
|
Spring Processor Forum 2006レポート
新アーキテクチャやクロックレスなど話題の多いARM
 |
会期:5月15日~17日(現地時間)
会場:米カリフォルニア州サンノゼ
DoubleTree Hotel
今回のSPFでもARMにまつわるさまざまな発表が多かった。そこでかいつまんでこれらをまとめてみたい。
●TIとARMによるCortex-A8の実装
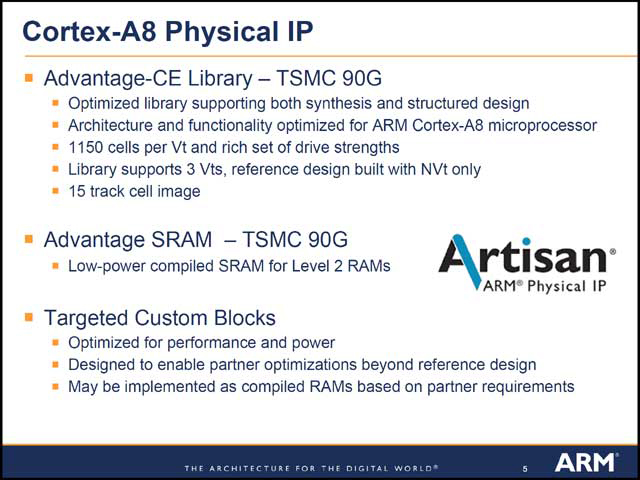
前年のFPF2005で発表されたARMの「Cortex-A8」だが、今回はTI(写真01)とARM(写真02)により、この実装に関する発表があった。大きな違いは、TIは自社の65nm Fabによる実装、ARMはTSMC 90nm標準プロセスによる実装という話で、当然ながらさまざまな点で違いが見えて面白かった。
 |
 |
| 【写真01】ARM Cores Program Manager, TI Wireless Terminal Business Unit, Texas InstrumentsのTy Garibay氏 | 【写真02】Implementation Lead, ARMのVivek Nagaraj氏 |
TIは、これが65nmによる初製品ということもあってか、意外なことに自社のDSPコアではなく、ARMの「NEON」を搭載している(写真03)。実装に関し、割合に細かなパラメータも示している(写真04)。
 |
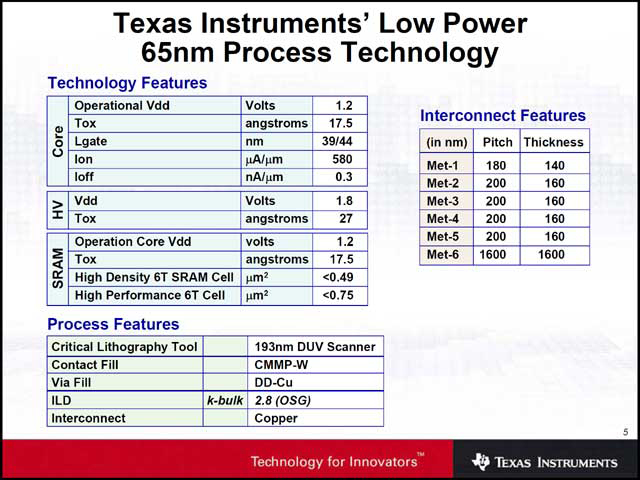 |
| 【写真03】初期のOMAP1はARM7もしくはARM9+TMS320C54X/55Xという、「ARMコア+TIのDPS」であるが、2005年に発表されたOMAP2では、ARM11+IVA2(Imaging Video and Audio Accelerator)がベースで、必要に応じて+TMS320C55Xが追加されるという形態であった。だからNEONを搭載したからといっておかしくはないのだが、将来的にはNEONとTI DSPのDual DSP構成とかも登場するのだろうか? | 【写真04】配線は6層で1.2V駆動。やはりリークはそれなりに多い |
一方のARMは、いかに普通のファウンダリで製造できるか、という点をアピールするのが主目的のようで、まだ量産体制が整っていない65nmではなく、あえて90nmを使って1GHz動作にチャレンジしている(写真05、06)。
 |
 |
| 【写真05】現状TSMCの65nmはRISK Processで量産にはまったく向いていないため、これは妥当なトライアルであろう | 【写真06】TSMCのLow Power SRAMセルの利用や、いかに設計を容易にするかといったトライが今回の目的であるとしている |
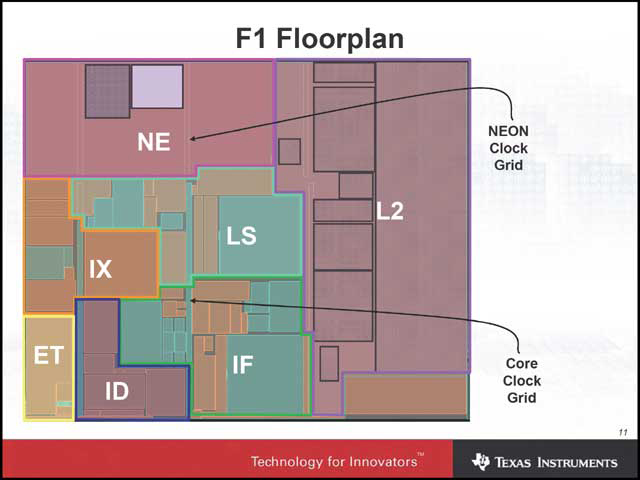
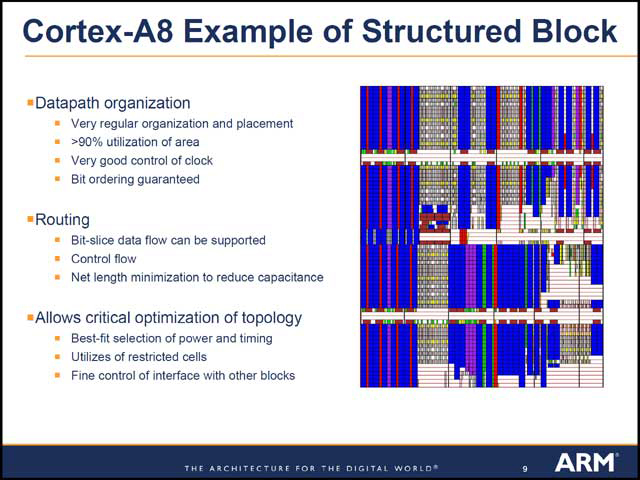
まず両社とも最初に取り上げたのが、Clock Disrtributionの問題。TIは単にCPUコアとNEONを分けただけだが、ARMはコア/NEON/その他の3つのドメインに分けているのがちょっと面白い(写真07、08)。フロアプランは似ているといえば似ている(写真09、10)が、せいぜいがその程度。データパスもだいぶ違っており(写真11、12)、やはりこのあたりは利用できるファウンダリとか設計ツールなどの影響を受けやすいという事だろう。ちなみにTIは、具体的にどのブロックをどう配線したかも示した(写真13)。
 |
 |
| 【写真07】こちらがTIのClock Distribution。NEONはコアと異なるパイプラインで動くため、分けるのは合理的 | 【写真08】講演の中でも、「その他」は「その他」で終わっていて詳細はわからなかったが、キャッシュ周りのアービタなどを別にしているのかもしれない |
 |
 |
| 【写真09】TIはフロアプランの決定に多少手作業の最適化も入ったそうで、割と入り組んだ構成になっている | 【写真10】ARMではこのあたりを完全にブロック化している関係で、TIよりもブロックが明確に分かれている |
 |
 |
 |
| 【写真11】TIのData Path。これは整数演算ユニットとロードストアユニットを示したものと思われる。「必要に応じてSPICEを使いながらデザイナーが手でレイアウト」しなければいけない部分もあった、というのがなかなか大変である | 【写真12】ARMのData Path。こちらはL2以外の全体っぽい。ブロックを大きく分けて、その内部を自動配線ツールでルーティングしてゆくというコンサバティブな方法。ただこれでおおむね問題はなかったとのこと | 【写真13】案外にFull Custom Designの割合が多いのはちょっと驚き。SRAMセルまでがFull Customというのは単に65nmに対応したライブラリが無かったためだろうか |
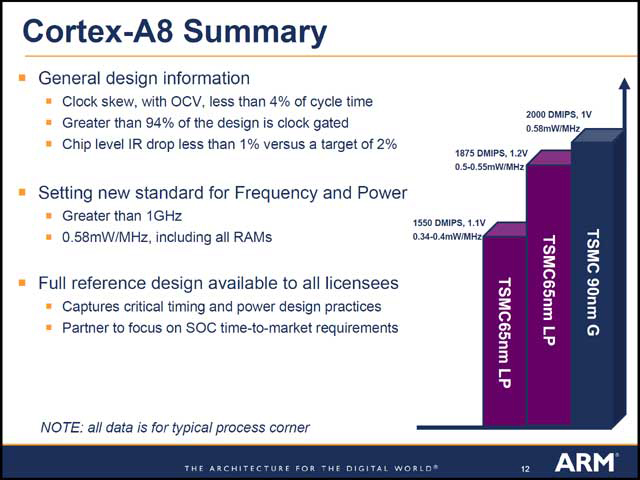
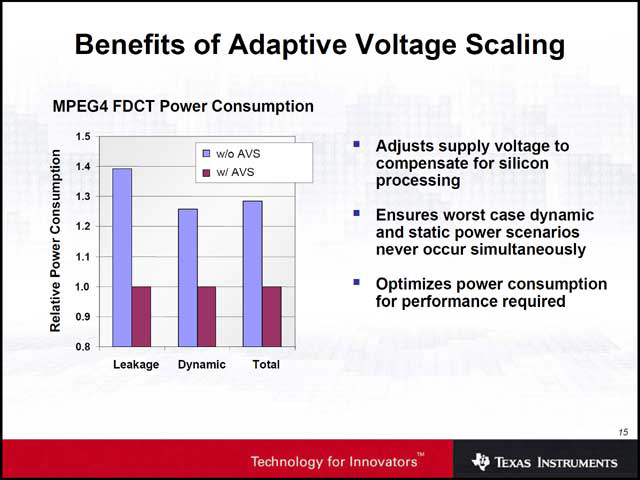
性能と消費電力に関し、ARMは特に省電力機構などを入れずに0.58mW/MHz(つまり1GHz動作で580mW)の性能を確保した(写真14)。一方、TIは具体的な数字は示さなかったが、省電力機構としてNSとARMが共同開発したAVS(Adaptive Voltage Scaling)を搭載することで、一定の省電力性を確保できた、としている(写真15)。
興味深かったのは、TIの最後のプレゼンテーションである(写真16)。45nm世代では、やはり設計がかなり難しくなる事が改めて示されており、今しばらく普通の用途では関係ないが、今後さらに微細化が進むケースではこうした問題が広くクローズアップされてくることになるのだろう。
 |
 |
 |
| 【写真14】TSMCの65nm LowPower Processの数字はあくまでも推定、という話で実際にやってみるとどうなるかはまた別の話である | 【写真15】さすがにに65nm世代ではAVSなしでは難しい、ということだろうか | 【写真16】今のところ65nm世代ですら、IntelとIBM/SONY/東芝/AMD共同グループ、富士通程度が量産に入っているだけで、TIはやっとその仲間入りのポジション。TSMCやUMCなどのファウンダリで65nm世代が普通に使えるようになるのはだいぶ先だし、45nmはさらにその先である。なので、これらの問題を解決するための時間はまだまだあるとはいえるが、先端プロセスに突っ走る限りはこれらの問題が避けて通れないことになる。おそらく最初にぶつかるのはIntel、次いでIBMという順だろうが、このあたりがどうなるかはちょっと興味深い |
●Cortex-R4
 |
| 【写真17】Product Manager, ARMのRichard York氏 |
次に、今回のSPFで初公開となったARMの「Cortex-R4」をちょっとご紹介したい(写真17)。2005年10月にARMはハイエンド製品の「Cortex-A8」を発表したが、それに先立つ1年前の2004年10月にはバリュー向けの「Cortex-M3」を発表していた。
Cortex-A8が2.0DMIPS/MHzで1GHzを狙い、一方Cortex-M3は1.2DMIPS/MHzで100MHz程度のレンジを狙う製品で、両者の間には猛烈なギャップがある。このギャップを埋めるのが、今回発表されたCortex-R4である(写真18)。1.6DMIPS/MHzで300~400MHzのレンジに位置しており、丁度両者の間にはまるわけだ。
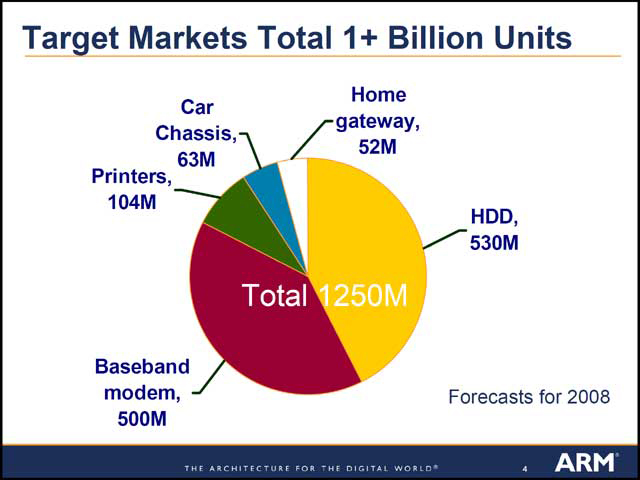
このCortex-R4のターゲットがまた面白い。HDDのコントローラと携帯のBaseband Modemがその大半を占めているという、非常に興味深いものが示されている(写真19)。上位にCortex-A8がある関係で、必ずしも高性能を狙う必要はない反面、柔軟性やソフトウェア開発の容易性、信頼性などが求められる部分で(写真20)、こうした部分に狙いを定めている。
 |
 |
 |
| 【写真18】Cortex-A8は性能が高すぎてこのチャートの遥か上方にあるためプロットされていない。Cortex-M3はARM7と一部のARM9の代替品で、Cortex-R4はARM10~11の代替ということになる。現在は480DMIPS(0.13μmプロセスで300MHz)で、90nmプロセスで400MHz駆動だと640DMIPSという計算だ | 【写真19】HDDとはHDD内部のコントローラ。最近のHDDはおおむねGPU+DSPでコントローラが構成されており、このGPU部の代替である。Baseband ModemはFeature Phone(単機能の電話)向けという感じか。Printerはインクジェットなどの家庭用プリンタがメインである | 【写真20】しかしながら、最後の“A Perfect oppotunity for a new product!”が全てを物語っている気も。要するに、いろいろ作り直したかった、ということだ |
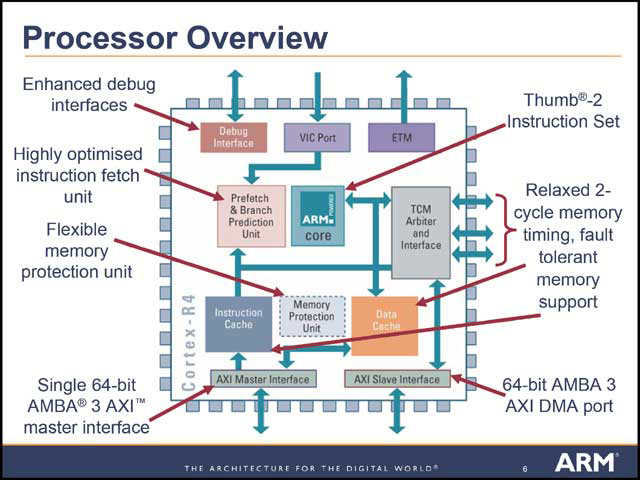
内部構造はというと、コアに外付けする形でPrefetch/Branch Prediction、L1/L2キャッシュ、TCMなどが配され、外部とのインターフェースはAXIとしている(写真21)。パイプラインは全8段とちょっと短くなっているが(写真22)、Pre-decodeは同時2命令デコードになっているとか(写真23)、実行部はOut-of-orderのスーパースケーラ構造になっている(写真24)など、なかなか意欲的な構造であり、In-Orderのまま推移したARM9/10とは大きく異なっていることがわかる。
 |
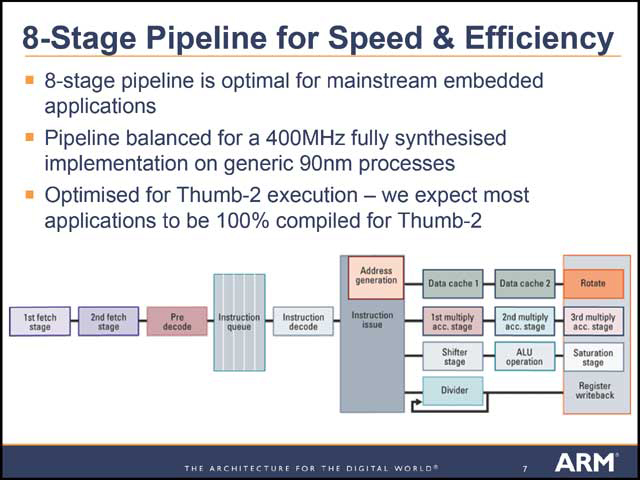 |
| 【写真21】キャッシュやTCM(これは後述)、Memory Protection Unitなどはオプション構成であり、目的に応じて変更可能 | 【写真22】パイプライン全景。どことなく、Feroceonを連想させる |
 |
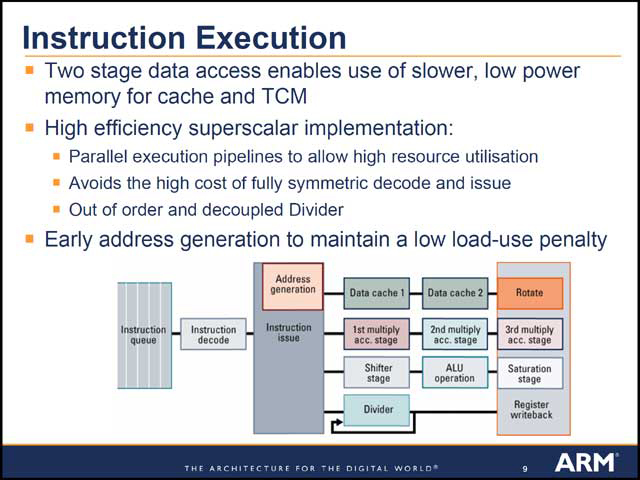 |
| 【写真23】メモリが遅い場合にもパイプラインストールを起こさないようにフェッチが2段になっているのが面白い。Pre-decodeがThumb-2の場合に2命令、というのもちょっと独特だ | 【写真24】ALU一般として、Divider(割り算)は極端に処理性能が遅くなるので、これを分離するのは理に適っている。もっとも、最適化したコンパイラは不用意に除算命令は出さないと思うが |
ただそれより面白いのは、ALU性能以外の部分だ。ARM11(というか、ARM V6)でも割り込みに関して2種類の動作モードをサポートし、Low-Interrupt-Latency(20~30Cycleで処理される)とHit-Under-Miss(200Cycle以上を要する)のどちらかで構成できるようになっていたが、Cortex-R4ではアプリケーションプロセッサよりもデバイスコントローラとしてのニーズが高いと見たためか、Low-Interrupt-Latencyをデフォルトとした模様だ(写真25)。また先のパイプラインの話とも関係するが、Cortex-R4では低速なメモリを組み合わせることを前提に、メモリからのアクセスを遅めにすることが許されるようになっている(写真26)。
 |
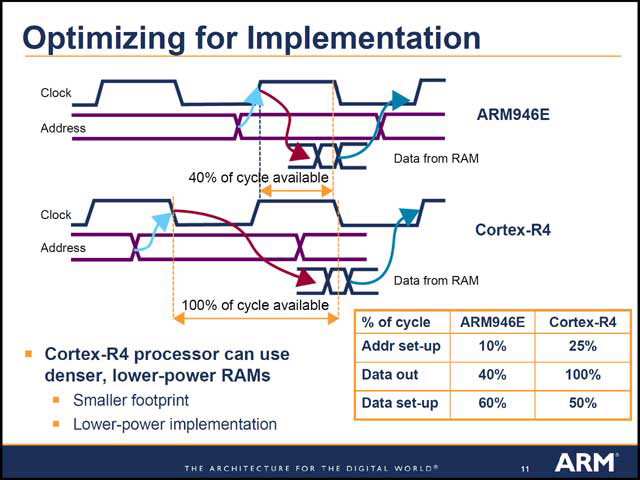 |
| 【写真25】Low-Interrupt-Latencyは割り込み処理自体は高速だが、消費電力が高くなるという問題を鑑み、ARM V6の世代ではこれをサポートしないことも可能だった。ちなみにARM 9の世代ではそもそもこの機能が無かった | 【写真26】Mobile RAMなどの省電力(だが低速)メモリと組み合わせるケースを想定しているらしい。どうでもいいが、クロックの立下りがトリガーになっているのがちょっと面白い |
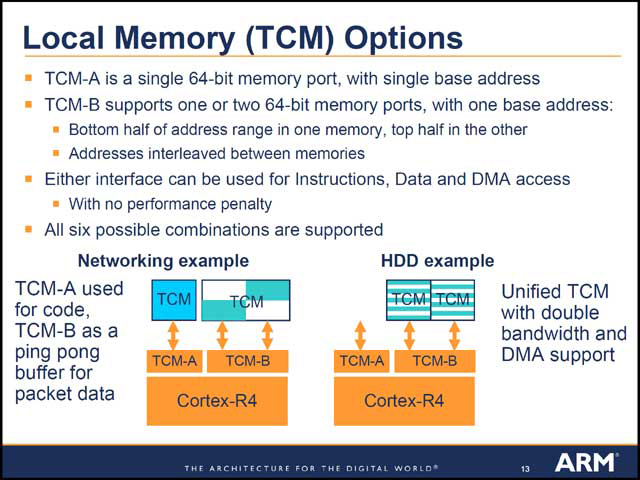
Cortex-R4でもう1つ特徴的なのが、TCM(Tightly Coupled Memories)である。要するにキャッシュとは別に設けられたローカルメモリで、プログラムから自由にアクセス可能なものだ。容量は非常に少ないが、アクセスにペナルティがない(つまりL1データキャッシュ同様に1cycleでアクセス出来る)ということで、これをうまく使うことでデータ転送などの効率化を計るというものだ。
Cortex-R4の目的は、GPUというよりはMicroControllerという扱いに近く、従来の「携帯用プロセッサ」というところから一歩踏み出すための戦略製品と考えても良さそうだ(写真28)。しいて難点を挙げるとすれば、従来のMicroControllerの場合、各メーカーは猛烈な量のモデルを用意して、目的に応じた最適な製品を提供する、というスタンスを取っている。
 |
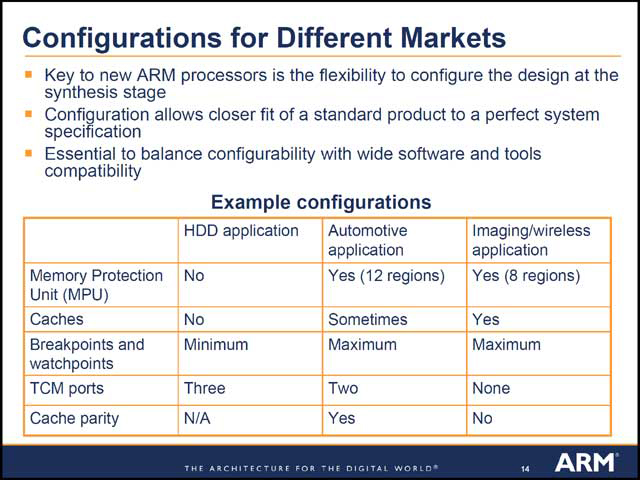 |
| 【写真27】2つのTCMポートが用意され、そこに好きな形でTCMを配置できるとしている。ただこのTCMの配置は起動時に変更できるのか動的に変えられるといったわけではなく、製造時に決める形になるようだ。TCMはAIXからも直接転送が可能になっており、プログラム内部のテンポラリエリアだけでなく、I/Oなどにも利用できる | 【写真28】用途別の構成の違いの一例 |
Cortex-R4そのものは、こうしたMicroControllerのためのBuilding Blockであって、実際に採用されるためにはチップベンダー側が(Cortex-R4を使って)膨大なバリエーションの製品を作らないとなかなか入っていかないように思える。が、そうしたラインナップを揃える体力のあるベンダーは既に自前のコントローラを持っているのが普通で、開発の減価償却も済み、顧客もそれ用の開発機材を導入済で、それなりに性能面でも満足されている、というケースが多いと想像される。
こうしたものをCortex-R4で置き換えるためのモチベーションがどの程度あるのか、が良くわからないところである。ARM自身がそうしたラインナップを揃えるとは考えにくいし、実際はCortex-R4だけでは足りずに周辺機器を集約したSoCにして初めて意味が出てくる。もうすこし、普及には時間がかかりそうだ。
●Handshake ARM996HS
 |
| 【写真29】Chief Design Engineer, Handshake SolutionsのArjan Bink氏。ちなみにHandshake SolutionsはSPF Japan 2006でも講演を予定しているが、2日目の朝食時に捕まえて話をしていたところ、「日本語でのプレゼンテーションができない」のでBink氏は日本に来ないそうな。で、講演は「まだ決まってないけど、日本IBMかARM Japanにお願いするつもりだ」とのこと。ARM Japanはともかく何故日本IBM? と思うのだが、ビジネスでのパートナー関係があるのだそうだ |
ARMの最後はHandshake Solutionsの「ARM996HS」である。Handshake SolutionはPhilipsの事業部門の1つであり、今回はARMと共同で開発した、初のクロックレスプロセッサを発表した(写真29)。
ARMのWhite Paperを見ると“ARM's first commercially-available synthesizable CPU……”という、やや持って回った言い方をしているが、実はクロックレスのARMはこれが初めてではない。というのは、ARMは古くからマンチェスター大学と共同で「AMULET」という非同期プロセッサの設計プロジェクトを行なっているからだ。
'93年に登場した最初の「AMULET1」は152mWの消費電力で20.5DKIPS(K Dhrystones)を発揮し、同プロセス(1μm)で製造されたARM6(20MHz駆動)の31DKIPSにはやや及ばないものの、非同期プロセッサが製造可能であることを実証。続く「AMULET2」は'96年に登場し、ほぼARM8と同等の性能/消費電力性能を達成した。
また待機時に消費電力を3μW(3mWではない!)まで落とすことに成功し、非同期プロセッサの低消費電力の優位性を明確に示した。このプロジェクトは続いて「AMULET3」の開発に移り、Thumb命令を含むARM V4アーキテクチャ(ARM9)互換チップを2000年に開発している。こうしたAMULETプロセッサはあくまで技術開発のためのもので、商用として量産することは前提にしていないが、多少なりともこの成果がARM996HSに応用されているのではないか、と思う(*1)。
(*1) Bink氏と話をしているときは、うっかりAMULETの存在を忘れていて、関係を聞き損ねた。ちなみにHandshake SolutionsのプレスリリースではAMULETに関し“ARM has long recognized the potential of clockless IC design and has supported the Amulet project led by Professor Steve Furber at Manchester University.”と簡単に触れられているだけである。
ついでに言うと、商用のクロックレスプロセッサとして最初のものは、シャープが'98年に発表したDDMP(Data Driven Media Processor)ではないかと思う。今では一部のボードを除き、社史に名前が残っている程度、というのがアレであるが。この時にシャープが共同開発の相手に選んだのが、ARCの発表にも出てきたCadenceというのが、さらに趣を深いものにしている。
余談が過ぎたので元に戻そう。HandshakeはARM9の内部回路を全てクロックレスとした。一般にICは全て同期式、つまり入力したクロックに同期する形で内部回路が動いている。クロックにあわせてラッチと呼ばれる回路がデータを送り出すことになるので、煩雑に回路が動くことになり(仮にデータが無くてもラッチは動作する)消費電力が増え、また回路の全てに同一タイミングでクロック信号を送らないと、うまく歩調が取れなくなる(先の写真07/08はこのクロック信号の分配経路を示している)から、この設計が面倒だ。また、理論的に言えば同期式ということは、余分にタイミングを入れることで回路の他の部分と歩調をあわせているからであり、これをなくせばより高速に動く「可能性がある」。
こうしたメリットがあるにも関わらず、(AMULETやDDMP以外に)ほとんど例が見られなかったのは、小さな回路ではともかく、プロセッサともなると、非同期で全てを設計するのは極めて困難であり(同期式ということでタイミングを合わせているからまだ設計が可能なのであって、完全に非同期だと回路の位置を変えるとタイミングが変わるから、設計がほぼ不可能になる)、また実際には一貫性の確保などのために余分なコストがかかり、遅くなることも珍しくない(AMULET1の場合、レジスタの一貫性をレジスタロック機構で保証していたが、結果としてこのレジスタロックへのアクセスが理由でパイプラインがしばしば止まっていた)といった問題があった。特に設計の難易度の高さが大問題で、これが普及を妨げる大きな要因となっていた。
ではHandshakeはこれをどう解決したかという話だが、機能モジュールを細かく分けた上で、モジュール間をハンドシェイクで通信させる(これが社名の由来でもある)ことで対処している(写真30)。パイプラインそのものはARM9同様に5段であるが、そのパイプラインはいずれもRequest/Ackのハンドシェーク信号に則って動作し、それを中央のパイプライン制御部が管理するという仕組みだ(写真31)。写真32はメモリインターフェイスとの接続例だが、ロジック部からはやはりハンドシェイク信号を出し、これとクロックが同期を取る形で通信を行なえる。
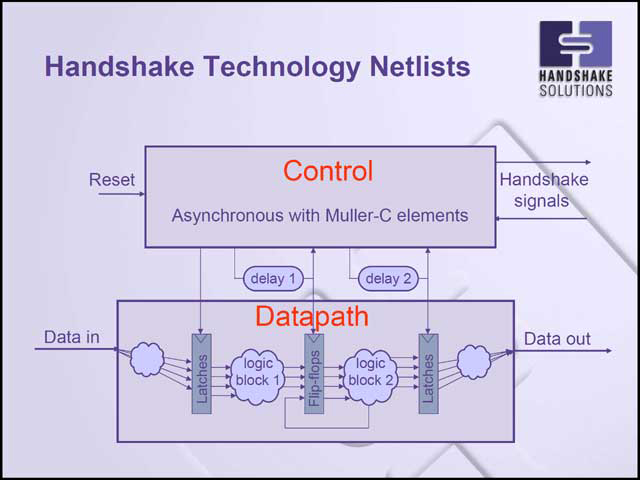 |
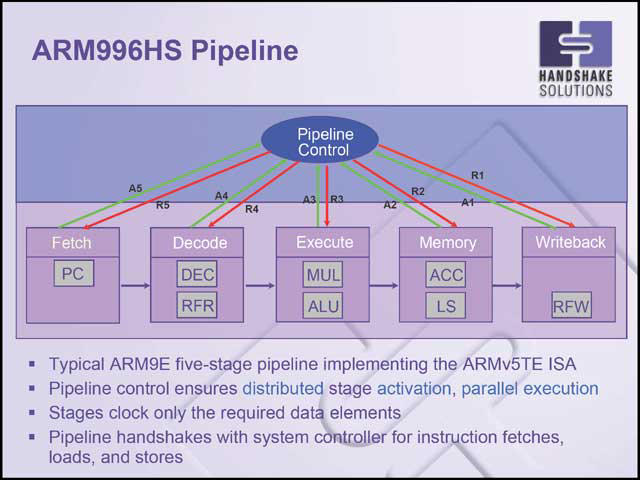 |
 |
| 【写真30】各ロジック内部は完全に非同期で設計し、ロジック間にラッチがある「ように見える」 | 【写真31】さすがに、データの移動は従来同様データクロックを使ってのデータ転送となる。あくまで非同期なのは命令の処理部分のみだ | 【写真32】クロックに合わせる形でハンドシェイクしアクセスを行なう |
さてこのハンドシェイク方式のメリットとデメリットだが、そもそもクロックに依存しない形で動作するから、処理性能は個々のトランジスタのスイッチング速度に依存する。なので、例えば環境温度が上がって速度が低下した場合、同期式ならタイミングが間に合わなくなり、動作がおかしくなったりするわけだが、ARM996HSの場合は単に遅くなるだけで、それにより止まることはない。
また遅くなるということはスイッチングの頻度が減ることでもあり、発熱が減るということにもなるから、ある温度以上に上がりにくいのが特徴だ(写真33)。ただしこれは逆にいうと、環境で速度が決まるので、スピードをゆっくり動かすということが原理的にできない。そこでこのために、Tempo interfaceと呼ばれるものを新設してあり、これを使ってハンドシェイクの時間を遅らせることで速度調整を行なっている(写真34)。
 |
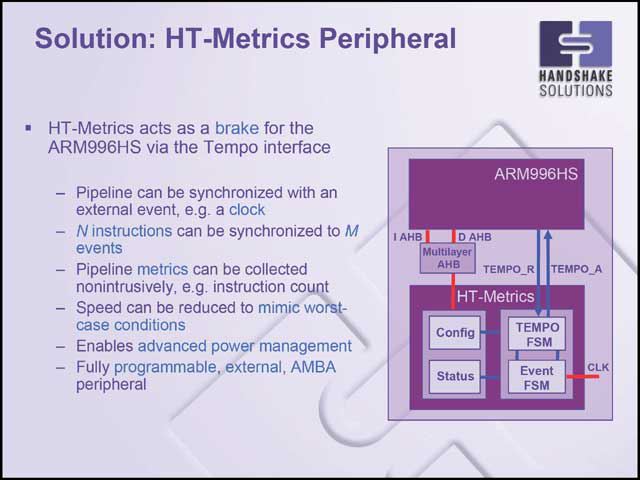 |
| 【写真33】大雑把に言えば電圧と温度で決まるから、例えば温度調節をすれば間接的に速度を下げるのは可能だが、あまりにも馬鹿馬鹿しい | 【写真34】Tempo I/Fはパイプラインの動作速度を見ながらハンドシェイクに介入することで速度調整を行なう。Advanced Power Managementの機能も持っているが、これは察するにコアそのものではなく、周辺回路や外部に対してのものだろう |
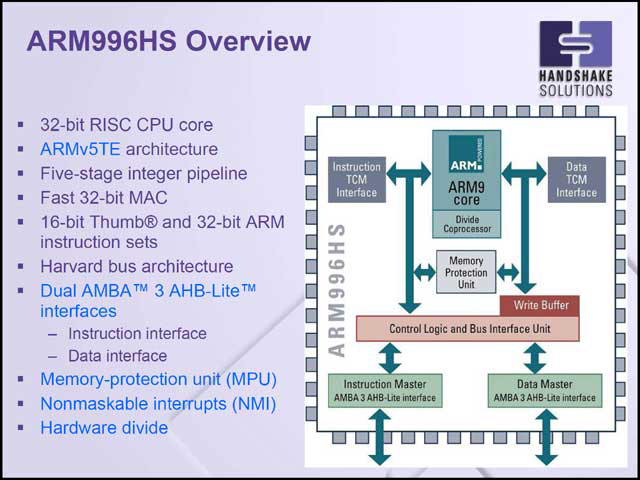
話は前後するが、ARM996HSそのものは単にコアのみならず、AHB Lite I/FやTCMなどを持った、既存のARM V5TE互換のCPUとして構成されている(写真35)。信号が完全互換というわけではない(TEMPO I/Fなどもあるからだ)が、ARM V5TEの搭載を前提としたコアをこれに置き換えるのはそう難しくない。
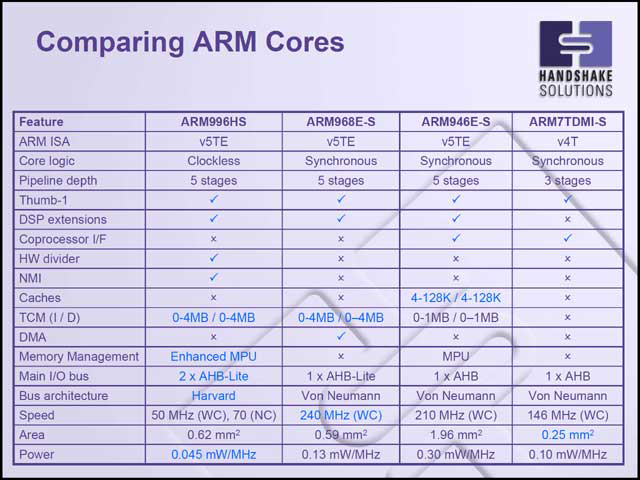
では性能面ではどうか? ということで、まず写真36は既存のARMコアとの要素を比較したものだ。特徴的なのは消費電力で、他を圧倒するスペックになっている。性能という面では、100MHz駆動のARM968E-Sのほぼ半分程度でしかないが(写真37)、消費電力では2.3~3.5mW(ARM968E-Sは13mW)だから4~5分の1で済んでいる計算だから、これは非常に効果的なアーキテクチャと言える。
 |
 |
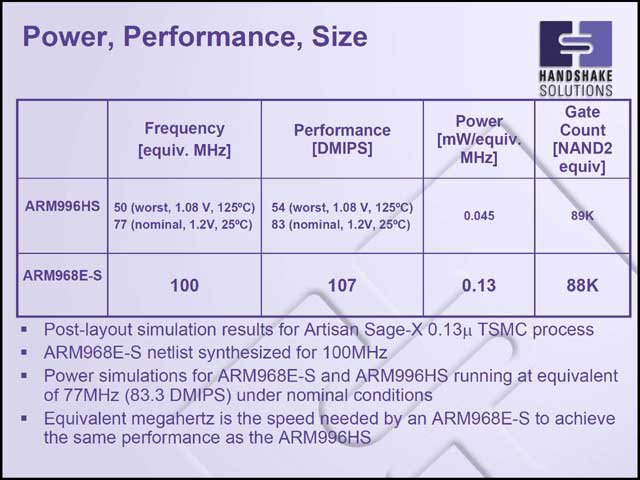 |
| 【写真35】CPUコア以外は、従来のARM V5TEと見分けがつかない | 【写真36】クロックレスだから0.045mW/MHzという表記は本来おかしいのだが、ここで言っているのは「同期回路で構成したら50MHzないし70MHz相当」という意味である | 【写真37】やはり周囲温度が上がると(Worst Caseでは摂氏125度)それなりに性能が落ちるのは致し方ないところ |
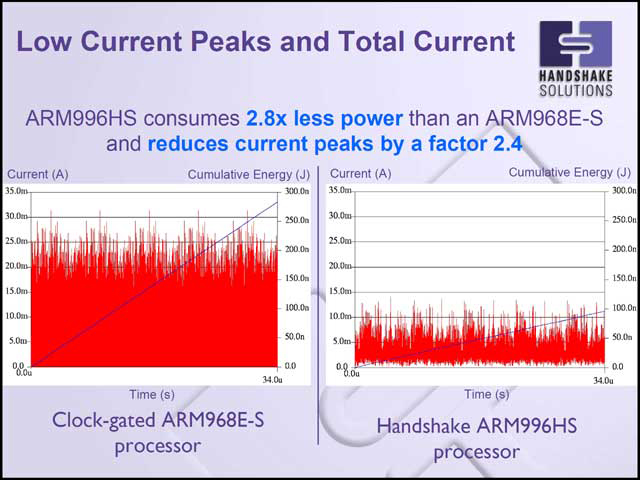
消費電力が低いのだから、電流そのもの(写真38)や不要輻射(写真39)も当然低く、消費電力の縛りが厳しい場所、あるいはノイズ低減を非常に強く求められる場所にARM996HSは最適であるとしている。
 |
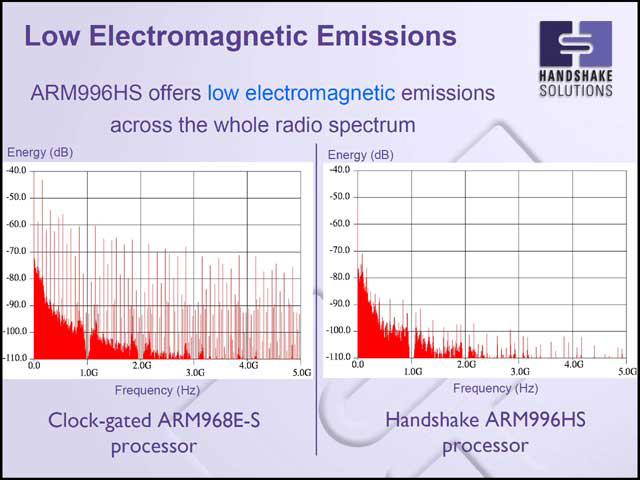 |
| 【写真38】赤が電流、黒が積算したエネルギー量である。ARM968E-Sも平均20~25mA程度だから悪い数字ではないのだが、ARM996HSは平均10mA未満に抑えられ、エネルギー量ではほぼ3分の1近い | 【写真39】こちらは周波数スペクトル。100MHzのベースクロックで動いている関係か、ARM968E-Sはこのベースクロックの整数倍の位置に高いピークが発生しており、全体的にノイズレベルがやや高い。ARM966HSでは整数倍のノイズはほとんど無い(メモリ周りでクロックが供給されるためか、皆無ではないが、かなりレベルは低い)上に、全体的にも低めである |
ちなみに消費電力が低い一方で性能も低いのは事実で、これを上げるのは逆に困難、ということらしく、今後の製品ラインナップを聞いたところ、「Cortex-M3」などを視野に入れている(逆にARM11とかCortex-A8/R4などは考えていない)という返答だった。つまり性能は低くてもいいが、低消費電力が求められる分野向けの技術、と割り切っているようだ。
ちなみにこの技術は別にARM向けに限ったわけではなく、8051を非同期化したこともあるとの話。これは商用ではなく技術研究の一環らしいが、ちょっと面白い話ではある。
□Spring Processor Forum2006のホームページ(英文)
http://www.instat.com/spf/06/
□ARMのホームページ
http://www.jp.arm.com/
□TIのホームページ
http://www.tij.co.jp/
□Handshake Solutionsのホームページ(英文)
http://www.handshakesolutions.com/
□関連記事
【5月17日】【SPF】ARC Internationalと東芝が戦略的提携
http://pc.watch.impress.co.jp/docs/2006/0517/spf01.htm
【2005年10月26日】【FPF】ARM、ハイエンドプロセッサコアの技術内容を公表
http://pc.watch.impress.co.jp/docs/2005/1026/fpf02.htm
Spring Processor Forum 2006レポートリンク集
http://pc.watch.impress.co.jp/docs/2006/link/spf.htm
(2006年5月26日)
[Reported by 大原雄介]
【PC Watchホームページ】
PC Watch編集部 pc-watch-info@impress.co.jp お問い合わせに対して、個別にご回答はいたしません。
Copyright (c)2006 Impress Watch Corporation, an Impress Group company. All rights reserved.