 |


■後藤弘茂のWeekly海外ニュース■モバイルにもL3キャッシュをもたらすNehalem |
●デスクトップやモバイルにも最適化した3レベルキャッシュ階層
Intelは4月頭に上海で開催する「Intel Developer Forum(IDF)」を前に、IDFのプレビューを発表した。その中で、Intelは今年(2008年)後半に登場する次期CPUマイクロアーキテクチャ「Nehalem(ネハーレン)」のより突っ込んだ概要や、その次に当たる「Sandy Bridge(サンディブリッジ)」、データ並列型のメニイコアCPU「Larrabee(ララビー)」などの情報もアップデートした。より詳細な情報はIDFで明らかにされる。
今回のプレビューでは、Intelが“マルチレベルの共有キャッシュ”と呼んでいた、Nehalemのキャッシュ階層についての詳細がさらに明らかになった。
Nehalemでは、L1、L2、L3の3階層のキャッシュ構成を取る。クアッドコア版のNehalemでは、各CPUコア毎に32KBのL1命令キャッシュとL1データキャッシュ、それに256KBのL2キャッシュを備える。さらに3層目として4コアで共有する8MBのL3キャッシュを備える構成となっている。共有されるのは、最下層のL3だけだ。
 |
| Nehalemは3階層のキャッシュを採用する |
Intelは、従来からサーバーCPUでは大容量のL3キャッシュを搭載してきた。例えば、今年(2008年)投入する6コアのMP(Multi-Processor)向けCPU「Dunnington(ダニングトン)」は、各CPUコア毎に32KBのL1命令キャッシュとL1データキャッシュを備え、2個のCPUコア毎に共有する3MBのL2キャッシュ、さらに6コアで共有する16MBのL3キャッシュを備える。Intelに限らず、サーバーCPUではL3までのキャッシュ階層を備えることは珍しくない。しかし、Nehalemの3層キャッシュアーキテクチャは、従来のサーバーCPUの3層キャッシュとは性格が異なるという。
「Nehalemで我々は3レベルのキャッシュ階層に移行する。現行のCore 2は2レベルキャッシュ階層だ。(Core 2系でも)Dunningtonは3レベルの階層だが、Nehalemが異なるのは、サーバーだけでなく、デスクトップとモバイルにももたらされる点だ」
従来のIntel CPUは、モバイルとデスクトップ、ボリュームサーバーは2レベルのキャッシュで、ハイエンドのMPサーバーだけが3レベルのキャッシュ階層だった。CPU設計は、デスクトップやモバイル向けに、比較的大容量のL2キャッシュを備える設計を取り、MPサーバーではその設計に単純により大容量のL3キャッシュを加えていた。
それに対して、Nehalemは当初から全製品ファミリを3階層キャッシュを前提に設計していたようだ。CPUの構成に応じて、3レベルのキャッシュの構成をスケーラブルに変える。
「全体的に、新しい3レベルキャッシュとなる。キャッシュサイズは、コア数などに依存する。2008年中の製品はクアッドコアで8MBのL3キャッシュを備える。デュアルコアはより小さいキャッシュとなる」
デュアルコア版Nehalemでは4MBのキャッシュとOEMには説明されており、これがL3であると推定される。それに対して、オクタ(8)コアのMP版Nehalemでは24MBの共有L3キャッシュを備える。
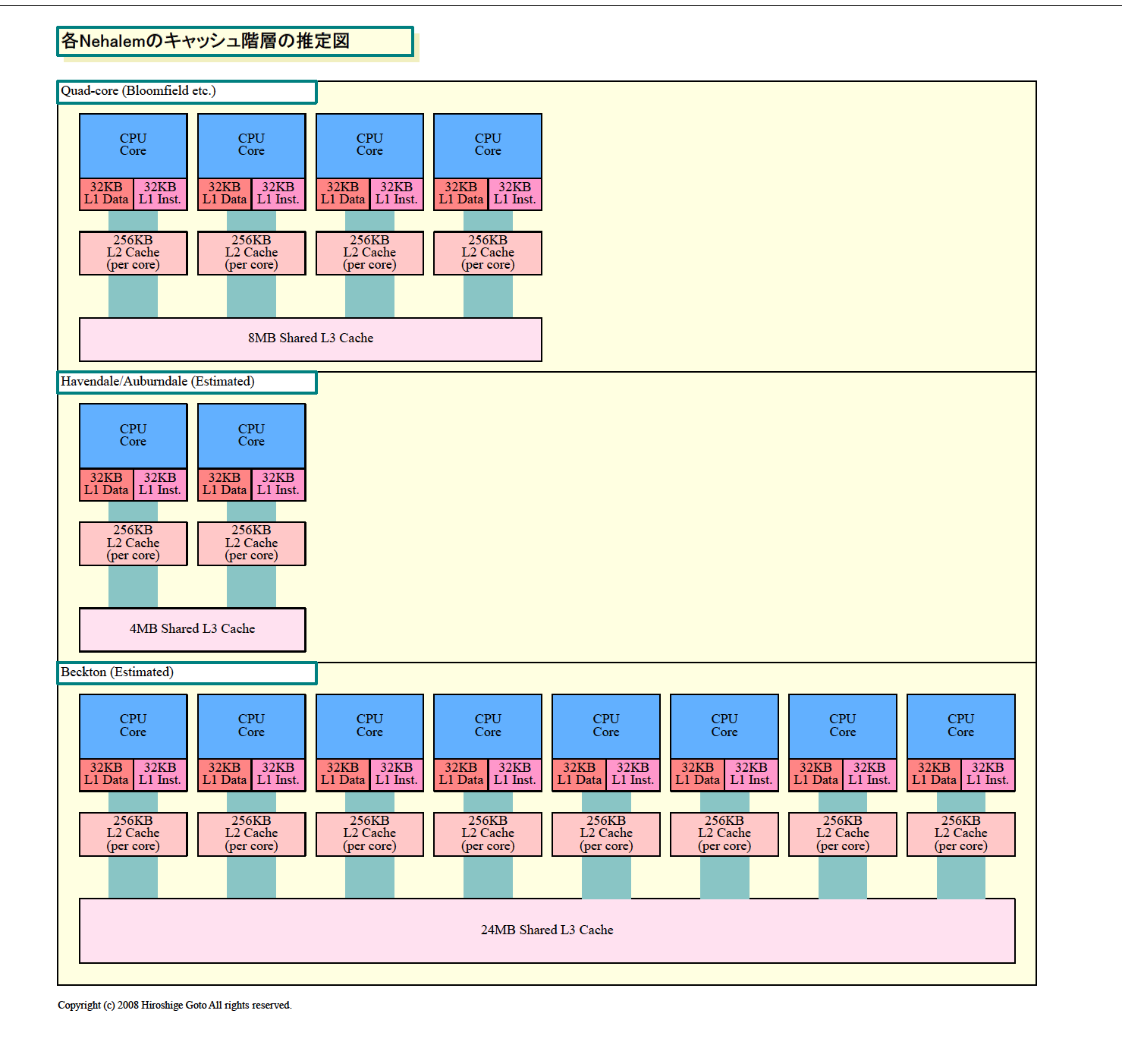 |
| Nehalemのキャッシュ階層の推定図
PDF版はこちら |
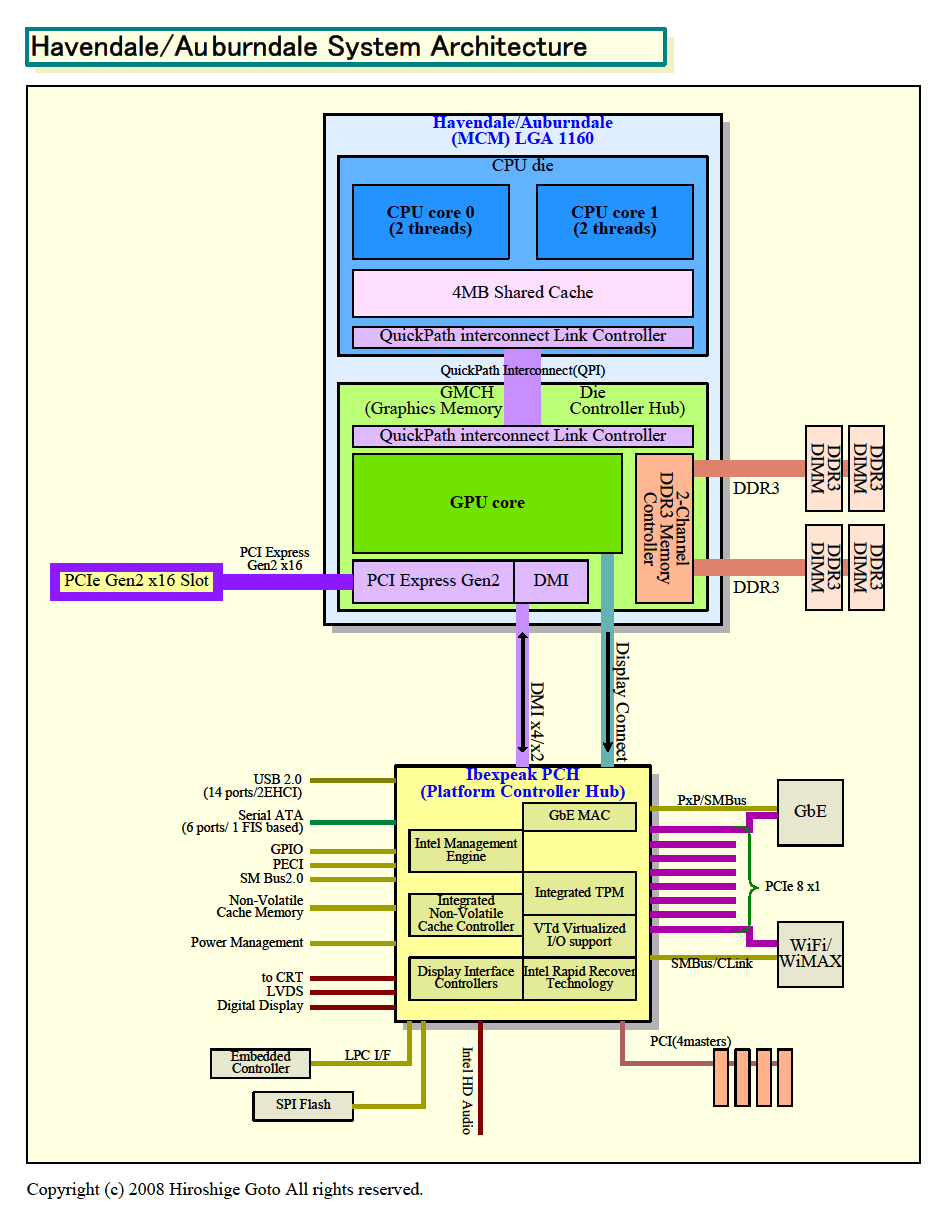 |
| Havendale/Auburndaleのシステムアーキテクチャ
PDF版はこちら |
●伸びるレイテンシを埋める新しいキャッシュ階層
キャッシュメモリは大ざっぱに言えば、容量が大きくなるに従って、アクセスレイテンシが長くなる。また、アクセスするコア数が増えることでも、レイテンシが伸びる可能性がある。L2アクセスに必要なサイクル数は、以前は1桁台だったのが、L2の大容量化とマルチコア化によって2桁台の10数サイクルになり、さらに伸びつつあった。つまり、CPUから見て、L2は次第に遠く(アクセスに時間がかかる)なりつつあった。
とはいえ、キャッシュにヒットしなければ、もっとはるかに遠い外部DRAMにアクセスしなければならない。その場合は、何百サイクルもムダになってしまう。そのため、これまでは、“より遅くなる”のを覚悟で“より大容量”のキャッシュを載せる方向へ進んで来た。
Nehalemの今回の3層キャッシュは、こうした問題に対する回答だと推定される。Intelは、これ以上、L2キャッシュが遅くなると、パフォーマンスに影響が出てしまうと判断したようだ。新しいキャッシュ構成のアプローチで、レイテンシ問題を解決する。すなわち、低レイテンシの小さな占有L2キャッシュと、レイテンシは長いが容量が大きな共有L3キャッシュの組み合わせだ。
Intelは次のように説明する。
「我々はキャッシュを極めてスケーラブルにしたかった。CPUコアを増やすにつれて、キャッシュ階層もスケールできるように。そのために、2-3の鍵となる要素がある。
1つは、(Nehalemでは)L2キャッシュの導入によって、L3キャッシュをバッファできる。CPUコア間で共有されるL3では、全てのコアがアクセスすることで、ボトルネックができる。それに対して、L2は各CPUコア占有で、非常にレイテンシが低く、実行エンジンにデータをうまく供給してくれる」
こうして見ると、考え方としては、大容量化するマルチコア時代の共有キャッシュと、CPUコア内部のL1キャッシュの間に、新たに、中間のレイテンシと容量を持つキャッシュ階層を挟み込んだと言えそうだ。実際に、Intelも「レベル2はブランドニューのキャッシュ」と表現する。つまり、3階層のうち、新たに加わったのはL3ではなくL2というニュアンスだ。従来のキャッシュ階層の下にL3を加えたのではなく、従来のL2とL1の間に1階層挟み込んで、その結果が3階層キャッシュとなったのだろう。
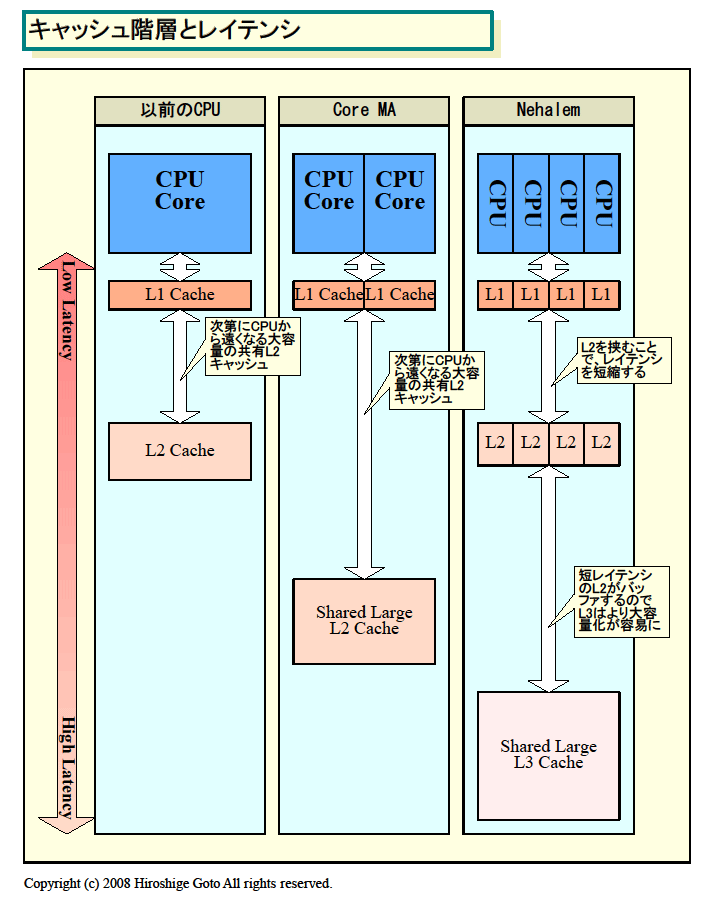 |
| キャッシュ階層とレイテンシ
PDF版はこちら |
より大きな視点で見ると、CPUから見たメモリとストレージは、遠く(アクセスが遅く)細く(CPUパフォーマンスに対する帯域が相対的に狭く)なり続けている。そのため、コンピュータシステムのメモリ階層は、どんどん深まる傾向にある。IntelとAMDが、どちらも3階層キャッシュを取り入れたことは、こうした全体の傾向からすれば、当然の流れと言えるかもしれない。
ちなみに、次のステップは、DRAMダイ(半導体本体)の、CPUダイへのスタッキングとなる可能性が高い。ディスクドライブとメインメモリDRAMの間にも、NANDフラッシュなど不揮発性メモリが挟まれて行くため、システムのメモリ階層は深化しつつある。全ては、CPUから遠くなるメモリとストレージをカバーするためだ。
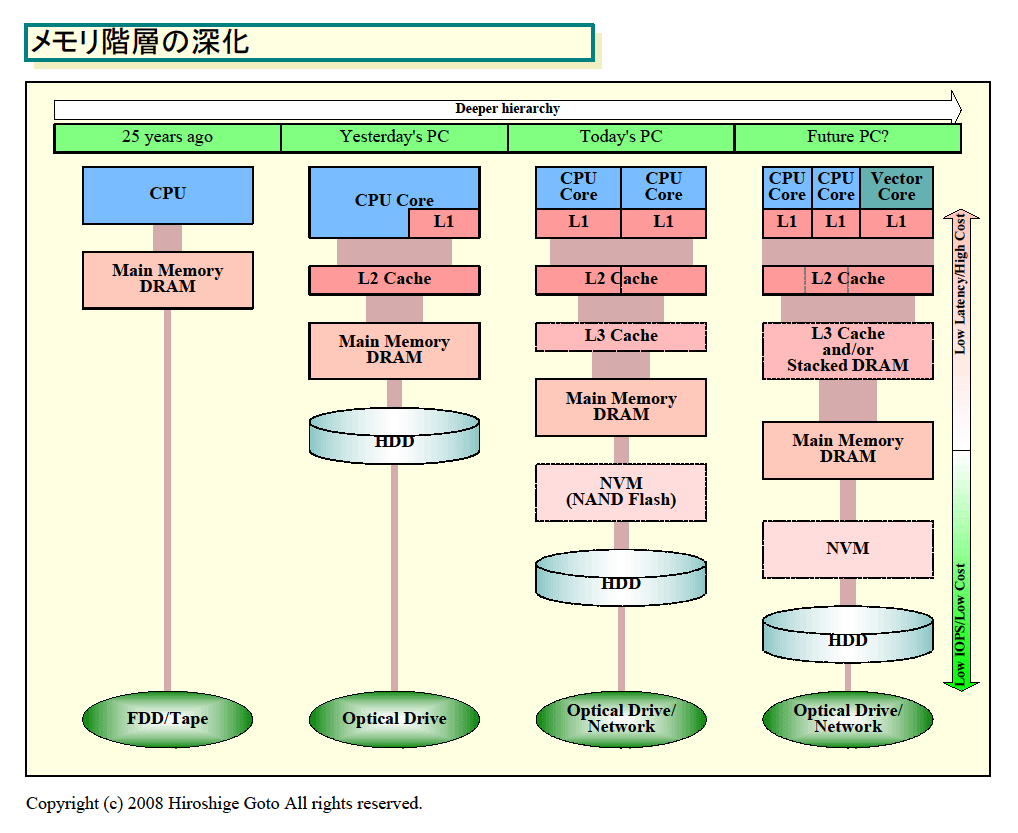 |
| メモリ階層の深化
PDF版はこちら |
●スケーラブルな展開を助けるインクルーシブ型のキャッシュポリシー
Intelは、キャッシュのスケーラビリティのもう1つのポイントは、「インクルーシブ型のキャッシュポリシー」だと言う。
「インクルーシブポリシーでは、L1とL2に存在するデータは、全てL3にも存在する。他のCPUやコアは、(メモリ上の)データが他のCPUやコアに(キャッシュされて)ないかどうかをチェックする必要がある。インクルーシブポリシーでは、L3キャッシュをチェックすれば済むが、そうでないと全てのコア(のキャッシュ)をチェックしなければならなくなる。そうなると、スケーラブルなソリューションにならない」
インクルーシブポリシーでは、キャッシュ容量にムダが生じるが、利点も多い。Intelは伝統的にインクルーシブポリシーを取っており、それがエクスクルーシブポリシーの採用が多いAMDとの違いとなっていた。ただし、AMDも、クアッドコアのBarcelona(バルセロナ)ファミリからはキャッシュの制御ポリシーを変更、エクスクルーシブポリシーにインクルーシブポリシーも加えたハイブリッド型にしている。キャッシュライン単位で、キャッシュ内容に応じてポリシーを変更する。
Nehalemのキャッシュ構成では、L1だけでなくL2キャッシュまでがCPUコアに付属している。そのため、CPUコア数の増減に合わせてL3キャッシュ量を変えるだけで、スケーラブルに対応できる。L2は256KBと小さいため、今のSRAMセルサイズならそれほどダイサイズ(半導体上の面積)を取らない。そのため、メインストリームデスクトップやモバイルのようにダイサイズと電力を抑えたい製品にもフィットする。これが、Intelの言う、デスクトップやモバイルにも最適化されているポイントだろう。
●スケーラブルに派生が可能なNehalemのキャッシュ階層
そのため、Nehalemでは、4コアから2コアと8コアへの派生でも、L2を含めたCPUコア自体の設計にはほとんど変更がないものと推測される。32nmの「Westmere(ウェストミア)」では、ハイエンドデスクトップとボリュームサーバー向けが6コアとなるが、その派生も同様にして行なわれると推定される。つまり、Nehalemではこのキャッシュ構成のために、上下への派生品の開発が、より迅速に行なわれたと推測される。
新たに公開されたNehalemの、より明瞭なダイ写真では、各CPUコアの右下または左下にL2キャッシュとおぼしき、比較的大きなSRAMエリアが見て取れる。だとすると、NehalemではCPUコアとL2がセットで矩形のCPUコアブロックとしてまとめられていることになる。CPUコア数に応じて、L2を含めたCPUコアのブロックの設計がそのままコピーされると推定される。
 |
| Nehalemのアーキテクチャはダイナミックにスケーラブルで、革新的な新デザイン |
Nehalem以前のIntel CPUでは、こうした柔軟なスケーラビリティはない。そのため、サーバーCPUでは、デスクトップ/モバイル用として設計されたCPUに、L3を張り出し的につけ加えて来た。いい例がDunningtonで、このCPUは32KBずつのL1、2個のCPUコアで共有する3MBのL2、6コアで共有する16MBのL3の3階層となっている。L2が2コアで共有なのは、元となるCore Microarchitecture(Core MA)が2コアでL2を共有する設計となっているからだ。
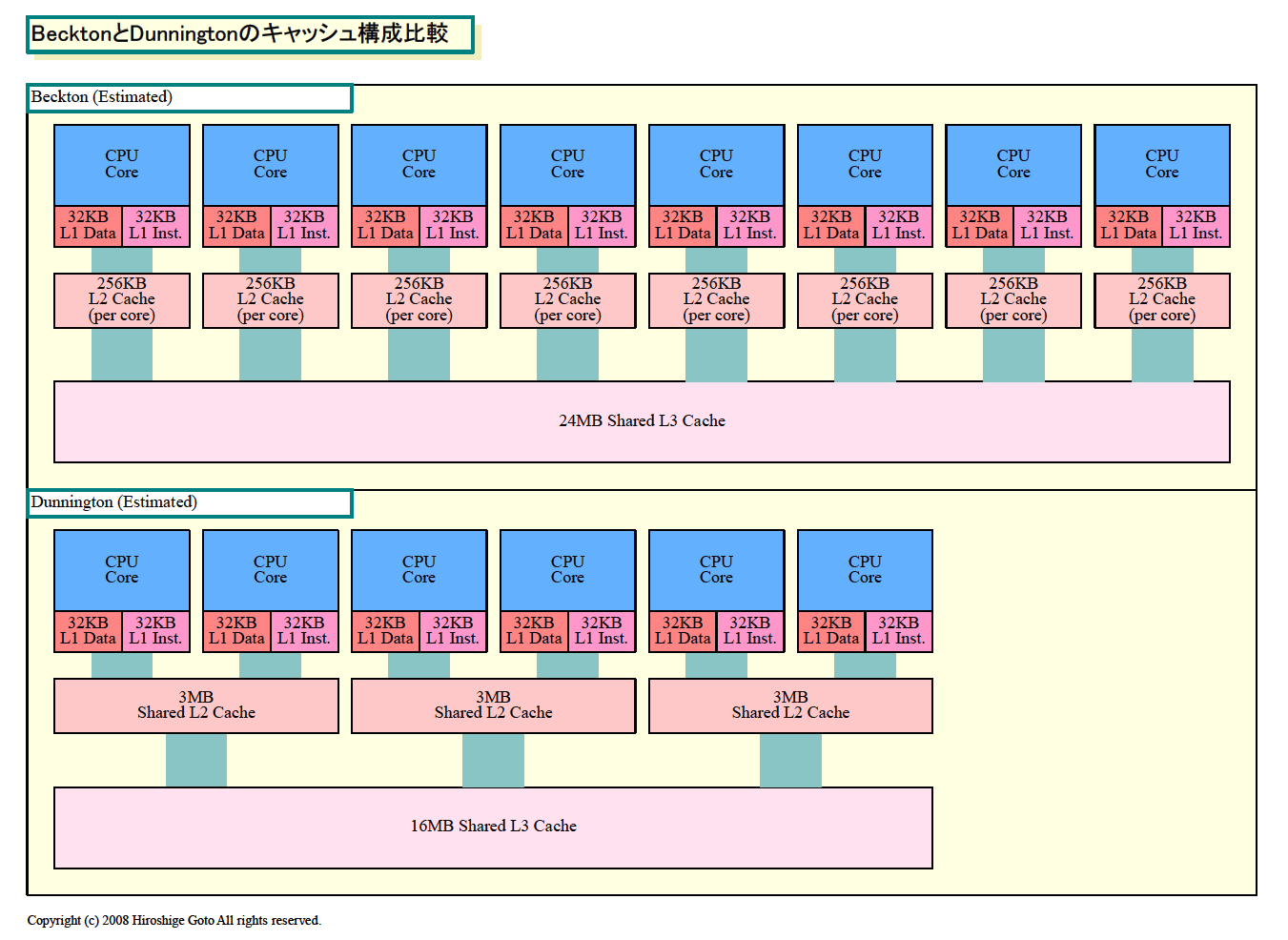 |
| BecktonとDunningtonのキャッシュ構成比較
PDF版はこちら |
今回公開されたDunningtonのダイ(半導体本体)写真を見ると、それがよくわかる。Intelも「デュアルコアのPenrynが3つ載っている」と形容するように、デスクトップ/モバイルのCore MAのCPUが、そっくりそのまま3個搭載されている。3個のデュアルコアCPUを、スイッチでL3と結んでいるのがDunningtonだ。
 |
| Intelが「デュアルコアのPenrynが3つ載っている」と形容するDunnington |
各CPUコアに占有L2があり、最下層に共有のL3を持つNehalemのキャッシュ構成は、じつはAMDのクアッドコアと共通する。AMDのBarcelona系CPUはL1データとL1命令キャッシュが各CPUコアにそれぞれ64KBずつ、占有L2キャッシュが各CPUコアに512KBずつあり、さらに4コアで共有する2MBのL3キャッシュを備える。両社がある程度似たようなキャッシュ階層を取ったのは、それが最も合理的だからかもしれない。
 |
| Nehalemのキャッシュ構成はAMDのクアッドコアと共通する |
 |
| Intelのデスクトップ向けCPUロードマップ
PDF版はこちら |
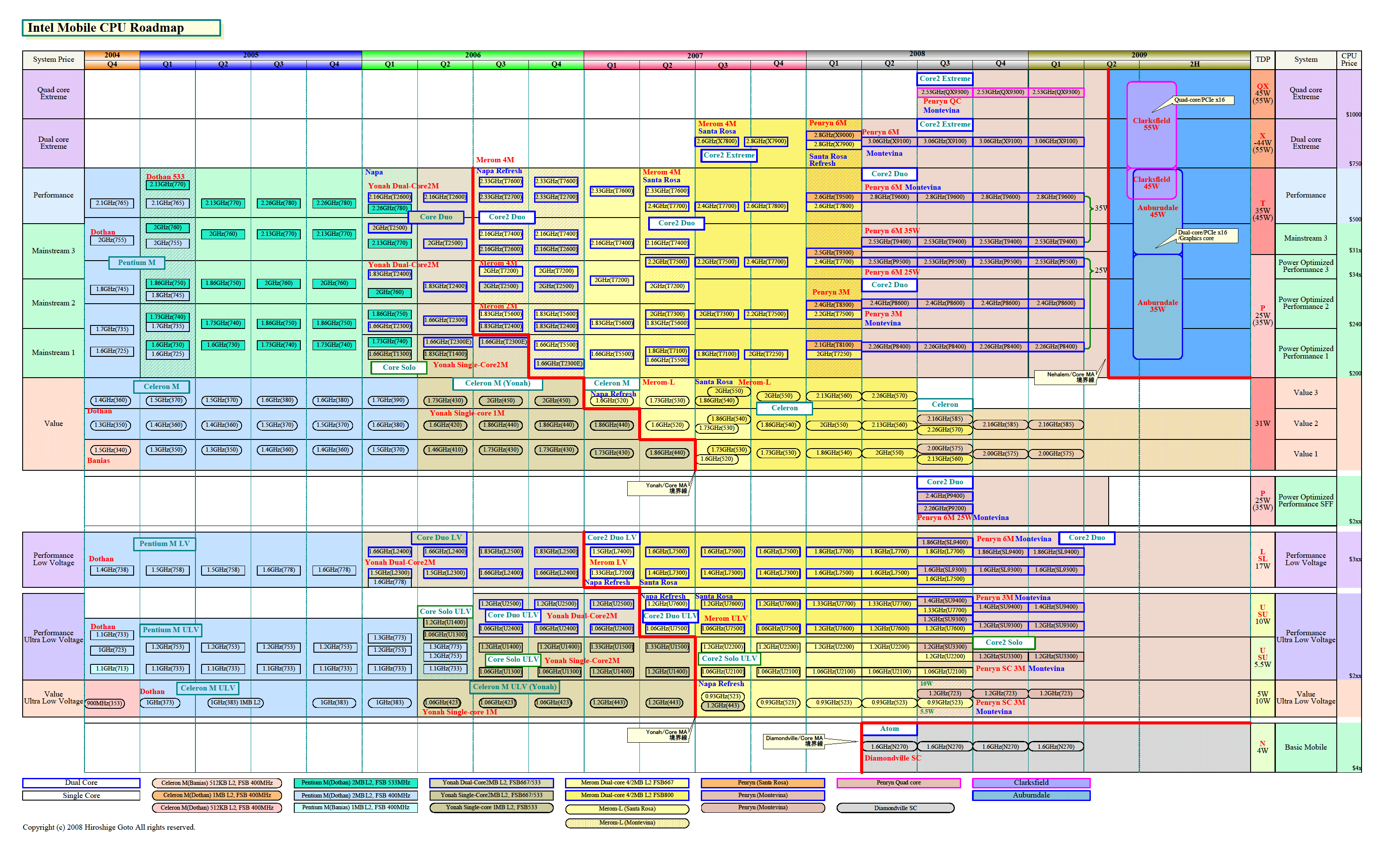 |
| Intelのモバイル向けCPUロードマップ
PDF版はこちら |
□関連記事
【3月18日】Intel、8コアNehalemや6コアDunningtonの概要を公開
http://pc.watch.impress.co.jp/docs/2008/0318/intel.htm
【2007年9月27日】【海外】Penrynの1.5倍のCPUコアを持つ次世代CPU「Nehalem」
http://pc.watch.impress.co.jp/docs/2007/0927/kaigai389.htm
【2007年10月2日】【海外】デュアルコアからオクタコアまでスケーラブルなNehalem
http://pc.watch.impress.co.jp/docs/2007/1002/kaigai390.htm
【2007年10月5日】【海外】Intelが目指すNehalemでのGPUとCPUの統合
http://pc.watch.impress.co.jp/docs/2007/1005/kaigai391.htm
(2008年3月21日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.