 |


■後藤弘茂のWeekly海外ニュース■PCのメモリ階層の変革を展望するMicrosoftとIntel |
●Microsoftがメモリ階層の変革の必要性を説明
フラッシュメモリは、はたしてPCの標準的なメモリデバイスとして、全てのPCに取り込まれるようになるのか。全てのPCが、DRAMとHDD以外にフラッシュを標準で積むようになるのか。それが、現在の疑問点だ。
フラッシュがPCに取り込まれるようになった直接的な原因は、NANDフラッシュメモリの価格下落と大容量化だ。フラッシュベンダは、NANDの新市場を開くために、PCへの応用に積極的に動いてきた。
しかし、ソフトウェアベンダであるMicrosoftがWindows Vistaでフラッシュを積極的にサポートし、CPUベンダ(フラッシュも製造している)であるIntelがフラッシュの搭載に積極的になり始めた理由は、価格や容量だけではない。その背後には、PCのメモリ階層の変革についての展望がある。
MicrosoftやIntelの構想を突き詰めると、フラッシュのような不揮発性メモリ(NVM:Non-Volatile Memory)が、やがてHDDやDRAMのようにPCの標準的なメモリ階層として入ってゆくことになる。つまり、PCのメモリ&ストレージはDRAM+HDDではなく、DRAM+NVM+HDDまたはDRAM+NVMへと切り替わる。
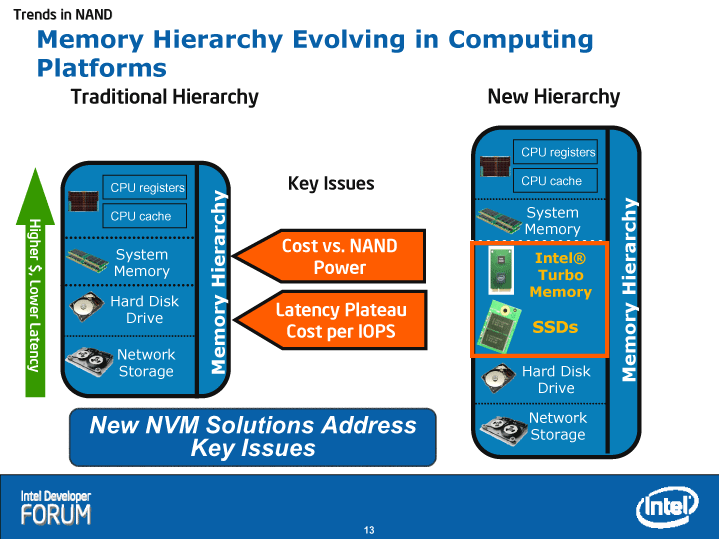 |
| コンピュータプラットフォームにおけるメモリ階層の進化 ※別ウィンドウで開きます |
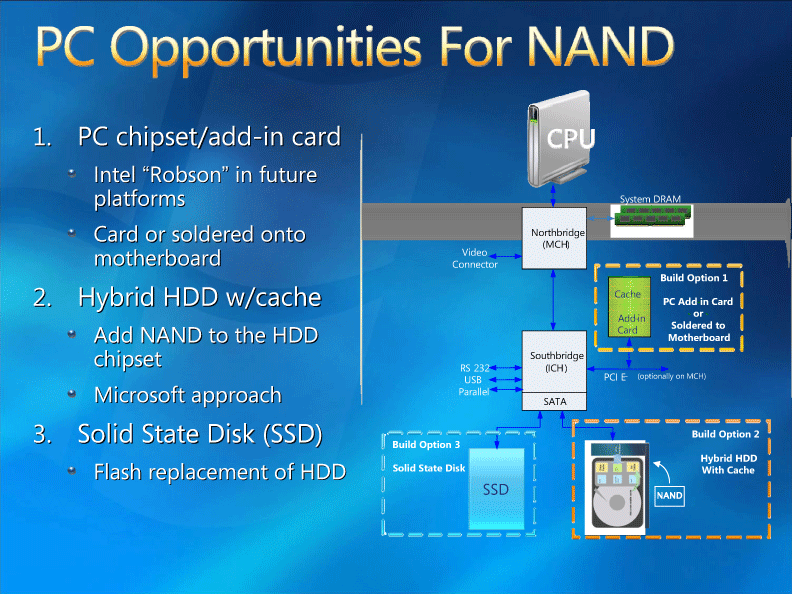 |
| PCへのNAND導入 ※別ウィンドウで開きます |
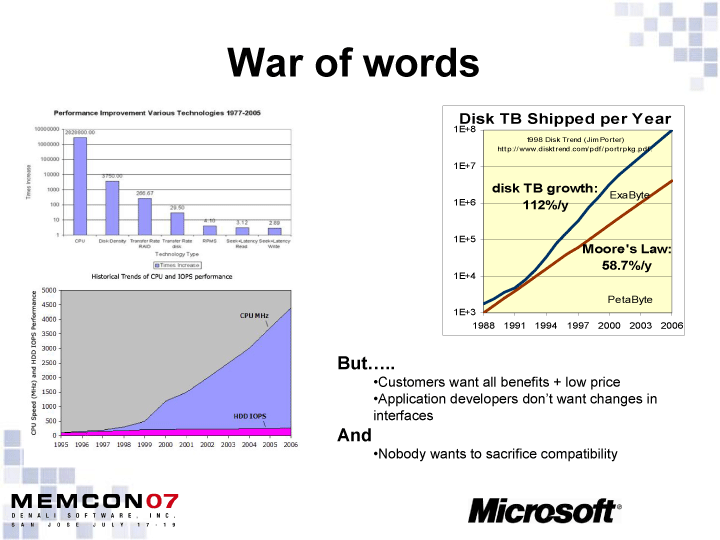
Microsoftなどがメモリ階層を改革しようとしている背景には、いくつかの理由がある。(1)CPUとディスクのI/Oパフォーマンスギャップ、(2)ストレージ側のシーケンシャルアクセスとランダムアクセスのパフォーマンスギャップ、(3)クライアントWindowsの64-bit化の遅れ、(4)ストレージ上のデータのホット部分とコールド部分への二極化。これらは、Microsoftでストレージアーキテクチャを担当するVlad Sadovsky氏(Software Storage Architect, Microsoft)が、7月に開催されたメモリとストレージのカンファレンス「MEMCON07 San Jose」で示したものだ。
 |
| ストレージの巨大化と要望 ※別ウィンドウで開きます |
 |
| 高速化への制約 ※別ウィンドウで開きます |
 |
| メモリレーンの進化 ※別ウィンドウで開きます |
半導体製品であるCPUのパフォーマンスは指数関数的に向上して行くのに、機械部品であるディスクストレージのパフォーマンスはなかなか上がらない。また、ディスクストレージはシーケンシャルな読み書きは高速になっているが、ランダムな読み書き性能はほとんど向上しない。つまり、ディスクドライブはCPUから見ると、より低速でアクセスするのに遠いデバイスになりつつある。特にランダムアクセスではその傾向が強まっている。
さらに、クライアントWindowsは64-bit移行がMicrosoftの思惑より遅れたため、メインメモリ搭載量には実質的に3GBの制約が課せられている。そのため、今後、一般ユーザ向けのメインストリーム&バリューPCでは、メインメモリの量を増やし続けて、ディスクアクセスを減らすことが難しくなる。
一方、ディスク上のデータは、頻繁に読み書きされるホットな小部分と、連続的なアクセスが時たま行なわれるだけのコールドな大部分に分離しつつある。そのため、ホットスポットをキャッシュすることで、アプリケーションを高速化するチャンスが大きくなっている。
MicrosoftとIntelなどメモリベンダは、最近のカンファレンスで、こうした技術背景とPCのメモリ&ストレージアーキテクチャの変革の構想を明らかにし始めている。
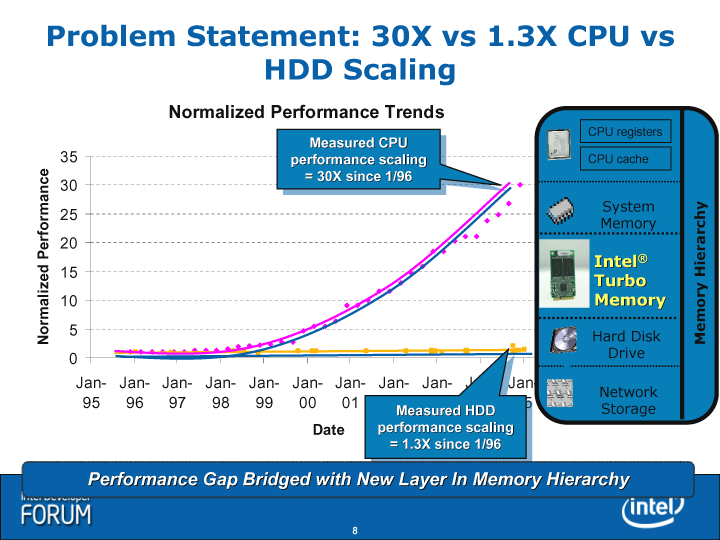 |
| CPUおよびHDD高速化の比較図 ※別ウィンドウで開きます |
●PCの進化とともに厚くなるPCのメモリ階層
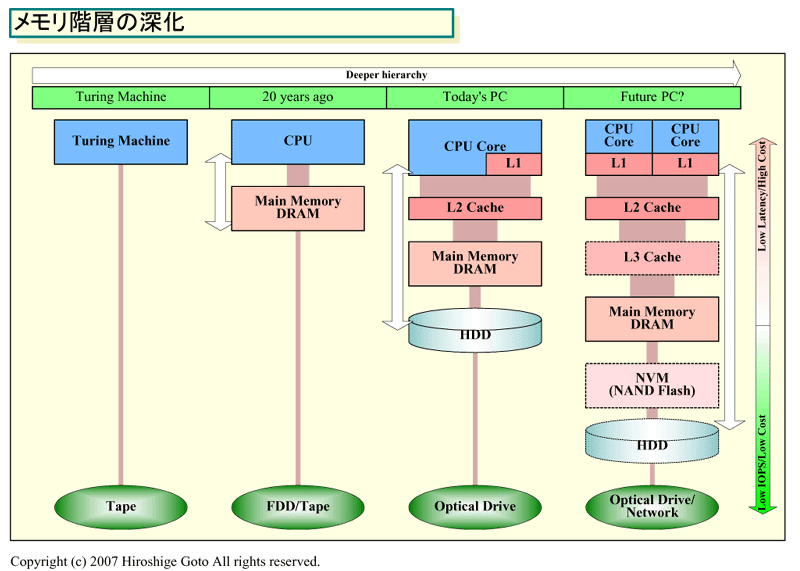
現代のデジタルコンピュータの基本的なアイデアの元となっている「チューリングマシン」では、テープと仮定した単一のメモリ装置に対して、計算機械のヘッドが読み書きを行なう。作業領域としてのメインメモリと、データとプログラムの保存域としてのストレージといった分離は考えられていなかった。思考実験であるチューリングマシンでは、現実的なパフォーマンスを考慮する必要がなかったためだ。逆を言えば、今のPC&サーバーで当たり前のメモリとストレージの分離と階層化は、電子コンピュータのパフォーマンスの現実的な必要性から産まれてきたと言える。
実際、PCの歴史の初期を振り返ると、メモリ&ストレージの階層は浅かった。CPUの下にDRAMメインメモリがあり、その下にテープやフロッピィディスク(FDD)といったストレージが存在するだけだった。その時点では、CPUが非常に低速だったため、浅いメモリ&ストレージ階層でもまかなえた。
まず、当時のDRAMメインメモリは、CPUに対して相対的に高速だったため、シンプルなメモリ階層で性能を発揮できた。ストレージは極めて低速だったが、CPUのパフォーマンスが低く、プログラムやデータのサイズが小さかったため、それでも対応ができた。小サイズのプログラムとデータを、いったんメモリに取り込んでしまえば、低レイテンシでアクセスできたからだ。
しかし、時とともにCPUパフォーマンスが上がり、CPUとメモリやストレージの間のギャップが開いていった。ストレージやメモリにアクセスして、CPUにデータをロードするまでの時間が同じでも、CPUが高速になれば、CPU内部での待ちサイクルが多くなる。そこで、ストレージは低速なテープやフロッピィディスク(FDD)からハードディスク(HDD)へと切り替えられ、CPU側にはL2キャッシュメモリSRAMが搭載されるようになった。
 |
| 【図】メモリ階層の深化 ※別ウィンドウで開きます |
●相対的にどんどん遠くなるメモリとディスク
こうして見ると、CPUパフォーマンスの向上とともに、メモリ階層がどんどん深まっていることがわかる。指数関数的にパフォーマンスが向上するCPUから見ると、パフォーマンスの向上がずっと遅いメモリとストレージはどんどん遠くなりつつある。そのため、ギャップの間に、新しいメモリやストレージを挟み込んで、より短時間でアクセスできるようにして来た。PCの歴史は、メモリ階層を深めることで、パフォーマンス向上を維持する歴史だったと言ってもいい。そして、それは今も続いている。
現在のCPUの場合、いったんCPUから外部のDRAMメインメモリにアクセスすると数百サイクルのレイテンシが生じ、CPUからHDDにアクセスすると数十万サイクル以上のレイテンシが生じてしまう。CPUにとって、メモリとディスクは、相対的に、以前のPCよりさらに低速なデバイスとなっている。
キャッシュの意味は、コードとデータの局所性(Locality)を利用することで、このギャップを埋めることにある。プログラムやデータの中で頻繁に使われる(ホットな)部分を、よりCPUに近い側(キャッシュやメインメモリ)に持って来ることで、CPUのストールを減らしてパフォーマンスを維持する。キャッシュは、より低レイテンシであるため、CPUからのアクセスが近くなる。
現在のCPUは、動作周波数は上げずにCPUコア数を増やす方向に向かっているが、これもCPUとメモリやストレージのギャップ問題を深刻化させる。CPUコアの数が増えると、それだけメモリやストレージに対するアクセスが増える。GPUコアなどの統合によるヘテロジニアス(Heterogeneous:異種混合)マルチコア化が始まると、ますますその傾向が強くなる。CPUの演算パフォーマンスが上がり、より多くのデータが必要になるためだ。
●CPUとDRAMメインメモリの間はキャッシュの階層を厚く
CPUサイドを見ると、次のステップでは、ハイエンドPC向けCPUでL3キャッシュを載せる方向へと向かっている。キャッシュを大容量化するとアクセスレイテンシが増えるため、キャッシュ階層を深める必要が生じるからだ。L2を大容量にしてレイテンシを伸ばすよりも、アクセスが高速で中容量のL2キャッシュと、アクセスは中速だがより大容量のL3キャッシュの組み合わせが合理的な解となる。
もっとも、本来ならソフトウェア側で、ロカリティをうまく利用するアルゴリズムへと切り替えて行けばCPU側のローカルメモリの肥大化はある程度抑えられるはずだ。しかし、MicrosoftのSadovsky氏は、PCではソフトウェア側を変えることは難しいため、ソフトウェアの再設計を最小にするようにハードを作らなければいけないと説明する。こうした事情から、CPUとメインメモリの間のキャッシュはますます厚みを増しつつある。
もちろん、そこにかかるコストも上昇している。現在のPC向けメインストリームCPUは、ダイ(半導体本体)の約半分がキャッシュSRAMとなっている。それだけメモリ階層にはコストがかかっている。また、CPU外部とのI/Oも広帯域化するに従って、CPUのダイ(半導体本体)上に占めるI/O部分も増している。現在のPC向けCPUでは、純粋にCPUコアが占める面積は1/3から1/4に減少し、そのほかの面積はSRAMとI/Oとなっている。
「CPUの中で非コアが占める部分はどんどん増大している。増えるCPUコアにフィードするためには、メモリ階層を深くし、I/Oデータ転送レートを上げなければならないからだ。より多くのコアを載せると、コア群とメモリの間のデータレートのギャップが開くため、それを補間する必要が出てくる」とAMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer(CTO))は語る。
 |
| エンタープライズ系で利用されるSSD ※別ウィンドウで開きます |
●CPUパフォーマンスの向上を維持するためのフラッシュ
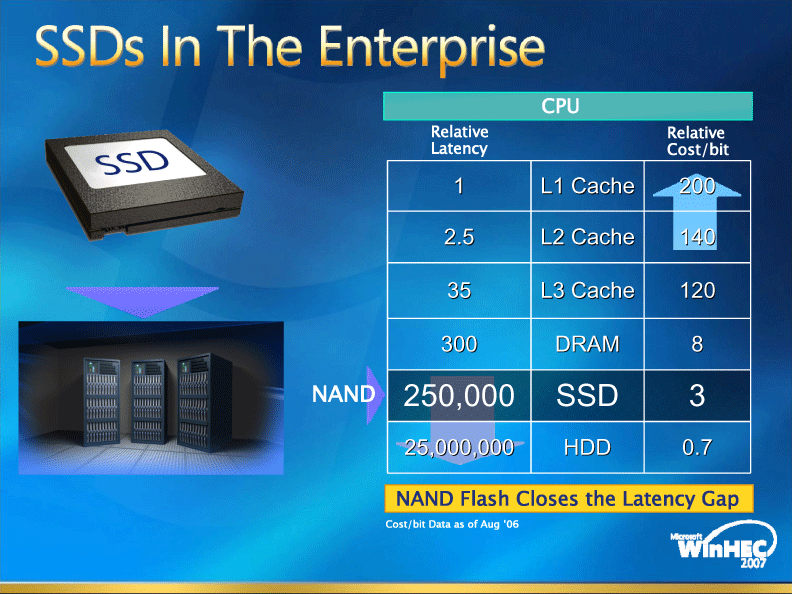
CPU-メモリ間のギャップをキャッシュSRAMで埋めるだけでは不十分で、メモリ-ストレージ間のギャップも埋める必要がある。それが、フラッシュメモリのPCへの搭載だ。キャッシュ階層を増やすことでメインメモリアクセスを減らすのと同様に、フラッシュを挟むことでディスクアクセスを減らす。あるいは、HDDを完全にフラッシュベースのSSD(Solid State Drive)に置き換える。
 |
| Solid state storageの信頼性 ※別ウィンドウで開きます |
プラットフォームベンダにとって、遠くなる一方のHDDをそのまま放置しておくと、エンドユーザーの体感パフォーマンスが上がらない。メモリ-ストレージがボトルネックとなり、CPU性能を上げてもユーザーが体感できなくなってしまう。これはCPUベンダーにとって切実な問題だ。IntelのCTOであるJustin R. Rattner(ジャスティン・R・ラトナー)氏(Senior Fellow, Corporate Technology Group/CTO, Intel)は昨年(2006年)11月に次のように語っていた。
「ユーザーエクスペリエンスパフォーマンスは、基本的にはI/Oパフォーマンスに依存する。ベンチマークテストでは小さなプログラムセットが、全てキャッシュに入ってしまうため、非現実的なパフォーマンス測定になる。プログラムが決してキャッシュミスせず、決してI/Oアクセスしないことを期待する。IntelもAMDも、そうした人工的な測定によるパフォーマンスを上げるために苦闘して来た。
ところが、ユーザードリブンパフォーマンスは、CPUよりもI/Oパフォーマンスに依ってしまう。例えば、Core 2 DuoとNehalem(ネハーレン:Intelの次期CPU)の違いよりも、Robson(Intel Turbo Memory)があるかないかの方が、ユーザーはパフォーマンスの違いを感じるだろう(笑)。そのため、我々はCPUだけでなく、I/O階層をどんどん改良して、より高速にして行かなければならない」
I/O側がボトルネックになると、CPU内部のパフォーマンスをいくら上げても、PCエンドユーザーの体感性能が上がらなくなってしまう。だから、Intelは連綿とメモリ階層を深めるなどのアプローチで、CPUとメモリ&ストレージのギャップを埋めてきた。フラッシュメモリの搭載は、IntelのNANDフラッシュメモリ事業(Micron Technologyとの合弁)のためというより、むしろCPUのためというわけだ。
こうして眺めると、フラッシュなどNVMを取り込むことは、PCのアーキテクチャの自然な流れのように見える。これまでにも繰り返された、メモリ&ストレージ階層の深化の、次のステップかもしれない。そのシナリオ通りになれば、PCにHDDやキャッシュが入ったように、次はNVMが標準として入ることになる。
しかし、その点について、MicrosoftやIntelの歯切れはあまりよくない。彼らの説明を聞く限り、メモリ階層の深化が必要というメッセージが伝わってくる。だが、そう言いつつ、MicrosoftもIntelも、全てのPCへのフラッシュの標準搭載に向けて、まだ強力には動いていない。その背景には、現在のNVMの理想と現実のギャップがある。次回はそのギャップについて説明したい。
□関連記事
【8月21日】【海外】Intelが再びRambusのメモリを採用か?
http://pc.watch.impress.co.jp/docs/2007/0821/kaigai381.htm
【8月10日】【海外】6.4Gbpsを狙う次々世代メモリ「NGM Diff」
http://pc.watch.impress.co.jp/docs/2007/0810/kaigai380.htm
【8月7日】【海外】岐路にさしかかるDDR3モジュール
http://pc.watch.impress.co.jp/docs/2007/0807/kaigai379.htm
【8月6日】【海外】3.2Gbpsを狙う次々世代メモリ「DDR4」
http://pc.watch.impress.co.jp/docs/2007/0806/kaigai378.htm
(2007年9月4日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 [email protected] ご質問に対して、個別にご回答はいたしません
Copyright (c) 2007 Impress Watch Corporation, an Impress Group company. All rights reserved.