 |


■後藤弘茂のWeekly海外ニュース■Intelの次期CPU「Nehalem」の設計思想は“1 for 1” |
●Nehalem CPUコア自体の拡張はインクリメンタル
Intelが今年(2008年)第4四半期に投入するのが、次期CPUマイクロアーキテクチャ「Nehalem(ネハーレン)」だ。Intelは、4月2~3日に中国上海で開催した技術カンファレンス「Intel Developer Forum(IDF)」で、Nehalemのマイクロアーキテクチャの概要を明らかにした。そこで見えてきたのは、現在のCore Microarchitecture(Core MA)の電力効率を維持しながら、ハイエンドシステム向けにパフォーマンスの上限を高めたマイクロアーキテクチャだった。
Nehalemは、完全に新しいマイクロアーキテクチャというわけではない。現行のCore MAをベースに拡張している。それも、Core MAの骨格部分には、ほとんど手を付けずに継承している。言い換えれば、それだけCore MAの高い電力効率を大切にしている。Core MAのベースラインは改革せずに、マルチスレッディング技術SMT(Simultaneous Multithreading)を始めとした、パフォーマンスをアップするさまざまなテクニックを加え、新しいキャッシュ階層と、ノースブリッジ(MCH/GMCH)機能を統合したのがNehalemと言ってよさそうだ。
これは、AMDの「K7(Athlon系)」から「K8(Athlon 64系)」への進化と非常によく似ている。K7→K8の場合も、CPUコア自体は同じベースラインのマイクロアーキテクチャを改良。パフォーマンスは、マイクロアーキテクチャの改良にプラスして、メモリインターフェイスと高速I/Oの統合によって得た。同じことが、Core MAからNehalemへの進化でも行なわれる。
 |
| Core MAとNehalemの違い
PDF版はこちら |
下の右のチャートはIDFでの説明とインタビューを元にしたNehalemのブロック図だ。一部に推定が入っている。これを、左のNehalemの図に合わせて書き直したCore MAのブロック図(一部推定)と較べると、基本的な部分でNehalemがCore MAを継承していることがよくわかる。
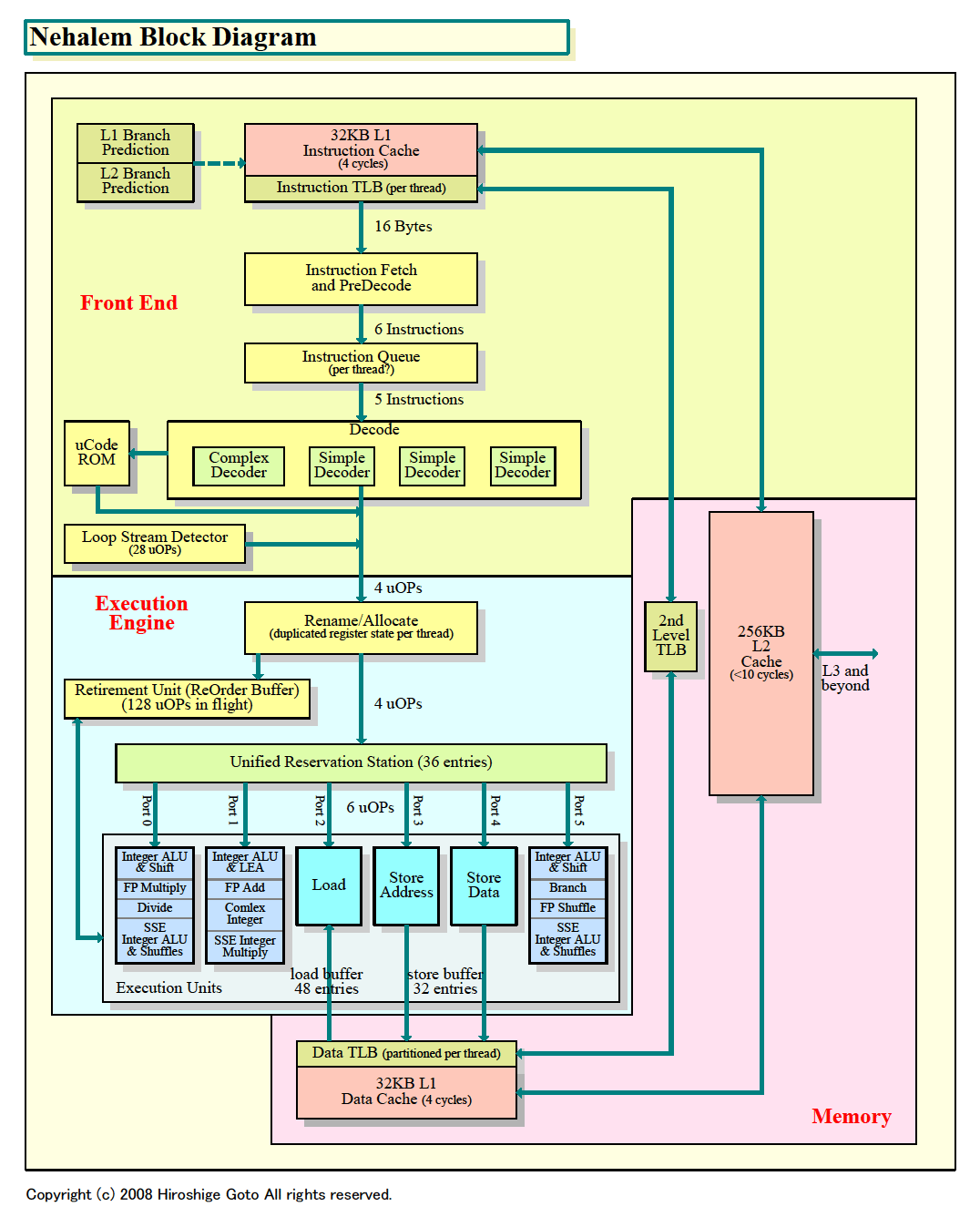 |
| Nehalem Architecture Block Diagram
PDF版はこちら |
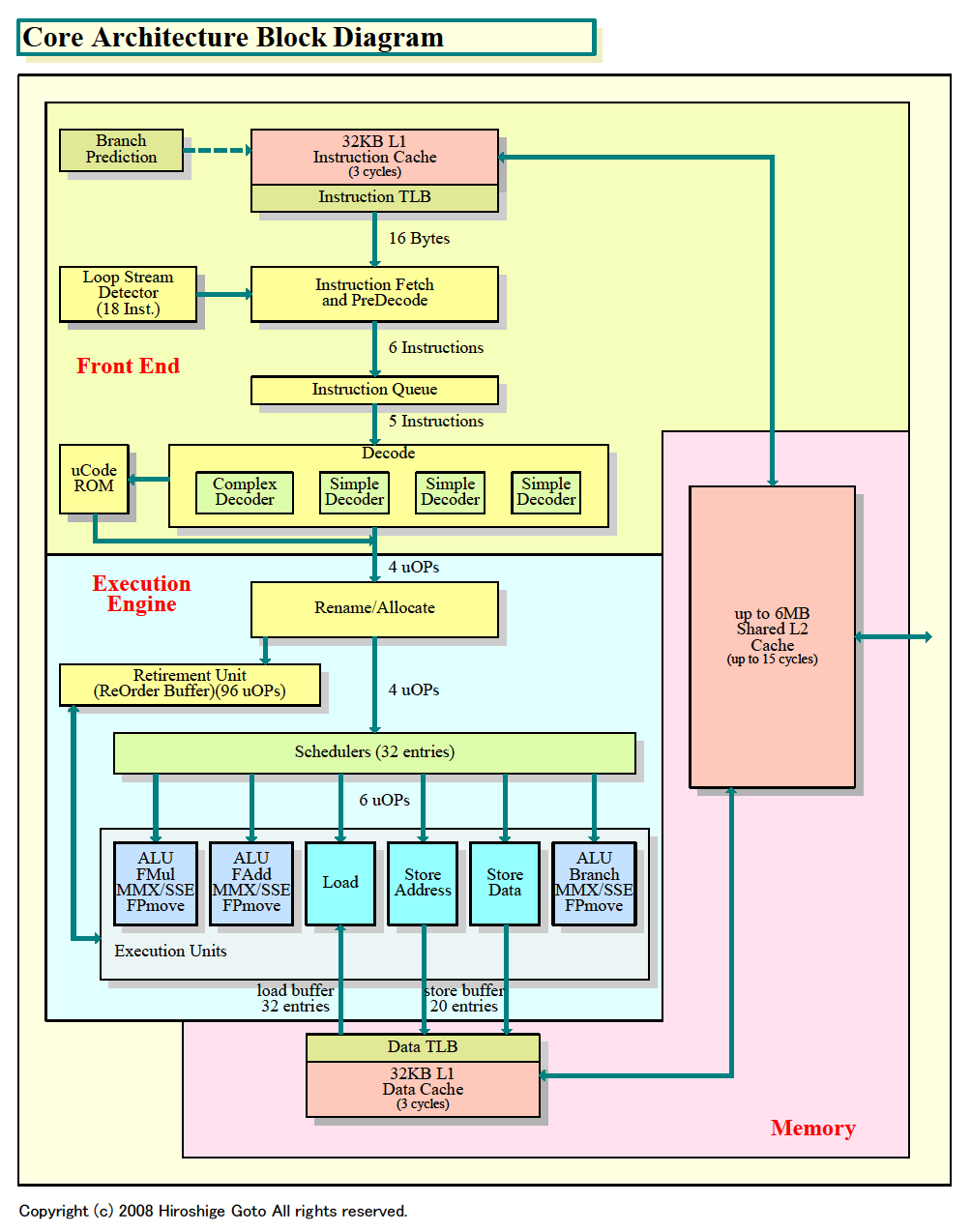 |
| Core Architecture Block Diagram
PDF版はこちら |
●1対1のフィロソフィで拡張されたNehalem
 |
| Jim Brayton氏 |
NehalemはCore MAからの進化系であるため、現在のCPUコアで最も重要となる、パフォーマンス/消費電力の高さは継承されている。Nehalemで加えられた拡張も、電力効率を悪化させないように、慎重に選択したという。Nehalemの開発ディレクタであるJim Brayton氏(Director, Enterprise Microprocessor Group and Design Manager, Nehalem Family CPU Development, Intel)は、次のように説明する。
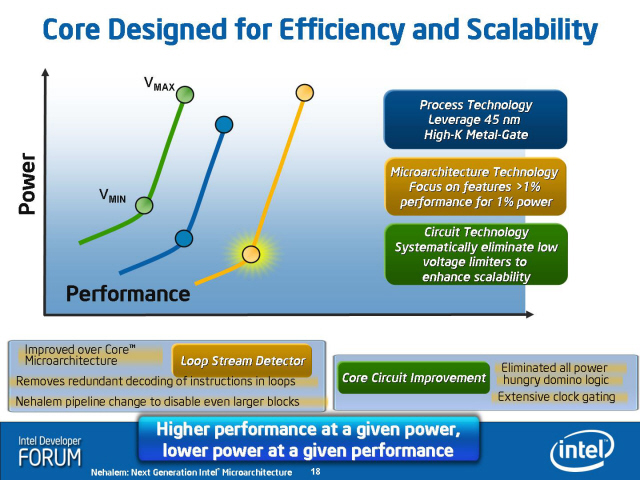
「Nehalem設計に当たって、我々は、自社のコンピュータアーキテクトから提案された数百のアイデアを調査した。我々がNehalemの設計に加えてもいいと考えたのは、その中でも最も効率的なものだけだ。
我々は、Silverthorne(Atomプロセッサ)では『1対1電力効率(1 for 1 power efficiency)』の原則でフィーチャを加えた。1%のパフォーマンスアップを1%の電力の枠内で実現するということだ。同じ効率をNehalemに組み込むフィーチャについても追求した。つまり、1%の電力と(トランジスタ)コスト毎に、少なくとも1%のパフォーマンスアップが得られる、目覚ましく電力効率のいいフィーチャだけをNehalemに選択した」
 |
| Patrick P. Gelsinger氏 |
Nehalem開発を担当したDigital Enterprise Groupを指揮するIntelのPatrick(Pat) P. Gelsinger(パット・P・ゲルシンガー)氏(Senior Vice President and General Manager, Digital Enterprise Group)も次のように要約する。
「我々がマイクロアーキテクチャに加えたものは、全て1%の(コスト)追加で、1%以上のパフォーマンスを実現できるものだけだ。マイクロアーキテクチャレベルでひとつひとつのトレードオフを検討した」
1対1以上の効率で拡張したとすれば、Nehalemは、Core MAに対して、パフォーマンス/消費電力の比率が少しでも悪くなるフィーチャは実装しなかったことになる。Intelは、NetBurst(Pentium 4)に対するPentium Mでは、パフォーマンス/消費電力の比率を1以上に上げることをテーマにしていた。しかし、電力効率の向上したCore MAに対して、Nehalemはその効率を維持することにフォーカスしている。
●ハイエンド寄りにチューンされたNehalem
この1対1の電力効率原則は、Nehalemの説明で、各レベルの担当者から度々引用されており、Nehalemの重要な設計指針となっていることが伺える。そのため、原理的には、NehalemでCore MAより電力効率が悪くなることはないはずだ。
ただし、Nehalemの拡張にはある指向性があり、そのため、Core MAとは性格が若干異なる部分もある。Nehalemの方が、よりサーバー&ハイエンドPC向けに最適化されている。マルチスレッド化が進んでいて、メモリ帯域への圧迫が大きく、プログラムサイズが大きく、メディアデータなどの処理やループが多いソフトウェア環境に向いている。また、マルチプロセッサでのスケーラビリティは、Nehalemの方がCore MAよりずっと高い。
そのため、Core MA→Nehalemで得られるパフォーマンスの向上は、ハイエンドデスクトップPCやサーバー&ワークステーションの方が、メインストリームから下のPCやノートPCよりずっと大きくなるだろう。つまり、1対1の効率で増やしたパフォーマンスが、ハイエンドシステムで活きる部分にやや寄っているように見える。これを対AMDの視点で見ると、パフォーマンスとスケーラビリティの利点があったAMDに一時浸食されたサーバー市場を取り戻し固めるという点で有利となる。
このあたりには、Nehalem開発を担当したのが、IntelのDigital Enterprise Groupであるという事情が関係していると推測される。モバイルにも適用できる電力効率を維持しているが、どちらかと言えば、ハイエンドデスクトップPCやサーバーでの利点が大きい。NehalemはそうしたCPUである可能性が高い。うがった見方をすれば、Core MAでIntel内部での地位を高めたIntel Mobility Groupに対しての、“Digital Enterprise Groupの逆襲”かもしれない。
特にパフォーマンス面で影響が大きいのは、Nehalemファミリの上位と下位で、実装に大きな違いがある点だ。上位のNehalemはCPUにオンダイ(On-Die)でノースブリッジ(MCH)機能を統合しており、そのために低レイテンシのメモリアクセスや広帯域メモリを実現できている。それに対して下位のGPUコア統合版のデュアルコアCPU「Havendale/Auburndale(ヘイブンデール/オーバーンデール)」は、現在判明している限りでは、パッケージ上でCPUコアとノースブリッジ(GMCH)コアをQuickPath Interconnect(QPI)で接続している。オンパッケージの接続なので広帯域のアクセスが可能だが、オンダイ統合と較べるとレイテンシや消費電力では不利となる。Nehalemのパフォーマンスアップのある程度の部分が、ノースブリッジ(MCH)の統合によるものだとすれば、下位のNehalemではその恩恵は薄れることになる。
 |
| HavendaleとAuburndaleのSystem Architecture
PDF版はこちら |
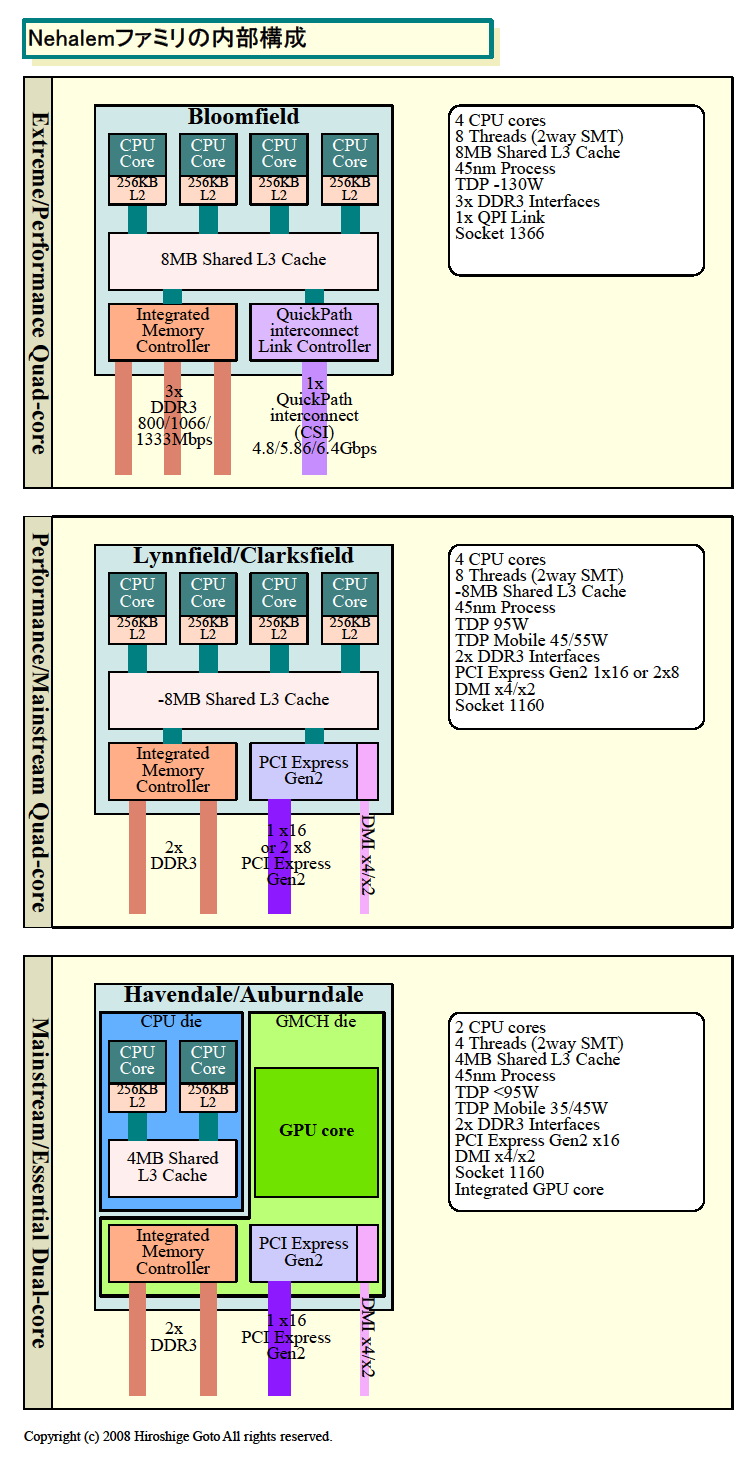 |
| Nehalemファミリの内部構成
PDF版はこちら |
とはいえ、Core MAの電力効率は維持されており、さらにNehalemでは回路設計などの改良によって、Core MAより低電圧化が可能になっている。そのため、IntelがNehalemをモバイルにも全面的に投入するという説明にも説得力がある。Intelのモバイル部門の責任者であるDavid(Dadi) Perlmutter氏(Executive Vice President, General Manager, Mobility Group)は、次のように語っている。
「Nehalemは現在と同じ熱設計枠を維持する。現在、上はクアッドコア版のCore 2 Duoが約90Wで、下はCore 2 Duoが10WでミニノートPCに入っている。同じようになるだろう」
Nehalemは10WレンジのULV(超低電圧)デュアルコアまでをカバーするようだ。
 |
 |
 |
| David Perlmutter氏 | Nehalem、フレキシビリティのためのモジュールデザイン | 効率性と拡張性のためのコアデザイン |
●命令フェッチからデコードまでの基本的な仕組みはCore MAと同じ
 |
| Ronak Singhal氏 |
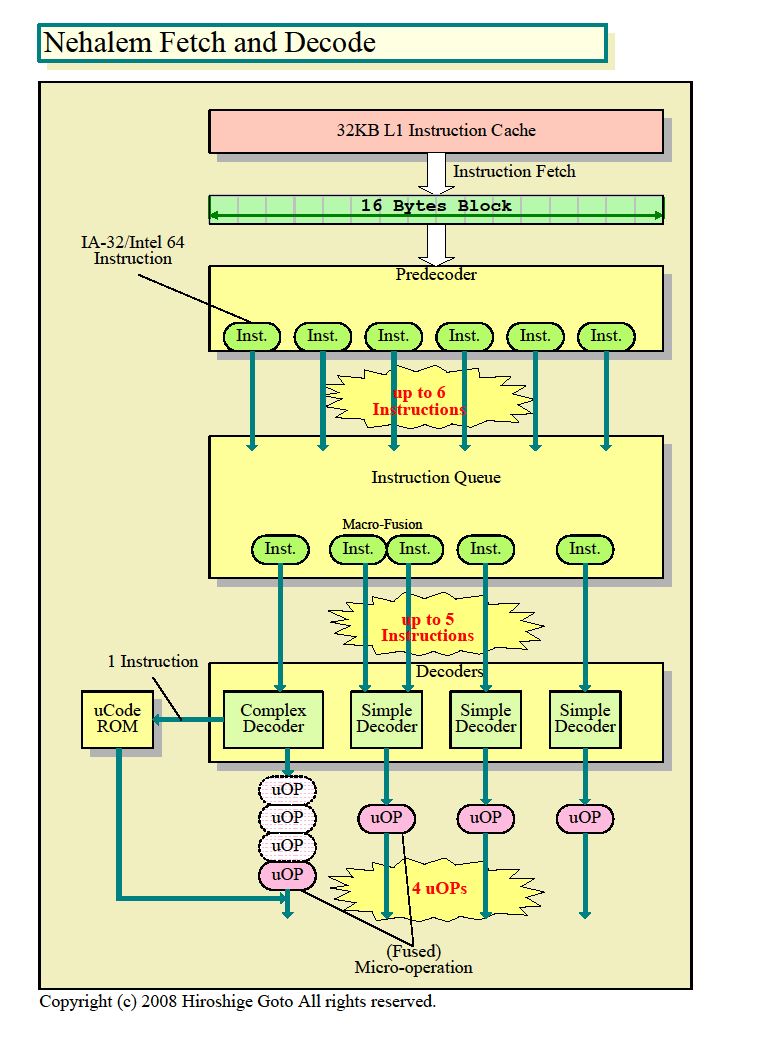
Nehalemマイクロアーキテクチャの骨格部分は、Core MAのストラクチャをほぼそのまま使っている。下は、パイプラインの先頭に位置する、命令フェッチから命令デコードまでの「フロントエンド」部分のチャートだ。Nehalemのリードアーキクトの1人であるRonak Singhal氏(Principal Engineer, Oregon CPU Architecture, Intel)に、命令フェッチ、プリデコード、デコードの各ステージの構造について、下の図を見せてそれぞれ確認をした。いずれの部分も図のように「Core MAと同様だ」(Singhal氏)という。
フロントエンドについては、さまざまなパフォーマンス拡張テクニックは加えられたものの、基本的なストラクチャはCore MAのままであることがわかる。Core MAは、フロントエンドにいくつかの弱点を抱えているが、Nehalemもその多くを継承する。弱点を含めて、Core MAのフロントエンドをほぼ踏襲した設計となっている。この点が重要なのは、x86系CPUでは、フロントエンドの設計がカギとなるからだ。
 |
| Nehalemのフェッチとデコードの流れ
PDF版はこちら |
x86命令の実行で、最もやっかいなのは命令デコーダ回りだと言われる。RISCやIA-64の場合は、命令長が固定または少ない種類に定まっており、命令フォーマットも一定だ。そのため、命令デコードのロジックは簡単で済む。しかし、x86系命令の場合は、命令長はバリエーションが多く、さらにオペコードの前にプリフィックスがつく場合があるため、命令フォーマットも複雑だ。
x86 CPUメーカーのCentaur Technologyを率いるGlenn Henry(グレン・ヘンリー)氏(President and Founder)は「おかしなプリフィックス(Funny Prefixs)がx86命令のデコードを非常に難しいものにしている」と語る。そのため、x86アーキテクチャでは、命令デコードは極めて複雑で、手間のかかる処理となっている。
パイプライン全体を見ると、x86系CPUの場合は、命令実行のレベルで命令並列性を増すことは、相対的に簡単だ。より多くの実行ユニットを並列化し、スケジューリングできる命令ウインドウを広げ、リネームレジスタやバッファを深くすれば、ある程度までは並列性を増やすことができる。ところが、スケジューラに送り込む命令を切り出してデコードする段階で、並列性を増やすことは、x86命令の場合は難しいという。
そのため、x86 CPUにとって、命令キャッシュからx86系命令を効率よく切り出して、内部命令(uOPs)に効率よく変換することが、パフォーマンス向上にとって重要な課題となっている。特に、CPU内部の実行パイプラインの並列度を高めようとすると、フロントエンドがボトルネックとなりやすい。最大4命令並列と内部並列度が高いCore MA/Nehalemでは、この問題は特に大きい。AMDのCTOからの辞職が伝えられたPhil Hester(フィル・へスター)氏も「4命令を実行するより、4命令をデコードする方が難しいだろう」と語っていた。
●フロントエンドの抜本的な拡張は行なわなかったNehalem
こうした背景があるため、Nehalemマイクロアーキテクチャでは、フロントエンドがどのように拡張されているのかが、1つのポイントとなっていた。昨年(2007年)秋、フロントエンドの改良はどの時点で行なうのかとIntelのShmuel(Mooly) Eden(ムーリー・エデン)氏(Vice President, General Manager, Mobile Platforms Group, Intel)に質問した時には次のように答えていた。
「Penrynでの改良は素晴らしいが、それは、あくまでも限定された“美容整形手術”のようなものだ。“心臓手術”のように、全てを再アーキテクチャ化する大きなものではない。大きな変更はNehalemで行なわれる」
しかし結論から言えば、Nehalemの命令デコーダ回りは、64bitsモードでMacro-Fusionが働くようになった以外は、本質的にはほとんど改良されなかった。正確に言えば、問題の本質的な部分には手を付けずに、問題を回避するテクニック(uOPsベースのループストリームディテクタ)や、それ以外の部分でパフォーマンスを引き上げるテクニックが盛り込まれただけだった。
Intelは、x86系CPUの命令フェッチャー&プリデコーダ&デコーダを抜本的に改良しようとすると、膨大なロジック(=トランジスタ)が必要となるからだという。つまり、1対1の電力効率の原則に照らし合わせると、フロントエンドの抜本的な拡張は割に合わないものだったという。x86 CPUのフロントエンドの弱点が、x86系命令セット自体の複雑性に起因することを考えると、これは非常に重要だ。電力効率を高めようとすると、フロントエンドでより多くの命令をフェッチ&デコードすることが難しいことを意味しているからだ。
こうして見ると、Nehalemはパフォーマンスを引き上げたが、x86命令実行の根本的な困難も浮き彫りにしたことがわかる。x86命令を実行すること自体が、電力効率を上げにくい原因になっている。そして、x86命令のフェッチ&デコード部分には手を付けにくい。Nehalemのように、トランジスタ予算があっても、見送らなければならないほどやっかいだということだ。Intelは、x86のソフトウェア資産に頼る以上、今後、このチャレンジに直面し続けなければならない。
論理的には、この問題の最終的な解決手段は、“できるだけフェッチ&デコードしない”こととなりそうだ。つまり、uOPsに変換した後でのバッファリングを充実させて、uOPsのリユースを高めることだ。実際、Nehalemのループストリームディテクタは、この方針でuOPsをバッファする。また、NetBurst(Pentium 4)マイクロアーキテクチャでは、膨大なトレースキャッシュでuOPsをキャッシュしていた。Core MAを開発したIntelイスラエルに所属する研究者が数年前に発表した「Power AwaReness thRough selective dynamically Optimized Traces(PARROT)」アーキテクチャの論文も、uOPsレベルでの最適化と再利用を行なうというアイデアだった。
こうしたアイデアを突き詰めてゆくと、コードの局所性が高ければ高いほどパフォーマンスが上がるようになる。ループの多い、例えば、マルチメディア処理のようなケースで、より性能が上がるだろう。この問題は、CPUの進化やパフォーマンスの向上の方向も規定して行くことになりそうだ。
 |
| キャッシュ階層の変化
PDF版はこちら |
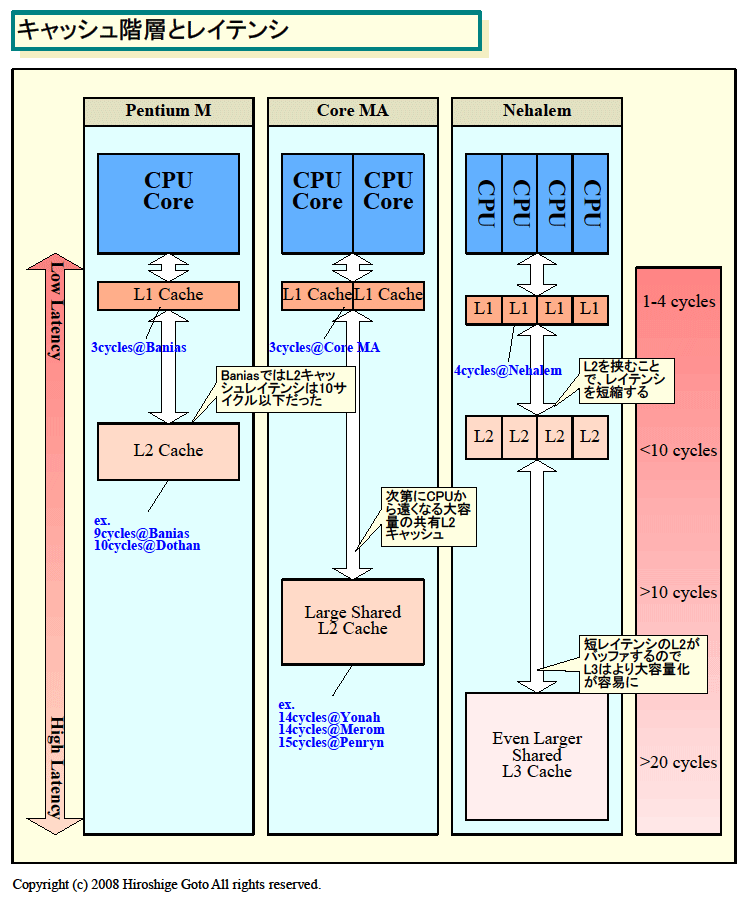 |
| キャッシュ階層とレイテンシ
PDF版はこちら |
□関連記事
【4月10日】【海外】なぜIntelはSandy Bridgeに「AVX」を実装するのか
http://pc.watch.impress.co.jp/docs/2008/0410/kaigai435.htm
【4月7日】【海外】x86からの脱却を図るIntelの新ロードマップ
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
【3月21日】【海外】モバイルにもL3キャッシュをもたらすNehalem
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
【1月29日】【海外】2つのCPU開発チームに競わせるIntelの社内戦略
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
(2008年4月24日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.