 |


■後藤弘茂のWeekly海外ニュース■AMDが次期GPU「R700」を巨大にできない理由 |
●GPUのダイサイズの中のミッシングパート
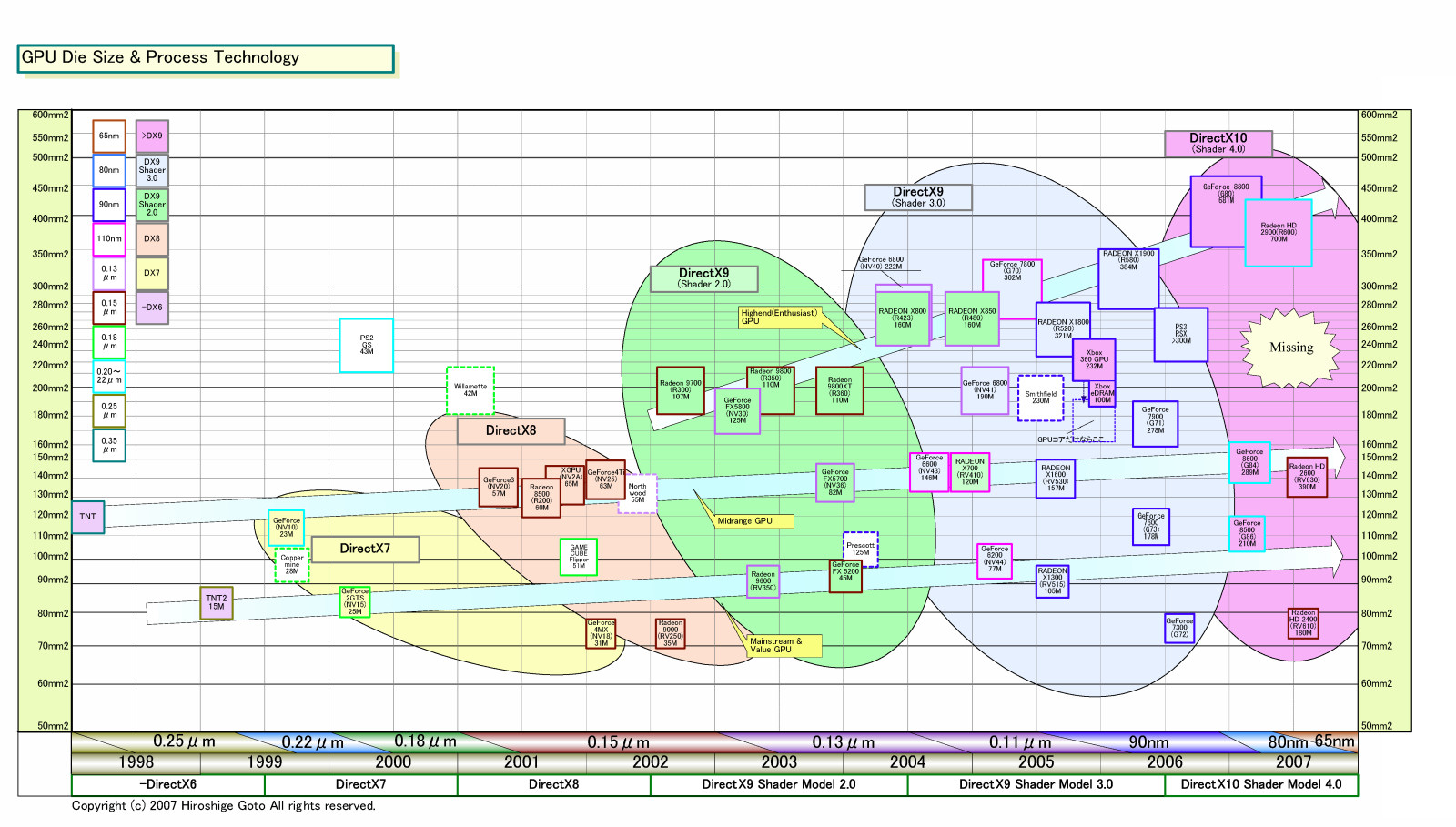
現在のGPUでは、ハイエンドGPUだけが異例に巨大化し、下位のバリューGPUやミッドレンジ&メインストリームGPUとダイサイズ(半導体本体の面積)の差が開いている。バリューGPUのダイは80~120平方mm程度で、ミッドレンジGPUは140~160平方mm程度。それに対してハイエンドGPUは、NVIDIAの「GeForce 8800(G80)」とAMDの「Radeon HD 2900(R600)」のどちらも400平方mm台。ハイエンドGPUチップは、その下のミッドレンジGPUの約3倍のダイサイズとなっている。そのため、ハイエンドとその下のミッドレンジGPUの間には、ぽっかりと空隙が空いてしまっている。AMDのGPU製品部門を率いるDavid(Dave) E. Orton(デイブ・オートン)氏(Executive Vice President, Visual and Media Businesses, AMD)は、次のように語る。
「現在の(GPU)製品のダイサイズを見ると、我々はハイエンドに新製品があり、下に2つの新製品がある。しかし、ハイエンドとミッドの間は(ダイサイズが開いてしまったため)ミッシングパートがある。我々は、ここ(の製品)が必要だ」
ギャップが開いた理由は簡単だ。バリューGPUとミッドレンジGPUのダイサイズは大きく変わっていないのに、ハイエンドGPUだけが巨大化を続けてきたからだ。ハイエンドGPUは、DirectX 7世代では100~120平方mmだったのが、DirectX 8世代で140平方mmクラスとなり、DirectX 9世代ではRADEON 9700(R300)で200平方mmを突破した。以来、RADEON X800(R420)が300平方mm弱、Radeon HD 2900(R600)で400平方mm台と一定のペースで肥大化を続けている。肥大化の理由はパフォーマンスで、ハイエンドGPUは、ダイを大型化することで、搭載できるトランジスタ数を増やしてパフォーマンスを引き上げてきた。
しかし、ハイエンドGPUの肥大化はついに止まりつつある。Orton氏は、ATI TechnologiesのCEOだった昨年(2006年)の6月に次のように述べていた。
「(ダイサイズの大型化は)フラットになるだろう。我々は、これ以上大きなチップを作ろうとは思わない。これまで(GPUは)14mm角(約200平方mm)、17mm角(約300平方mm)、20mm角(400平方mm)と大きくなってきた。しかし、25mm角(約600平方mm)は現実的ではないと思う。20mm角(400平方mm)が業界的には限界だろう」
このインタビューの時点では、旧ATIはすでにR600の設計をほぼ終えており、R600が20mm角(400平方mm)であることが、Orton氏の頭にあったと思われる。1年前の時点で、旧ATIはR600の400平方mm台が打ち止めになると決めていたわけだ。それはすなわちR700ではダイがこれ以上大きくならないことを意味している。それはまた、R700以降ではAMDがハイエンドGPUでマルチチップソリューションを取る可能性を示している。
 |
| GPUのダイサイズとプロセスの移行 PDF版はこちら |
●電圧降下が止まったためチップ消費電力が増大
Orton氏は、先月のインタビューでその理由について説明している。
 |
| David E. Orton氏 |
「ここ(ハイエンドGPU)に対しては、これ(ミッドレンジGPU)が2つになるかもしれない。なぜなら、電力面が高くなりすぎるからだ。消費電力は、基本的にキャパシタンス×電圧の二乗×周波数で導かれる。電圧は二乗で効果が大きく、我々はこれを下げ続けることで消費電力を抑えてきた。ところが、今では1Vちょっとで電圧の低下は止まってしまっている。
一方、周波数は継続して上がる。だから、電力を抑えることは、ダイをシュリンクすることでしか達成できない。キャパシタンスを減らすわけだ。そのため、20mm角の65nmと45nm(のチップ)というアイデアは、電力の面で歓迎されないだろう。」
現在のハイエンドグラフィックスカードの消費電力は200Wクラスに達している。これが限界に近いことは、だれもが気づいている。そのため、対策が必要だが、内部のロジック回路がフルに動くケースが多いGPUでは、消費電力の低減はかなり難しい。
プロセッサの消費電力のうちアクティブ成分は「キャパシタンス(Cdynamic)×電圧(Vdd)の2乗×動作周波数(F)」に比例する。このうち、周波数はパフォーマンスの面から下げることが難しい。現状では、GPUでも段階的に上がりつつある。そして、駆動電圧は、現在、プロセスが微細化してもほとんど下がらなくなってしまっている。
アクティブ電力を左右する3つの要素のうち、2つまでは、現状では微細化でも下げることができない。Orton氏が指摘するように、微細化によって下げることができるのはキャパシタンスだけだ。そして、キャパシタンスの減少だけでは十分ではない。
実は、Intelもこれと全く同じ指摘を'99年頃から行なっている。下は2004年秋のIntel Developer Forum(IDF)のテクニカルセッションでIntelが示したスライドだ。プロセス世代毎の電圧の低下が0.9倍に鈍化したことと、その影響を示している。現在は、さらに電圧低下は鈍化して、電圧はほぼ下がらなくなってしまっている。
 |
| プロセスと電圧の関係 |
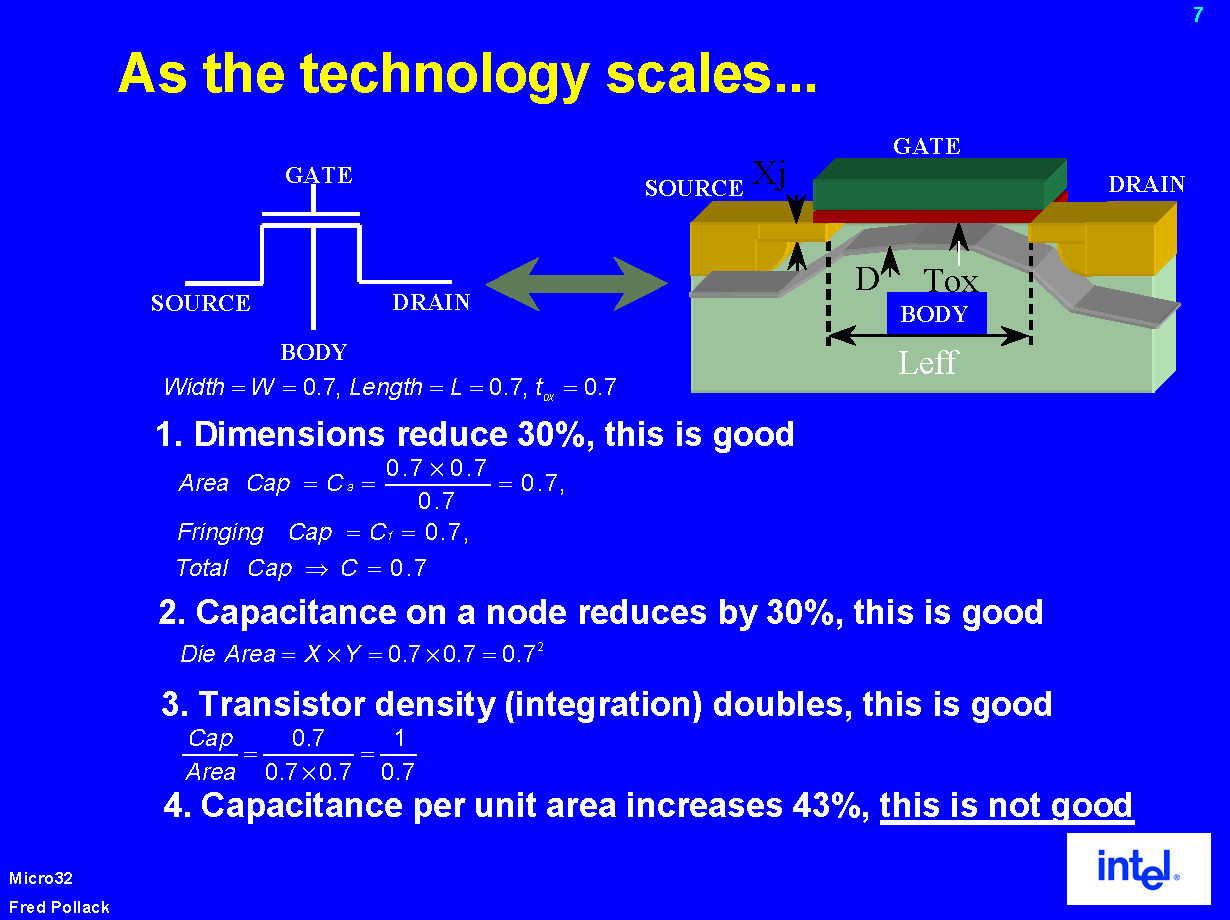
では、微細化しても電圧が下がらなくなったことで、どんな影響が出るのだろう。問題はチップ消費電力が増大してしまうことだ。消費電力面では、大きな問題があることを下のIntelのスライドが説明している。このスライドは、'99年当時、Intel Microprocessor Research Labs(MRL)のディレクタ兼Intel FellowだったFred Pollack(フレッド・ポラック)氏が、Micro32カンファレンスで講演した時のものだ。
 |
| プロセスと消費電力の関係 |
プロセスが1世代微細化すると、各トランジスタ毎のキャパシタンスは0.7倍に減る。しかし、1世代の微細化によって、トランジスタのサイズは0.7倍の二乗の0.5倍に縮小する。そのため、微細化すると同じダイ面積に約2倍のトランジスタが搭載できるようになる。
つまり、トランジスタ数は2倍になるのに、トランジスタ当たりのキャパシタンスは0.7倍にしか減らないわけだ。そのため、同じダイ面積当たりのキャパシタンスは、約1.4倍に増えてしまう。つまり、電圧と周波数が同じなら、1世代微細化すると、同じダイサイズのチップの消費電力は1.4倍に増えてしまうわけだ。
簡単に言えば、今までと同じサイズのチップを作り続けるなら、プロセス世代毎に消費電力は増え続ける。90nmから65nm、45nmへと移行すると、電力は1.4倍、2倍へと増えてしまう。Orton氏が指摘しているのはこの問題だ。
●半導体スケーリングで見た場合必然的なダイの縮小
そのため現状では、チップベンダーがチップ毎の消費電力を抑えようとしたら、Orton氏が言うように、チップのダイサイズを抑える方向へ向かわざるをえない。実際にCPUでは、コアのダイサイズが縮小している。
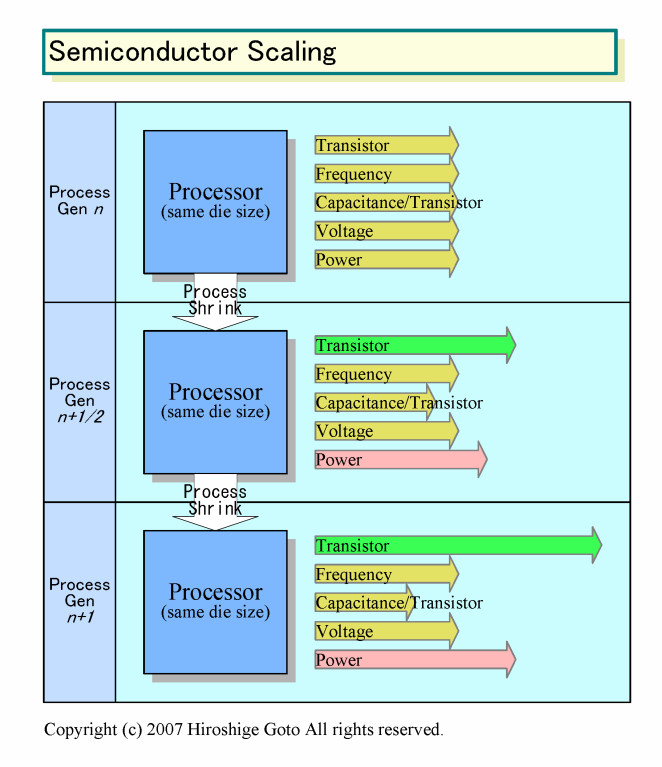
ダイを小さくしないと消費電力は増大してしまう。例えば、ハーフノードの80nmから65nmへと移行すると、計算上では、同じダイサイズに搭載できるトランジスタ数は約1.4倍に、キャパシタンスは約0.84倍になる。そのため、同じダイサイズのGPUの消費電力は、原理的には約1.2倍に増えてしまう。同様に、55nmでは80nmの約1.4倍に、45nmでは約1.7倍へと消費電力は増える。下の図で言うと、一番上が80nm、次が65nm、その下が55nmとなる。
 |
| 半導体のスケーリング PDF版はこちら |
これは、AMDが同じダイサイズでGPUを造り続けると、R600の消費電力に対して、R700の消費電力は1.2倍に、R800の消費電力は1.4倍に増えてしまうことを意味している。R800世代は、計算上は1個のGPU構成で300Wを突破してしまうことになる。このことは、400平方mmクラスのダイサイズのGPUを作り続けることが、非常に難しいことを意味している。Orton氏が、400平方mm(20mm角)の65nmや45nmプロセスのGPUは難しいと見ている理由はここにある。
Orton氏が指摘する問題は、物理学上の理論的な問題だ。問題が根源的なものであるため、解決が難しい。また、AMDだけでなく、NVIDIAも全く同じ問題を抱えている。そのため、今後のハイエンドGPUは、次世代か次々世代で、ダイサイズを減らす方向に向かう可能性が高い。ダイサイズを減らせば、ワンチップ当たりの消費電力を押さえることが可能になる。
ただし、ダイサイズを減らした場合には問題がある。それは、ハイエンドGPUではパフォーマンスを伸ばし続けることが要求されていることだ。プロセスの微細化にともなってダイを縮小すると、パフォーマンスを現在のペースで伸ばし続けることはできなくなってしまう。
例えば、R600からR700で、プロセス技術を80nmから65nmへと半世代進化させる場合。同じダイサイズでは、理論上のパフォーマンスは1.4倍となるが消費電力も1.2倍となってしまう。そこで同じ消費電力に抑えた場合には、ダイサイズは0.84倍の350平方mm程度になり、パフォーマンスは1.19倍程度にとどまる。これは、世代毎に1.4~2倍のパフォーマンス向上が期待されているハイエンドGPUでは受け容れられにくい。
問題は、現在のハイエンドGPUのパフォーマンスカーブが、一定消費電力下での半導体スケーリングを上回ってしまっていることになる。そのため、この問題を解決するには、抜本的な手段を取る必要がある。それが、ハイエンドGPUのマルチチップ化である可能性は高い。
●2チップ化することでよりよい電力制御を実現
しかし、個々のチップの消費電力を抑えたとしても、複数のチップでハイエンドビデオカードを構成したなら、カード全体の消費電力は結局のところ高くなってしまう。チップが分離されることで、冷却はしやすくはなるが、省電力化という点では、マルチGPU化の意味は薄いように見える。もしマルチGPU化するとしたら、どうやって消費電力を抑えるのだろう。Orton氏は、次のように示唆する。
「興味深いのは、どうやって2チップをゲーム以外でも一般的にすることができるのかという点だ。まず、コンピュータの電源を入れると、(2つのチップが)協調して動くようにする。しかし、通常に稼働している時は、単に(使われていないGPUが)アイドル(状態に)になるというのではないだろう。
電力管理の面から言うと、(CPUの)マルチコアのように、ローパワーモードでは(アイドル状態の)コアは走らせないで、もっとパフォーマンスが必要な時だけ、別な(サブのGPU)コアをONにする。コンセプト的には、これと似たような方法が考えられる。(GPUには)まだ実現すべきイノベーションが数多く残されている」
現在のマルチコアCPUは、個々のCPUコアの動作周波数と省電力ステイトを個別に制御。アイドル状態のCPUコアは、スリープ状態にすることで消費電力を抑えている。GPUもマルチチップ化することで、そうした個別の省電力制御が容易になる。例えば、Windows VistaのUIだけを走らせている時は1 GPUだけを走らせる。ゲームやストリームコンピューティングによって、GPU負荷が高まった時には2 GPUをONにするといったことが予想できる。こうしたコア単位の省電力制御は、マルチコアCPUのようにオンダイでも可能だが、チップ単位で分離した方がさらに容易になる。
●製造コスト面からも限界に近いハイエンドGPU
AMDは、製造コスト面からも、ハイエンドGPUのダイサイズを縮小したいと考えている。ハイエンドGPUの400平方mmというダイサイズは、サーバーCPUクラスで、経済性は極めて悪い。サーバーCPU同様に高コストなGPUを、コンシューマ向けグラフィックスカードでは、サーバーCPUの数分の1の価格で売っているからだ。こうした構造は、AMDのGPU事業の利益率も悪化させているはずだ。
AMDは、昨年(2006年)12月のアナリスト向けカンファレンス「Analyst Day」で、旧ATIのGPU事業の収益性が極めて悪いことを指摘。ダイサイズの縮小などで、収益を上げることを予告している。200平方mm台のGPUは、400平方mm台のGPUより格段に歩留まりが高くなり、1枚のウェハから採れる良品チップ数は2倍以上になる。そのため、製造コスト的には利点がある。
 |
| Analyst DayでのAMDの資料 |
GPUのマルチチップ化については、Orton氏は昨年からすでに可能性は示唆していた。
「グラフィックス(タスク)はパーティション化が可能であるため、もっとコスト効果を上げられる。2チップ(構成)と1チップの間で、よりよい方を選ぶことができるだろう。ただし、グラフィックスでは課題もある。それは、(両GPUに接続されたメモリ間での)メモリのデュプリケートは望ましくないということだ。アーキテクチャ的には、最適化しなければならない点がある。しかし、業界として見ると、価格パフォーマンスカーブを上げなければならない」
CPUでは、はるか以前から一般的であるマルチプロセッサ構成が、GPUではなぜ今も特殊なのか。それは、GPUのバスやメモリ回りのアーキテクチャが、マルチプロセッサ構成に適したものになっていないからだ。そのため、AMDやNVIDIAといったGPUベンダーが、現在のマルチボード向けアーキテクチャを超えて、本格的なマルチチップ構成に踏み出す時には、GPU間のインターコネクトをうまく設計する必要がある。オンボード接続を前提にするなら、GPU間をより高速に接続するバスを設計することは可能だ。
現状では、AMDがどんなアプローチでR700の設計を行なっているのかはわからない。しかし、AMDだけでなくNVIDIAも、ハイエンドGPUのダイサイズの肥大化にストップをかける時期にさしかかりつつあることは確かだ。また、ソフトウェア環境も、それを助ける方向へと向かっている。例えば、MicrosoftがOS側でGPUのコンテクストスイッチングをサポートすることは、マルチGPU化を容易にする。GPU上で、グラフィックス以外のタスクを行なう、ストリームプロセッシング化は、複数個のGPUでの柔軟な処理にフィットする。中期的に見ると、GPUアーキテクチャがマルチコア化に進むことは自然だ。
□関連記事
【7月5日】【海外】AMDの次世代GPUは55nmプロセスがターゲット
http://pc.watch.impress.co.jp/docs/2007/0705/kaigai370.htm
【2004年8月26日】【海外】GeForce 6600登場で見えてきたGPU業界のトレンド
http://pc.watch.impress.co.jp/docs/2004/0826/kaigai112.htm
(2007年7月9日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.