 |


■後藤弘茂のWeekly海外ニュース■x86からの脱却を図るIntelの新ロードマップ |
●Sandy BridgeとLarrabeeが見えるIntelの命令拡張
Intelは、今後CPUの命令セットアーキテクチャを次々に大きく拡張して行く。Intelは、2010年から先も含めた命令セットロードマップを、4月2~3日に中国・上海で開催した技術カンファレンス「Intel Developer Forum(IDF)」で示した。2010年のCPU「Sandy Bridge(サンディブリッジ)」以降は、主に、命令セットを拡張することで、CPUコアの性能を飛躍させて行く。
Intelは、そのための土台となる新命令拡張「Intel Advanced Vector Extensions (Intel AVX)」をSandy Bridgeから導入する。AVXでは、SIMD(Single Instruction, Multiple Data)演算の幅を従来の128bitsから256bitsに拡張する。それに合わせて、Sandy BridgeのSIMD演算ユニットの演算幅も256bitsに拡張、データロードも倍増させる。そのため、理論値ではCPUコア当たりの浮動小数点演算パフォーマンスは2倍に跳ね上がる。
 |
 |
| 新拡張命令「Intel AVX」の概要 | 浮動小数点演算の幅を2倍に拡張 |
Intelのこの方針によって、2010年から先は、ソフトウェアが新命令に対応し、SIMD浮動小数点演算を多用しないと、CPUの性能向上を活かすことが難しくなる。また、パフォーマンスが拡張されるのは、主にSIMDの浮動小数点演算となる。既存のコード、特にスカラ整数演算中心のソフトウェアは、今後、性能向上の幅が小さく留まるだろう。もっとも、現状でも、シングルスレッドの整数演算性能の向上は難しくなっている。今回のIDFでは、CPU開発の方向の変化という形で、その技術トレンドが明瞭に示された。
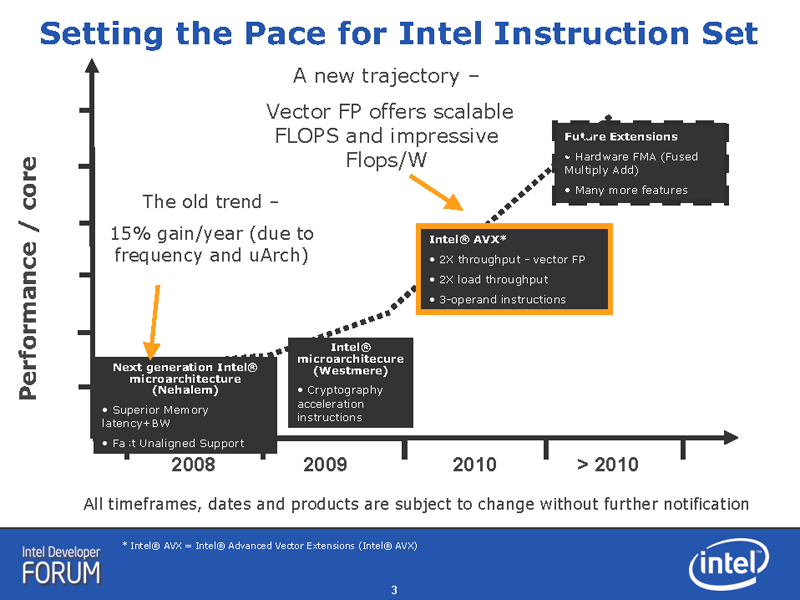 |
| 2008年以降のIntel命令セットの変化 |
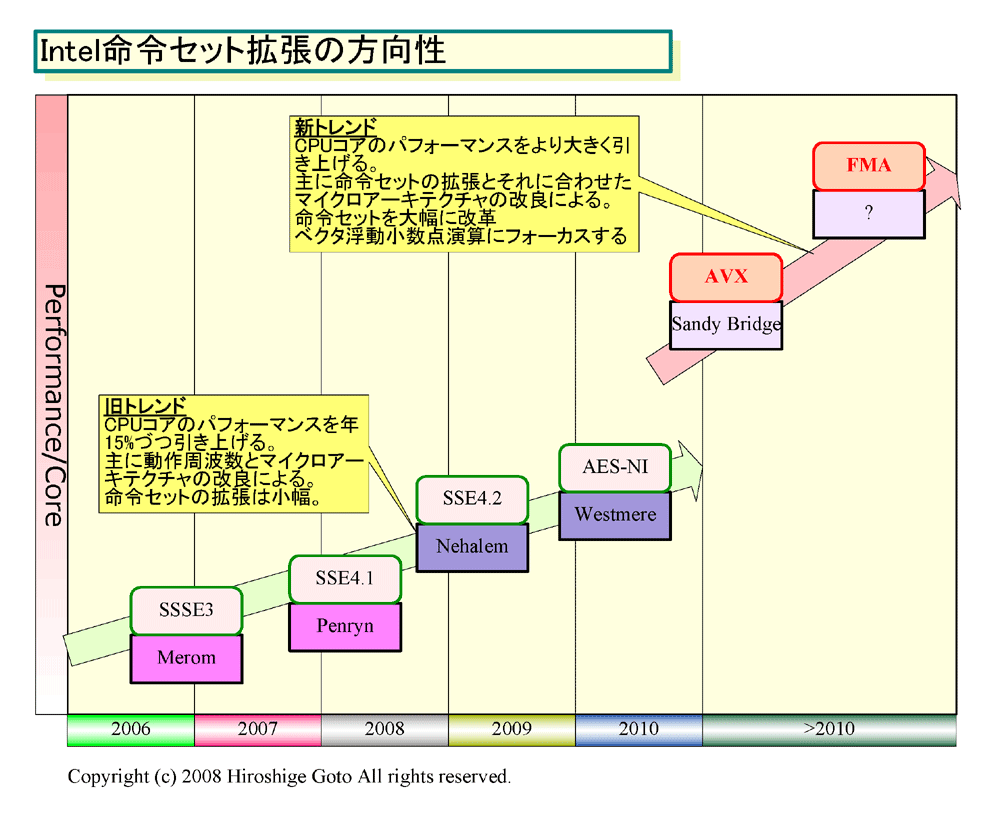 |
| Intel命令セットの拡張の方向性 PDF版はこちら |
Intel AVXは、CPUの性能をSIMD演算で拡張するMMX/SSEの延長にある。しかし、MMX/SSEとは根本的に異なる点がある。それは、拡張したAVX命令では、命令フォーマットも大きく変える点だ。x86(IA-32/Intel 64)アーキテクチャでは、これまで命令の頭に「プリフィックス(Prefix)」を加えることで、新命令を実現してきた。これは、あたかも、狭い家を次々に増築するようなもので、その結果、家(命令セット)は不格好でつぎはぎだらけになってしまった。こうした命令セットの複雑化と命令長の伸張は、x86 CPUのパフォーマンス向上の大きな壁になっている。
そこで、AVXでは、従来の不格好なx86命令の拡張方式をやめる。その代わりに、より効率的で、CPUハードウェアが扱いやすく、将来の拡張も容易な命令フォーマットシステムを導入する。家(命令セット)を大改築して、すっきりした建築に直そうというのが、AVXの方向性だ。命令フォーマットを再定義することで、“伝統的x86”を脱すると言い換えてもいい。Intelは、従来のSSE命令も、AVXへと移行させて行く予定だ。そのため、AVXはSSE命令をポートしやすいようになっている。
AVXの新しい命令エンコーディングシステムによって、Intelは、この先も次々に大幅な命令セット拡張が可能となる。例えば、Sandy Bridgeの先では、乗算と加算の2命令を融合させた「積和算命令」を導入する。また、512bitsや1,024bitsといったベクタ長の拡張も容易になる。Intelが、2008年末から2009年にかけて投入する予定のメニイコアCPU「Larrabee(ララビー)」は、AVXの命令フォーマット拡張の上に乗っている可能性が高い。AVXには、今後、毎世代命令セットを大きく拡張して行く、Intelの戦略が根幹を伺うことができる。
●命令フォーマットが根底から変わるAVX
AVXの256bits SIMDや3オペランドシンタックスは大きな拡張だが、実は、AVXで最も革新的な部分は別にある。それは、命令エンコーディングフォーマットの変更だ。
x86(IA-32/Intel 64)命令は、命令の中のオペコードの前に1バイト長のプリフィックスをつけることで、拡張することができる。新たに命令を加えたり、レジスタを拡張することは、命令の頭にプリフィックスを次々と足すことで実現して来た。SIMD系の命令を示すSIMDプリフィックスや、Intel 64アーキテクチャで拡張した8本のレジスタにアクセスできるREXプリフィックスがそれだ。
IA-32/Intel 64は、プリフィックスで拡張ができることが利点だが、副作用もある。それは、プリフィックスによって命令フォーマットが複雑になり、命令長が長くなることだ。そのため、IA-32/Intel 64命令は、デコードが難しく、命令デコードが性能のボトルネックとなったり、命令デコーダが肥大化して電力を消費するといった問題を引き起こしている。実際、Core Microarchitecture(Core MA)では、大きなパフォーマンスボトルネックが、命令のプリデコードとフェッチだった。また、命令拡張を繰り返すと、プリフィックスがどんどん増えて、命令長がネバーエンディングで長くなって行くという潜在的な問題もある。
「AVXの命令エンコーディングシステムを変えた理由は、ここ数年のSSE命令の進化にある。(IA-32/Intel 64の)SIMD命令は、最初は3バイト長の命令からスタートした。しかし、データタイプを追加するために、1バイトのプリフィックスを命令の最初に加え、次に、64-bitアーキテクチャでレジスタを8本加えたため、もう1バイトを命令頭に加えた。そうやって、3バイト長だった命令が、5バイト長になってしまった」とIntelのBob Valentine(ボブ・バレンタイン)氏(CPU Architect, Mobility Group)は問題点を説明する。
AVXでは、命令エンコーディングフォーマットを大きく変更することで、この問題を解決する。1バイト長のプリフィックスを次々に重ねるという“間に合わせ”の非効率なフォーマットをやめる。代わって、1バイトの「VEX(Vector Extension)」と呼ぶプリフィックスと、VEXに続く1~2バイトの「ペイロード(Payload)」システムを導入する。従来のプリフィックスで表現していた情報は、ペイロードのビットフィールドの中で表現する。
「VEXエンコーディングシステムのアイデアは、これらプリフィックス群に含まれる情報を圧縮することにある。1バイトのペイロードの中に、プリフィックスの情報を全て入れ込んでしまう。さらに、これから導入する新しいレジスタや、128bits長か256bits長などの情報も、ペイロードの中に圧縮する」(Valentine氏)。
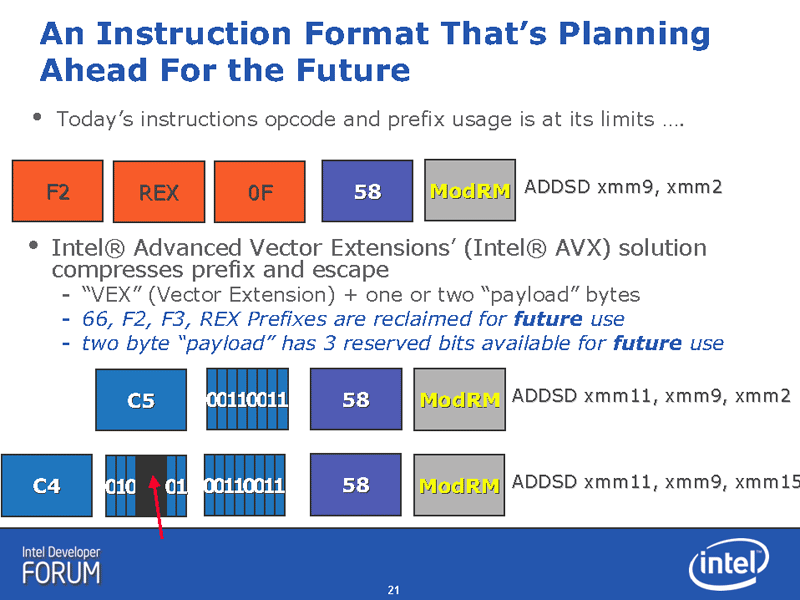 |
| AVXは将来に向けた命令フォーマット |
●将来の16wayのSIMD拡張まで可能にする命令フォーマット
 |
| IntelのBob Valentine(ボブ・バレンタイン)氏(CPU Architect, Mobility Group) |
VEXによって、AVXでは相対的に命令長が短くなる。VEXのペイロードは1バイトと2バイトの2種類がある。1バイトペイロードのVEXプリフィックスは「C5」、2バイトは「C4」となっている。1バイトペイロードの場合は、同じ命令でも、従来の命令フォーマットと較べると1バイト分命令が短くなる。
「実際には、全てを1バイトのペイロードに入れることはできない。そこで、2つのバージョンのVEXを用意した。4バイトバージョン(ペイロードは1バイト)と5バイトバージョン(ペイロードは2バイト)だ。ほとんどのレガシーコードは、例え、64bits命令であっても、4バイトバージョン命令に格納できる。そのため、1バイト分は命令が短くなる。いくつかの新しい命令は、新レジスタを使うため、5バイトバージョン命令を使うことになる。それでも、現状と同じ5バイトに収まる」と、Valentine氏は命令長でVEXが有利であることを説明する。
VEXエンコーディングフォーマットのもう1つの重要な点は、今後の命令セットの拡張も、同じ命令長で容易に実現できるようになることだ。命令を拡張すると、どんどん命令長が長くなるといった問題から解放される。
「5バイトバージョンの2つ目のペイロードはフルではない。将来の拡張のために3ビットが残されている。3bitsあれば、1,000以上の新命令を加えることができる。新しいフィーチャ、新しいレジスタ、新しいベクタ長。ほとんどなんでも加えることができる」(Valentine氏)。
VEXのフォーマットの命令長のままで、512ビットまたは1,024bitsのSIMDも導入できるという。また、多種のプリフィックスを重ねる従来の方式と較べると、命令全体のフォーマットが絞られ、命令長が予測しやすくなる。先頭の1バイトがC5かC4かで、オペコードまでの長さは決まる。そのため、ハードウェア側から見た場合に、命令のプリデコードが容易になると考えられる。
●x86 CPUのボトルネックを軽減するVEXエンコードフォーマット
AVXのVEXエンコードシステムは、Intel CPUの今後の進化に深く関わっている。なぜなら、x86系CPUの最大の弱点が、命令デコードにあるからだ。
Core MAは、4命令実行の強力な実行パイプラインを持つが、フロントエンドに弱点がある。まず、L1命令キャッシュから命令をフェッチするポートは16バイト長と、フェッチ幅が限られている。そのため、個々の命令が長いと、フェッチできる命令数が制約される場合がある。次に、IA-32/Intel 64命令を切り出すプリデコードにもボトルネックがある。オペランドやアドレス長を変化させる命令プリフィックス「LCP(Length Changing Prefixes)」がつくと、プリデコードが格段に遅くなる。命令長マーキングのアルゴリズムを変えなければならないからだ。
 |
 |
| 命令フェッチ&プリデコードの最適化 | |
Core MAのプリデコード&デコード部分の弱点は、IA-32/Intel 64の命令セットアーキテクチャそのものに関わっている根が深い問題だ。可変長命令に増築を重ねた現在のIA-32/Intel 64では、拡張した命令は長くなり命令フェッチ帯域を圧迫し、複雑な命令フォーマットは命令を切り出しにくくしている。それに対して、一般的なRISC(Reduced Instruction Set Computer)では、命令長と命令フォーマットが決まっているため、デコードはずっと容易だ。x86系CPUベンダーは、この問題を解決しようとするとリソースが必要となり、電力効率を落とすという、ジレンマを抱えている。
そして実は、最新のNehalemですら、Core MAのこうした弱点は、ある程度引き継がれている。明白な弱点であるため、Nehalemでは改良されると推測していたが、16bytesフェッチやプリデコードのシステムなどは、ほぼそのままだという。なぜなら、改良しようとすると、膨大なトランジスタが必要となり、電力消費を増やしてしまうからだという。
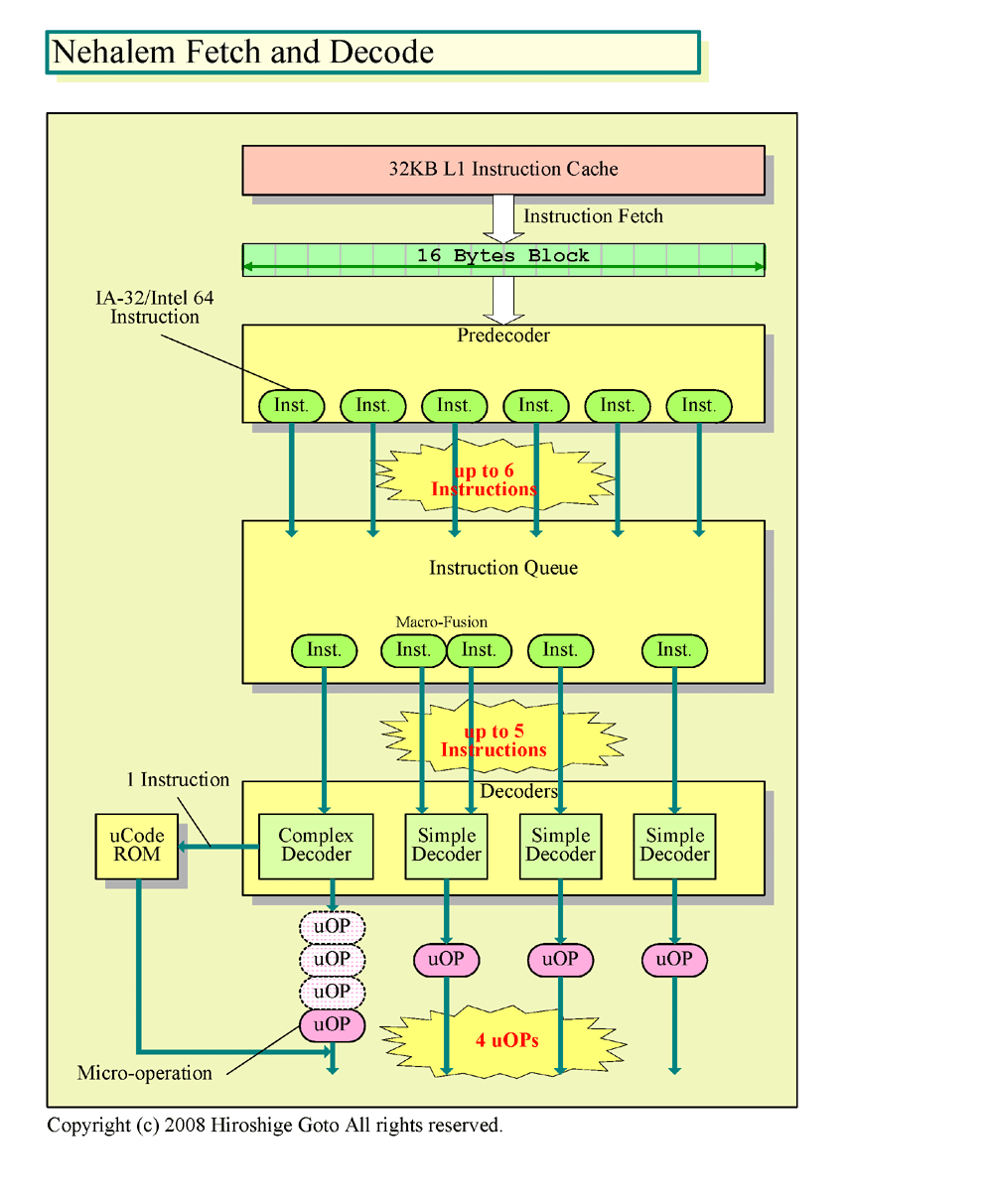 |
| Nehalemのフェッチ&デコード PDF版はこちら |
Nehalemのこの設計チョイスには疑問があったが、VEXフォーマットの仕様を見ると、意図は明白だ。Intelは、CPU側のプリデコード&デコードハードウェアをいじるよりは、命令フォーマットそのものを改革した方が良策だと判断したと思われる。つまり、問題の根源の方から手をつけようと判断したわけだ。命令フェッチ幅の狭さも、命令マーキングアルゴリズムの複雑さも、命令フォーマット側が改良されれば、自然に軽減されて行く。
Intelは、CPUハードウェア側のこうした設計を考えて、VEXフォーマットを開発したと推測される。IDFでVEXフォーマットの説明を行なったValentine氏が、Core MAのフロントエンドのフェッチからデコードまでの部分を開発したシニアアーキテクトであることが、それを証明している。IA-32/Intel 64命令のデコーダ設計のスペシャリストが、VEXでの命令フォーマットの改革を先導したと推測される。
 |
| Nehalemブロックダイヤグラム PDF版はこちら |
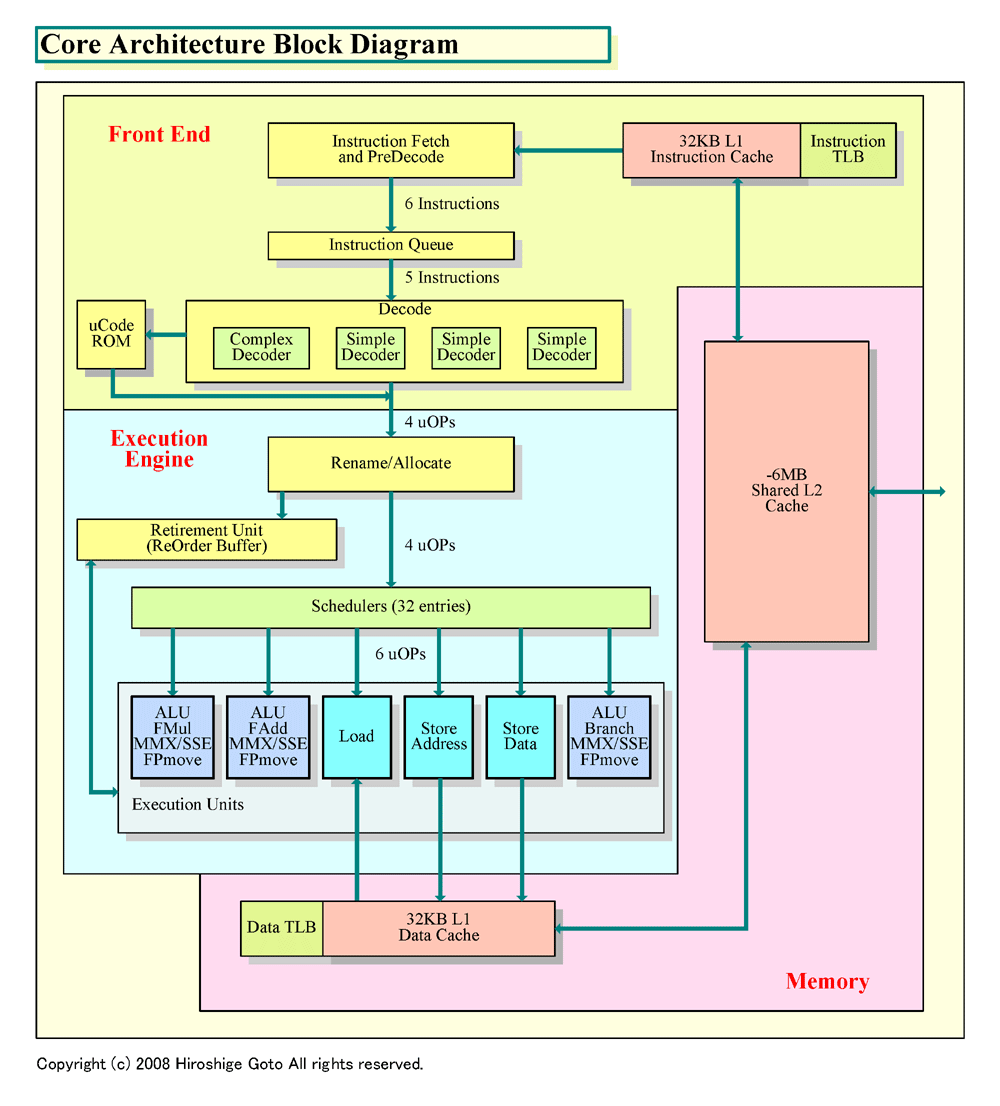 |
| Core Architectureブロックダイヤグラム PDF版はこちら |
このように、AVX拡張命令を概観すると、IntelのCPU開発の全体の流れが見えてくる。Intelは、以前と較べると、よりドラスティックに命令セットアーキテクチャを改革しようとし始めた。なぜなら、同じコードのソフトウェアが、マイクロアーキテクチャの改良により、新CPUでは、より速く走るという構図が、もはや通用しないからだ。CPUパフォーマンスをアップさせるには、もはやソフトウェア側の対応を促すしかない。それなら、命令セットをハイペースで進化させ、ついでに命令フォーマットも変革してしまおう、それがIntelの現在の方向性だ。
AVX拡張命令は、SSEを包含するもので、AVXへの移行を促すことで、今日のSSEもVEXフォーマットへと置き換えようとしている。「全体を見ると、Intel AVXは、徐々に、今日のアプリケーションの中の従来型のSSE命令を置き換えて行くと予想している」とIntelのBenny Eitan氏(CPU Architect, Mobility Group)は語る。
Sandy Bridgeのデコーダハードは、旧来のIA-32/Intel 64のプリフィックス型フォーマットと、新しいVEXフォーマットの両方をデコードできる。しかし、VEXの方が命令長で有利であるため、1サイクルでデコードできる命令数は原理的には多くなる。また、プリデコーダが、VEXをより効率よくマーキングできるとしたら、そこでもVEXの方が有利になる。Sandy Bridgeの世代では、まだ差がつかないかもしれないが、いつかはそうなるだろう。
 |
| Intel命令セット拡張の変遷 PDF版はこちら |
□関連記事
【3月21日】【海外】モバイルにもL3キャッシュをもたらすNehalem
http://pc.watch.impress.co.jp/docs/2008/0321/kaigai427.htm
【1月29日】【海外】2つのCPU開発チームに競わせるIntelの社内戦略
http://pc.watch.impress.co.jp/docs/2008/0129/kaigai412.htm
【2007年12月11日】【海外】イスラエルから発信されるIntelの次世代CPUテクノロジー
http://pc.watch.impress.co.jp/docs/2007/1211/kaigai406.htm
(2008年4月7日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2008 Impress Watch Corporation, an Impress Group company. All rights reserved.