 |


■後藤弘茂のWeekly海外ニュース■拡大が進むAMDのコプロセッサ構想 |
●ステップを踏んで進むAMDのコプロセッサ構想
 |
| AMDのPhil Hester(フィル・へスター)氏 |
AMDは、特定ワークロードの処理を高速化する「コプロセッサ(アクセラレータ)」の統合を真剣に考えている。コプロセッサについては、2005年から言及していたが、ここへ来て明確な道程を示し始めた。AMDのPhil Hester(フィル・へスター)氏(Senior Vice President & Chief Technology Officer)は、5月に日本で開かれたラウンドテーブルでコプロセッサについて次のように説明した。
「現時点で、2つの方法でコプロセッサを搭載できる。1つは、PCI ExpressなどI/Oバスを使う方法で、これは簡単に実現できる。もう1つは、『Coherent HyperTransport』を使う方法で、より高パフォーマンスは得られるが、技術的な難度も高い。我々は、こうした、標準I/OやCoherent HyperTransportを使う方法で、他の人々が容易に専門化したコプロセッサを作ることができるようにすることを発表するつもりだ。
さらに将来を考えると、次のステップでは、マルチチップモジュールを考えることができるかもしれない。マルチチップモジュールで、スタンダードなCPUとコプロセッサを一緒に納める。
その先では、CPU(のダイ)にコプロセッサを実際に統合することも、理にかなう時が来るかもしれない。ただし、その場合のチャレンジは、(CPUを買う)誰もがコプロセッサに対しても(代金を)払わなければならないことだ」
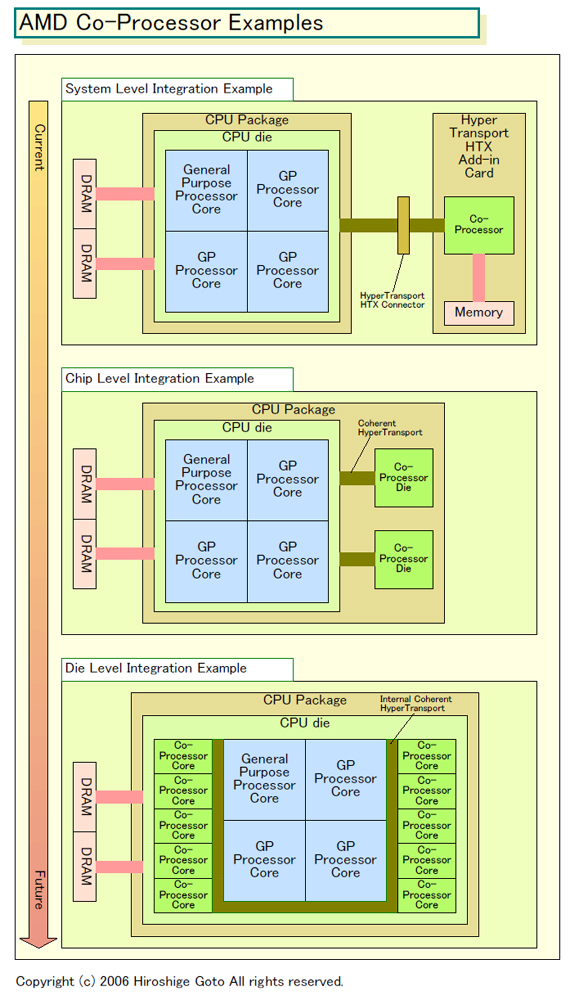
AMDのコプロセッサ構想は、大きく4ステップに分けられる。下が推定したコプロセッサ搭載例だ。
 |
| AMD Co-Processor Examples (別ウィンドウで開きます) PDF版はこちら |
●拡張ボードでの搭載からCPUへの統合まで
ファーストステップは、PCI ExpressやHyperTransport HTX(HyperTransportの拡張インターフェイス仕様)を使ったドーターボードによるシステムレベルでのコプロセッサの搭載。この場合は、GPUのように単純に処理を投げる形でコプロセッサを利用することになる。
次のステップはOpteronのCoherent HyperTransportリンクを使うもので、CPUとのメモリコヒーレンシを取ることで、より緊密なコプロセッシングを可能にする。一般的な意味でのコプロセッサはこの段階からだろう。これら2ステップでは、AMDはサードパーティによるコプロセッサ開発を強く期待しているようだ。
 |
| AMDのDirk Meyer(ダーク・メイヤー)氏 |
ちなみに、クアッドコア版K8に実装されるHyperTransportリンクは、従来のOpteronの3リンクより「多くなる」(Dirk Meyer氏, President & COO, AMD)という。リンク数を増やすのは、32プロセッサまでのマルチプロセッサ構成を容易にするためと、コプロセッサのサポートのためという、2つの目的があると推定される。
さらに、その延長で、マルチチップモジュールにCPUダイ(半導体本体)とコプロセッサダイ(半導体本体)を載せて接続するアプローチもAMDは視野に入れている。この場合も、Coherent HyperTransportを使うことを想定しているという。
マルチチップモジュールを使う場合は、コストが増すが、コプロセッサ搭載を必要な市場向け製品だけに限定することが容易になる。例えば、サーバー版パッケージはコプロセッサを載せ、デスクトップ版はコプロセッサをなしにするといった作り分けが容易にできる。そのため、コプロセッサのニーズが限定されている間は、この方式が採られるかもしれない。
しかし、最終的にはCPUダイへのコプロセッサの統合も検討しているようだ。汎用(General Purpose)CPUコアと、コプロセッサを、1個のダイに載せてしまう。今風の言い方をすれば“ヘテロジニアス(Heterogeneous:異種混合)”型マルチコアCPUとなる。上の図は汎用CPUコアをコプロセッサコアが取り巻くように描いているが、「取り巻くというのは比喩的な表現で、必ずしも現実の実装が取り巻くようになるとは限らない」(Hester氏)という。内部は高速バスで接続し、メモリはCPUに接続された物理メモリを共有する。
AMDの発表会後の懇親会で、Hester氏は次のようにも語っていた。
「チップ内部でも、本質的にはCoherent Hypertransportリンクで結ぶ。別なビューで見ると、メモリコントローラがクロスバースイッチに接続され、クロスバーにコプロセッサが接続されるような形だ」
プロトコル的にはCoherent Hypertransportを使うという意味に取れる。オフチップ場合の設計との共通性を持たせるためかもしれない。
●x87浮動小数点コプロセッサの統合が示す将来像
CPUベンダーは、それほど多くのチップのバリエーションを持たない。通常、数種類の設計で、モバイルからサーバーまで全市場をカバーする。そのため、CPUへコプロセッサをいったん統合してしまうと、多くのユーザーがそのためにコストを払わなければならなくなる。例えば、サーバーCPUにコプロセッサを統合すると、ハイエンドデスクトップCPUのユーザーもコプロセッサに払わなければならなくなる。コプロセッサを統合する分、搭載できる汎用CPUコアの数は減るわけで、AMDとしてはニーズが十分に育たない限りCPUへの統合は難しい。
Hester氏は次のようにビジョンを語る。
「我々は、まだ、誰もがシリコンに支払っていいと思えるほど十分に普遍化した特定のワークロードを見いだしていない。しかし、業界の歴史的な例が示している。それは、386と387浮動小数点演算コプロセッサの統合(486)だ。我々は、将来のどこかの時点で、x87浮動小数点演算のワークロードのように、誰もが(シリコン統合に)納得するワークロードが出てくると信じている。
そのため、我々は、現時点では、新しい特定ワークロードをサポートできる、よりよいフレームワークを用意しようとしている。人々が、コプロセッサを開発して簡単にアタッチすることができるようにし、将来、もっとタイトな統合もできるように道を引こうとしている」
つまり、現状ではどのワークロードがユーザーにとって“必須”になるかわからない。そのため、いきなりCPUへの統合というステップへは進まない。その代わり、コプロセッサを載せるためのフレームワークをAMDが用意して、コプロセッサを試行錯誤させていく。その昔、浮動小数点演算コプロセッサが花開いた時代を思い起こさせるような構想だ。その上で、最終的に必須となったコプロセッサを、必要ならCPUへと取り込む道へと進むというアプローチのようだ。
●N+1で汎用プロセッサにコプロセッサを追加する
また、Hester氏は汎用(General Purpose)コンピューティング向けのプロセッサコアをパワフルに保つことの重要性も強調する。コプロセッサの導入によって、メインとなる汎用プロセッサの性能を落とすことは考えない。
「重要なのは、今日、データセンターで走っている汎用(General Purpose)のワークロードは、決してなくならないということだ。そのため、我々は顧客に『N+1』という説明をしている。つまり、汎用ワークロードを走らせるためにN個のプロセッサを持っていたとする。その上で、さらに、特殊なワークロードを扱うために、追加のプロセッサを導入するというシナリオだ。
汎用アプリケーションを走らせるためには、AMD64のようなパワフルな汎用設計(のCPUコア)が今後も必要だ。それに加えて、特殊化したアクセラレータを加えれば、特定ワークロードが高速化され、効率が上がる。ところが、もし(CPU全体を)特定ワークロードに最適化し過ぎてしまうと、汎用ワークロードのパフォーマンスが落ちてしまう。
だから、我々は、正しいアプローチは効率的な汎用プロセッサに、追加のアクセラレータを加えることができるようにすることだと確信している」
こうした点では、メインの汎用プロセッサコアは単純化し、演算用のサブプロセッサ「SPE(Synergistic Processor Element)」を多数搭載することにフォーカスした「Cell」とは考え方が大きく異なる。
「我々のワークロードは汎用コンピューティングが主流だが、ゲームプラットフォームでは異なるストーリーとなる。Cellはそのためのプロセッサだが、汎用コンピューティングでは難しいだろう。ただし、潜在的には、(強力な)汎用プロセッサにCell(のSPE)をアタッチすることもできると考えている。特定のワークロードはCell(のSPE)で走らせ、汎用ワークロードは強力なままのプロセッサで走らせるといった形だ」とHester氏は懇談会で語った。
●Java、XML、ベクタ、セキュリティの4分野をアクセラレート
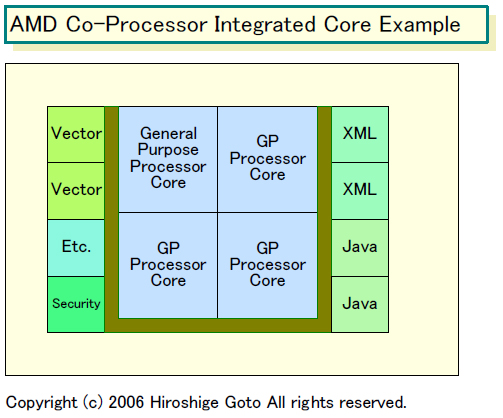
AMDはどのようなコプロセッサを考えているのか。Hester氏は次の4分野を挙げる。
「今日の時点では、4つの例を挙げることができる。Java、XML、ベクタ浮動小数点演算、セキュリティ暗号化の4分野だ。この4つは、目覚ましいパフォーマンス向上を期待できる、いい例だと考えている」
 |
| AMD Co-Processor Examples (別ウィンドウで開きます) PDF版はこちら |
Javaバイトコードをダイレクトに実行したり、XMLメッセージ処理をハードワイヤドで高速化する、あるいはベクタ型浮動小数点演算に特化したり、セキュリティ暗号化処理をアクセラレートする。AMDが、第1段階として想定しているのは、こうした分野だ。
Hester氏のインタビューから浮かび上がってくるのは、現時点では、AMDがサーバーコンピューティング寄りのコプロセッサ考え方をしていることだ。サーバー向けが歴然としているJavaやXMLのアクセラレータはもちろん、ベクタ浮動小数点演算についても、マルチメディア処理というより科学技術演算系のハイパフォーマンスコンピューティングのニーズを意識している。
例えば、Cellの演算プロセッサコア「SPE(Synergistic Processor Element)」が32bit単精度浮動小数点演算に特化している点について「Cellが目指しているマルチメディア処理では、これはいい。しかし、全てのワークロードに当てはめられるわけではない」とHester氏は指摘する。AMDが考えているのは、汎用向けの倍精度またはそれ以上の精度のベクタ型コプロセッサのようだ。これは、以前読者からも指摘があったが、科学技術演算系でのニーズにAMDが対応しようとしている。
こうした対応は、サーバーCPUにフォーカスを移している現在のAMDの戦略とCPU開発の方向性を反映している。また、コプロセッサをシステムにアドオンするところからスタートするなら、これは当然のアプローチとも言えるかもしれない。
「私は、将来は、先ほど挙げた4分野以外のワークロードも重要になると信じている。しかし、我々は、そうした将来のワークロードを定義しようとは、あまり思わない。その代わり、他の人々に特殊化した(コプロセッサの)技術を開発できるようにすることで、エコシステムとエコノミースケールの利点を得られるようにしようとしている。彼らは、ゼロから(専門化した)システムを作る代わりに、追加のピース(=コプロセッサ)を設計すれば済むようになる」
つまり、サードパーティがコプロセッサを開発し、それが花開いてビジネスが成り立つようになり、エコシステムが形成され、ボリュームが出荷されるようになり安価に入手できるようになる。そうしたサイクルを考えているようだ。また、現在、専用システムをゼロから開発しているようなベンダーが、AMDプラットフォーム向けにコプロセッサを開発することで、より安価に専用化したハードを実現できるようになる。
●IntelのMany-coreと明確に異なるアプローチ
AMDのコプロセッサ構想では、一見してわかる通り、コプロセッサ側の命令セットのx86との共通性は考えていない。
「同じ命令セットアーキテクチャである必要は一切ない。Javaコードに特化したり、特定のベクタ浮動小数点演算に向かうなら、当然、命令セットは(x86)とは大きく異なるだろう」とHester氏は語る。
JavaやXMLは、すでに抽象化されたコードをソフトウェア処理しているものを、ハードウェアベースに移すことになる。つまり、ソフトウェア側の抽象化に合わせて、ハードウェアを変化させるという流れにある。
これは、Intelのヘテロジニアスマルチコア構想である「Many-core(メニイコア)」とは大きく異なる。2005年11月に、Intelの研究部門を統括するJustin R. Rattner(ジャスティン・R・ラトナー)氏(Intel Senior Fellow, Director, Corporate Technology Group)は、Many-core構想の一部を明かしている。その時は、Rattner氏は、プロセッサのマイクロアーキテクチャはヘテロジニアス型だが、命令セットアーキテクチャでは“ホモジニアス(Homogeneous:均質)”なアーキテクチャを考えていると説明していた。命令セットは同じx86系だが、シングルスレッド性能を追求する大型のCPUコアと、マルチスレッド性能を重視する小型のCPUコアを搭載すると考えられる。
また、Rattner氏は3月のIntel Developer Forum(IDF)時には、AMDのコプロセッサとMany-coreを比較。IntelのMany-coreで構想しているサブプロセッサコアは、AMDのように特定用途に特化するのではなく、より汎用寄りだと語っていた。特定用途に特化したコプロセッサの方が原理的には効率はよくなるが、Intelはそれより汎用性を取ろうとしていると想定される。
また、こうした違いの理由の1つは、IntelがCPUへの統合を前提に考えているためとも推定される。CPUへいきなり統合するなら、特殊化したコプロセッサよりも、汎用性の強いサブプロセッサを載せて、使い回しが利くようにしようという発想かもしれない。IntelはAMDのようなコプロセッサをアドオンするアプローチはあまり考慮してはおらず、CPUへの統合へと急いでいるように見える。
「我々は、人々がコプロセッサを開発できるようにしようとしている。それに対して、Intelは彼ら自身で(サブプロセッサ開発を)やろうとしている。我々は、Coherent HyperTransportバスで、他の人々がコプロセッサを接続できるようにしようとしている。しかし、Intelは彼らのFSB(Front Side Bus)に、他の人々が(コプロセッサを)接続するのは好まないだろう。フィロソフィが異なる」とHester氏は言う。
AMDとIntelでは、サブプロセッサで特定のワークロードをアクセラレートしようという発想は似ているが、アプローチとフィロソフィは全く異なる。
□関連記事
【5月8日】DRC、Opteronソケットに実装するFPGAコプロセッサ
http://pc.watch.impress.co.jp/docs/2006/0508/drc.htm
【5月3日】【海外】クアッドコアCPUを2段階投入するAMDのロードマップ
http://pc.watch.impress.co.jp/docs/2006/0503/kaigai267.htm
【2月6日】【海外】IBMとの共同開発で変わるAMDのCPU
http://pc.watch.impress.co.jp/docs/2006/0206/kaigai239.htm
【1月30日】【海外】ヘテロジニアスマルチコアも視野に入れたAMD
http://pc.watch.impress.co.jp/docs/2006/0130/kaigai237.htm
(2006年6月1日)
[Reported by 後藤 弘茂(Hiroshige Goto)]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp ご質問に対して、個別にご回答はいたしません
Copyright (c) 2006 Impress Watch Corporation, an Impress Group company. All rights reserved.