 |


■後藤弘茂のWeekly海外ニュース■AMDが1TFLOPS GPU
|
●AMDがプレスイベントで1TFLOPSのRV770の特長を紹介
AMDも1TFLOPSのGPU「Radeon HD 4800(RV770)」ファミリで、NVIDIAに対抗する。
AMDは、米サンフランシスコで、6月16日(現地時間)に開催したプレスイベント「Cinema 2.0 Event」で、近日中にリリースする新世代GPU「RV770」の浮動小数点演算性能が1TFLOPSに達することを明らかにした。AMDのRick Bergman(リック・バーグマン)氏(Senior Vice President & General Manager, AMD Graphics Product Group)は、AMDがグラフィックス製品として初の1TFLOPS製品をリリースすることを強調。競合であるNVIDIAのグラフィックス製品GeForce GTX 280(GT200)が、1TFLOPSを若干下回ることから、自社の優位を謳った。GPUは、“1TFLOPS GPU戦争”の様相を帯びてきた。
AMDが謳うRV770の利点は、非常に明瞭だ。TSMC 55nmプロセスで製造されるRV770チップのダイサイズは、約16mm角で約250平方mm前後のダイサイズ(半導体本体の面積)だという。対するNVIDIAのGT200のダイは580平方mmに近い。RV770のトランジスタ数は950M(9億5,000万)台と、これもGT200の1.4B(14億)よりぐっと少ないという。そのため、消費電力と製造コスト面、ひいては価格でRV770は優位に立つとAMDは主張する。Bergman氏は、イベントで1TFLOPSが、たった200ドルで手に入ると強調した。1TFLOPSボードの消費電力は110Wでシングルスロット仕様だという(ミッドレンジ製品はデュアルスロット仕様)。このほか、AMDは、RV770にGDDR5インターフェイスを実装したことを公式に明らかにした。
 |
 |
 |
| AMDのRick Bergman(リック・バーグマン)氏 | 演算能力は1TFLOPS超 | RV770とGT200の比較 |
また、AMDは今世代のハイエンドGPU「R700」も、2個のRV770で構成することを、公開のプレスセッションで明らかにした。Bergman氏は、COMPUTEX時のインタビューで、すでにR700がデュアルチップであることを明らかにしていた。
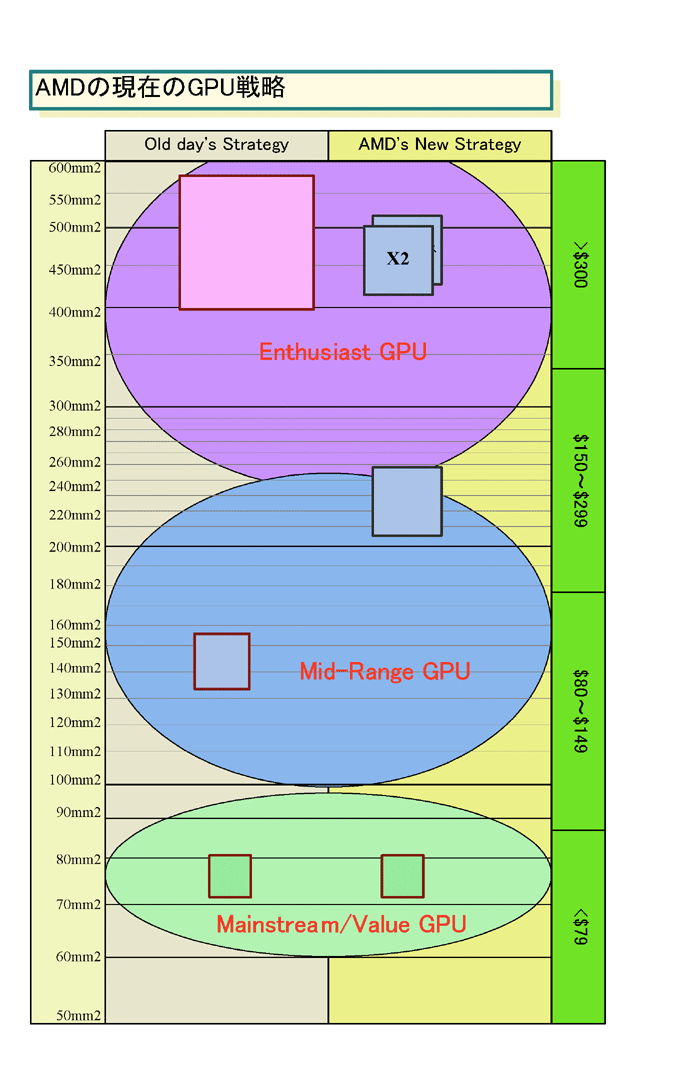
AMDはもはやNVIDIAのようなモンスターチップは作らない。ミッドレンジのGPUダイ(半導体本体)と、その下のメインストリーム&バリューGPUダイは作るが、ハイエンドは、2個のミッドレンジGPUで構成するデュアルチップ路線を堅持する。ATI TechnologiesがAMDと合併する前の、一昨年(2006年)6月のCOMPUTEX時からATI幹部はデュアルダイ化を語っていた。当時ATIの社長兼CEOだったDavid(Dave) E. Orton(デイブ・オートン)氏は次のように語っていた。
「グラフィックスの利点は、グラフィックスタスクがパーティション化が容易なので、GPUを、よりコストエフェクティブにできることだ。1チップで処理する代わりに、2チップで処理することで、もっと低コストにできる可能性がある。業界として見ると、価格性能比カーブを上げなければならないことは確かだ」。
R700に見られるデュアルチップ路線は、AMDにとってクリアな戦略であることがわかる。
 |
| AMDのGPU戦略 PDF版はこちら |
●CPUの10倍の浮動小数点演算パフォーマンスがカギ
なぜGPUベンダーは、1TFLOPSにこだわるのか。
1TFLOPSはGPUベンダーにとって、汎用コンピューティングアプリケーションを惹きつけるための重要なマイルストーンだからだ。CPU側は、マルチコア化によって、ピーク浮動小数点演算性能を増しつつあり、クアッドコアでは3.2GHzで理論値で100 GFLOPSに達する。しかし、ここでGPUベンダーが、1TFLOPSを示すことができれば、10倍の性能差を維持することができる。
この10倍という数字は、一種のマジックナンバーだ。Cell Broadband Engine(Cell B.E.)の発表の際に、あるCell関係者は「2倍程度のパフォーマンス差なら、わざわざプログラムを書き換えてはくれない。しかし、10倍のパフォーマンス差なら、アーキテクチャの変化を受け入れてもらえると考えた」と語っていた。10倍のパフォーマンス差があるのなら、CPUではなくGPUにプログラムを書いてもらえる、それが1TFLOPS化への重要なモチベーションだと推測される。
少なくとも、NVIDIAは、1TFLOPSにそうした意味を見出している。そして、それに対抗するAMDも、CPU製品が不調である分、GPU製品で盛り返したい。となると、NVIDIAと同じラインで、汎用アプリケーションを狙う方向へ向かうことになる。そのために1TFLOPSが重要になる。
●1TFLOPSの実効性能を競うフェイズに
ただし、1TFLOPSからマーケティングのベールをはがすと、その競争は違った側面を帯びてくる。1TFLOPSに最初に惹きつけられるハイパフォーマンスコンピューティング(HPC)コミュニティにとっては、どちらの理論値1TFLOPSが、本当に高いリアル性能を発揮するかが問題となる。両社とも、ピーク性能での1TFLOPS製品を投入した後は、実効性能を競うことになる。同時にプログラミングの容易性も。
AMDは、VLIW(Very Long Instruction Word)型フォーマットによる命令レベルの並列性(ILP:Instruction-Level Parallelism)を追求した内部プロセッサコアのアーキテクチャの有効性を試されることになる。NVIDIAについても同じことが言える。その意味では、1TFLOPS戦争は、まだ始まったばかりだ。
ちなみに、AMDはGPUによる汎用コンピューティングのための人材を集めている。その1人は、スタンフォード大学のStanford Graphics Labの研究者として知られていたMike Houston(マイク・ヒューストン)氏で、ストリームプログラミング言語「BrookGPU」や、分散コンピューティング「Folding@Home」でのGPUクライアントプロジェクト、そして、プロセッサのメモリ階層をプログラミング言語の中でモデル化する「Sequoia(セコイア)」プロジェクトなどをリードした。GPUを汎用に使う研究のリーダーの1人だ。
Houston氏は、現在、AMDのアーキテクトグループにおり、ソフトウェアとハードウェアの両面をカバーしているという。AMDが、GPU上での汎用コンピューティングに注力していることは確かだ。ちなみに、スタンフォード大学でBrookなどのプロジェクトでHouston氏の同僚だったIan Buck氏は、NVIDIA CUDAの技術リーダーとなっている。
●ハイエンドGPUで分かれたNVIDIAとAMDの選択
ハイエンドGPUをどう構成するか、その点で、NVIDIAとAMDは2つに分かれたコースを進みつつある。
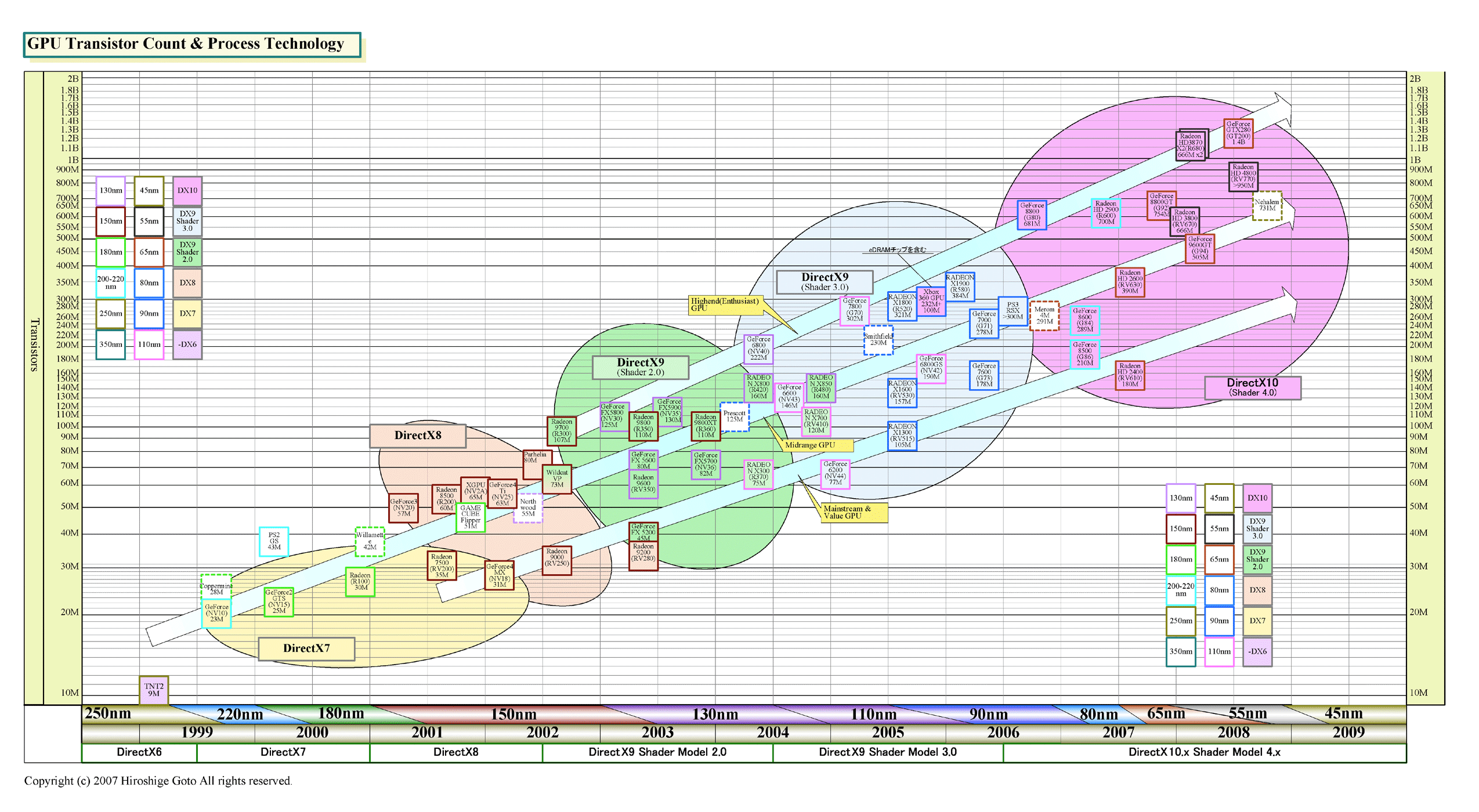
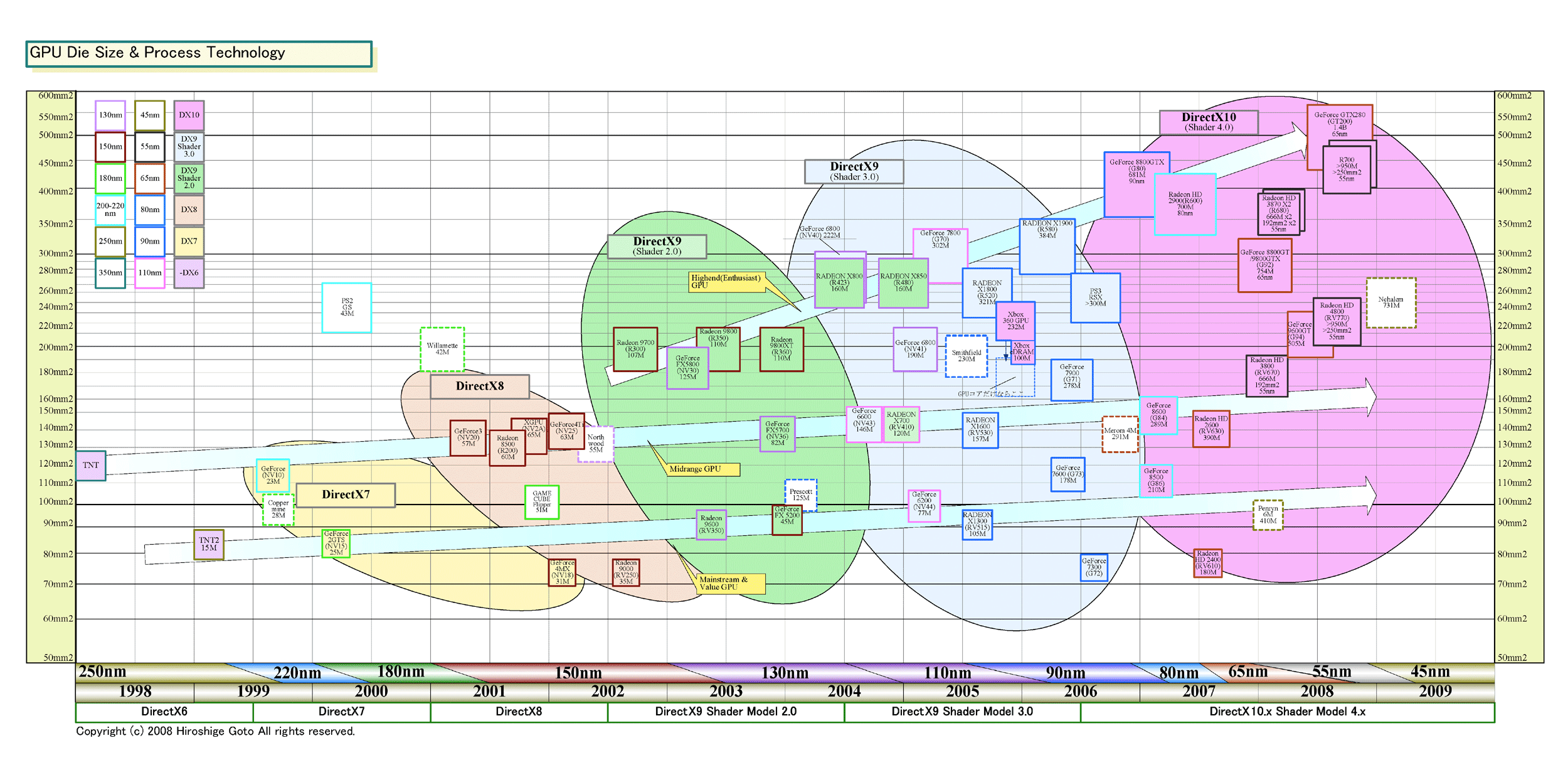
GPUメーカーは、DirectX 9世代以降、大まかに言って3種類のGPUを作ってきた。1番上のエンスージアスト向け、その下のパフォーマンス&メインストリーム向け(ミッドレンジ)、そして一番下のバリュー向けだ。それぞれ性能が異なり、ダイサイズ(半導体本体の面積)が違う。そして、最上位のエンスージアスト向けは、性能競争のために肥大化を続け、DirectX 10世代では、ダイサイズが400平方mmを超えてしまった。ハイエンドサーバーCPUクラスのサイズだ。
GPUベンダーは、DirectX 9世代以降は、GPUをより大きくし、トランジスタ数を増やすことでパフォーマンスを強化した。DirectX 8世代のハイエンドGPUのダイサイズ(半導体本体の面積)は大きくても150平方mm程度だったのが、DirectX 9 Shader Model 2.0世代では200平方mm前後に増えた。ダイはDirectX 9 Shader Model 3.0世代で300平方mmに達し、DirectX 10世代ではついに400平方mmを超えた。これは、CPUで言えばMPサーバー向けハイエンドCPUのサイズだ。
 |
| GPUのトランジスタ数の変遷 PDF版はこちら |
 |
| GPUダイサイズの変遷 PDF版はこちら |
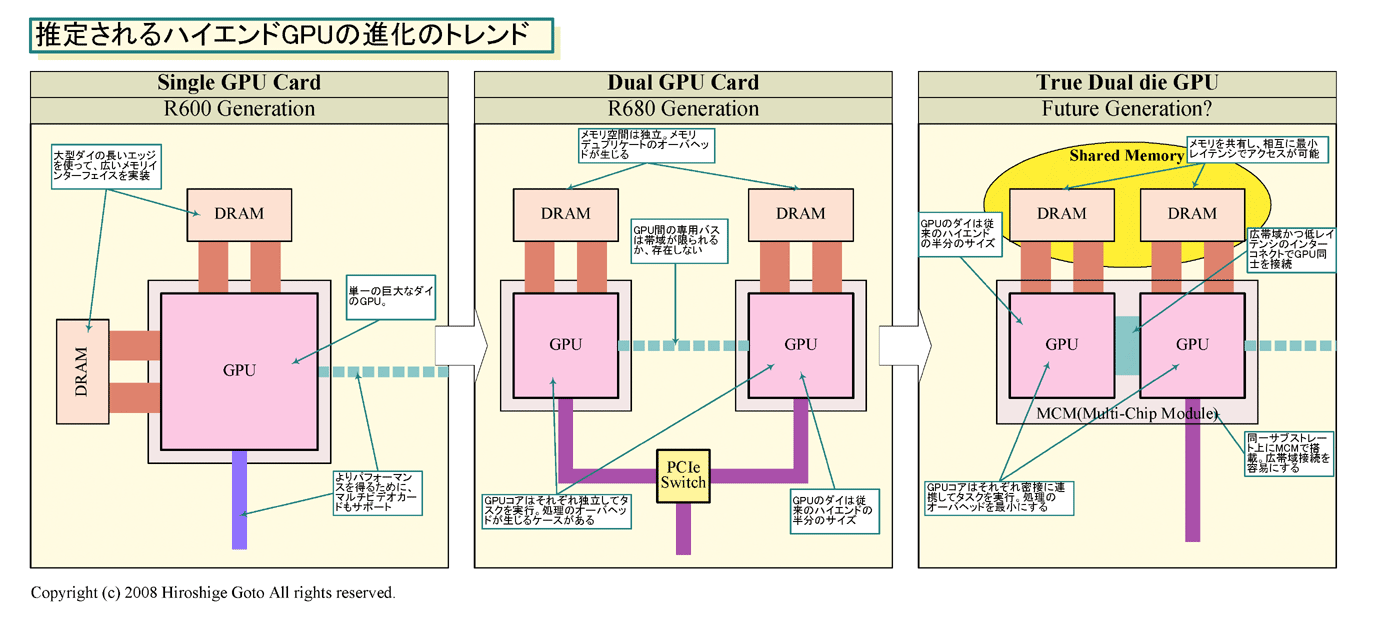
NVIDIAは現在もこの路線を歩んでおり、470平方mmのGeForce 8800(G80)、570平方mm台のGeForce GTX 280(GT200)と確実に巨大化している。それに対してAMDは、前世代からハイエンドの「Radeon HD 3870 X2(R680)」で、巨大チップはやめた。ミッドレンジGPU「Radeon HD 3800(RV670)」を2個の構成へと切り替えた。RV670のダイサイズは192平方mmと、それまでのハイエンドの半分のミッドレンジクラスだ。
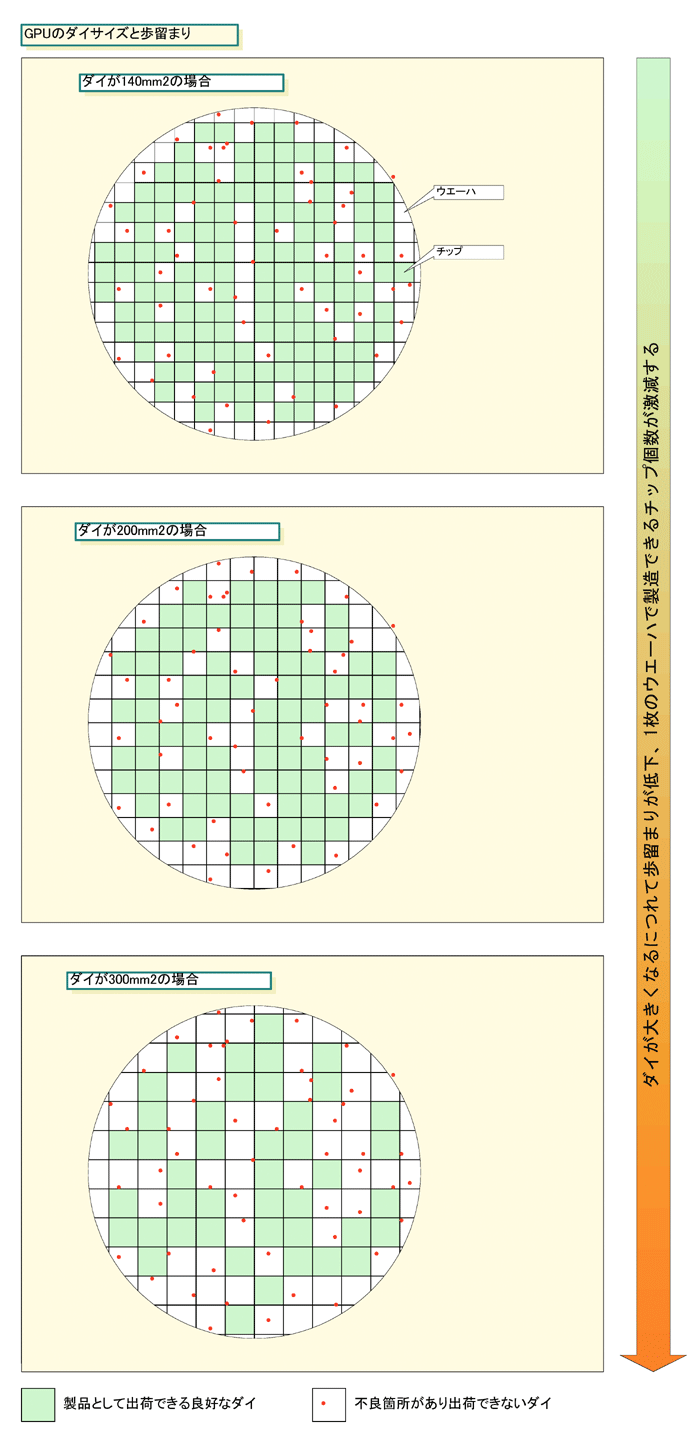
ダイが巨大化すると消費電力が増大するだけでなく、製造コストが激増する。大型ダイでは、1枚のウェハから採れるダイの数が減る。さらに、半導体チップは、製造過程でのウェハ上の欠陥(Defect)のために不良ダイが発生してしまう。ダイが大きくなると、1個のダイエリアに欠陥が含まれる可能性が増えるため、良品の率(歩留まり)も悪くなる。
つまり、ダイの面積が2倍になると、製造できるチップ個数は1/2ではなく、1/3あるいはそれ以下に減ってしまう。その結果、GPUコストが増大する。GPUでは、ダイの上の欠陥が含まれた部分をディセーブルして、シェーダ数の少ない廉価版として売ることで、この問題を軽減している。それでも、コスト面では非常に厳しい。
 |
| GPUのダイサイズと歩留まり PDF版はこちら |
●2個のミッドレンジGPUでハイエンドGPUを
AMDの選んだデュアルチップの道は、この問題の解決となる。ミッドレンジのGPUダイを2個使って、ハイエンドGPUを作るなら、ダイサイズが半分になり、1枚のウェハに配置できるダイ数が増え、ダイサイズが半分になることで歩留まりも上がる。結果として、製造コストが大幅に下がる。
また、エンスージアストGPU向け巨大チップのために、半導体製造用のマスクを作る必要もない。現在は、マスクコストが高騰しており、チップ設計数を絞って大量に製造しないと割に合わない。この面でも、1種類のダイで2つの市場(=価格帯)に対応するAMDの戦略はコストエフェクティブだ。
ただし、副作用もある。NVIDIAは大型のダイを比較的低速で走らせることで、電力密度の向上を抑えている。比較的小型のダイで性能を引き出すため、やや高速で走らせると、電力密度の向上を招く。また、小さなダイではエッジ長が限られるため、DRAMインターフェイスの幅を広げにくい。512-bitインターフェイスは大型ダイだから実現できた。200平方mm程度のダイのエッジ長では、ミッドレンジの256~384-bitインターフェイス程度が妥当だ。
しかし、AMDはGPU内部のコンピュテーションパフォーマンスは、1TFLOPSを実現する。そのため、AMDはNVIDIAが512-bitインターフェイスで実現するのと同等レベルのデータ転送を半分程度のインターフェイス幅で実現しなければならない。AMDがGDDR5を採用する理由の1つは、そこにあると推測される。
●オーバーヘッドが壁となるデュアルGPU
AMDの選んだデュアルチップ構成のハイエンドGPUは、製造コストの面では有効だ。ただし、課題もある。それは、理論上のパフォーマンスはともかく、実効性能をどうやって上げるかだ。SLIやCrossFireといったマルチGPU構成では、必ずしも実効パフォーマンスが保証されない。それは、マルチプロセッサ構成をサポートする仕組みを持たないためだ。CPUで言えば、シングルプロセッサ用のCPUを無理矢理接続して、ソフトウェアで制御して処理を分散しているのが、現状のマルチGPUソリューションだ。
そのため、2個のGPUの間で、処理やデータのオーバーヘッドが生じてしまう。2 GPU間でジオメトリなどのコンピュテーションがオーバーラップしたり、両メモリに同じデータを複製して持っているといった無駄が発生している。
AMDとの合併後にAMDを去ったOrton氏は、AMD時代に次のように語っていた。
「1チップの代わりに、2チップで処理するためには課題がある。それは、フレームバッファメモリをデュプリケート(二重化して持つ)ことは望ましくないということだ。この点を最適化する必要がある」。
現状では、SLIもCrossFireも、メモリの重複とそれに伴うコンピュテーションの重複という問題を抱えている。各GPUチップに接続されたビデオメモリは、それぞれ独立しており、これまでは相互に直アクセスもできないし、互いのデータの一貫性(コヒーレンシ)もハードウェアでは取られていない。オーバーヘッドがあるため、マルチGPUで走らせても、リニアにパフォーマンスが伸びないケースが発生する。
●AMDのデュアルGPUソリューションの今後
この問題を解決する方法はいくつか考えられる。
1つは、2個のGPU間で、メモリコヒーレンシをハードウェアで取ること。データの複製は行なうが、データの一貫性はハードウェアで制御する。ソフトウェア処理のオーバーヘッドを減らすことができる。
より進んだ方式は、連結されたGPUダイがメモリ空間を共有し、それぞれのメモリに直接アクセスできるアーキテクチャにすることだ。AMD CPUで、マルチプロセッサ構成時のOpteronが、他のOpteronに接続されたメモリに直接アクセスするNUMA構成を取るのと同じだ。メモリ共有が実現すると、各GPUコア間での、データの複製や重複したコンピュテーションが不要になる。CPUのマルチプロセッサと同じ環境が実現し、柔軟なタスク分割が可能になる。パフォーマンスも、リニアに近く引き出せるようになる。
 |
| 推定されるハイエンドGPUのトレンド PDF版はこちら |
Bergman氏は、COMPUTEX時に次のように答えていた。
「まさにそういったアイデアを、数年前に検討した。例えば、シングルメモリスペースで、テクスチャなどを共有するといったアイデアだ。しかし、その時は、適切だと思える解を見つけることができなかった。最大の壁は、(GPU間の)ハイスピードコミュニケーションが必要なことだ。コスト面を考えると、今のソリューションよりベネフィットがある方法を考えられなかった。しかし、R700デュアルGPUソリューションでは、今話題に上ったいくつかのイシューに対して、なんらかの答えをすることができるだろう」。
理想型は、GPUダイ同士を、広帯域で低レイテンシのインターコネクトで接続することだ。AMD CPUやIntelのNehalemがCPU間を高速インターコネクトで結ぶのと同じアプローチだが、違いがある。コンピュテーションパフォーマンスの高いGPU同士の接続には、CPUよりずっと広帯域のインターコネクトが必要だ。
ダイ間の超広帯域接続を低コストに実現するためには、2個のGPUダイを同じチップパッケージ上に載せることが望ましい。サブストレート上であれば、レイテンシの短いパラレル伝送で、極広いインターフェイス幅の接続ができるからだ。Xbox 360のGPU(Xenos)では、GPUダイとROPパスをそうした広帯域インターコネクトで、オンサブストレートで接続している。AMDがデュアルGPUソリューションを続けるとしたら、次のフェイズのマルチダイGPUでは、そういったデュアルダイパッケージへと進化するのが必然だろう。
□関連記事
【6月17日】AMD、200ドルで1TFLOPS越を実現するRadeon HD 4850を6月25日出荷
http://pc.watch.impress.co.jp/docs/2008/0617/amd.htm
【6月17日】【海外】NVIDIAの1TFLOPS GPU「GeForce GTX 280」がついに登場
http://pc.watch.impress.co.jp/docs/2008/0617/kaigai446.htm
【2007年12月5日】【海外】2個のGPUダイを密接に連携させたデュアルダイGPUが次のステップ
http://pc.watch.impress.co.jp/docs/2007/1205/kaigai405.htm
【2007年7月9日】【海外】AMDが次期GPU「R700」を巨大にできない理由
http://pc.watch.impress.co.jp/docs/2007/0709/kaigai371.htm
【2007年7月5日】【海外】AMDの次世代GPUは55nmプロセスがターゲット
http://pc.watch.impress.co.jp/docs/2007/0705/kaigai370.htm
(2008年6月17日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.