
|
Spring Processor Forum 2006レポート
最終回:特色のあるプロセッサたち
 |
会期:5月15日~17日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
さて、そろそろSPF2006のレポートも終わりにしたいと思う。ということで、最後は恒例の「妙なもの」を色々とご紹介したい。
●Silicon Hive Moustique-IC2
 |
| 【写真01】Silicon Hive CTOのJeroen Leijten氏 |
Silicon Hiveの製品をレポートするのはこれが初めてだが、実はSPF/FPFなどでは割と頻繁に登場するベンダーである。具体的には
MPF2003:A Massively Parallel Reconfigurable ULIW Core
EPF2004:The HiveCC Compiler for Massively Parallel ULIW Cores
SPF2005:The Avispa Family of ULIW Parallel-Processing Cores for Multimedia and Communications
といった具合に、毎年1回は必ず何か発表している。で、これらの講演タイトルを見てもわかるとおり、ULIW(Ultra Long Instruction Word:VLIWよりもさらに命令長が長いということで同社が作った造語)のプロセッサとこの周辺技術を追いつづけている会社である。実はこのSilicon Hiveは前回レポートしたHandshake Solution同様、Philipsの事業部門の1つであり、だからこそこんな特殊なマーケットを追いつづけていられる、ともいえるのだが。
さてそのSilicon Hive、従来はULIWベースの汎用……というとやや語弊が残る気がする……プロセッサとそれ用のコンパイラ、あるいはややマルチメディア系に特化したプロセッサといった、割と応用範囲を広く取るアプローチで製品開発を行なっていたが、「何にでも使える」はしばしば「何にもできない」と表裏一体の関係にあるわけで、一応いくつかの採用例はアナウンスされているものの、やはりもう少し絞り込まないと難しいと判断したらしい。で、どういうわけかいきなりカメラのコントローラ分野に参入することにしたようだ。
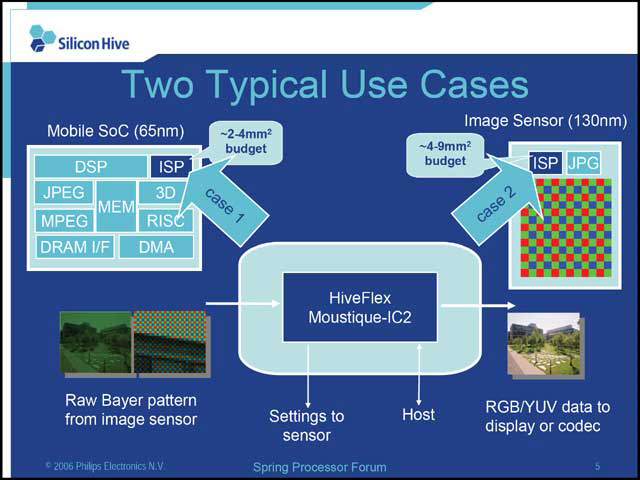
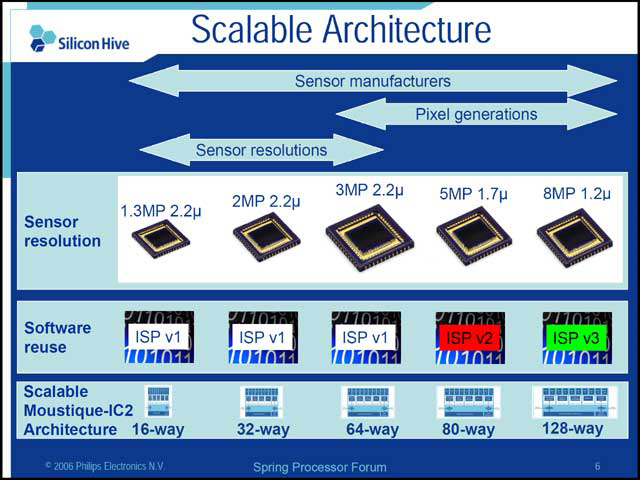
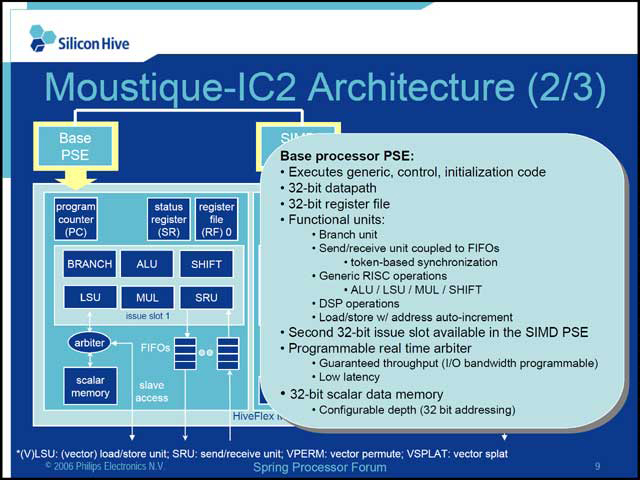
今回発表された「Moustique-IC2」は、カメラ専用プロセッサとして、汎用カメラと携帯用カメラの2つをマーケットとして開発された(写真02)。当初は3Mpixel程度のCCDまでカバーするが、コアを拡張することで8MPixel程度までスケーラブルに対応できる(写真03)。内部的にはBase processoer PSEと呼ばれる汎用プロセッサに近い構成(写真04)と、SIMD processor PSEと呼ばれるSIMDエンジン(写真05)からなり、このSIMD部をスケーラブルに拡張することでピクセル数の増加に対応しようという目論見(写真06)だ。
 |
 |
 |
| 【写真02】同社はあくまでIPを売る会社であり、従ってこれを搭載したディスクリートチップではなく、あくまでカメラなり携帯用のSoCへの採用を見込んでいる | 【写真03】最小構成は4wayだが、概ね16way程度あれば1.3Mpixelクラスには対応できるとのこと。ISPに関しては後述 | 【写真04】通常の演算部は比較的シンプルな構成。詳細は明らかになってないが、別スライドによればパイプラインは“Shallow 3(+) pipeline”とあり、主に指しているのはSIMDの方だろうが、こちらもそれほど深いパイプラインではないだろう |
 |
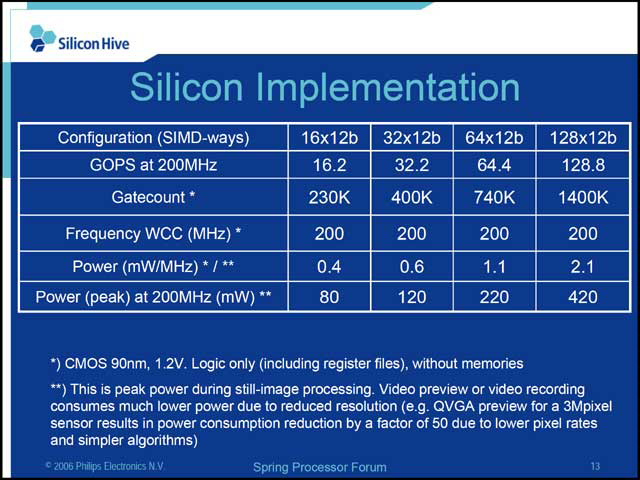 |
| 【写真05】こちらが問題のSIMD側。4つのIssue slotが用意される。8wayだと各々2つ、16wayだと各々4つということなのだろうか? way数が増えた際にload/storeが間に合うのか、ちょっと心配だ | 【写真06】SIMD構成と性能、消費電力の比較。TSMCの90nmプロセスの場合、Standardでおおよそ420KGates/平方mmなので、128WのケースでSIMD部のダイ面積は3.3平方mmというところか。もっとも周辺回路も必要だろうから、4平方mmではちょっとつらく、5平方mm未満あたりか |
この手のプロセッサの場合、画像の「味付け」をどう調整するか、が割とポイントになるわけだが、これに関してはフランスのDxO Labsと共同開発を行なっており、同社のDxO ISPをすでにMoustique-IC2に搭載しており、「味付け」は半ばこちら任せといった感じになっている(写真08)。
 |
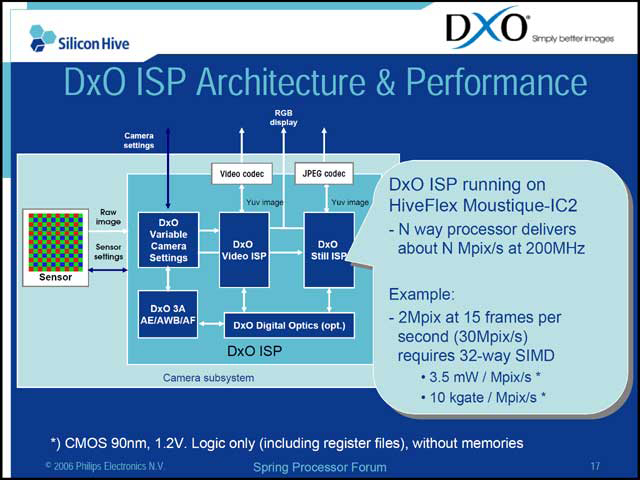 |
| 【写真07】DxO ISPの効果を示したもの。比較対象がNokia 6630やニコンのCOOLPIX 2200というあたりが、ポジションを物語っている | 【写真08】DxO ISPの動作概念図。DxO ISPそのものはソフトウェアであって、これをうまくMoustique-IC2にポーティングしたという話。2MpixelのCCDで15fpsの動画を処理する場合、32way構成が必要というあたり、決して軽い処理とは言えないだろう |
今回どこまでSilicon Hiveがカメラにフォーカスしているかというと、非常に怪しい感じである。ただ、ただのVLIWプロセッサですら適用範囲が少なくて困っている現状では、ULIWともなるとさらに適用範囲が狭まり、待っていても誰も使ってくれないので、こちらから提案する形の一例、といった見方が一番妥当なのだろう。
ちなみに「ローエンドのカメラや携帯ベンダーはそもそも自前でSoCなどを作れたりしないし、力のあるカメラメーカーは自社でImage Processorを持っている。ディスクリートではNewcore Techのようなベンダーが既に汎用Image Processorを提供しているという現状で、誰がこれを使うのか?」と意地悪な質問をしたところ、一番有力なのは携帯向けのチップセットを提供しようとしているベンダー、という答えが返ってきた。しかしそうなると、Freescale、Samsung、TIなどといった、割と限られたところになりそうな気もするのだが、Silicon Hive自体がPhilipsの事業会社であることを考えると、一番有力なのはPhilips Semiconductorなのかもしれない。
●Connex Technology CA1024
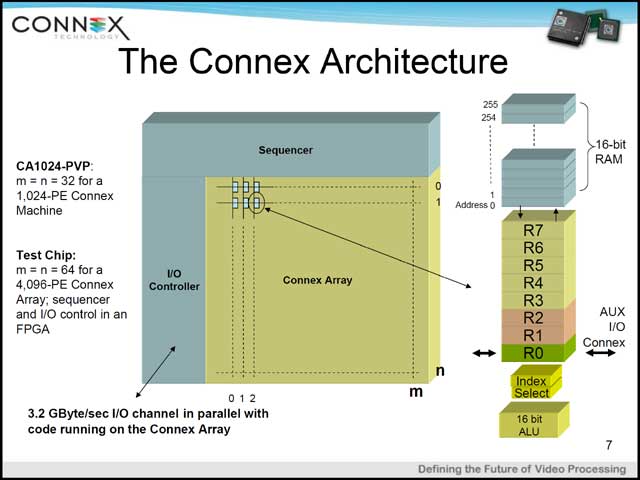
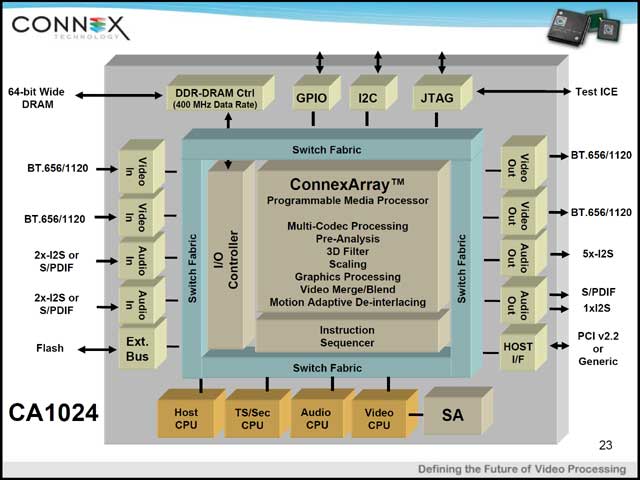
Array Processorという発想には、ある種のArchitectの関心を引いて止まない何らかの魅力があるらしい。古くはNeoMagicが発表した「MiMagic 6」などはその代表例だと思うが、Connex Technology CA1024もこれの一種。HDTVのソリューション(まずはMPEG-2やH.264のデコード、将来はエンコード)を最初のターゲットとしたというプロセッサは、32×32で1,024個のCellを並べ、周囲にI/OとSequencerを配した構成である(写真10)。面白いのは、各々のCellが自前でRAMも持っていることで、これによりArray全体での処理のスループットを上げることができるようになっている(写真11)。
 |
 |
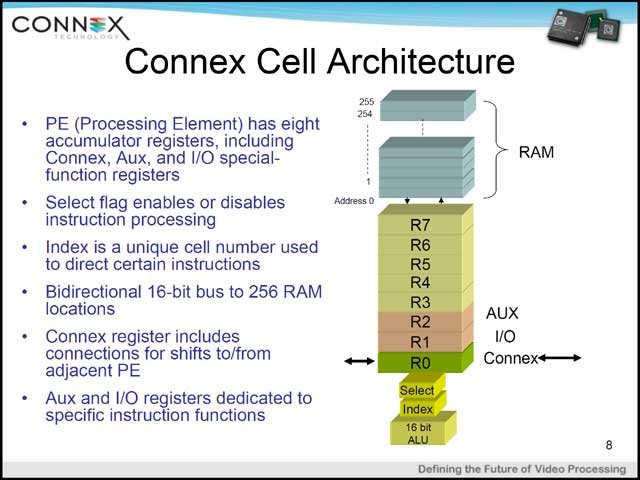 |
| 【写真09】Gheorghe Stefan氏(Chief Scientist, Connex Technology) | 【写真10】テストチップでは64×64で4,096個のCellを集積したものもあるそうだ。Sequencerについては後述 | 【写真11】各Cellが自身のRAMを持っており、このRAMの各エレメント間での演算が可能 |
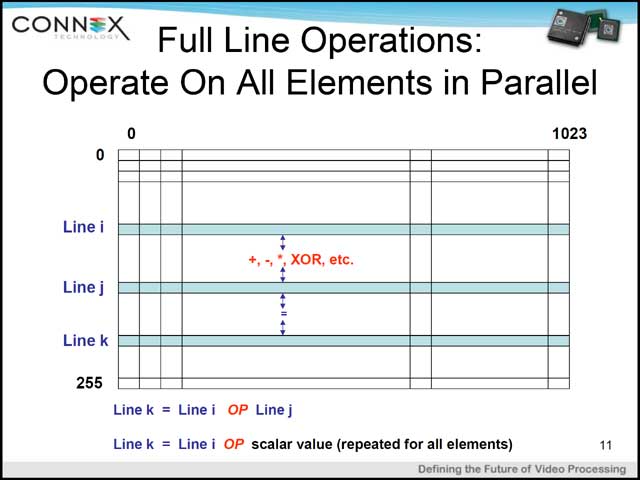
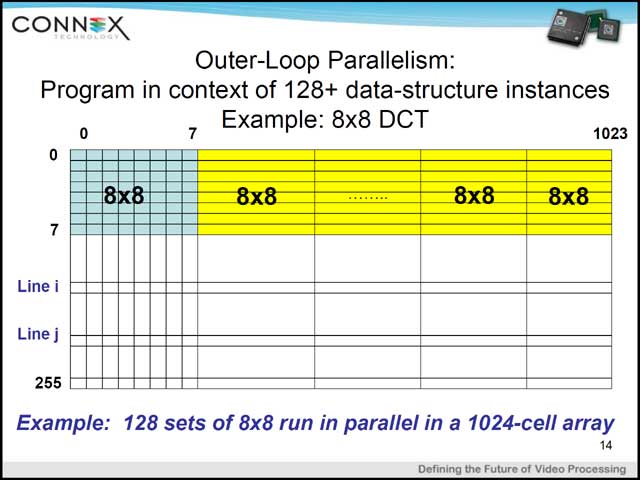
では実際にどんな形で演算が行なわれるか、を端的に示したのが写真12である。実のところCellが32×32という正方形をしていることにあまり意味はなく、論理的には1,024(なり4,096)のElementが横一列に並び、これが一斉に同じ命令で処理を行なうという、言わば「超SIMD」構成なのが、この「CA1024」である。なので、Arrayであることは間違いないのだが、この場合演算方向はあくまでLine間の処理に限られる。つまりCell #0とCell #1の間で演算を行ない、結果をCell #2に入れるなんてことは、直接的には不可能だ。もちろん写真11にあるように、レジスタ間での通信は可能なので、これを使うことでCell間の連携も取れる。写真13はDCTの例だが、適切に配置を行なえば同時に128組のDCTを処理することも可能だ。
ちなみに全てのCellが必ず同時に処理されるわけではない。写真11で、下のほうに“Select”というレジスタがあるが、これをSetすれば処理され、Resetすると処理されないため、これを使ってCell単位で演算する/しないを制御できる。このあたりの制御を行なうのが、写真10に出てきたSequencerである。写真11からもわかるとおり、各Cellは命令の実行部しか持っておらず、命令の解釈やそもそも命令のロード自体、単独では不可能である。そこで各Cellに対して命令をロードしたりするのは、全てこのSequencerが行なうことになっている。
 |
 |
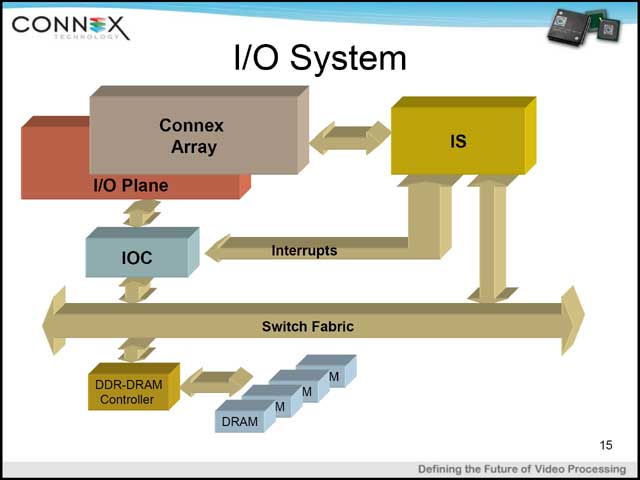 |
| 【写真12】横軸はCellが一列に並ぶ構造で、縦軸(Line)は要するに各Cellが持つRAMである | 【写真13】普通に2次元DCTをかけると無駄が多すぎるので、アクセスの最適化に関しては何らかの工夫は必要であろうと思うが、縦軸方向はペナルティなしでアクセス可能なため、1クロックで1,024個分の処理が可能だからアベレージのスループットはさぞすごいと思われる | 【写真14】これだけ見てるとあまりすごそうに思えないI/O System |
一方各メモリに対しての処理は、同じく写真10に出てきたI/O Planeが行なう。I/O PlaneはFablicでメモリコントローラに繋がっており、これで外部から各Cellのメモリにロードする、あるいはCellのメモリの内容を外部にストアするといった形になる(写真14)。Fablicの性能などは今回明らかにされなかったが、実際のCA1024ではかなり大規模なSOCとなる(写真15)関係で、かなり高速なものと想像される。
さて、これだけのものを作ると何が実現できるかだが、例えばPerforemanceで言えば、DCTが0.35 clock cycle/pixel、SADだと0.0025 clock cycle/pixelという数字が公表されている。ダイサイズなどは不明だが、TSMCの0.13μmプロセスで製造されたCA1024は2GOPS/平方mmという、評価が今一つ難しい数字が示された。もう少し現実的なところでは、H.264の1080iのDual Stream Decodingの試算(写真16)が示されたが、十分能力的に足りることが示されている。
 |
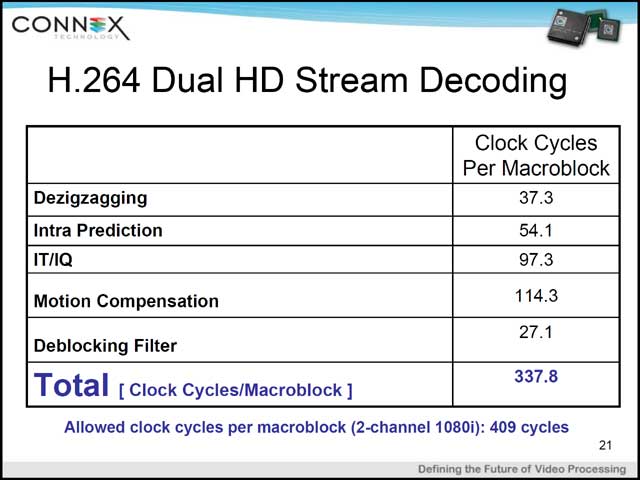 |
| 【写真15】下に4つほど並ぶCPU(Host CPU etc……)は実際はMIPS(おそらく「MIPS32 4K」シリーズのようだ)。これだけの規模だと、メモリがDDR400 1chで足りるのかちょっと心配だ | 【写真16】とても大雑把な試算で言えば、1080i(1,920×1,080ドット@60Hz インターレース)×2だと毎秒あたり処理すべきマクロブロックは243,000個である。これを処理するのに1個あたり409cyclesまで許されることから、Cell Arrayの動作速度はおおむね100MHzということになる。ただ実際はもう少しマージンが必要な気はするが、たった100MHz駆動でこれが可能、というあたりがすごい |
●IntellaSys SEA
このArrayの集積度をさらに上げれば、もっと性能が出ると考えたのがIntellaSysである。SEA(Scalable Embedded Array)と名づけられた同社のアーキテクチャは、一言でまとめれば「数で勝負」。そこでいかに数を集積するか、がキーとなる。この結果、SEAは非常に小さな18bit長の命令で構成されるForthマシン(IntellaSysはこれをnodeと呼んでいる)を非同期で繋ぐ、という他に類を見ない代物になった(写真18)。高集積疎結合マルチチップ、というのが1番適切ではないかと思うが、これが全て非同期で動作している、というのがSEAの特徴である。
 |
 |
| 【写真17】IntellaSys Corporation CTOのCharles Moore氏 | 【写真18】命令セットは僅か30で、Forceの構文で動くStack Machine。しかも“no central clock”というあたり、もうどう評価したものか…… |
 |
 |
| 【写真19】ClocklessだからClock Treeの無駄な消費電力が抑えられるというのはまぁ確かにそうなのだが。疎結合マルチプロセッサの極北とでも言えばいいのか? | 【写真20】各PE(Processing Element)間にレジスタを挟み、これでCommunicationするというのは割と普通の考え方。ただEdge resisters(要するに一番端にあるレジスタ)はそのままPIOポートになるというあたり、このレジスタの実装はどうなってるんだろう? と考えざるを得ない |
さらにややこしいのは、このnodeをどれだけ集積するか、というのも自由度が異様に高いことで(写真21)、おまけにChip間の接続形態を選ばない(写真22)という話が出てくるに至り、すでに通常のCPUの範疇からも逸脱しつつある(写真21)。これを支えるのは、不可解なほどの高いI/O能力である。On-Chipでワイヤレス用のDACを搭載しており(写真22)、これを使ってデジタル家電なども簡単に作れる(写真23)というのが同社の主張だが、こうなってくるともうどう判断したものか。
 |
 |
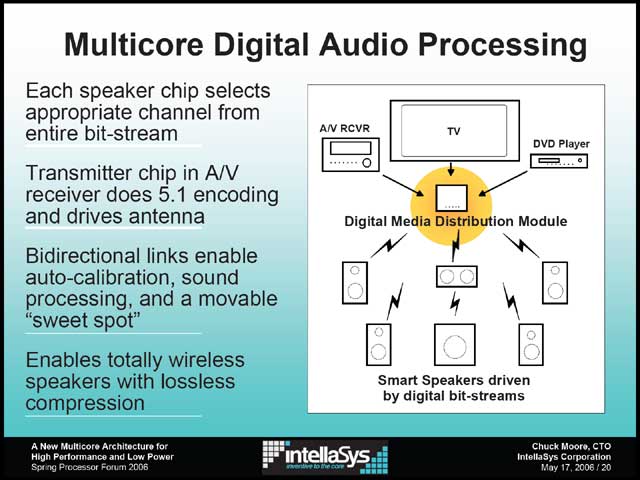 |
| 【写真21】チップ間は要するにEdge Register同士が通信するということだが、この間の物理層を選ばないという話。冷静に考えると、IRだWireだRadioというのは物理層の話で、TCP/IPというのはその上の話である。これを同列に並べているのは、要するにSerial Communications over any protocolみたいな実装を考えているのか、それとも何も考えていないのか…… | 【写真22】A/D、D/Aをオンチップに統合しており、出力が足りなければ外部にトランシーバなりパワーアンプなりを追加できるという話だが、CPUから直接R/Fが出てくるという実装は今のところこれが初めてかもしれない(チップ間の通信に無線を使う、という話は現在研究が盛んであるが、これはまた別の話だ) | 【写真23】これはあくまで概念の話だと思いたいが。2.4GHz帯を使い、全てのデバイス(特にスピーカー)にSEA Coreを入れ、間をSEAコア間の通信で繋ぐという実装で、ワイヤレススピーカーシステムを簡単に作れるという例 |
ちなみに性能は明確になってないが、1nodeで概ね1,000MIPSというのが同社の主張だ(写真24)。で、例えば48nodeのチップを100個集積すれば4,800,000MIPS(4.8TIPS)、これを10枚重ねて48TIPS(!)のスーパーコンピュータができる……というのはもう何と言うか(写真25)。ただ消費電力は案外に多く、24node構成で2.7平方mm、最大500mWということなので、熱密度はかなり高そうだ(写真26)。2006年Q4には24nodeチップを、OEM価格1個$10でボリューム出荷を始めるとしているが、使う人はいるのだろうか。
 |
 |
 |
| 【写真24】このMIPSがまた謎。なにしろ30命令しかないForthマシンのMIPS(Mega Instructions Per Second)だから、通常のRISC系CPUと同じことをやらせた場合にどの位の数字になるかは想像しにくい。非同期な故に、動作していないときはSleepになる、というのはHandshakeのARM966HSと同じ | 【写真25】並べりゃいいというものではないと思うのだが。しかもForthマシンで完全非同期。プログラミングにはさぞかし芸術的な要素が多大に必要であろうと想像される | 【写真26】この24nodeチップで“24 billion operations/second”だから、1nodeあたり1,000MIPSという判断で間違ってはないと思うが |
●Vivace Semiconductor ViViD
別の意味で特徴的なマルチコアCPUがVivace Semiconductorの「ViViD」コアである。同社は2005年10月設立の非常に新しいメーカーで、これが同社の初めての製品ということになる。同社はViViDというマルチメディアエンジンと、これを利用したVSP200/VSP300という製品を発表したが(写真28)、今回はこのViVIDコアの詳細がメインである。そのViViDコア、ブロック図からもわかるように4つのエンジン(写真29)から成立するSoCである。問題がこのエンジンが揃いも揃ってまったく異なるアーキテクチャになっていることだ。
 |
 |
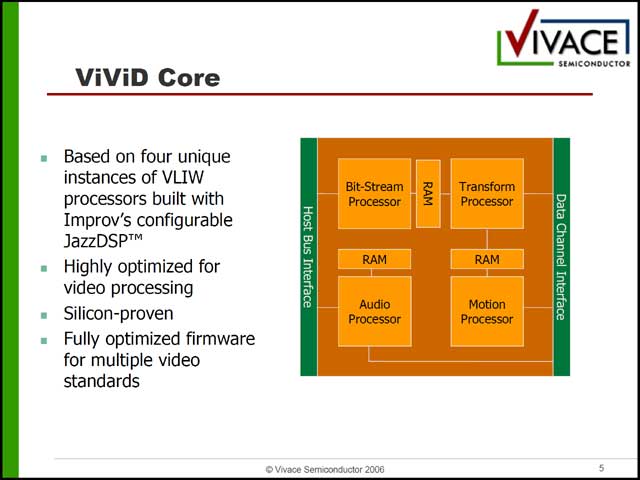 |
| 【写真27】本来は同社のCEO兼FounderのCary Ussery氏が講演の予定だったが、急用で参加できなくなり、代わりに登場したBryan Greear氏(Vice President of Sales and Marketing) | 【写真28】ポータブルビデオプレーヤーとデジタル家電にマーケットを絞った製品。もっともポータブルプレーヤーで720pをサポート、というあたりはハイエンド志向ではある。まぁ最初からバリュー向けではマーケットを取るのは難しいのかもしれない | 【写真29】さすがにスクラッチから起こしたわけではなく、ImprovのJazzDSPをベースにしている。ちなみに2つ前に行なわれたsci-worxの「MoViStar」という、やはりビデオ用のマルチメディアエンジンはTensilicaのXtensa LXをベースに作られるなど、Reconfigurableコアの利用が目立つのも今回の特徴か |
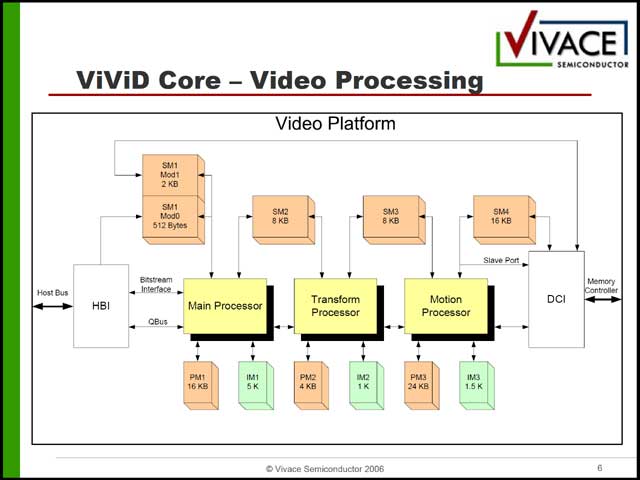
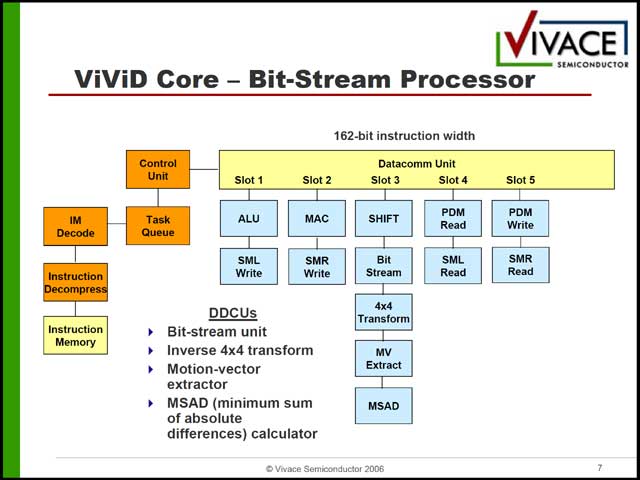
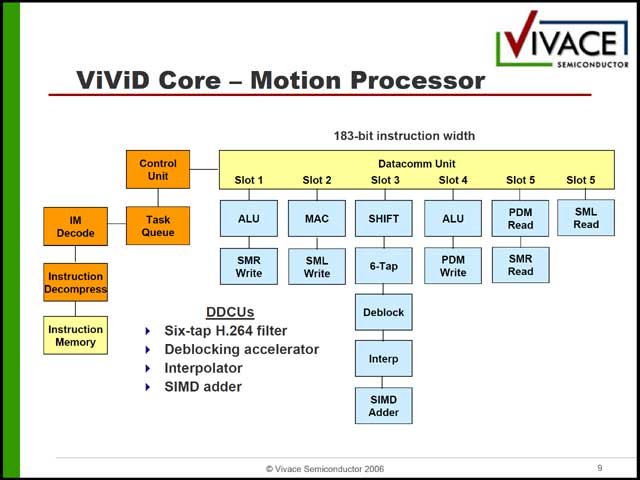
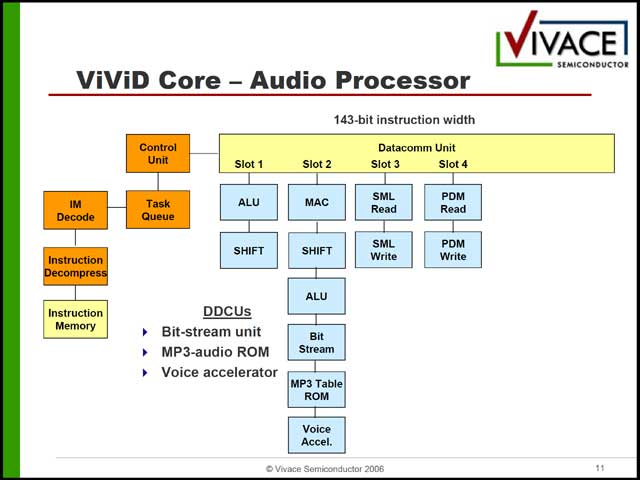
まずビデオ部は3種類のエンジンから構成されるが(写真30)、この3種類がまるで命令長が違う(写真31~33)という、なぜ汎用プロセッサ構成にしているのかすでに不明な構成になっている。これはオーディオ側も同様で、構造自体はシンプルであるが(写真34)、内部構造は相変わらずである(写真35)。
 |
 |
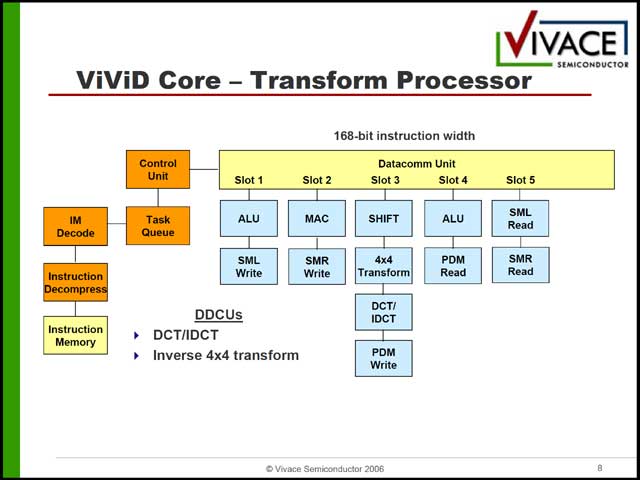 |
| 【写真30】各々のプロセッサの用途はこの後説明。Main Processorにしても、実態はBitStreamの管理で、あまりMainとは言いにくい | 【写真31】そのMain ProcessorことBitStream Processor。5SlotのVLIWだが、VLIWにする意味があるのだろうか? | 【写真32】こちらはTransform Processor。DCT/IDCTと2D逆変換のみを行なう、ちょっと不思議な構成。命令長は168bitに変更される |
 |
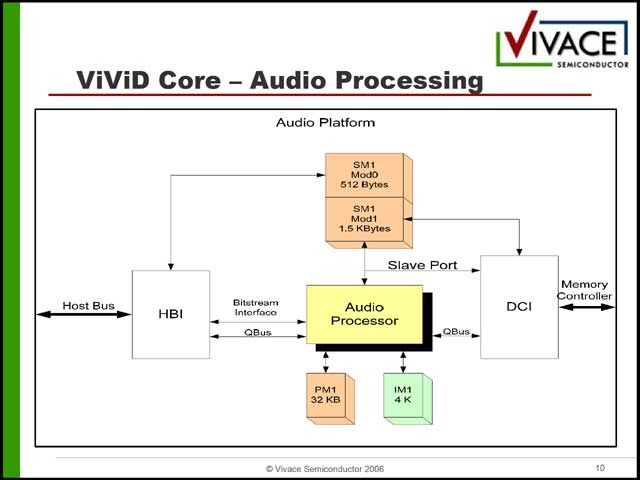 |
| 【写真33】Motion Processorは要するにDeblocking Filterなどを管理する。6slot分ありながら実態は5slot、というのは多分JazzDSPが同時5slotまでしか命令を発行できず、利用頻度の少ない2つをまとめてSlot 5に割り当てたものと想像される | 【写真34】気になるのはVideoとAudioの同期を取るメカニズムが一切見当たらないこと。ひょっとするとこれはHost側の管理なのかもしれない |
これを搭載した「VSP-200/300」は比較的コンサバティブなSoC(写真36)である。今回説明されたのはVSP-300だが、VSP-200では多少デバイスが減らされ(SATA HDD/Ethernet/HDMI/ITU-R-656が省略される)、動作周波数がやや控えめ(CPUが最大250MHzのARM926、ViViDコアは150MHz駆動)な以外は違いが無い。従来では、こうしたチップでメディアエンジンは、自前でがりがり作るのが普通であったが、そこにJazzDSPを使って生成したVLIWエンジンを流用することで、デザインの時間を短縮する、というのが実のところ最大のミソなのかもしれない。カスタムデザインは(CPUそのものを作るよりは高速とは言え)開発の負荷は大きいし、仮にこうしたReconfigurableなコアを使って同じことができるならばその方が確実なのかもしれない。
 |
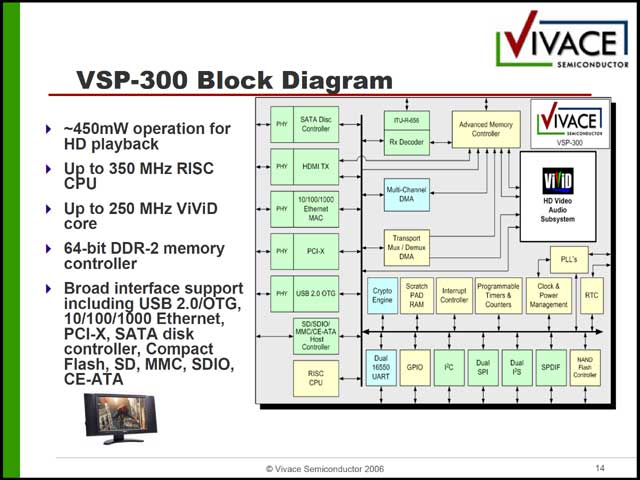 |
| 【写真35】MACとSHIFTを一緒にすることでSlot数を減らした結果、命令長は143bitに減っているが、Slot数を減らす意味があるのか、がそもそも疑問 | 【写真36】RISC CPUの詳細は明確にされなかったが、おそらくは350MHzのARM926あたり。内部バスはAHBとAPBではないかと想像される |
プレゼンターがTechnical Personではないために細かいニュアンスは判らなかったが、Vivace自体はViViDコア内部の4つのVLIWエンジンを汎用プロセッサとして使わせることはあまり意図していないようで、ファームウェアの形でVivaceから複数バージョンが提供され、これをロードすることで(ちなみにloadable on demandだそうだ)利用できるようになるAPIを上位アプリケーションか叩く、といった使い方を考えているようだ。カスタムロジックをReconfigurable Processorで作成することでTATを減らす、というデザイン例と言ってもいいかもしれない。
●まとめ
今回のSPF、それなりに盛況であったのは事実だが、ますます規模が小さくなっているのがちょっと気になるところ。大手ではARMが目立つ程度で、MIPSは2月に発表したMIPS32 34Kの内容の繰り返し。PowerPC勢はP.A.SemiのDan Dobberpuhl氏による基調講演があった程度で、内容的にも目新しいことはない(テクニックとしては色々面白い話があったが、アーキテクチャ的には前年のFPFでの発表から何も変わっていない)程度だった。
ほかに面白いと感じたのはNSとFreescaleがどちらも電圧制御メカニズムを発表したことだが、NSはEPF2003で発表されたAVSの進化系で、複数の電圧ドメインを管理できるようにしたもの。FreescaleはAVS相当の電圧制御機能に周辺回路を統合したワンチップコントローラを作成、というもの。実装面ではどちらも面白かったが、技術的な面ではTransmetaの発表で言い尽くされている感があり、今回レポートは見送った。
謎だったのがTarari。こちらも発表を行なう予定だったCTO & co-founderのJeff Carmichael氏が急用で参加できず、Vice President MarketingのJohn Bromhead氏が登場しての発表だった。Contents Processorを使ってWME9のエンコードを20~30倍高速化するという話はあったものの、「なぜContents ProcessorでWMVE9が高速化されるのか」(あるいは、Contents Processorは何をやっているのか」に関しては語られずじまい。Bromhead氏自体「おりゃーTechnical Guyじゃないんで、Q&Aを受けても答えられない。後でメールでくれれば折り返し返事するよ」とか言い出す始末で、結局謎のまま終わってしまった。TarariはSPF Japan 2006には不参加らしく、結局肝心なところがわからずじまいで終わってしまったのはちょっと残念だ。
それにしても、「うーん」である。だんだんSPFやMPFが、「中小ベンダーが新製品をロハでAnnounce出来る場」になりつつある現状が、ちょっと不安である。確かにMicroProcessor Forumはそうした面を多分に備えたイベントであったのは事実だが、かつてはIntel、AMD、IBM、Motorola(現Freescale)、Sunなどといった大手メーカーの発表も少なくなかった。これがうまくバランスしているからこそここまで続いてきたわけだが、この先も続けてゆくためには、もう少し大手の参加が必要な感じを受けた。
幸い、というべきか不幸にも、というべきか、SPF Japan 2006にはルネサス、富士通、NECなどが参加するので、バランスが取れた方向にシフトしている。こうしたベンダーが参加しているのがSPF Japan 2006にとって幸運であり、ところが本国のSPF2006に参加していないのが不幸である。次回もSPF2007のレポートをできるといいのだが、一抹の不安を感じざるをえない。
□Spring Processor Forum2006のホームページ(英文)
http://www.instat.com/spf/06/
□Silicon Hiveのホームページ(英文)
http://www.siliconhive.com/
□Connex Technologyのホームページ
http://www.connextechnology.com/index-ja.asp
□IntellaSysのホームページ(英文)
http://www.intelasys.net/
□関連記事
【5月26日】【SPF】新アーキテクチャやクロックレスなど話題の多いARM
http://pc.watch.impress.co.jp/docs/2006/0526/spf07.htm
【5月19日】【SPF】復活したEfficeonはXboxポータブルに搭載か
http://pc.watch.impress.co.jp/docs/2006/0519/spf04.htm
【5月17日】【SPF】Spring Processor Forum 2006、15日開幕
http://pc.watch.impress.co.jp/docs/2006/0517/spf02.htm
Spring Processor Forum 2006レポートリンク集
http://pc.watch.impress.co.jp/docs/2006/link/spf.htm
(2006年6月1日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 [email protected] お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2006 Impress Watch Corporation, an Impress Group company. All rights reserved.