。
 |
 |
●CPUが自動的にマルチスレッドにしてしまう
Rattner氏によると、この研究はItaniumで、コンパイラをモディファイして行なったという。しかし、Intelの目標は、こうしたスペキュレイティブマルチスレッディングを、CPUのハードウェア(あるいはCPUに被せたソフトウェアレイヤー)でコントロールすることだと思われる。実際、Rattner氏は質疑応答の中で、「ダイナミックスレッドクリエイション(Dynamic Thread Creation)」と呼ぶ将来の展開を示唆した。これは、CPU側がスレッドに分解できるブロックを見つけて自動的にスペキュレイティブスレッドを生成、実行してしまう方法のようだ。これについては、IntelのMRLの論文「Better Exploration of Region-Level Value Locality with Integrated Computation Reuse and Value Prediction」(Youfeng Wu & Dong-Yuan Chen & Jesse Fang, July 2001)などで、すでに具体的に触れられている。
ダイナミックスレッドクリエイションを使うと、アプリケーション側はスペキュレイティブマルチスレッドを意識する必要がない。アプリケーションは、シングルスレッドのつもりで走っているのに、自動的にマルチスレッドに分解され並列に実行されてしまうからだ。つまり、今まで使っていたシングルスレッドアプリケーションが、CPUを変えただけでマルチスレッド対応になってしまうのだ。
 |
では、具体的に自動生成したスレッドで、どうやってプログラム実行を高速化するのか。これについては、IntelのFred Pollack氏(Intel Fellow,Director, Intel Architecture Strategic Planning, Intel Architecture Group)がPACT 2000で行なったプレゼンテーション「New Challenges in Microarchitecture and Compiler Design」で説明している。
それによると、例えば、callで飛んだ先を実行している時に、別スレッドでcallから先の命令ストリームを実行する。あるいは、ループのボディをそれぞれ別スレッドに分けて並列に実行してしまう。または、命令ストリームの先の部分を別スレッドで先に実行してしまう、ループから抜けたあとのコードをループを実行している間に実行してしまう。これを図式にすると図のようになる。つまり、スレッドに分解して並列に実行してしまうことで、プログラム実行のスループットを上げようというわけだ。
さっきのSpeculative Pre-computationでは、スペキュレイティブスレッドの結果は破棄してしまっていたが、スペキュレイティブスレッドの結果がコレクトかどうかをチェックできるようなスレッド間コミュニケーションの仕組みを作れば、破棄する必要はなくなる。
●新パラダイムを迎えたCPUアーキテクチャ
Intelによると、こうしたスペキュレイティブマルチスレッディングで、CPUの並列化は新しいステップに上がるという。これまでよりも並列化が広域のコード内で行なわれる。これまでのインストラクションレベルの並列化ではなく、コードブロックのレベルでの並列化になるという。CPUの実行ユニットが、これまでよりずっと効率的に使われるようになれば、性能は大きく向上する。
もっとも、スペキュレイティブマルチスレッディングには課題も多い。例えば、データのディペンデンシ(依存度)が問題になってくる。そのため、Intelはバリュープレディクションと呼ばれる手法も組み合わせるつもりだ。これまでのCPUのプレディクションは、条件分岐の予測だったが、今後はデータの値まで予測してしまう。このバリュープレティクションは、CPUアーキテクチャ開発の最前線でトレンドの手法らしく、さまざまな論文が出てきている。正直な話、素人には手に負えない、アーキテクトたちの奥の院の議論の段階だ。ただ、Pollack氏のプレゼンテーションを見ると、80~90%の予測ができるといった研究結果が出ている。いずれにせよ、これだけ研究が盛んになってくると、インプリメントされるのも時間の問題だろう。
というわけで、CPUのテクノロジは、どうやら新しい段階を迎えたようだ。CPUのアーキテクチャは、それぞれ次のようにシフトする可能性が高い。
・インストラクションレベル→スレッドレベル
・スペキュレイティブエグゼキューション→スペキュレイティブスレッディング
・ブランチプレディクション→バリュープレディクション
つまり、パラダイムが変わろうとしているのだ。そして、今回、新パラダイムへの一番乗りを果たすのは、Intelになりそうだ。
(2001年8月30日)
[Reported by 後藤 弘茂]