 |


■後藤弘茂のWeekly海外ニュース■IntelのGPU統合CPU「Havendale/Auburndale」とは何か |
●IntelがMCMでGPUコアを統合する理由
IntelのGPU統合CPUである「Havendale(ヘイブンデール)」と「Auburndale(オーバーンデール)」の大まかな姿が明らかになった。Havendale/Auburndaleの正体は、デュアルコア版のNehalemと、グラフィックス統合チップセットGMCH(Graphics Memory Controller Hub)をワンパッケージに納めたMCM(Multi-Chip Module)だ。Intelは、クアッドコアを早期に投入するためにMCMを選んだが、GPU統合CPUでも同じ選択を行なった。
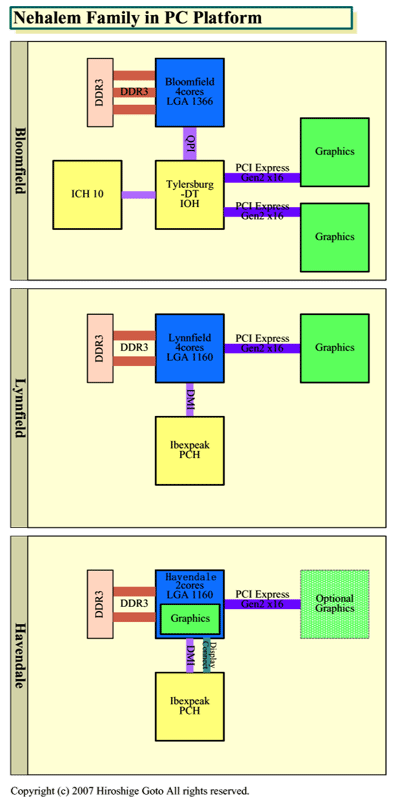 |
| PC向けNehalemファミリ ※別ウィンドウで開きます PDF版はこちら |
このことは、いくつかの興味深い事実を示唆している。まず、NehalemではGPU統合は当初からの設計プランに入っていなかった可能性が高い。Intelは、Nehalemではクアッドコアだけでなくオクタコア(8コア)もネイティブで1個のダイに統合する。それなのに、GPUはネイティブ統合ではない。オクタコアは最初からプランにあったが、GPU統合はそうではなかったのかもしれない。
もっとも、GPU統合をMCMで実現するのが合理的である理由もある。それは、CPUの方が開発サイクルがGPUより長いからだ。そのため、GPUコアのマイクロアーキテクチャがある程度固定化されないと、CPUのサイクルに合わせた統合は難しい。DirectX 10でそのレベルまで進んだように見えたGPUアーキテクチャだが、実際には、まだ実装上のインパクトが多少ある改良(マルチコンテキスト化など)が漸進的に進んでおり、CPUへの統合に課題があるのも確かだ。
また、IntelのGPUコアのマイクロアーキテクチャ自体、パフォーマンス/ダイ効率を考えると、まだ成熟しているとは言い難い。Havendale/Auburndaleへのネイティブ統合に間に合わせるには、2007年に設計したGPUコア(EagleLake相当)を使う必要がある。しかし、MCMで統合するなら、CPUへのネイティブ統合に比べて、1世代進んだGPUコアを使うことができる。GPUコアのフィーチャやパフォーマンスを第一に考えるなら、MCMの方がいい選択と考えることもできる。ただし、消費電力ではMCMは不利になる。
もっとも、Havendale/Auburndaleとペアになるチップセット「Ibexpeak(アイベックスピーク)」の仕様を見ると、Intelがどこかの時点でGPUのネイティブ統合を考えていることも分かる。アナログ部分がGMCHからIbexpeak側に移されて、GPUからのデジタルアウト専用のインターコネクト「Display Connect」が用意されているからだ。アナログ回路は、CPUダイへの統合では障壁となる。
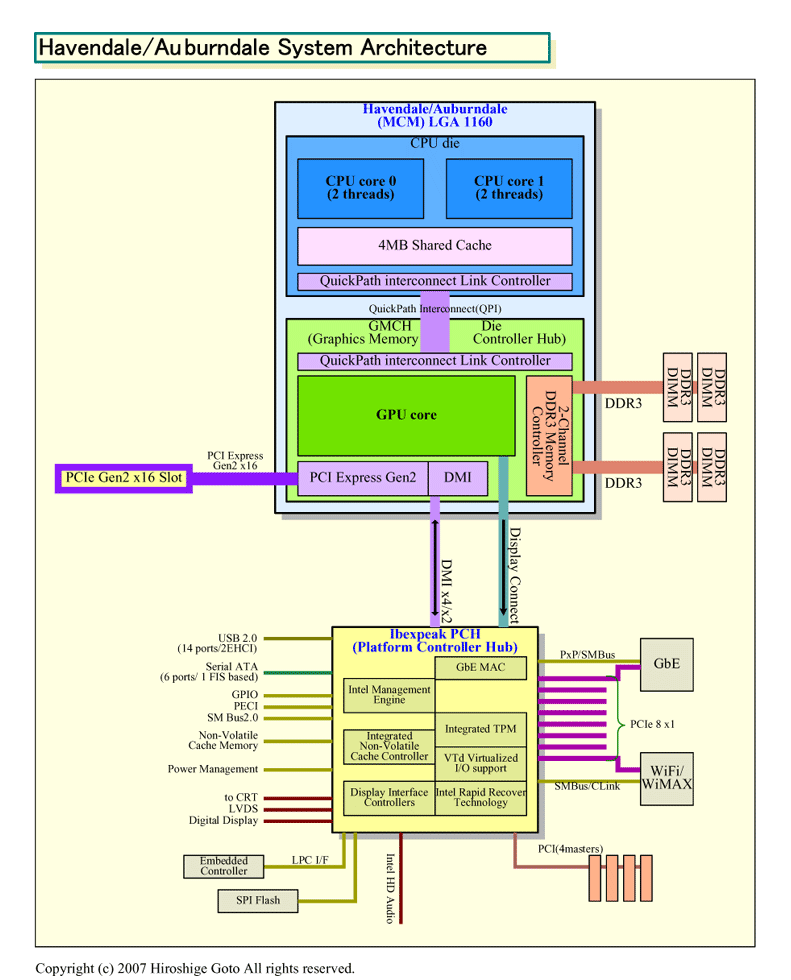 |
| Havendale/Auburndaleシステムアーキテクチャ ※別ウィンドウで開きます PDF版はこちら |
●デュアルコアで4MBキャッシュのHavendale
Havendale/Auburndaleは、CPUダイ(半導体本体)とGMCHダイの2個のダイで構成されている。
HavendaleはCPUダイはデュアルコアで、プロセス技術は他のNehalemファミリと同じ45nmプロセス。これはAuburndaleも同様だと見られる。CPUコアは、上位のNehalem系CPUと同様に各コアが2スレッドを実行するSMT(Simultaneous Multithreading)アーキテクチャとなっている。そのため、2コアで合計4スレッドの同時実行が可能だ。命令セットの拡張も、他のNehalemと同じだ。2個のCPUコアは4MBのキャッシュを共有している。キャッシュ階層は明らかになっていない。
 |
| 推定されるNehalemファミリのダイ ※別ウィンドウで開きます PDF版はこちら |
GMCHダイには、デュアルチャネルDDR3インターフェイス、PCI Express Gen2 x16、GPUコア、DMIインターフェイスなどが実装されている。そのため、Havendale/Auburndaleは、単体でメインメモリDRAMとPCI Express Gen2デバイスを接続できる。また、内蔵GPUコア以外に、ディスクリートグラフィックスを接続することも可能だ。
消費電力はサーバーとデスクトップ向けのHavendaleが95W以下、モバイル版のAuburndaleが45Wと35Wとなる予定だ。パッケージはHavendaleが「LGA1160」、Auburndaleが「rPGA989」。VRDのバージョンは11.1。対応するチップセットは、新開発の「PCH(Platform Controller Hub)」であるIbexpeakとなる。GMCH機能がCPUパッケージ内に統合されているため、Havendale/AuburndaleとIbexpeakの2チップでのシステム構成となる。
スケジュールは、来年(2008年)第3四半期から第4四半期頭にかけてHavendaleのファーストサンプルチップを配布する予定。すでに、Havendale/AuburndaleのCPUダイのサンプルはIntel社内では上がっており、社内ラボではテストを済ませていると言われている。量産サンプルは2009年前半で、2009年前半中に製造に入る見込みだ。順調に行けば製品出荷は2009年の第2四半期となる。
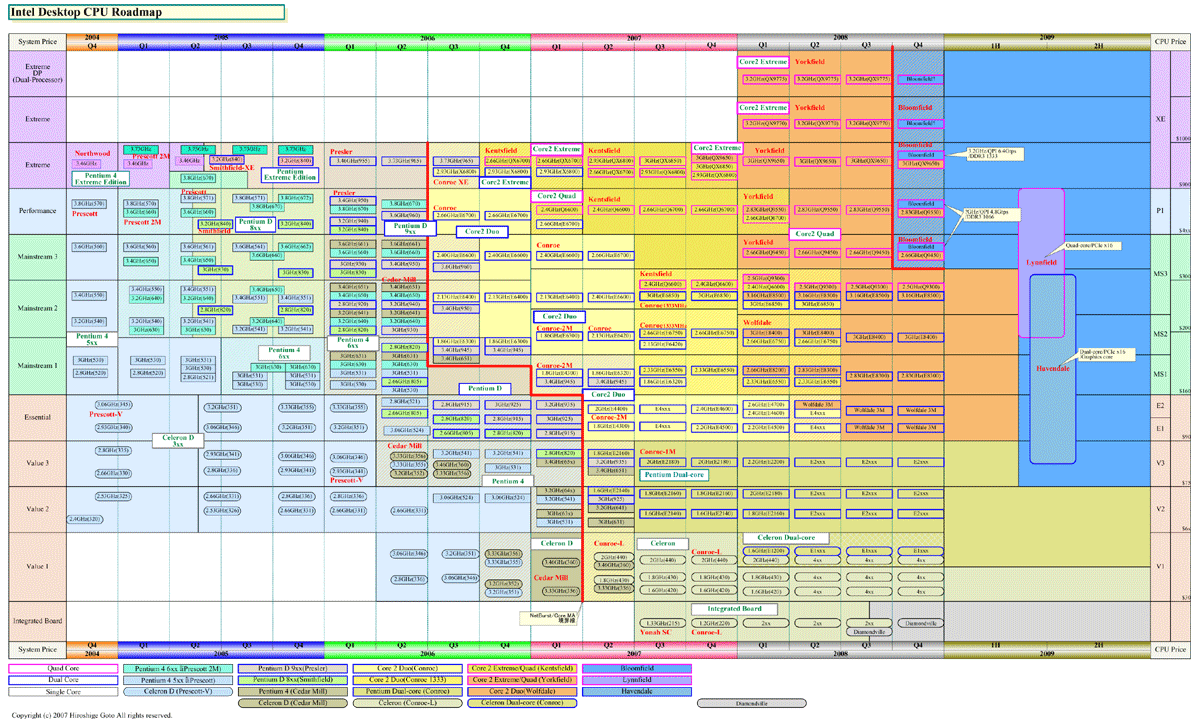 |
| Intel デスクトップCPUロードマップ ※別ウィンドウで開きます PDF版はこちら |
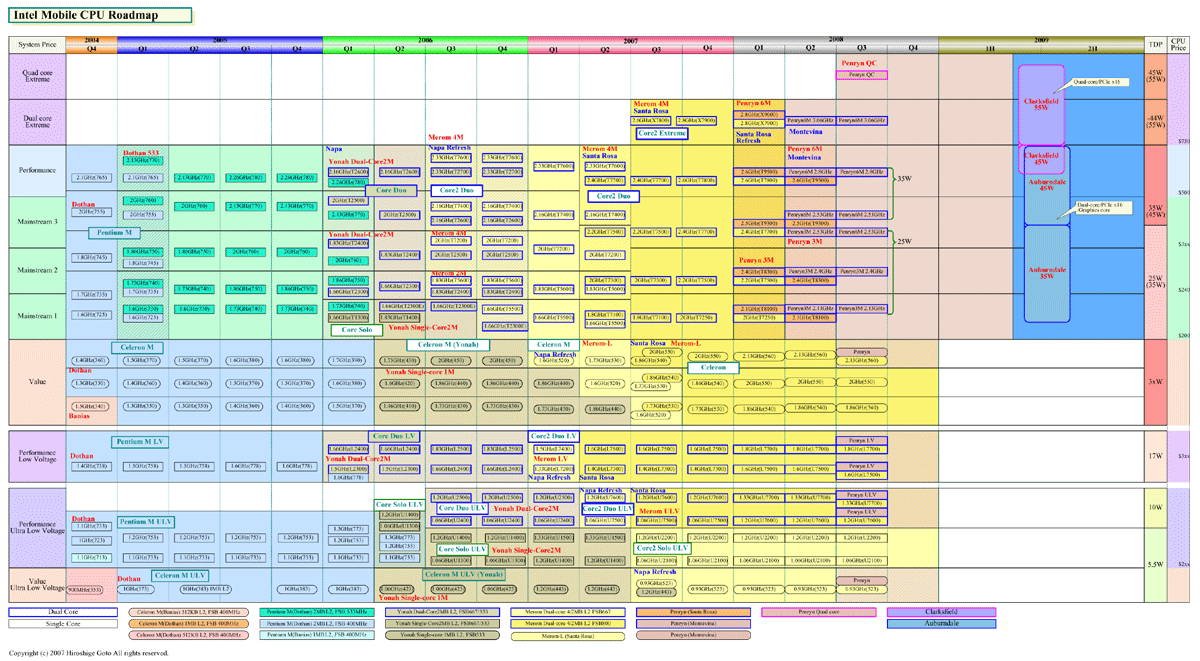 |
| Intel モバイルCPUロードマップ ※別ウィンドウで開きます PDF版はこちら |
●広帯域のCPUとGMCHのインターコネクト
Havendale/AuburndaleのCPUダイとGMCHダイは、オンサブストレートのインターコネクトで結ばれている。このインターコネクトは、Nehalemで導入されたシリアルインターコネクトのQuickPath Interconnect(QPI)と見られる。
 |
| Nehalemファミリの内部構成 ※別ウィンドウで開きます PDF版はこちら |
Intelはもともと、デスクトップCPUではMCMではなく、GMCHを従来通りCPUパッケージの外に出す構成を考えていた。その時点でのGMCHのコードネームは「SummitLake(サミットレイク)」で、そのFSBはQPIだった。そのため、Havendale/AuburndaleのCPUダイとGMCHダイもQPIで接続されていると推測される。
オフチップのQPIの転送レートはピン当たり最高6.4Gbpsで、インターフェイス幅は1リンクで上下16bitsずつ合計で32bits。帯域は25.6GB/secとなる。Havendale/AuburndaleのGMCHがDDR3-1333をサポートするなら、2チャネル128bitsのインターフェイスでメモリ帯域は21.3GB/secに達する。QPIの帯域でマッチすることになる。
もっとも、Havendale/Auburndaleのインターコネクトに関しては、Intelは原理的に、オンパッケージの利点を活かすことができる。伝送距離が短く、電気的に信号品質を上げることが容易であるため、より高い転送レートにすることも原理的には可能だ。将来的なスケーラビリティを持つ。
Havendale/AuburndaleのCPUの基本的なフィーチャは、上位のNehalemと共通していると見られる。少なくとも、SMT(Simultaneous Multithreading)や命令セット拡張などのキーフィーチャはHavendale/Auburndaleも備えている。
Havendale/Auburndaleのキャッシュ階層は浅いと予想される。CPUがキャッシュ階層を深める最大の要因は、キャッシュのレイテンシの増大だ。キャッシュ容量が大きくなり、アクセスするコア数が増えるに従って、アクセスレイテンシはどうしても伸びてしまう。キャッシュレイテンシは、CPUパフォーマンスに大きく影響するため、一定以下のレイテンシに保つ必要がある。
しかし、Havendale/Auburndaleでは、デュアルCPUコアで共有キャッシュ量も4MBに過ぎない。この構成から考えて、2階層のキャッシュでもレイテンシが現在のCore MA系デュアルコアCPUより伸びることはないと推測される。そのため、Havendale/Auburndaleではキャッシュ階層は、より単純なはずだ。
●小さなCPUダイと標準的なGMCHダイの組み合わせ
Havendale/AuburndaleのCPUダイのダイサイズ(半導体本体の面積)は明らかになっていない。しかし、単純に計算しても、2個のCPUコアと4MBのキャッシュ、GMCHとのインターコネクトであるQPI 1リンクという構成で、上位のNehalemのようなDRAMインターフェイスを持たないため、CPUサイズはかなり小さいと推定される。
クアッドコアでノースブリッジ機能も統合したBloomfield/Gainestownは約270平方mmのダイで、DRAMインターフェイスがかなりの割合を占めていた。それに対して、Havendale/Auburndaleは半分の130平方mm程度か、それ以下のサイズの可能性もある。そうなると、CPUとしてのダイサイズは、65nm版のCore MA「Merom(メロン)」のダイ143平方mmよりさらに小さく、45nm版のCore MA「Penryn(ペンリン)」の107平方mmに近づくことになる。つまり、コスト構造はCore MAに近づき、メインストリームCPUとして十分に低コストなサイズとなる。
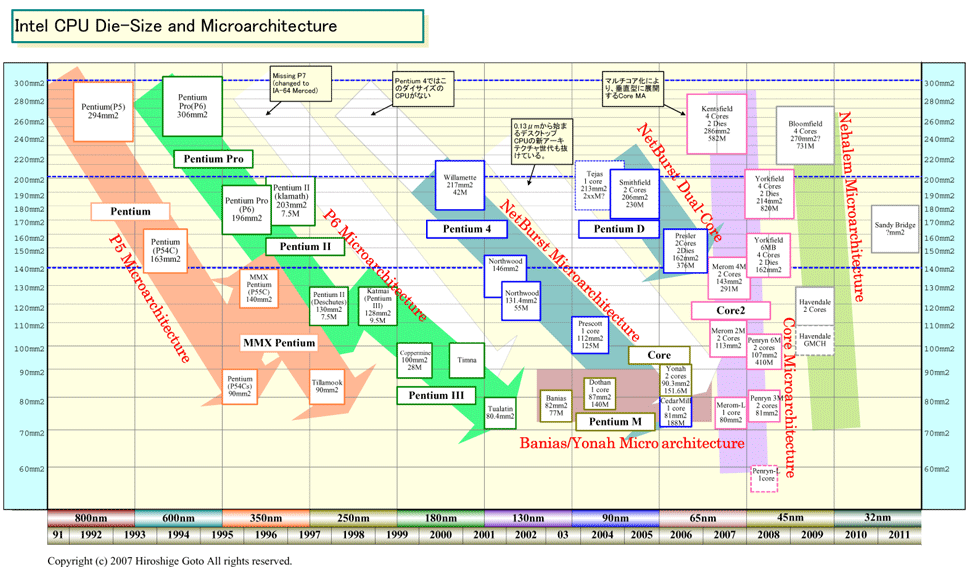 |
| Intel CPUダイサイズと歩留まり ※別ウィンドウで開きます PDF版はこちら |
Havendale/AuburndaleのGMCHダイのサイズもまだわかっていない。しかし、IntelはGMCHをそれほど小型化せず、従来のGMCHと同程度か一回り小さい100平方mm程度のサイズにするとも言われている。もしそうだとしたら、いくつかの理由が考えられる。
1つは、ノートPCでの熱処理の問題だ。GPUコアのように発熱が多いユニットを内蔵するGMCHは、ダイ(半導体本体)を小さくし過ぎると、電力密度が高まってしまい冷却が難しくなる。できれば、CPUとGMCHの電力密度がある程度近い数字であることが望ましい。
もし、モバイル向けのAuburndaleのGMCH自体の電力消費が、MontevinaのGMCHチップ「Cantiga(カンティーガ)」とあまり変わらないとすれば、ダイもあまり小さくすることができない。ダイを小さくすれば電力密度の上昇を招いてしまうからだ。ちなみに、Cantigaのダイサイズは10.5mm×10.5mmの110平方mmだと言われている。
そのため、IntelはHavendale/AuburndaleのGMCHでは、プロセス微細化によって各ユニットが縮小したとしても、ダイサイズを保つ必要がある。GPUコアのキャッシュやPCI Express Gen2などインターフェイスのバッファを増やすなどの方法で、発熱の少ないSRAMでダイを埋めて、電力を増やさずにダイサイズを保つことになる。
また、IntelはAuburndaleではCPUダイとGMCHダイで同じ冷却機構を共有することで、TDP(Thermal Design Power:熱設計消費電力)枠内での両ダイのワークロードを最大に引き上げようとしている。詳細は後のレポートで説明するが、そのために、CPUダイとGMCHダイを同じサーマルプレートにアタッチする必要がある。
そして、その場合、ヒートパイプのアタッチプレートは、サブストレート上の2つのダイに渡って均等にアタッチできるのが好ましい。理想的には2個が同じチップで、同じサイズで同じ高さのダイであればいい。Core MAのクアッドコアはこのパターンだ。しかし、Havendale/Auburndaleの場合にはCPUとGMCHなのでそうは行かない。次善の策は、ダイの縦長を揃えて、並べた時に同じようにプレートが当たるようにすることだが、これもダイの形状が制約される。
各種インターフェイスに一定のダイエッジが必要になることも、ダイの小型化を難しくする。GMCHは、デュアルチャネルDDR3インターフェイスとPCI Express Gen2 x16、PCHと接続するDMI、それにCPUダイとのインターコネクトなどを備える。Havendale/AuburndaleのGMCHが100平方mm程度のダイであるなら問題にはならないが、ダイを縮小し過ぎると問題が出る可能性はある。
□関連記事
【11月27日】【海外】Intelが投入するGPU統合CPU「Havendale/Auburndale」
http://pc.watch.impress.co.jp/docs/2007/1127/kaigai402.htm
【11月26日】【笠原】Intelは、Nehalem世代で5つのCPUコアを投入
http://pc.watch.impress.co.jp/docs/2007/1126/ubiq204.htm
【11月9日】【海外】2008年中に95%をデュアルコアにするIntel CPUロードマップの秘密
http://pc.watch.impress.co.jp/docs/2007/1109/kaigai399.htm
(2007年11月28日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.