 |


■後藤弘茂のWeekly海外ニュース■なぜIntelはSandy Bridgeに「AVX」を実装するのか |
●シングルコア性能を伸ばすための命令セット改革
Intelは、マルチコア性能だけでなく、シングルCPUコアのパフォーマンスを今後も伸ばす。ただし、従来とは違う方法で。CPUの整数演算と浮動小数点演算の性能のバランスを取って、新しく最適化されたソフトウェアだけでなく、既存のソフトウェアの性能を上げるのが、2002年までのアプローチ。それに対して、2010年以降の方向は、SIMD(Single Instruction, Multiple Data)型の浮動小数点演算の性能にフォーカスし、命令セットを大きく拡張する。また、2005年以降から進展してきたマルチコア化も継続する。
そのため、ソフトウェアはマルチスレッド化だけでなく、新命令セットにも積極的に対応して行かないと、CPUのフルパフォーマンスが発揮できなくなる。つまり、よりソフトウェアやコンパイラへとしわ寄せが行くようになる。逆を言えば、Intelは、ますますツールやコンパイラやプログラミング教育に力を入れて行かなければならない。
下のIntelのIA-32(x86)命令セット拡張の歴史チャートを見ると、下に行くに従って間隔が詰まっていることがわかる。Intelの命令拡張のペースが速まり、拡張の方向も広がっているからだ。
これは偶然ではない。Intelは、先週4月2日、3日に中国上海で開催した「Intel Developer Forum(IDF)」で、CPUアーキテクチャの方向性と命令拡張のロードマップの関連を明瞭に示した。2010年以降のCPUの性能の向上は、命令セットの拡張にかなり依存して行くという。下がその説明スライドで、現在は動作周波数の向上とマイクロアーキテクチャの改良で年に15%ずつCPUコアの性能をアップしているが、2010年から先は命令セットの拡張でパフォーマンスをアップするとなっている。2010年にまず「Intel Advanced Vector Extensions (Intel AVX)」が「Sandy Bridge(サンディブリッジ)」に実装され、その先のCPUでは「Fused Multiply Add(FMA)」が実装される。
 |
| 2010年以降のCPUの性能の向上は命令セットの拡張に依存する |
 |
| Intel AVXの特徴 |
 |
| 浮動小数点演算の幅を2倍に拡張 |
Intelのこの説明は、現状より前の、'90年代の古いトレンドまで振り返らないと理解できない。Intelが、こうした方向に転じる最大のモチベーションは、2003年より前のCPUコアパフォーマンスの向上カーブに戻ることにあるからだ。
●2002年の終わりに急にストップしたシングルコア性能の向上
CPU業界は'86年から2002年までの間、およそ年に52%ずつシングルCPUコアのパフォーマンスをアップさせて来た。下は「Computer Architecture : A Quantitative Approach, 4th edition」の共著者で、CPU研究者として有名なDavid A. Patterson(デヴィッド・A・パターソン)教授(University of California at Berkeley)が、2006年8月のCPUカンファレンス「HotChips 18」で示したプレゼンテーションだ。
 |
| Uniprocessorのパフォーマンス向上 |
CPUベンダーは16年間に渡り、競ってCPU性能を向上させ続け、Intel CPUもその流れにほぼ沿っていた。このチャートに示されているのは、シングルプロセッサの整数演算(SPECint)の性能で、主にCPUマイクロアーキテクチャ拡張と動作周波数の向上で実現されていた。
また、メインストリームのCPUでは、さらにベクタ型の1つであるSIMD演算の命令セットを追加した。IntelではこれはMMXと各世代のSSEで、この命令拡張で、ベクタ型の特に浮動小数点演算の性能も向上を図って来た。
この動きが止まるのが2002年から2003年にかけて。Intelを例に取ると、2002年の終わりまでは順調にNorthwoodの周波数を向上させていたが、2003年には周波数の向上が鈍化し、ついには止まってしまった。加えて、マイクロアーキテクチャを大きく拡張してシングルスレッド性能を引き上げるはずだった「Tejas(テハス)」はキャンセルになった。そのため、グラフのように2002年から2003年を境に、シングルコアパフォーマンスの向上は唐突に緩やかになってしまった。
Patterson氏によると、障壁となっている要素は3つ。命令レベルの並列性であるILP(Instruction-Level Parallelism)の限界「ILPウォール(ILP Wall)」、消費電力の壁「パワーウォール(Power Wall)」、メモリアクセスの壁「メモリウォール(Memory Wall)」だ。つまり、ILPを上げるためにハードウェアを追加しても、以前ほどのILPの向上は得られない。そのため、ILPを向上させようとすると、電力消費が増えて、パフォーマンス/消費電力が悪化してしまう。ところが、電力はすでにPC&サーバーに搭載できる限界に近いところまで上がってしまっている。また、CPUコアを高速にしても、メモリアクセスのレイテンシが減らないので、メモリが足を引っ張って性能が理論値にまで上がらない。
このように、原理的にシングルCPUコアのパフォーマンスは上げにくくなってしまった。この状況で、CPUベンダーは挙ってマルチコア化へと走った。CPUコアをプロセス世代毎に太らせて行っても、2003年以降のペースでは5年で2倍までしか性能が向上しない。ところが、マルチコア化すると、2年で2倍のペースで理論上のパフォーマンスを向上させることができるからだ。これが、過去数年でPC業界が体験したマルチコアターンだ。
とはいえ、PCとサーバーの一部では、依然としてシングルコア性能も重要だ。そこで、x86 CPUベンダーは、シングルCPUコアの性能を向上させるために苦闘することになった。
 |
| コンピュータのアーキテクチャにおける新旧常識 |
 |
| デジャヴュ再び? |
●CPUコア性能の向上がわずか15%/年に鈍化した現状
Intelは、高周波数に最適化したNetBurst(Pentium 4)マイクロアーキテクチャから、中程度の周波数に合わせたCore Microarchitecture(Core MA)に切り替えて、パフォーマンス/消費電力を向上させた。そのために、NetBurstの発展系のTejasをキャンセルし、Nehalemをいったん白紙に戻して再設計することにした。NetBurstでは、5GHzをターゲットに設計したCPUを、70%の周波数で動作させていたため、効率が悪く、一定のTDP(Thermal Design Power:熱設計消費電力)では性能が出なかった。それに対して、低いTDPと低い周波数に合わせたCore MAでは、一定のTDPの中で最高の性能を引き出すことができた。
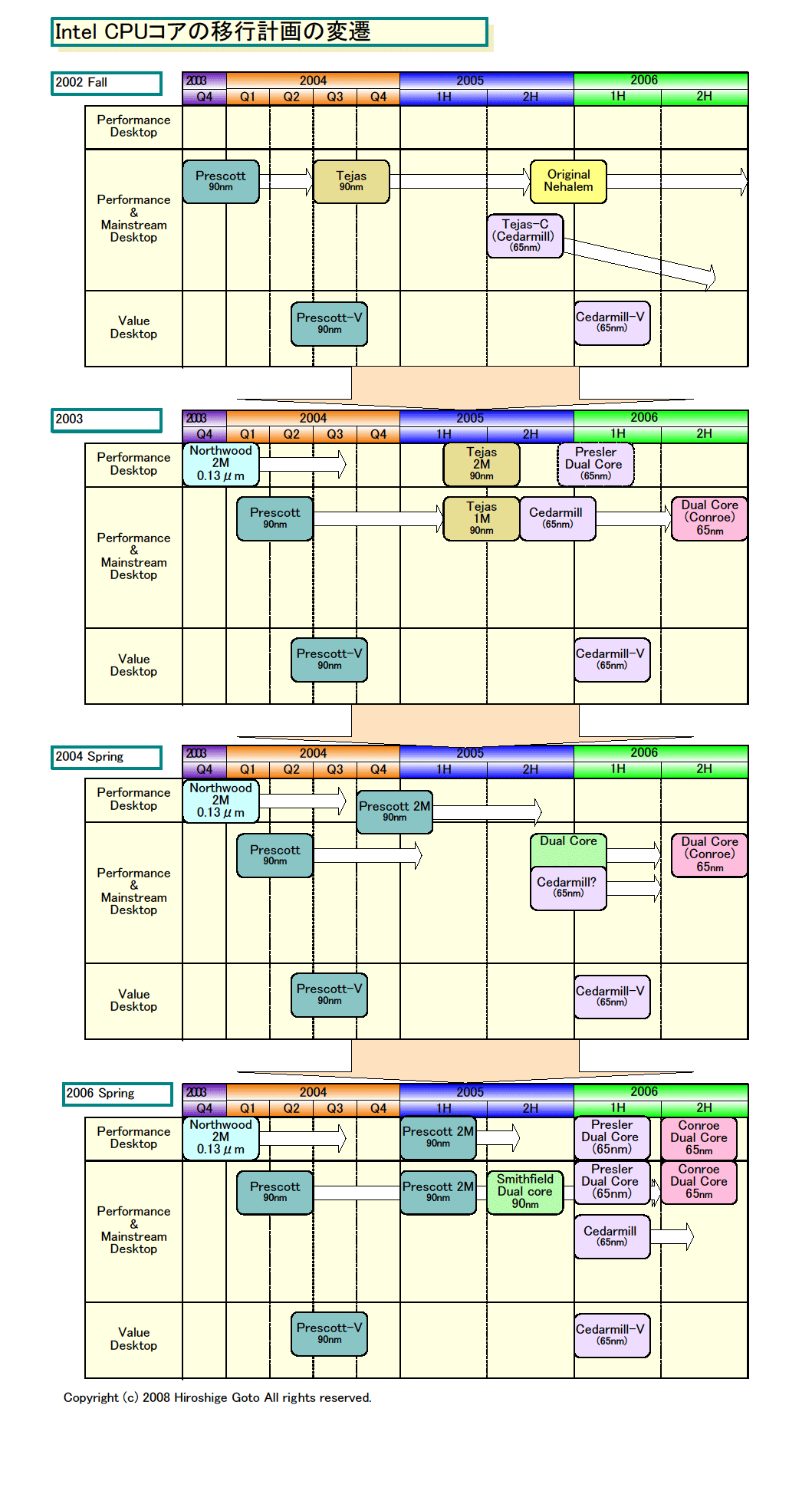 |
| CPU移行計画の変遷
PDF版はこちら |
次のNehalemでは、Core MAをベースにチューンに加え、さらにシステムアーキテクチャを変更して、メモリレイテンシを短縮、メモリ帯域を倍増させる。これによって、全体のパフォーマンスがアップするものと推測される。
それでも、シングルコアの性能向上の幅は、それほど大きくない。IDFでの説明では、現状ではCPUコアの性能は、年に15%ずつの向上程度だという。ここで言う性能の基準は明らかではないが、この数字は納得できる。Patterson氏とJohn Hennesy(ジョン・ヘネシー)氏(現スタンフォード大学プレジデント)が共著したComputer Architecture 4th editionでは、2003以降のペースを20%と見積もっていたからだ。Intelの15%/年よりちょっと多いが、いずれにせよ、従来の52%にはほど遠い。
もちろんIntelは、毎世代のCPU発表の際に、マーケティングメッセージとして「○○の性能が2倍」といった形で性能向上を謳う。しかし、オーバオールのユニプロセッサ性能の向上は鈍化しており、IDFの技術セッションでは、それを明瞭に認めていた。それが、現在のCPUの性能向上の真実だ。
ちなみに、AMDはこの崖っぷちにいち早く気づき、K8コアでは高周波数追求には向かわず、システムアーキテクチャを変え、マルチコア化も見据えと、全てIntelより早めに対策を取った。Intelは、アーキテクチャ的にはNehalemまでは遅れを取った形となっている。
●2つに割れたCPUアーキテクチャの方向性
こうして見ると、'80年代半ばからの順調なシングルCPUコアパフォーマンス向上が、2002年に崩れたことがよくわかる。2003年からこれまでのトレンドは、CPUコアのパフォーマンス向上が鈍化した現実を前に、どうCPUを設計するか、試行錯誤の時だった。そして、その霧が晴れるのは、2010年あたりとなる。
2010年のCPUアーキテクチャが見通せるようになった現在、CPU業界の方向が2つに分かれたことが明瞭になった。
1つは、シングルCPUコアの性能向上は、基本的に諦める方向。むしろ、個々のCPUコアをシンプルに小さくして、マルチコアでCPUコア数を増やして、マルチスレッド性能を追求する。この方向は、すでにスタートしている。Sun Microsystemsが、このアプローチの旗手で、Cell Broadband Engine(Cell B.E.)も同じ方向にある。このアプローチでは、シングルスレッドの性能向上すら、疑似投機スレッド実行で引き上げる。
もう1つは、マルチコア化を継続するが、CPUコア自体のパフォーマンスアップも継続する方向。CPUコアの中で性能を伸ばす余地がある部分、つまり、ベクタ型の浮動小数点演算を徹底的に伸ばそうというアプローチだ。ILPが行き詰まっているのは整数演算であり、浮動小数点演算でSIMDによってデータレベルの並列性(DLP:Data-Level Parallelism)を上げることは、まだ余地がある。これがIntelやAMDが、これから取ろうとしている方法だ。
ただし、そのためには、命令セットを大きく拡張する必要がある。だからIntelは「Intel Advanced Vector Extensions (Intel AVX)」と「Fused Multiply Add(FMA)」、AMDはSSE5という方向へと向かっている。AVX/FMAを例に取ると、SSEから、オペランドモデルを変える、積和算を実装する、ベクタ(SIMD)長を伸ばすといった方向だ。簡単に言えば、RISC風のモダンな命令に切り替える。
●ソフトウェア側の対応が必須となる2010年以降のパフォーマンス
これをソフトウェア側から見ると、また違ったビューとなる。2002年までは、ソフトウェア側は、メジャーな変更をしないままでも、CPU世代が変わると性能がそれなりに向上していた。この「フリーランチ」状態は、2002年を境に終わり、CPUのシングルスレッド性能は、ゆっくりとしか上がらなくなってしまった。ソフトウェアは、マルチコアに対応してマルチスレッド化するか、あるいはマルチタスク、マルチ仮想マシンの環境でしか、CPUの性能をフルに活かすことができなくなった。
2010年から先は、Intelの説明を信じると、2003年から2009年の5-6年間よりハイペースでCPUコアのパフォーマンスが上がることになる。しかし、性能の向上は、SIMD型の浮動小数点演算に集中する。また、マルチコア化も促進するため、マルチスレッド化も依然として必要となる。IntelのBob Valentine(ボブ・バレンタイン)氏(CPU Architect, Mobility Group)はソフトウェアの対応の必要性を次のように説明する。
「2つの方向があると考えている。1つのポイントは、ベクタ拡張への対応だ。ベクタ拡張に合わせて、(CPUが実行する)コードの一定の量をベクタライズして行く必要がある。今日、50%のコードがベクタライズされているとしたら、残りの50%もベクタライズしたい。次の10%をベクタライズする場合の壁となっているのは、ローテイトかもしれない。我々は、まだその答えを得ていないが、そうやって(ソフトウェアの)ベクタ対応を進めて行く必要がある。
もう1つのポイントは、ベクタ拡張とともに、我々がより多くのCPUコアを加えて行くことだ。そのため、ソフトウェアをマルチスレッドにする必要は継続している」
こうしてみると、CPUアーキテクト側は、コードのベクタライズ(この場合はSIMD化)が進むものと考えていることがよくわかる。
 |
| AVXにおけるソフトウェア開発 |
 |
| 多くの新しい基本命令がFP Vectorizationをシンプルにする(1) |
 |
| 多くの新しい基本命令がFP Vectorizationをシンプルにする(2) |
 |
| FMAについて |
 |
| Nehalemのブロックダイアグラム
PDF版はこちら |
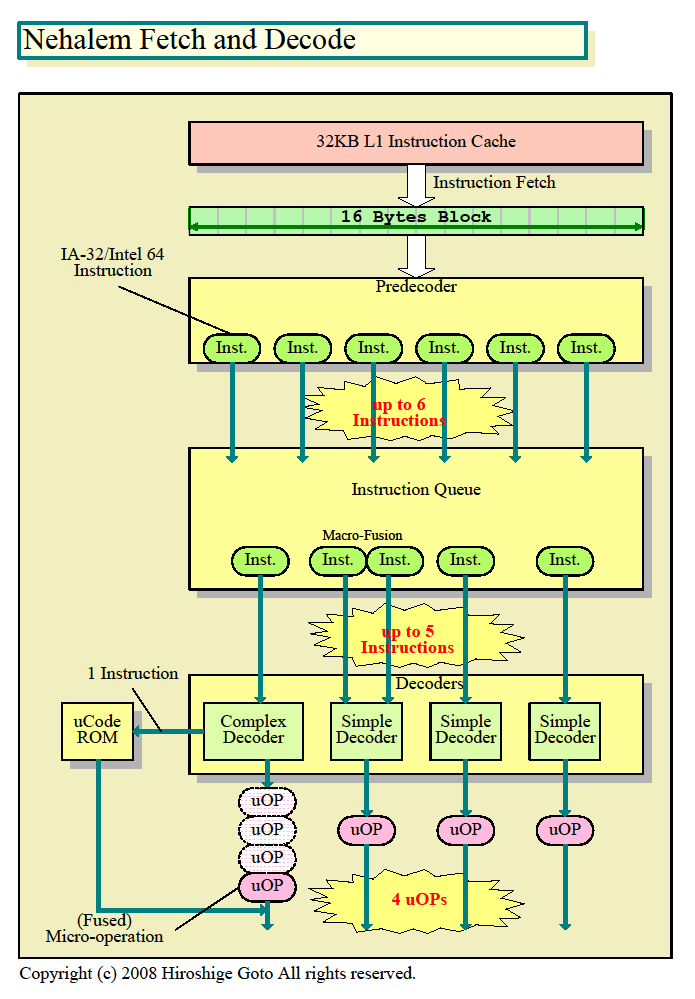 |
| Nehalemのフェッチとデコード
PDF版はこちら |
□関連記事
【4月7日】【海外】x86からの脱却を図るIntelの新ロードマップ
http://pc.watch.impress.co.jp/docs/2008/0407/kaigai434.htm
【3月21日】【海外】モバイルにもL3キャッシュをもたらすNehalem
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
【1月29日】【海外】2つのCPU開発チームに競わせるIntelの社内戦略
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
【2007年12月11日】【海外】イスラエルから発信されるIntelの次世代CPUテクノロジー
http://pc.watch.impress.co.jp/docs/2007/1211/kaigai406.htm
(2008年4月10日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.