 |


■後藤弘茂のWeekly海外ニュース■2個のGPUダイを密接に連携させたデュアルダイGPUが次のステップ |
●マルチGPU化でのコスト削減の効果が大きいRadeon HD 3870 X2(R680)
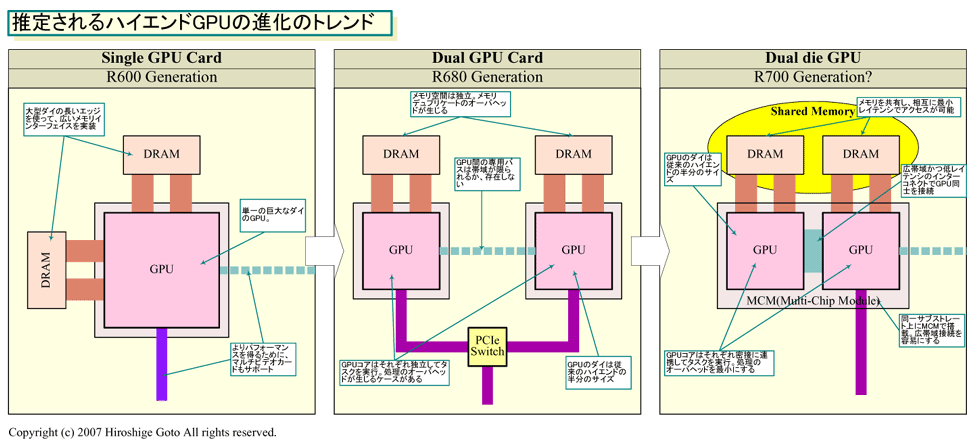
AMDは、GPUのマルチダイ(半導体本体)化へと向かい始めた。AMDの新しいハイエンド向け製品「Radeon HD 3870 X2(R680)」は、ミッドレンジGPU「Radeon HD 3800(RV670)」を2個、オンボードでCrossFire構成にしたものだ。これだけなら、これまでにもあったマルチGPUカードに過ぎない。しかし、その先の「R700」では、より密接なデュアルダイGPU化が行なわれると予測される。
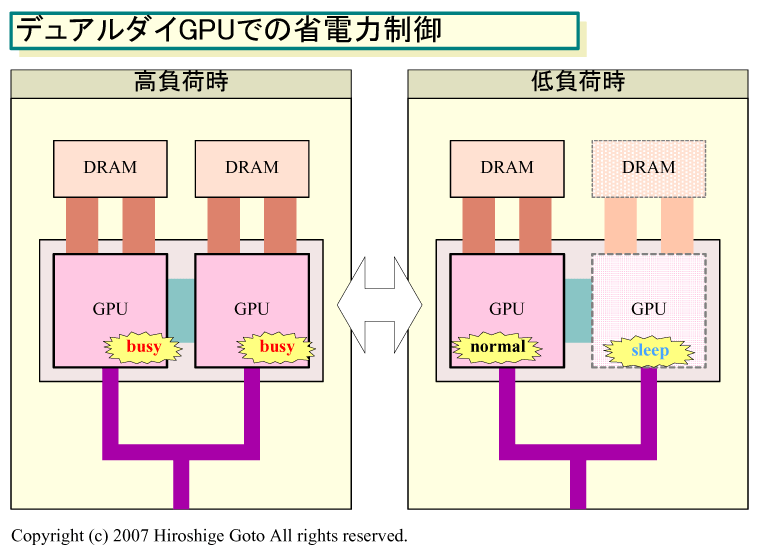
AMDがデュアルダイへと向かう理由は、大きく2つある。1つはコスト削減のため。巨大なダイサイズ(半導体本体の面積)のハイエンドGPUを作る代わりに、中程度のダイサイズのGPU 2個でハイエンドGPUを構成する。そうすれば、ハイエンドGPUをずっと低コストに作ることができるようになる。もう1つは、省電力制御のため。2個のGPUダイを負荷に応じてON/OFFすることで、電力消費を最適化する。
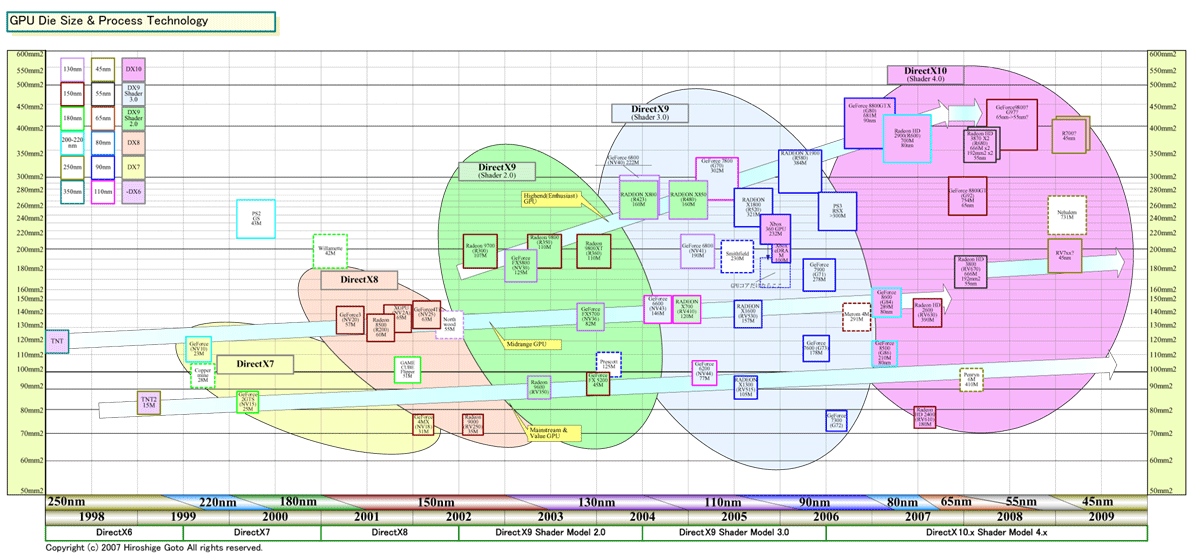
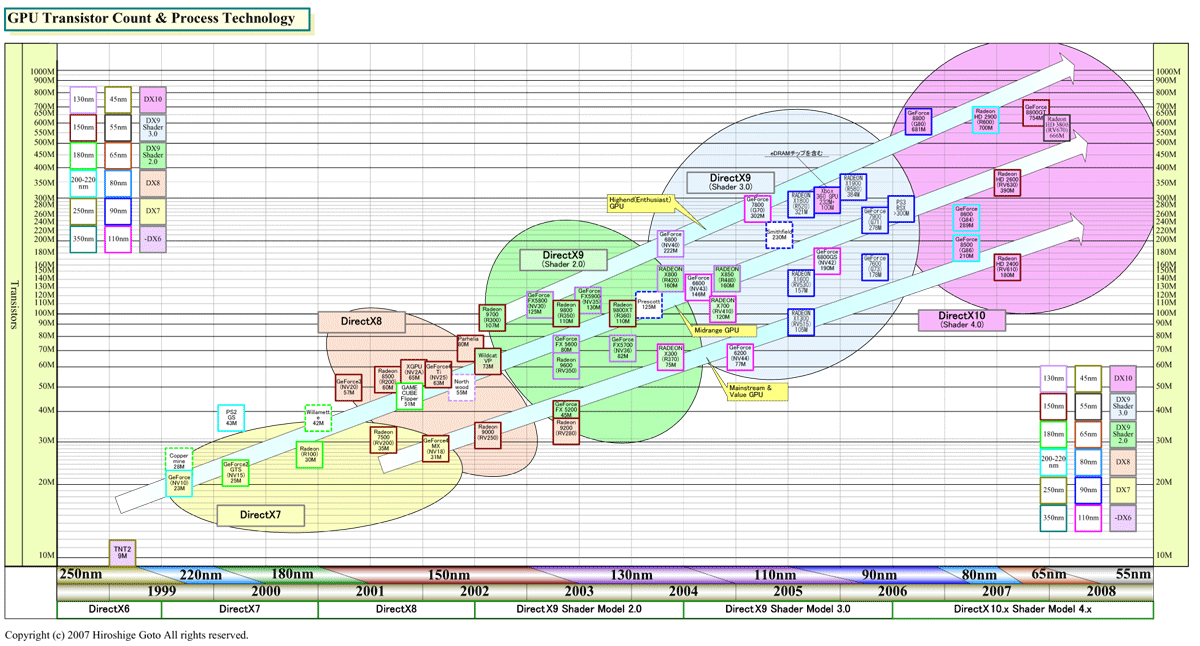
RV670は、ほぼ同じシェーダプロセッサ構成だった前世代のハイエンドGPU「Radeon HD 2900(R600)」の約半分のダイサイズである192平方mmに縮小した。そして、消費電力も、AMDの発表では、RV670はR600に対して消費電力では約49%、リーク電流では40%を下回り37%前後への低減を実現している。この、消費電力とリーク電流(Leakage)の低減は目覚ましい。
 |
| RV670でのリーク電流の低減 ※別ウィンドウで開きます PDF版はこちら |
1世代(80nm→55nm)プロセスが微細化すると、同じトランジスタ数のチップ上のキャパシタンスは70%に減少する。その計算では、RV670の消費電力はR600に対して70%までしか減らないはずだ。ところが、RV670では50%にまで下がっている。一見、計算が合わないように見えるが、それには理由がある。リーク電流の削減が大きく効いているためだ。
AMDの公表したチャートではRV670のリーク電流はR600の約36~37%程度になったように見える。もし、R600の消費電力のうち50%がリーク電流だったとしたら、計算上次のようになる。消費電力のうち、まず全体の半分を占めるアクティブ成分がキャパシタンスの減少で64%に下がり、さらに半分を占めるリーク電力が36%に下がる。すると、32%+18%で、全体の電力が約50%に下がる計算になる。
 |
| 推定されるハイエンドGPUの進化のトレンド ※別ウィンドウで開きます PDF版はこちら |
この計算では、キャパシタンスの減少分の計算値が、想定値とほぼ合致する。つまり、R600の電力の中で大きな割合を占めるリーク電流をさくっと3分の1に減らしたために、全体の消費電力が2分の1になったと考えられる。上記の計算が厳密に正しいかどうかはわからないが、リーク電流の削減が大きく効いていることから、R600ではリーク電流が膨大な比率だったことは確実だ。実際、ハイエンドCPUも電力消費の3分の1以上がリーク電流なのが普通だ。
 |
| デュアルダイGPUでの省電力制御 ※別ウィンドウで開きます PDF版はこちら |
 |
| GPUダイサイズと採用プロセス技術 ※別ウィンドウで開きます PDF版はこちら |
 |
| GPUトランジスタ数と採用プロセス技術 ※別ウィンドウで開きます PDF版はこちら |
●TSMCのプロセス自体が低消費電力へと振れる
なぜ、RV670ではリーク電流がそんなに減ったのか。日本AMDはRV670が採用したTSMC 55nmプロセスのリーク電流が65nmまでと比べて少ないためと説明する。しかし、55nmは65nmプロセスのハーフノードであり、ハーフノードの常としてトランジスタや配線層で大きな技術革新は行なわれていない。そのため、ハーフノードへの微細化というだけでは、トランジスタの改良が必要なリーク電流の低減がなされるとは考えられない。
この件については、TSMCが、65/55nmプロセス自体を、パフォーマンスから低電力へと振ったという背景を振り返る必要がある。もともとTSMCは65nmプロセスでは、GPUなど高速なロジック向けには、性能は中程度だが低リーク電流の汎用プロセス「CLN65GP」と、性能は高いがリーク電流の大きいハイパフォーマンスプロセス「CLN65HS」の2系統を提供する予定だった。2階層構成はTSMCの通常のパターンで、昨年(2006年)の段階ではTSMCはCLN65HSの提供を約束していた。
しかし、実際には、ハイパフォーマンスのCLN65HSはTSMCのロードマップから消えてしまった。また、55nmもハイパフォーマンスHS版がなく、汎用の「CLN55GP」だけが一般顧客には提供されている。つまり、TSMCの65/55nmでは、通常提供されるプロセスメニューからはHSカテゴリがなくなり、GPカテゴリの汎用プロセスでカバーするように切り替わった。
もっとも、AMDの採用しているのは、一般顧客向けのプロセスではない。AMDのCummings氏は「AMDが採用したのは、TSMCが提供する通常のプロセスではない。GPU向けにカスタマイズされた『CLN55G+』プロセスだ。GPプロセスよりパフォーマンスが高い」と説明する。しかし、型番から見ると、これもハイパフォーマンスプロセス系ではなく、汎用プロセス系のチューンナップ版だと見られる。型番は、実際にはCLN55GP+かもしれない。ちなみに、AMDが採用した65nmプロセスも、CLN65G+だったという。
●55nmではGPU向けプロセスもより低電力へと
詳細は不明だが、TSMCは65nmと55nmでは、HSを取りやめた代わりに、HSとGPの間で、パフォーマンスと電力のトレードオフのよいプロセス技術をGPUに提供したと見られる。おそらく、HSよりリーク電流が少なく、GPよりパフォーマンスの高いトランジスタを設定したと見られる。そして、このカスタマイズのさじ加減が、65nmと55nmでは異なり、55nmでは、より低リーク電流に振られたと推測される。
ちなみに、CLN65GPでは、80nmのハイパフォーマンスプロセスである「CLN80HS」に対して90%のパフォーマンスでアクティブ電力は約1.5分の1、リーク電流によるスタンバイ時の電力は約4分の1になる。それに対して、CLN65HSでは、性能はCLN80HSに対して30%増しで、スタンバイ電力はCLN80HSの約半分。スタンバイ電力が少ないように見えるが、それでもCLN65GPの2倍と依然として大きい。そのため、微細化によるキャパシタンスの増加とあいまって、チップ全体の消費電力は膨大になってしまう。
おそらく、それがCLN65HSの消えた理由だろう。CLN65GPは、性能(動作周波数)を引き上げるつもりがないのなら電力効率のいい選択となる。これは65nmのハーフノードである55nmでも事情が同じはずだ。
おそらく、AMDが今回採用したCLN55G+は、汎用プロセスのGPにかなり近く、性能より電力削減にレシピを振ったと推定される。また、同じプロセスでも、リーク電流の少ない高Vt(しきい電圧)トランジスタの比率を多くするといった、物理設計上の工夫によってもリーク電流を抑えられる。
各プロセスのパフォーマンスと電力の比較
| 80HS | 65GP | 65HS | |
|---|---|---|---|
| Vdd | 1 | 1 | 1 |
| Speed(25C) | 1.1 | 1 | 1.4 |
| Active Power(25C) | 1.5 | 1 | 1.3 |
| Standby Power(125C) | 4.13 | 1 | 2.1 |
●真のデュアルダイGPUには到達していないR680
こうして見ると、RV670コアは非常にパフォーマンス/電力効率が高く、コスト自体も低いコアであることがわかる。もちろん、従来のミッドレンジGPUが140~160平方mmのダイだったことを考えると、192平方mmのRV670のコストは高い。しかし、408平方mmのR600と比べると、コストは劇的に下がるはずだ。当然、プロセスの成熟度にも左右されるが、原理的にはコストは数分の1に下がる。
そのため、RV670を2個でハイエンドGPUを構成するというアイデアは、コスト的には非常に有効となる。RV670が2個分のダイサイズのGPUを製造しようとすると、RV670 2個を大きく上回るコストになってしまうからだ。AMD合併後の、ハイエンドGPUのコストを引き下げ、収益性を上げるというプレッシャーのためにデュアルGPUボードへと舵を切ったと推定される。
ただし、現在のR680は、AMDを去ったDavid(Dave) E. Orton(デイブ・オートン)氏(元Executive Vice President, Visual and Media Businesses, AMD)が、予告していたようなデュアルダイGPUにはまだ至っていない。そういう意味では、R680は過渡期の製品であり、緊急措置として用意されたようにも見える。なぜなら、Orton氏が指摘していた、デュアルダイGPU化の課題が解消されていないからだ。Orton氏は1年半前に、デュアルダイGPUについて次のように語っていた。
「1チップの代わりに、2チップで処理するためには課題がある。それは、フレームバッファメモリをデュプリケート(二重化して持つ)ことは望ましくないということだ。この点を最適化する必要がある」
現状では、SLIもCrossFireも、このメモリの重複とそれに伴うコンピュテーションの重複という問題を抱えている。
●GPUダイ間でのメモリ共有化が次のステップ
現在のマルチGPUソリューションでは、一般に、1つのグラフィックスタスクをフレーム内のリージョン単位、あるいはフレーム単位でパーティショニングして処理している。しかし、そこにはオーバーヘッドがある。例えば、2個のGPUの間のピクセルパーティションにまたがるジオメトリ処理がオーバーラップしたり、データを重複して保持しなければならない部分が生じる。そのため、Orton氏が指摘したような、GPUのコンピュテーションの重複(これもメモリが分割されているため生じている)と、GPUに接続されたメモリ内容の重複などのムダが発生してしまう。分割するのが1つのタスクという制約がある上に、オーバーヘッドがあるため、マルチGPUで走らせても、リニアにパフォーマンスが伸びないアプリケーションが出てしまう。また、電力効率の面でも、必ずしもよくない。
この問題を解決する方法は見えている。それは、連結されたGPUダイがメモリ空間を共有し、それぞれのメモリに直接アクセスできるアーキテクチャにすることだ。AMD CPUで、マルチプロセッサ構成時のOpteronが、他のOpteronに接続されたメモリに直接アクセスできるのと同じ仕組みだ。メモリ共有が実現すると、各GPUコア間での、データの複製や重複したコンピュテーションが不要になる。CPUのマルチプロセッサと同じ環境が実現する。
このアーキテクチャを実現するためには、GPUダイ同士を、広帯域で低レイテンシのインターコネクトで接続する必要がある。これは、AMD CPUやIntelのNehalemがCPU間を高速インターコネクトで結ぶのと同じだ。そして、メモリ帯域イータであるGPUダイ同士の接続では、バスはCPUよりずっと広帯域にする必要がある。
ダイ間の超広帯域接続を低コストに実現するためには、2個のGPUダイを同じチップパッケージ上に載せることが望ましい。チップのサブストレート上であれば、レイテンシの短いパラレル伝送で、広いインターフェイス幅で、かつ高転送レートのインターフェイスが、相対的に少ない電力で実現できる。おそらく、次のフェイズのマルチダイGPUでは、そうしたパッケージ形状になると推定される。
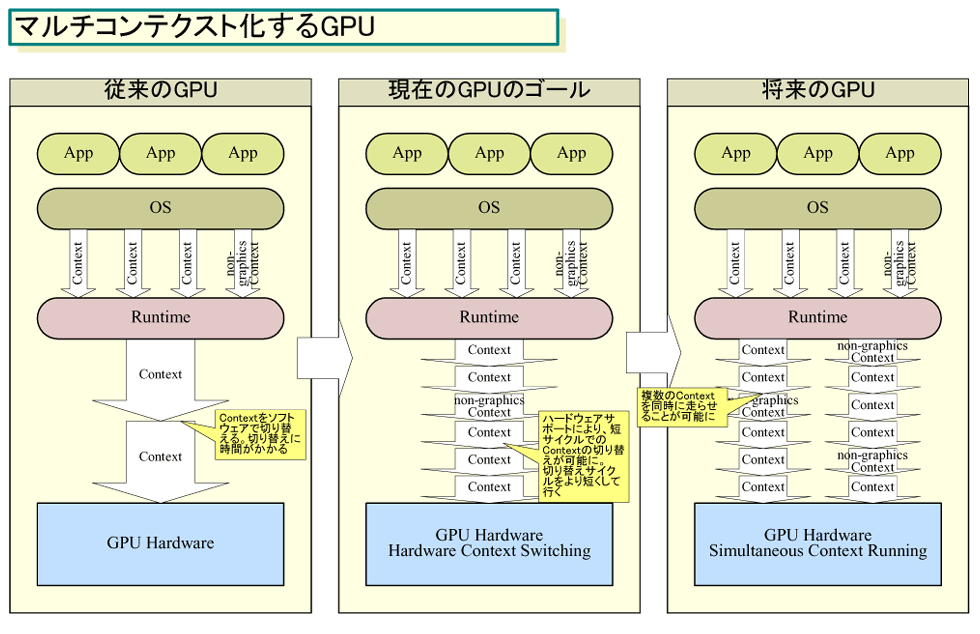
●GPUのマルチコンテキスト化とマッチするデュアルダイ化
デュアルダイGPUのもう1つの要件は、複数のGPUダイにまたがった、よりきめ細かな制御だ。GPU内の制御機構とランタイムソフトウェアであるドライバが、複数のGPUダイを連携させて効率的に制御する仕組みが必要になる。
現在のSLIやCrossFireでは、グラフィックス処理をフレーム単位やフレーム内のリージョンといった大きな単位で分割して割り振っている。しかし、2つのGPUダイがメモリ空間を共有して連携できるようになれば、粒度の大きな分割の必然性はなくなる。もっと小さな単位での、きめ細かで柔軟な分散化が可能になる。そうした制御がうまく働けば、より多くアプリケーションが、2個のGPUへの処理分散でのより大きな性能を享受できるようになる。
また、マルチダイGPUへの流れは、GPUのソフトウェア環境の変化にもマッチする。Microsoftは、Windows VistaからGPUのマルチタスク化を促進する方向へと進み始めた。従来のGPUは、シングルタスクシステムで、GDIベースのデスクトップやフルスクリーン3Dゲームのように、シングルクライアントであることを前提としていた。ところが、Windows Vistaからは、UIが3Dベースとなり、また、GPUリソースも仮想化されて、各アプリケーションが仮想化されたGPUにアクセスするようになった。複数のアプリケーションから仮想化されたGPUへの処理要求は、現状では時分割で物理的なGPUに割り振られる。
さらに、今後はGPUを非グラフィックスの処理にも使うようになって行く。非グラフィックス処理も、コンテキストの1つとしてGPUに割り振られることになる。例えば、NVIDIA GPUで、GPUコンピューティング向けのプログラミングモデル「CUDA」に沿ったプログラムを1 GPUで走らせる場合、グラフィックスとCUDAのコンテキストを時分割で切り替えている。例えば、フルスクリーンゲームであっても、GPUリソースを物理シミュレーションなどに使おうとすると、現状では2つのコンテキストを切り替えて走らせることになる。
GPU上で、多くのコンテキストを走らせるようになると、GPUコンテキストスイッチングをハードで制御するだけでなく、さらにコンテキストの切り替えを高速にし、オーバーヘッドを小さくしなければならなくなる。Microsoftも、この先のドライバモデルであるWDDM(Microsoft Windows Vista Display Driver Model) 2.1では、より粒度の小さな完全にプリエンプティブ(先制)なコンテキストスイッチングを要求している。要は、CPU並のマルチタスクサポートをGPUハードに求めている。そのため、GPU側はコンテキストをスイッチする機能を強化する方向へと進んでいる。元AMDのOrton氏は、今春、GPUのマルチコンテキスト化の流れを次のように語った。
「WDDMは、アーキテクチャ的にはもともとコンテキストスイッチングのために計画された。しかし、2つの問題がある。1つは、シェーダプログラムは非常に長くなる可能性がある。そのため、Windowsのレベルでコンテキストを切り替えると、GPUはコンテキストをスイッチアウトしなければならない。これを解決するのが1つ目のステージで、2つ目のステージが、複数のコンテキストを同時(サイマルテニアス:Simultaneous)に走らせることができるようにすることだと考えている。
ここで出てくる疑問は、サイマルテニアスとは何を意味するのかという点だ(笑)。本当に、複数のコンテキストをプロセッシングするのか、それともGPU上での時分割を“ブーンブーンブーン”とより高速にするのか。
WDDM自体のアイデアは「(GPUに対して)マルチプルなコンテキストを走らせることができるように」と既定しているだけだ。だから、コンテキストスイッチを高速にすれば、結果的にエンドユーザーは、サイマルテニアスにコンテキストが走っているように感じられる。これが、簡単な解決策だ。
もっと難しいのは、本当にコンテキストを同時に走らせることだ。現実的には、CPUですら、ほとんどは複数コンテキストを同時に走らせることはできない。GPUでの実装としては、複数のコンテキストを、機能の上で分割されたGPU上で効率的に走らせることになるだろう。これは、より難しい問題となる」
ソフトウェア側がマルチコンテキストへと向かうにつれて、GPU側はコンテキストスイッチの粒度を小さく、スイッチングを高速にしなければならなくなる。その道の先にあるのは、パーティション化されたGPUの上で、複数のコンテキストを同時に走らせることだ。そして、Orton氏が指摘したように、その実装は難しい。
GPUのマルチダイ化は、そのための手段としても有効だ。機能上で2つに分割された2個のGPUダイが、それぞれ別コンテキストを走らせるように制御すればいいからだ。シングルダイのGPUより、最大で2倍の数のコンテキストを走らせることが可能になる。マルチコアCPUでのマルチスレッド化と同じ効果がマルチダイGPUでも得られるわけだ。
GPUベンダーは、CPUのSMT(Simultaneous Multithreading)と同じように、1個のGPUの中で複数のコンテキストを完全に同時に走らせるアーキテクチャを取ることもできる。しかし、そのハードルは高いため、まずは、マルチダイ化でコンテキストを走らせた方が容易となる。もちろん、ソフトウェア側がサイマルテニアスマルチコンテキストを求めるところまで成熟していることが条件になるが。
 |
| マルチコンテキスト化するGPU ※別ウィンドウで開きます PDF版はこちら |
 |
 |
 |
| コンテキスト切り替えはどれだけ活発か | コンテキスト切り替えの保証 | マルチGPU上のコンテキスト切り替え |
●NVIDIAはどう動くのか
こうして概観すると、AMDが向かっているマルチダイGPUには、ハードとソフトの両面で、合理的な背景があることがよくわかる。そのため、SLIでマルチGPUシステムを確立したNVIDIAがどう動くのかが、注目される。
NVIDIAのDavid B. Kirk(デビッド・B・カーク)氏(Chief Scientist)は、SLIの導入時に、マルチGPUがより汎用的になる可能性を示唆。GPUコンテキストのスイッチングをOS側でハンドルするWindows Vistaによって、マルチGPUシステムがより活かされることも語っていた。上記のマルチコンテキスト化は、SLI型のマルチGPUソリューションでも、もちろん有効となる。
また、NVIDIAのトップJen-Hsun Huang(ジェンセン・フアン)氏(Co-founder, President and CEO)も「“ヘテロジニアス(Heterogeneous:異種混合)SLI”」と言うキーワードを語っている。これも、マルチプルでヘテロジニアスなソフトウェア環境に向けた、GPUシステムのコンセプトだと考えられる。NVIDIAも、基本的な考え方は同じ方向を向いているが、デュアルダイといった実装形態を取るかどうかは、まだわからない。少なくとも、次のハイエンドであるG97(GeForce 9800系)は、シングルダイだと言われている。
□関連記事
【12月4日】【海外】R680でデュアルダイGPUへと向かうAMD
http://pc.watch.impress.co.jp/docs/2007/1204/kaigai404.htm
【7月9日】【海外】AMDが次期GPU「R700」を巨大にできない理由
http://pc.watch.impress.co.jp/docs/2007/0709/kaigai371.htm
【7月5日】【海外】AMDの次世代GPUは55nmプロセスがターゲット
http://pc.watch.impress.co.jp/docs/2007/0705/kaigai370.htm
(2007年12月5日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.